







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Python全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注Python)

正文
Chrome浏览器
driver = webdriver.Chrome()
driver.get(‘https://www.csdn.net/’)
设置浏览器浏览器的宽高为:600x800
driver.maximize_window()
#### 浏览器前进&后退
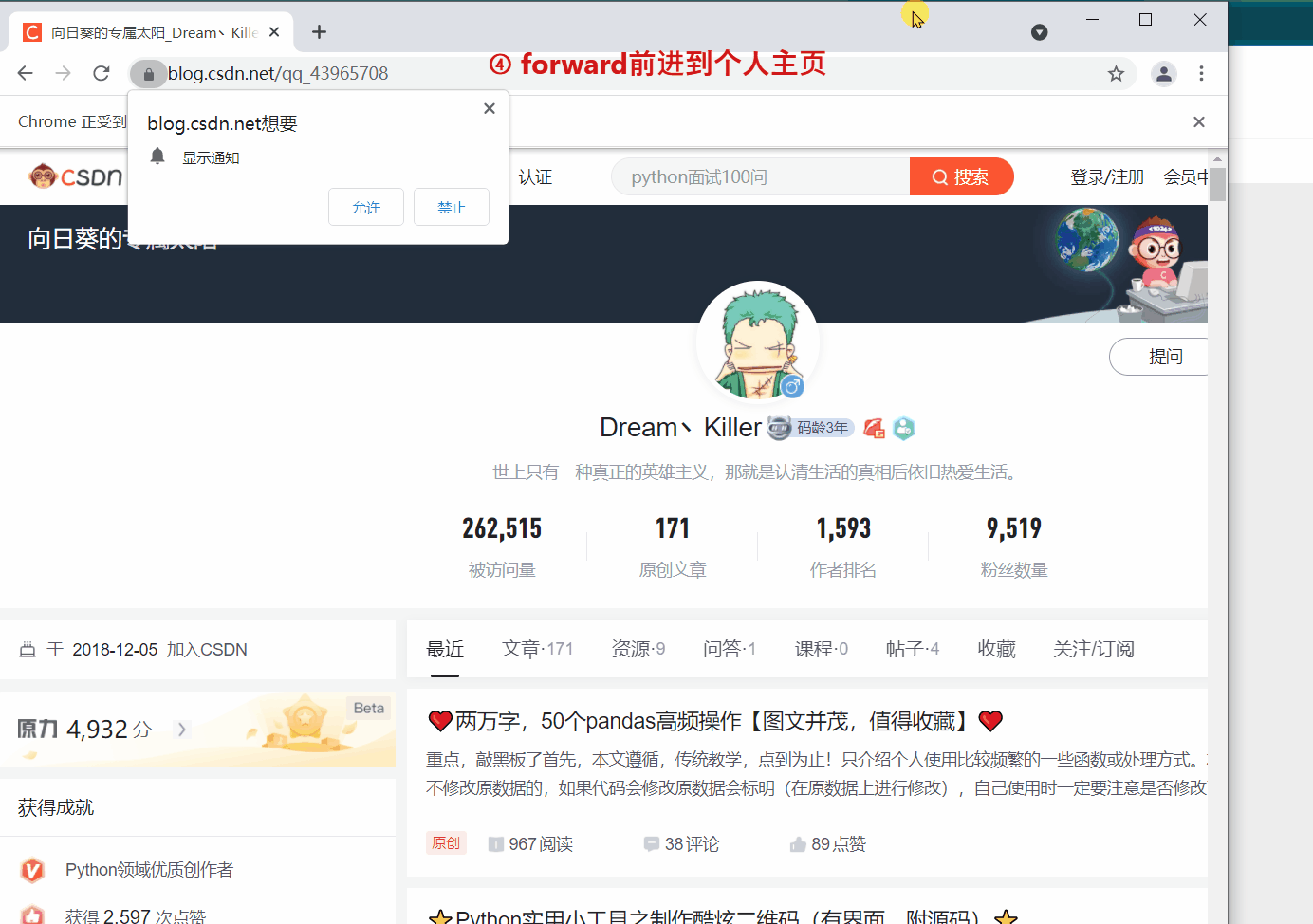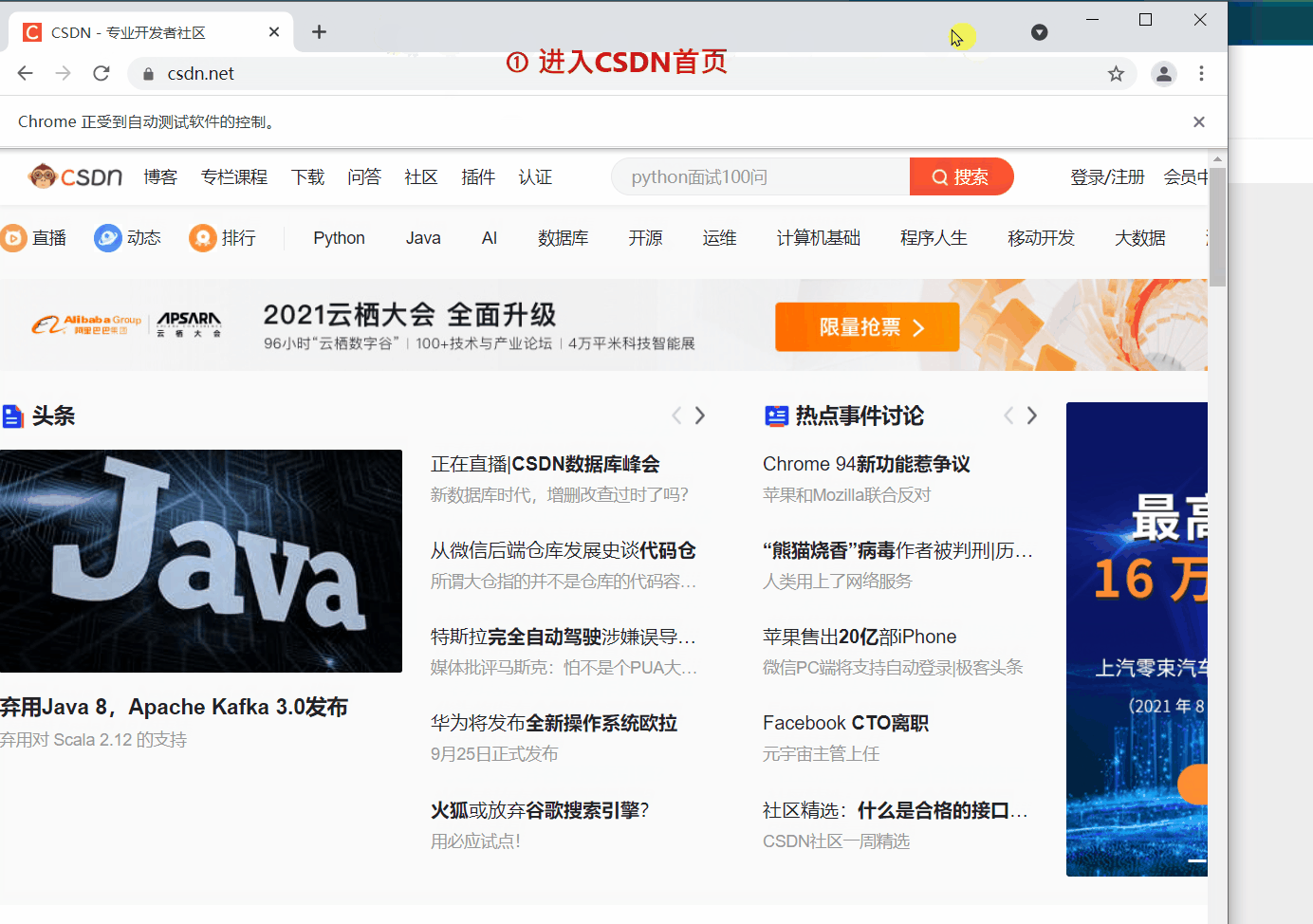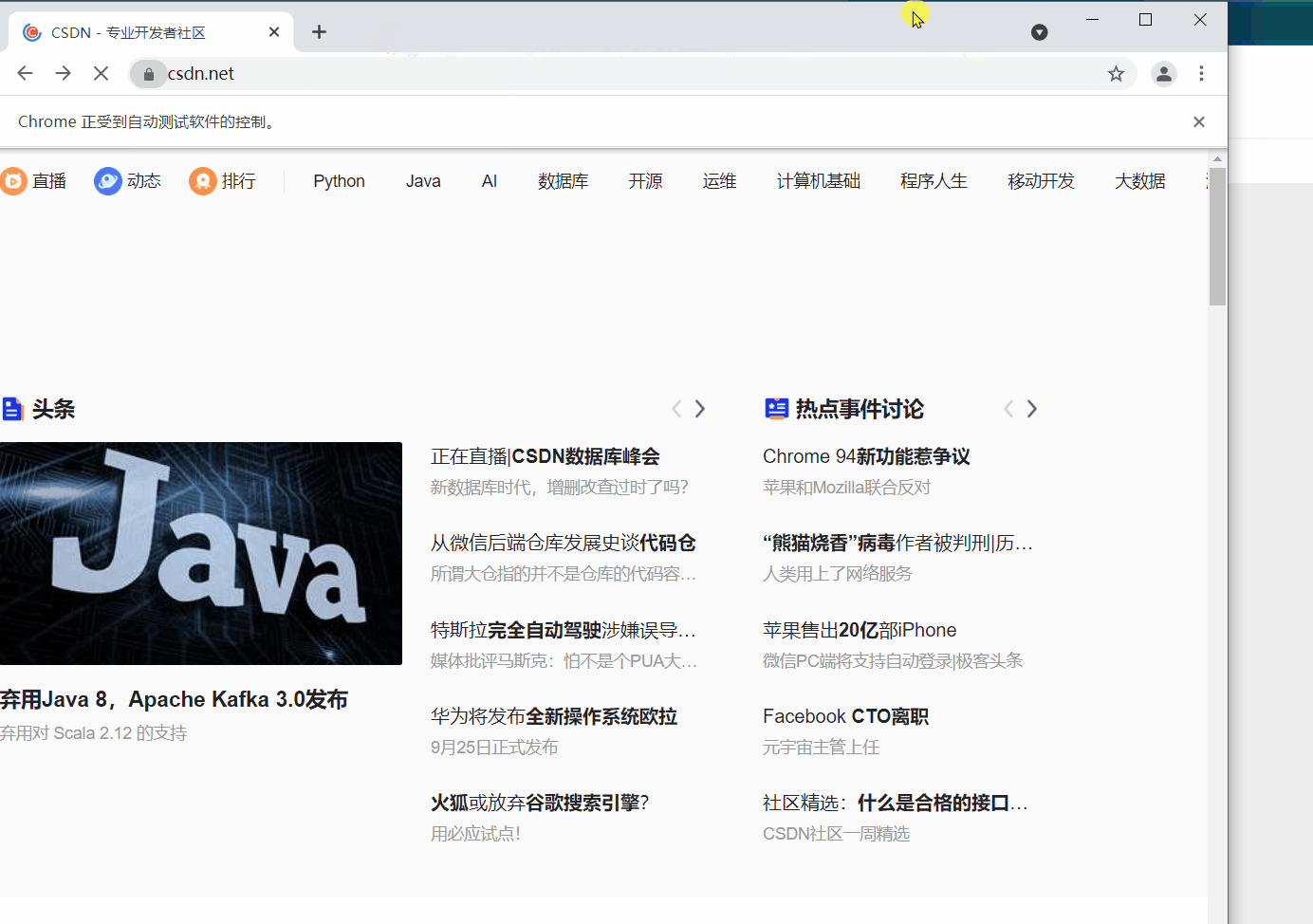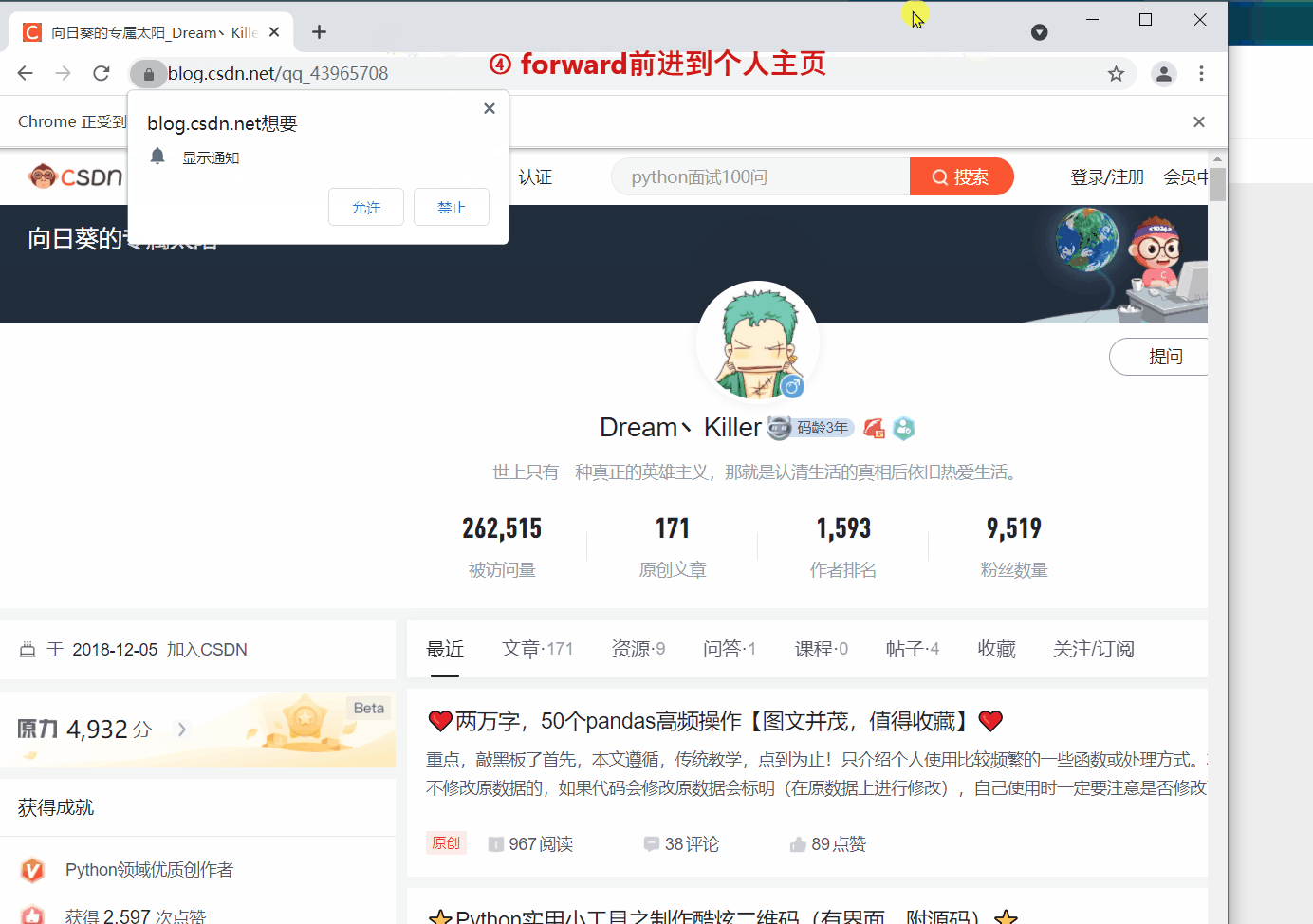
