







基础知识
-
索引的理解:
- 索引是数据库中用于加速数据查询的数据结构。
- 索引可以按照特定的列或字段值进行排序和组织,以提高查询性能。
-
观察主键索引现象:
- 主键索引是一种特殊的索引,它是唯一的,并且通常自动排序。
- 当表的主键被设置后,数据插入时会按照主键值的大小自动排序,即使插入时是乱序插入,MySQL也会自动按照主键进行有序排列。
-
MySQL与磁盘交互的基本单位是Page:
- MySQL在与磁盘交互时,以Page为基本单位进行读取和写入。
- 使用Page作为基本单位可以减少与磁盘I/O交互的次数,从而提高I/O效率。
- 局部性原理(数据访问时可能会访问其周围的数据)支持Page作为基本单位的有效性。
-
推导主键索引结构的构建:
- 索引结构的构建是基于B+树的数据结构,用于加速数据检索。
- 单个Page内部存储数据记录,可能包括页内目录用于加速查询。
- 随着数据量的增加,需要多个Page来存储数据,此时需要在Page之上创建页目录以加速查找。
- 逐级建立页目录,最终构建成B+树,B+树的每一层加速下一层的查找效率。
模型如下, 本质上B+树就是多级目录:
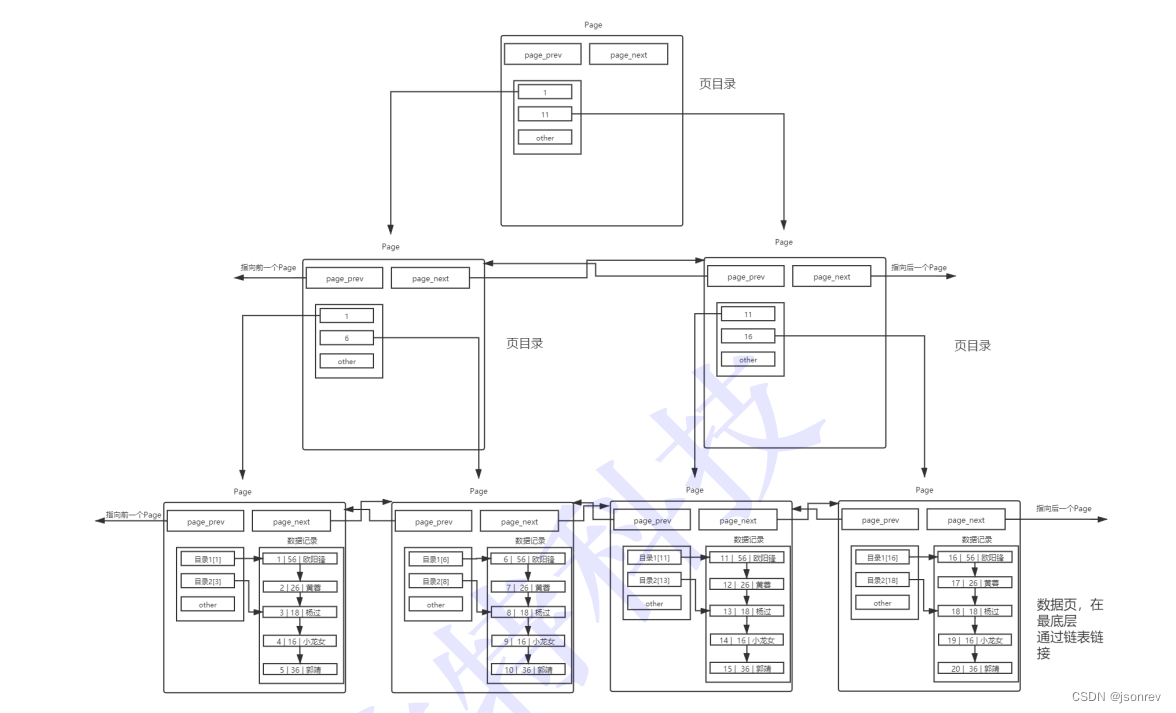
-
B+树中的Page结点是否需要全量加入到Buffer Pool中:
- 不需要将整棵B+树的结点全部加载到内存中,仅需加载访问路径上的结点。
- Page结点的修改标记用于标识脏数据,只有脏数据在刷新时才需要写回磁盘。
- MySQL与磁盘的交互基本单位是Page,这有助于精确控制内存的使用。
补充
-
数据库索引可以采用多种数据结构,不仅仅限于InnoDB存储引擎所采用的B+树结构。其他可能的数据结构包括:
- 链表:查找效率较低,因为需要线性遍历。
- 普通二叉搜索树:可能会退化成线性结构,导致查找效率下降。
- AVL树和红黑树:虽然保证了树的平衡性,但由于是二叉树结构,查询时需要遍历更多结点,可能导致更多的IO操作,因此不适用于索引结构。
- 哈希表:具有O(1)时间复杂度的查找效率,但不适合范围查找。
-
不同存储引擎支持不同类型的索引,例如:
- InnoDB支持BTREE索引。
- MyISAM支持BTREE索引。
- MEMORY/HEAP支持HASH和BTREE索引。
- NDB支持HASH和BTREE索引。
-
B+树相对于普通B树的优势在于:
- B+树的叶子结点之间连接,有利于范围查找。
- B+树叶子结点存储的是数据记录的主键值,而不是整条数据记录,节省了空间。
-
聚簇索引与非聚簇索引的区别:
- 聚簇索引将数据记录与索引结构放在一起,例如InnoDB。
- 非聚簇索引将数据记录与索引结构分离,例如MyISAM。
-
创建不同类型的索引:
- 创建主键索引可以在创建表时指定主键,或者在创建表后使用ALTER TABLE命令添加主键索引。
- 创建唯一索引可以在创建表时指定UNIQUE属性,或者在创建表后使用ALTER TABLE命令添加唯一索引。
- 创建普通索引可以在创建表时指定INDEX属性,或者在创建表后使用ALTER TABLE命令添加普通索引。
- 创建全文索引可以在支持的存储引擎上使用FULLTEXT属性来定义全文索引。
-
查询索引信息可以使用SHOW KEYS FROM 表名、SHOW INDEX FROM 表名或DESC 表名等SQL命令来查看。
-
删除索引可以使用ALTER TABLE 表名 DROP INDEX 索引名的方式删除非主键索引,或者使用ALTER TABLE 表名 DROP PRIMARY KEY的方式删除主键索引。
-
创建索引的原则包括:
- 频繁作为查询条件的字段应该创建索引。
- 唯一性差的字段不适合单独创建索引。
- 更新频繁的字段不适合创建索引。
- 不会出现在WHERE子句中的字段不应该创建索引,避免不必要的索引占用存储空间。















 405
405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









