






stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(''.join(frames))
wf.close()
if name == ‘main’:
a = recode()
a.recode(RECORD_SECONDS=30, WAVE_OUTPUT_FILENAME=‘record_pianai.wav’)
我们录完的歌曲是个什么形式?
如果只看一个声道的话,他是一个一维数组,大概长成这个样子

我们把他按照索引值为横轴画出来,就是我们常常看见的音频的形式。
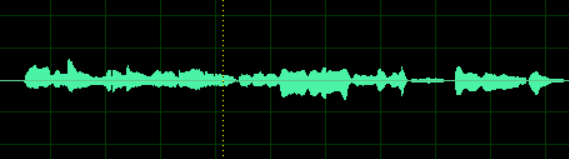
---
### 音频处理部分
>
> 我们在这里要写我们的核心代码。关键的“如何识别歌曲”。想想我们人类如何区分歌曲? 是靠想上面那样的一维数组吗?是靠歌曲的响度吗?都不是。
> 我们是通过耳朵所听到的特有的频率组成的序列来记忆歌曲的,所以我们想要写听歌识曲的话,就得在音频的频率序列上做文章。
> 复习一下什么是傅里叶变换。博主的《信号与系统》的课上的挺水,不过在课上虽然没有记下来具体的变换形式,但是感性的理解还是有的。
> 傅里叶变换的实质就是把时域信号变换成了频域信号。也就是原本X,Y轴分别是我们的数组下标和数组元素,现在变成了频率(这么说不准确,但在这里这样理解没错)和在这个频率上的分量大小。
>
>
>
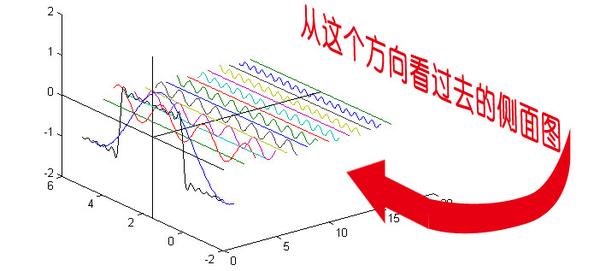
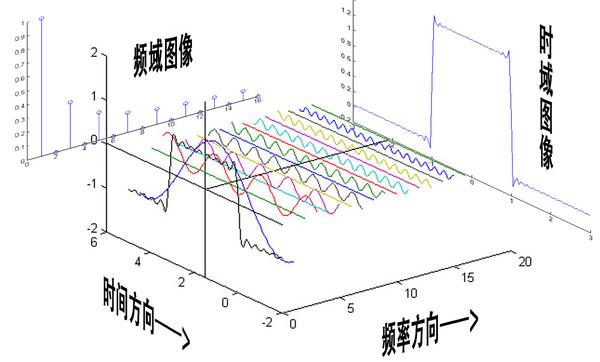
上面两幅图来自知乎,非常感谢Heinrich写的文章,原文链接:[点我跳转](https://bbs.csdn.net/topics/618317507)
怎么理解频域这个事情呢?对于我们信号处理不是很懂的人来说,最重要的就是改变对音频的构成的理解。我们原来认为音频就是如我们开始给出的波形那样,在每一个时间有一个幅值,不同的幅值序列构成了我们特定的声音。而现在,我们认为声音是不同的频率信号混合而成的,他们每一个信号都自始至终存在着。并且他们按照他们的投影分量做贡献。
让我们看看把一首歌曲转化到频域是什么样子?