`webdriver` 提供 `back` 和 `forward` 方法来实现页面的后退与前进。下面我们 ①进入CSDN首页,②打开CSDN个人主页,③`back` 返回到CSDN首页,④ `forward` 前进到个人主页。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
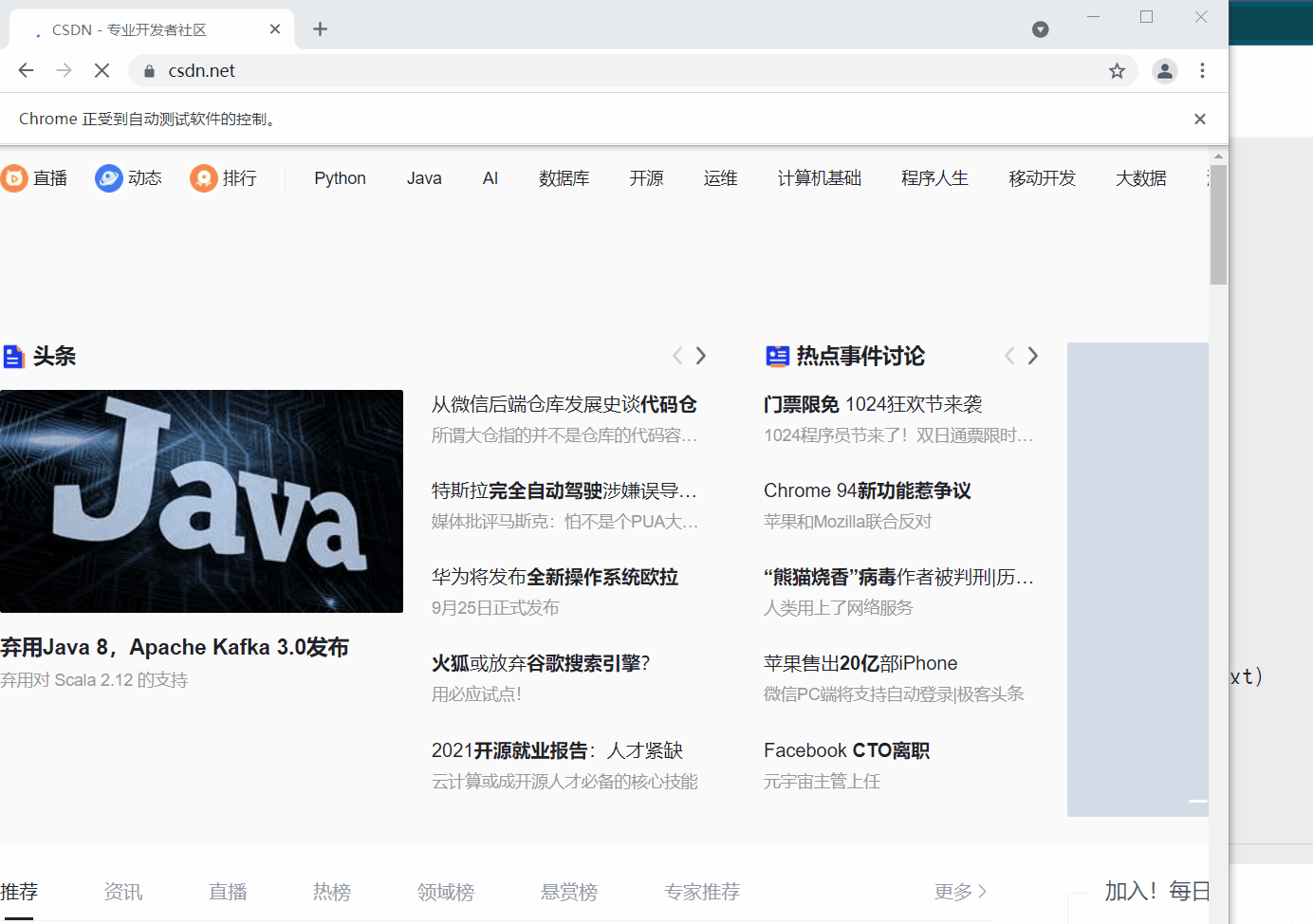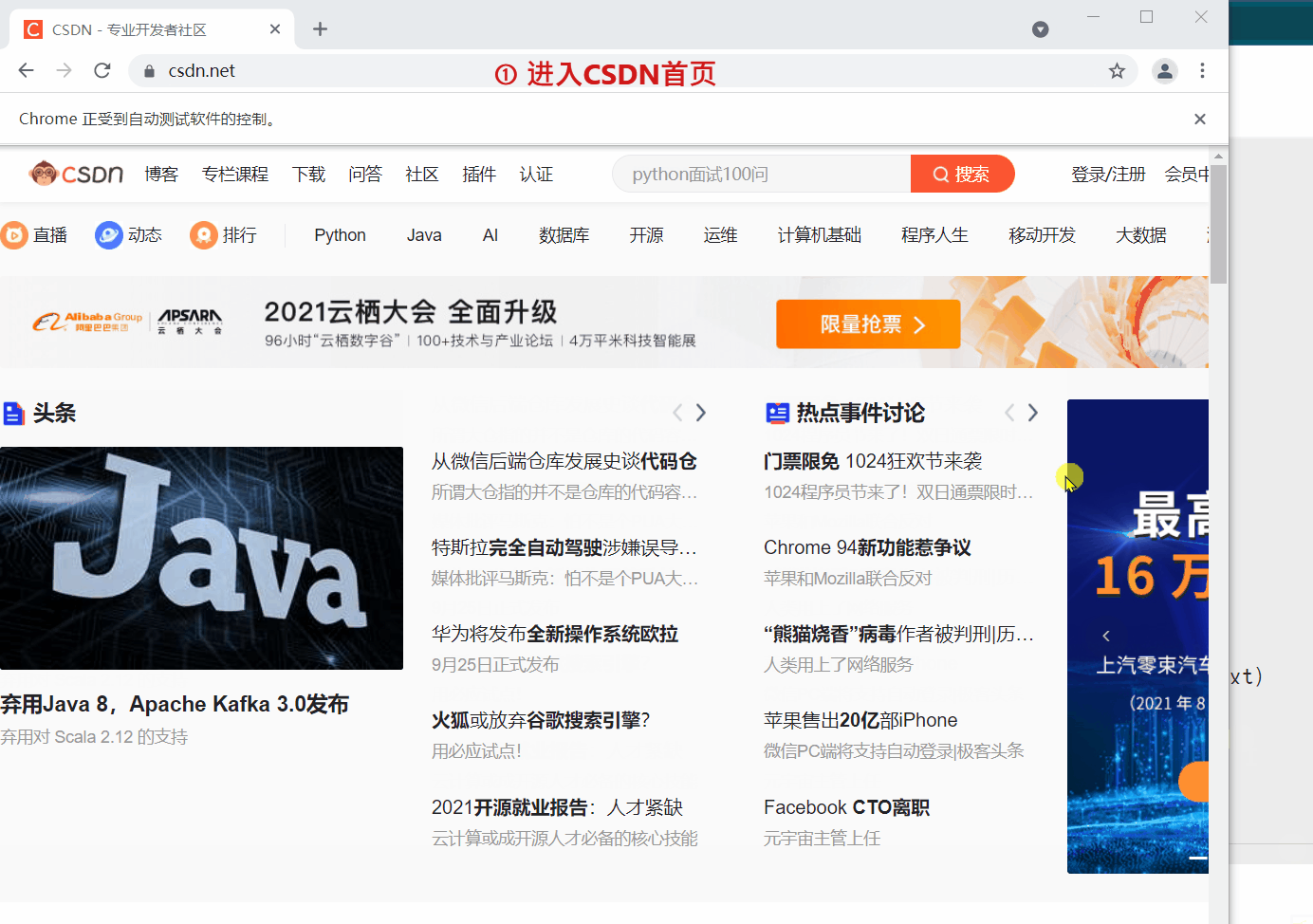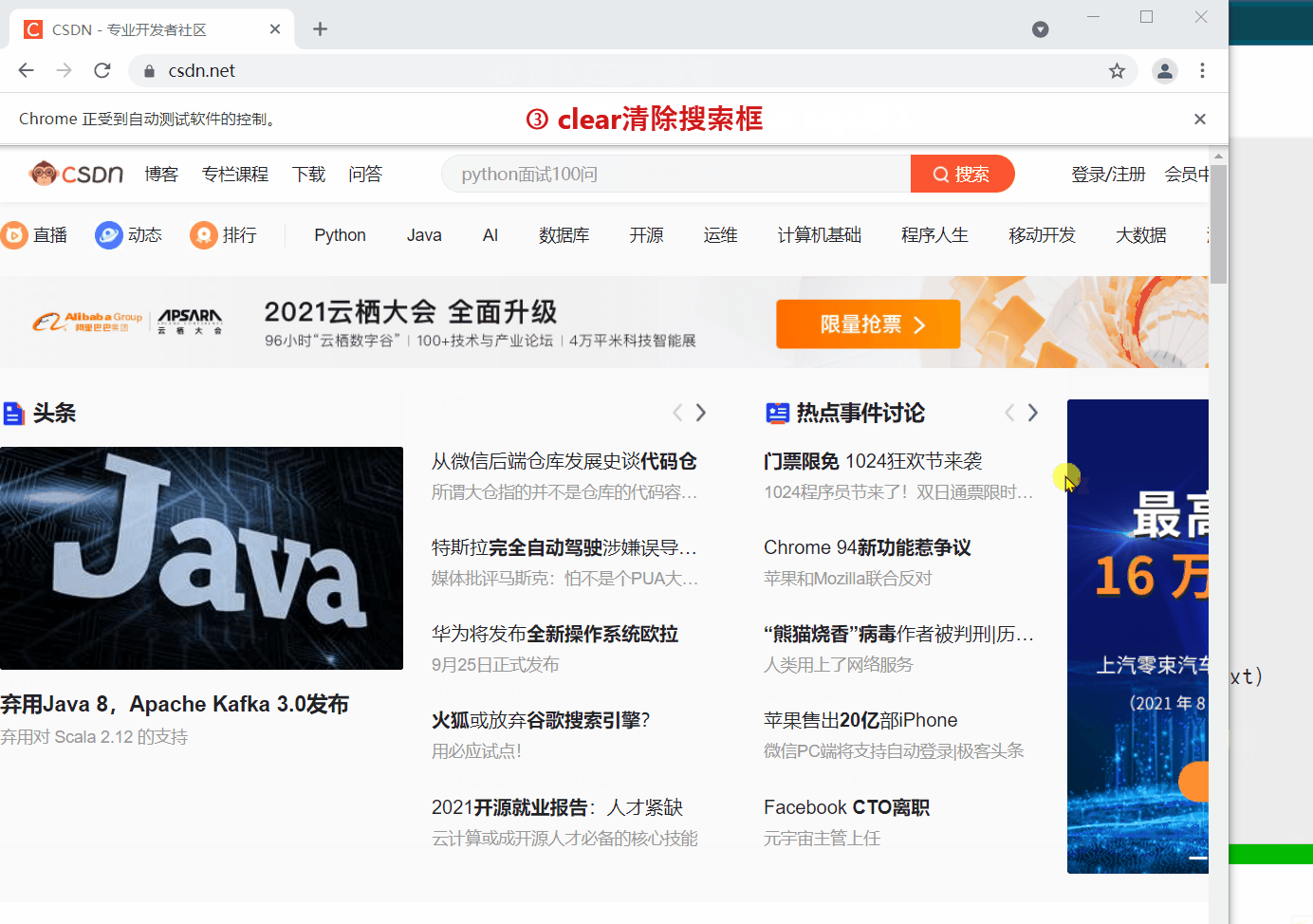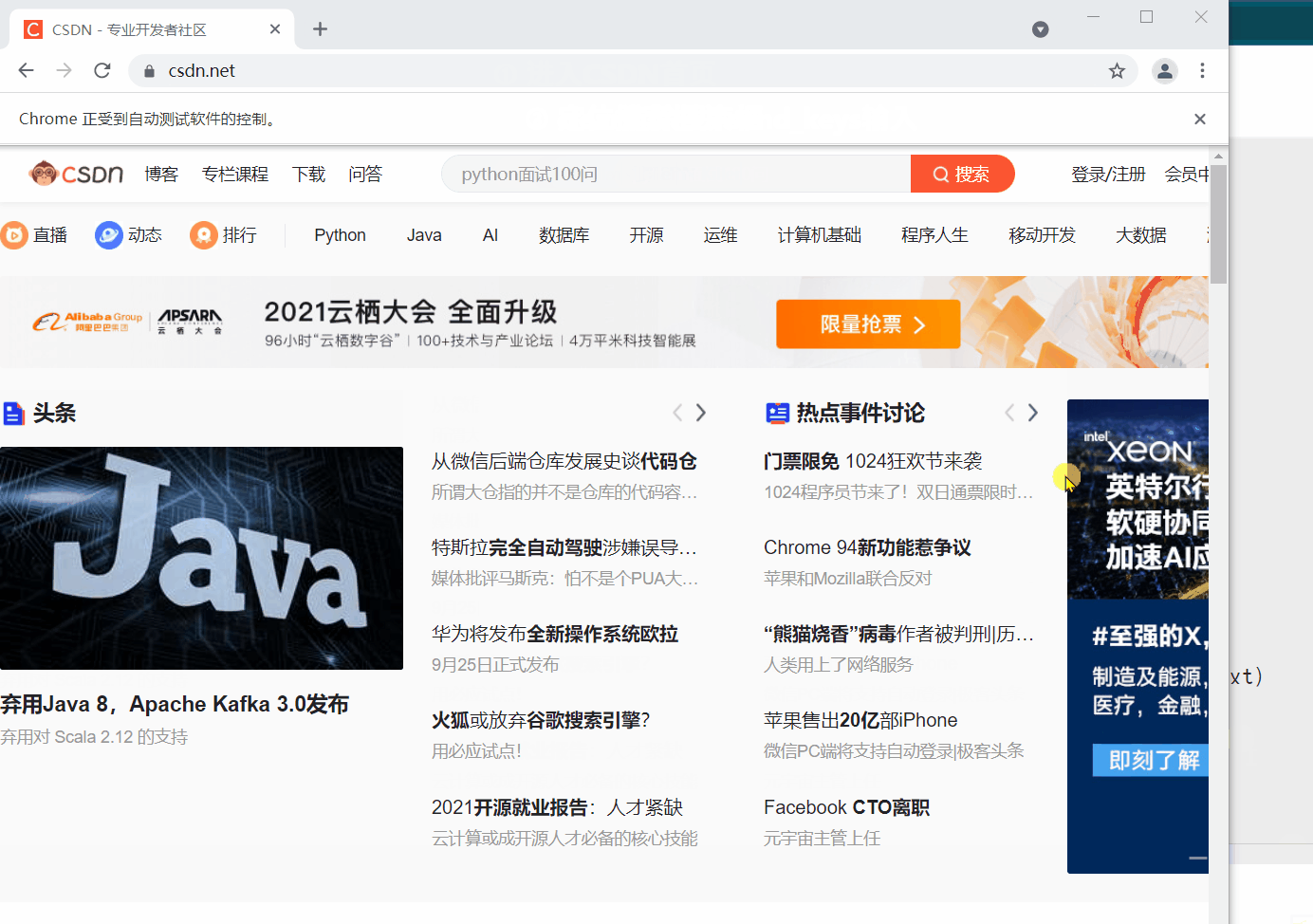
访问CSDN首页
driver.get(‘https://www.csdn.net/’)
sleep(2)
#访问CSDN个人主页
driver.get(‘https://blog.csdn.net/qq_43965708’)
sleep(2)
#返回(后退)到CSDN首页
driver.back()
sleep(2)
#前进到个人主页
driver.forward()
