







- 可恢复性:
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
- 顺序保证:
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。(Kafka 保证一个Partition 内的消息的有序性)
- 缓冲:
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
- 异步通信:
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
3. Kafka 基本架构
3.1. 拓扑结构
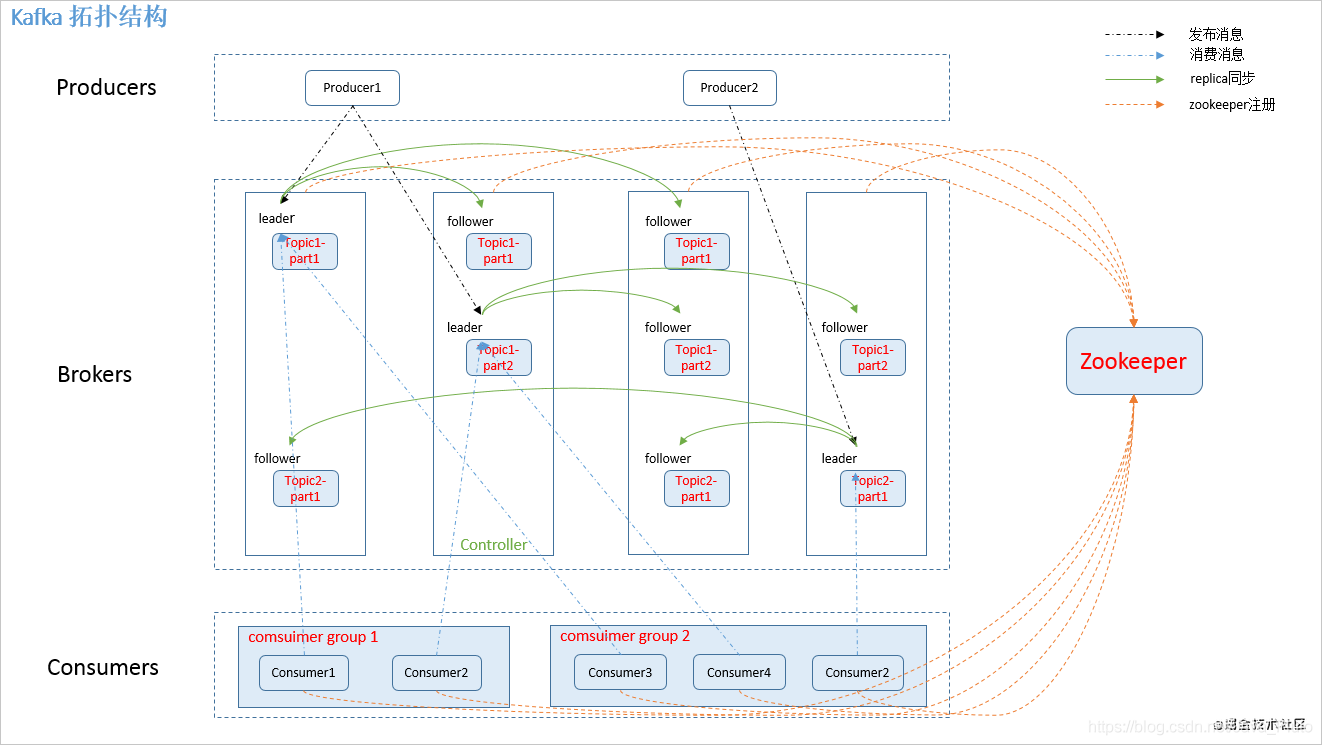
3.2. 名词概念
- producer:消息生产者,发布消息到 kafka 集群的终端或服务。
- broker:kafka 集群中包含的服务器。
- topic: 每条发布到 kafka 集群的消息属于的类别,即 kafka 是面向 topic 的。
- partition:partition 是物理上的概念,每个 topic 包含一个或多个 partition。 kafka 分配的单位是 partition。
- consumer:从 kafka 集群中消费消息的终端或服务。
- consumer group:high-level consumer API 中,每个consumer 都属于一个 consumer group,每条消息只能被 consumer group 中的一个 Consumer 消费,但可以被多个 consumer group 消费。
- replica:partition 的副本,保障 partition 的高可用。
- leader:replica 中的一个角色, producer 和 consumer 只跟 leader 交互。
- follower:replica 中的一个角色,从 leader 中复制数据。
- controller:kafka集群中的其中一个服务器,用来进行 leader election 以及 各种 failover
- zookeeper:kafka 通过 zookeeper 来存储集群的 meta 信息。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 159
159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