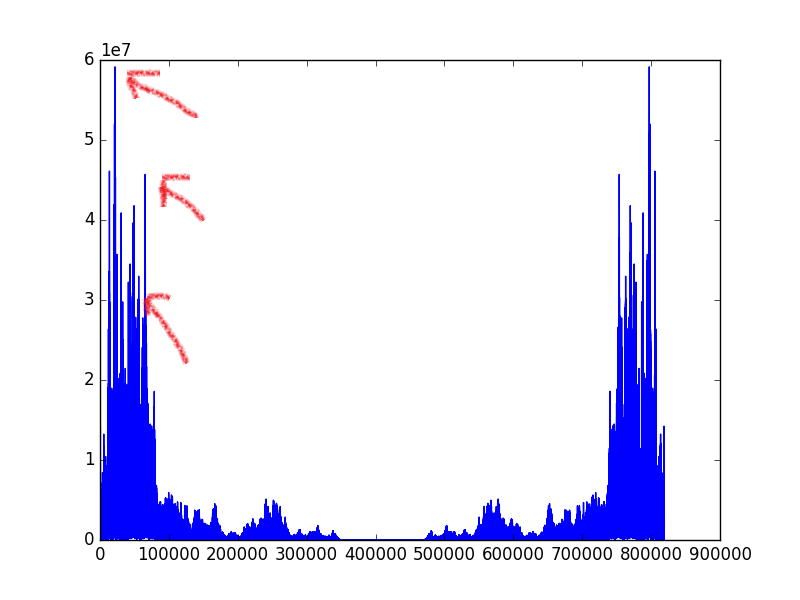
我们可以观察到这些频率的分量并不是平均的,差异是非常大的。我们可以在一定程度上认为在图中明显凸起的峰值是输出能量大的频率信号,代表着在这个音频中,这个信号占有很高的地位。于是我们就选择这样的信号来提取歌曲的特征。
但是别忘了,我们之前说的可是频率序列,傅里叶变换一套上,我们就只能知道整首歌曲的频率信息,那么我们就损失了时间的关系,我们说的“序列”也就无从谈起。所以我们采用的比较折中的方法,将音频按照时间分成一个个小块,在这里我每秒分出了40个块。
在这里留个问题:为什么要采用小块,而不是每秒一块这样的大块?
我们对每一个块进行傅里叶变换,然后对其求模,得到一个个数组。我们在下标值为(0,40),(40,80),(80,120),(120,180)这四个区间分别取其模长最大的下标,合成一个四元组,这就是我们最核心的音频“指纹”。
我们提取出来的“指纹”类似下面这样
>
> (39, 65, 110, 131), (15, 66, 108, 161), (3, 63, 118, 146), (11, 62, 82, 158), (15, 41, 95, 140), (2, 71, 106, 143), (15, 44, 80, 133), (36, 43, 80, 135), (22, 58, 80, 120), (29, 52, 89, 126), (15, 59, 89, 126), (37, 59, 89, 126), (37, 59, 89, 126), (37, 67, 119, 126)
>
>
>
音频处理的类有三个方法:载入数据,傅里叶变换,播放音乐。
如下:
coding=utf8
import os
import re
import wave
import numpy as np
import pyaudio
class voice():
def loaddata(self, filepath):
‘’’
:param filepath: 文件路径,为wav文件
:return: 如果无异常则返回True,如果有异常退出并返回False
self.wave_data内储存着多通道的音频数据,其中self.wave_data[0]代表第一通道
具体有几通道,看self.nchannels
'''
if type(filepath) != str:
raise TypeError, 'the type of filepath must be string'
p1 = re.compile('\.wav')
if p1.findall(filepath) is None:
raise IOError, 'the suffix of file must be .wav'
try:
f = wave.open(filepath, 'rb')
params = f.getparams()
self.nchannels, self.sampwidth, self.framerate, self.nframes = params[:4]
str_data = f.readframes(self.nframes)
self.wave_data = np.fromstring(str_data, dtype=np.short)
self.wave_data.shape = -1, self.sampwidth
self.wave_data = self.wave_data.T
f.close()
self.name = os.path.basename(filepath) # 记录下文件名
return True
except:
raise IOError, 'File Error'
def fft(self, frames=40):
'''
整体指纹提取的核心方法,将整个音频分块后分别对每块进行傅里叶变换,之后分子带抽取高能量点的下标
:param frames: frames是指定每秒钟分块数
:return:
'''
block = []
fft_blocks = []
self.high_point = []
blocks_size = self.framerate / frames # block_size为每一块的frame数量
blocks_num = self.nframes / blocks_size # 将音频分块的数量
for i in xrange(0, len(self.wave_data[0]) - blocks_size, blocks_size):
block.append(self.wave_data[0][i:i + blocks_size])
fft_blocks.append(np.abs(np.fft.fft(self.wave_data[0][i:i + blocks_size])))