细心的读者会发现第二次 `get()` 打开新页面时,会在原来的页面打开,而不是在新标签中打开。如果想的话也可以在新的标签页中打开新的链接,但需要更改一下代码,执行 `js` 语句来打开新的标签。
在原页面打开
driver.get(‘https://blog.csdn.net/qq_43965708’)
新标签中打开
js = “window.open(‘https://blog.csdn.net/qq_43965708’)”
driver.execute_script(js)
#### 浏览器刷新
在一些特殊情况下我们可能需要刷新页面来获取最新的页面数据,这时我们可以使用 `refresh()` 来刷新当前页面。
刷新页面
driver.refresh()
#### 浏览器窗口切换
在很多时候我们都需要用到窗口切换,比如:当我们点击注册按钮时,它一般会打开一个新的标签页,但实际上代码并没有切换到最新页面中,这时你如果要定位注册页面的标签就会发现定位不到,这时就需要将实际窗口切换到最新打开的那个窗口。我们先获取当前各个窗口的句柄,这些信息的保存顺序是按照**时间**来的,最新打开的窗口放在数组的**末尾**,这时我们就可以定位到最新打开的那个窗口了。
获取打开的多个窗口句柄
windows = driver.window_handles
切换到当前最新打开的窗口
driver.switch_to.window(windows[-1])
#### 常见操作
webdriver中的常见操作有:
| 方法 | 描述 |
| --- | --- |
| `send_keys()` | 模拟输入指定内容 |
| `clear()` | 清除文本内容 |
| `is_displayed()` | 判断该元素是否可见 |
| `get_attribute()` | 获取标签属性值 |
| `size` | 返回元素的尺寸 |
| `text` | 返回元素文本 |
接下来还是用 CSDN 首页为例,需要用到的就是搜素框和搜索按钮。通过下面的例子就可以气息的了解各个操作的用法了。

from selenium import webdriver
driver = webdriver.Chrome()
driver.get(‘https://www.csdn.net/’)
sleep(2)
定位搜索输入框
text_label = driver.find_element_by_xpath(‘//*[@id=“toolbar-search-input”]’)
在搜索框中输入 Dream丶Killer
text_label.send_keys(‘Dream丶Killer’)
sleep(2)
清除搜索框中的内容
text_label.clear()
输出搜索框元素是否可见
print(text_label.is_displayed())
输出placeholder的值
print(text_label.get_attribute(‘placeholder’))
定位搜索按钮
button = driver.find_element_by_xpath(‘//*[@id=“toolbar-search-button”]/span’)
输出按钮的大小
print(button.size)
输出按钮上的文本
print(button.text)
‘’‘输出内容
True
python面试100问
{‘height’: 32, ‘width’: 28}
搜索
‘’’
---
### 鼠标控制
在webdriver 中,鼠标操作都封装在ActionChains类中,常见方法如下:
| 方法 | 描述 |
| --- | --- |
| `click()` | 单击左键 |
| `context_click()` | 单击右键 |
| `double_click()` | 双击 |
| `drag_and_drop()` | 拖动 |
| `move_to_element()` | 鼠标悬停 |
| `perform()` | 执行所有ActionChains中存储的动作 |
#### 单击左键
模拟完成单击鼠标左键的操作,一般点击进入子页面等会用到,左键不需要用到 `ActionChains` 。
定位搜索按钮
button = driver.find_element_by_xpath(‘//*[@id=“toolbar-search-button”]/span’)
执行单击操作
button.click()
#### 单击右键
鼠标右击的操作与左击有很大不同,需要使用 `ActionChains` 。