self.high_point.append((np.argmax(fft_blocks[-1][:40]),
np.argmax(fft_blocks[-1][40:80]) + 40,
np.argmax(fft_blocks[-1][80:120]) + 80,
np.argmax(fft_blocks[-1][120:180]) + 120,
# np.argmax(fft_blocks[-1][180:300]) + 180,
))
def play(self, filepath):
'''
音频播放方法
:param filepath:文件路径
:return:
'''
chunk = 1024
wf = wave.open(filepath, 'rb')
p = pyaudio.PyAudio()
# 打开声音输出流
stream = p.open(format=p.get_format_from_width(wf.getsampwidth()),
channels=wf.getnchannels(),
rate=wf.getframerate(),
output=True)
# 写声音输出流进行播放
while True:
data = wf.readframes(chunk)
if data == "": break
stream.write(data)
stream.close()
p.terminate()
if name == ‘main’:
p = voice()
p.play(‘the_mess.wav’)
print p.name
这里面的self.high\_point是未来应用的核心数据。列表类型,里面的元素都是上面所解释过的指纹的形式。
---
### 数据存储和检索部分
因为我们是事先做好了曲库来等待检索,所以必须要有相应的持久化方法。我采用的是直接用mysql数据库来存储我们的歌曲对应的指纹,这样有一个好处:省写代码的时间
我们将指纹和歌曲存成这样的形式:

顺便一说:为什么各个歌曲前几个的指纹都一样?(当然,后面肯定是千差万别的)其实是音乐开始之前的时间段中没有什么能量较强的点,而由于我们44100的采样率比较高,就会导致开头会有很多重复,别担心。
我们怎么来进行匹配呢?我们可以直接搜索音频指纹相同的数量,不过这样又损失了我们之前说的序列,我们必须要把时间序列用上。否则一首歌曲越长就越容易被匹配到,这种歌曲像野草一样疯狂的占据了所有搜索音频的结果排行榜中的第一名。而且从理论上说,音频所包含的信息就是在序列中体现,就像一句话是靠各个短语和词汇按照一定顺序才能表达出它自己的意思。单纯的看两个句子里的词汇重叠数是完全不能判定两句话是否相似的。我们采用的是下面的算法,不过我们这只是实验性的代码,算法设计的很简单,效率不高。建议想要做更好的结果的同学可以使用改进的DTW算法。
我们在匹配过程中滑动指纹序列,每次比对模式串和源串的对应子串,如果对应位置的指纹相同,则这次的比对相似值加一,我们把滑动过程中得到的最大相似值作为这两首歌的相似度。
举例:
曲库中的一首曲子的指纹序列:[fp13, fp20, fp10, fp29, fp14, fp25, fp13, fp13, fp20, fp33, fp14]
检索音乐的指纹序列: [fp14, fp25, fp13, fp17]
比对过程:
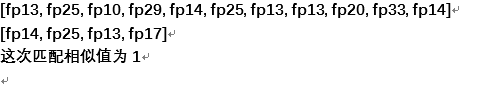






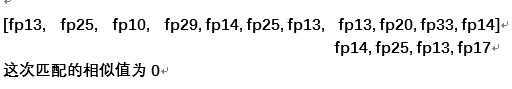
最终的匹配相似值为3
存储检索部分的实现代码
coding=utf-8
import os
import MySQLdb
import my_audio
class memory():
def init(self, host, port, user, passwd, db):
‘’’
初始化的方法,主要是存储连接数据库的参数
:param host:
:param port:
:param user:
:param passwd:
:param db:
‘’’
self.host = host
self.port = port
self.user = user
self.passwd = passwd
self.db = db
def addsong(self, path):
'''
添加歌曲方法,将歌曲名和歌曲特征指纹存到数据库
:param path: 歌曲路径
:return:
'''
if type(path) != str:
raise TypeError, 'path need string'
basename = os.path.basename(path)
try:
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1575
1575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