from selenium.webdriver.common.action_chains import ActionChains
定位搜索按钮
button = driver.find_element_by_xpath(‘//*[@id=“toolbar-search-button”]/span’)
右键搜索按钮
ActionChains(driver).context_click(button).perform()
#### 双击
模拟鼠标双击操作。
定位搜索按钮
button = driver.find_element_by_xpath(‘//*[@id=“toolbar-search-button”]/span’)
执行双击动作
ActionChains(driver).double_click(button).perform()
#### 拖动
模拟鼠标拖动操作,该操作有两个必要参数,
* **source**:鼠标拖动的元素
* **target**:鼠标拖至并释放的目标元素
定位要拖动的元素
source = driver.find_element_by_xpath(‘xxx’)
定位目标元素
target = driver.find_element_by_xpath(‘xxx’)
执行拖动动作
ActionChains(driver).drag_and_drop(source, target).perform()
#### 鼠标悬停
模拟悬停的作用一般是为了显示隐藏的下拉框,比如 CSDN 主页的收藏栏,我们看一下效果。
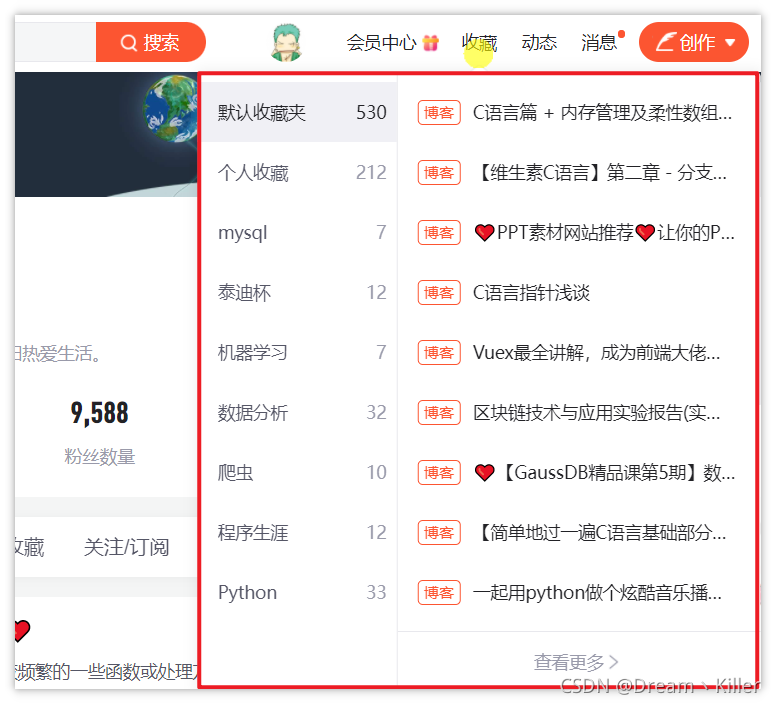
定位收藏栏
collect = driver.find_element_by_xpath(‘//*[@id=“csdn-toolbar”]/div/div/div[3]/div/div[3]/a’)
悬停至收藏标签处
ActionChains(driver).move_to_element(c
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2009
2009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









