







====================================================================================
思考:如果要经常判断 1 个元素是否存在,要怎么做?
-
很容易想到使用哈希表(
HashSet、HashMap),将元素作为 key 去查找时间复杂度:O(1),但是空间利用率不高,需要占用比较多的内存资源
如果需要编写一个网络爬虫去爬10亿个网站数据,为了避免爬到重复的网站,如何判断某个网站是否爬过?
- 很显然,
HashSet、HashMap并不是非常好的选择
是否存在时间复杂度低、占用内存较少的数据结构 ?
- 布隆过滤器(Bloom Filter)
===================================================================================
1970年由布隆提出
- 它是一个空间效率高的概率型数据结构,可以用来告诉你:一个元素一定不存在或者可能存在。
优缺点:
-
优点:空间效率和查询时间都远远超过一般的算法
-
缺点:有一定的误判率、删除困难
布隆过滤器实质上是一个很长的二进制向量和一系列随机映射函数(Hash函数);
常见应用:
-
网页黑名单系统
-
垃圾邮件过滤系统
-
爬虫的网址判重系统
-
解决缓存穿透问题(后端开发)
=======================================================================================
假设布隆过滤器由 20位二进制、 3个哈希函数组成,每个元素经过哈希函数处理都能生成一个索引位置。
布隆过滤器的基础操作有两个:添加、查询
-
添加元素:将每一个哈希函数生成的索引位置都设为 1
-
查询元素是否存在:
如果有一个哈希函数生成的索引位置不为 1,就代表不存在(100%准确)
如果每一个哈希函数生成的索引位置都为 1,就代表存在(存在一定的误判率)

-
添加、查询的时间复杂度都是:O(k) ,k 是哈希函数的个数
-
空间复杂度是:O(m) ,m 是二进制位的个数
误判率 p 受 3 个因素影响:二进制位的个数 m、哈希函数的个数 k、数据规模 n。
误判率 p 的公式:

已知误判率 p、数据规模 n,求二进制位的个数 m、哈希函数的个数 k:
-
二进制位的个数 m:

-
哈希函数的个数 k:

===========================================================================
Guava: Google Core Libraries For Java(谷歌核心库中Java实现)
布隆过滤器的基础操作有两个:添加元素、查询元素是否存在
/**
* 添加元素
* @return true代表bit发送了变化
*/
boolean put(T value);
/**
* 查询元素是否存在
* @return false代表一定不存在, true代表可能存在
*/
boolean contains(T value);
根据上面的公式可知,布隆过滤器必然有2个全局变量:
-
bitSize:二进制向量的长度(一共有多少个二进制位) -
hashSize:哈希函数的个数
并且必然有个容器来存储这些二进制位:
bits:这里选择long[]来存储,因为1个long可以表示64位bit;(int[]等数组也可以)
package com.mj;
public class BloomFilter<T> {
/**
* 二进制向量的长度(一共有多少个二进制位)
*/
private int bitSize;
/**
* 二进制向量
*/
private long[] bits;
/**
* 哈希函数的个数
*/
private int hashSize;
/**
* 布隆过滤器的构造
* @param n 数据规模
* @param p 误判率, 取值范围(0, 1)
*/
public BloomFilter(int n, double p){
if (n <= 0 || p <= 0 || p >= 1) { // 非法输入检测
throw new IllegalArgumentException("wrong n or p");
}
// 根据公式求出对应的数据
double ln2 = Math.log(2);
// 求出二进制向量的长度
bitSize = (int) (- (n * Math.log(p)) / (ln2 * ln2));
hashSize = (int) (bitSize * ln2 / n);
// bits数组的长度
bits = new long[(bitSize + Long.SIZE - 1) / Long.SIZE]; // 分页公式
// (64 + 64 - 1) / 64 = 127 / 64 = 1
// (128 + 64 - 1) / 64 = 2
// (130 + 64 - 1) / 64 = 3
// 分页问题:
// 每一页显示100条数据, pageSize = 100
// 一共有999999条数据, n = 999999
// 请问有多少页 pageCount = (n + pageSize - 1) / pageSize
};
}
测试一下,假设有1亿个数据,要求误判率为1%:
可以得到哈希函数的个数为 6,二进制位的个数是 958505837。
public static void main(String[] args) {
BloomFilter<Integer> bf = new BloomFilter<>(1_0000_0000, 0.01);
// 哈希函数的个数: 6
// 二进制位的个数: 958505837
}
设置指定位置元素的二进制值为1
比如要设置 100000 的 第2位bit 为 1,应当 100000 | 000100,即 100000 | (1 << 2);
100000
| 000100 == (1 << 2)
------------------
100100
那么设置 value 的 第index位bit为 1,则是 value| (1 << index);
/**
* 设置index位置的二进制为1
*/
private boolean set(int index){
// 对应的long值
long value = bits[index / Long.SIZE];
int bitValue = 1 << (index % Long.SIZE);
bits[index / Long.SIZE] = value | bitValue;
return (value & bitValue) == 0;
}
有了以上基础,可以实现布隆过滤器的添加元素操作:
/**
* 添加元素
*/
public boolean put(T value) {
nullCheck(value);
// 利用value生成 2 个整数
int hash1 = value.hashCode();
int hash2 = hash1 >>> 16;
boolean result = false;
for (int i = 1; i <= hashSize; i++) {
int combinedHash = hash1 + (i * hash2);
if (combinedHash < 0) {
combinedHash = ~combinedHash;
}
// 生成一个二进制的索引
int index = combinedHash % bitSize;
// 设置第index位置的二进制为1
if (set(index)) result = true;
// 101010101010010101
// | 000000000000000100 1 << index
// 101010111010010101
}
return result;
}
查看指定位置的二进制的值
比如要查看 10101111 的 第2位bit 为 1,应当 10101111 & 00000100,即 10101111 & (1 << 2),只有指定位置的二进制的值为 0,返回值才会是 0,否则为 1;
10101111
& 00000100 == (1 << 2)
--------------
00000100 != 0, 说明index位的二进制为1
那么获取 value 的 第index位bit 的值,则是 value & (1 << index);
/**
* 查看index位置的二进制的值
* @param index
* @return true代表1, false代表0
*/
private boolean get(int index) {
// 对应的long值
long value = bits[index / Long.SIZE];
return (value & (1 << (index % Long.SIZE))) != 0;
}
有了以上基础,可以实现布隆过滤器的判断一个元素是否存在操作:
/**
* 判断一个元素是否存在
*/
public boolean contains(T value) {
nullCheck(value);
// 利用value生成2个整数
int hash1 = value.hashCode();
int hash2 = hash1 >>> 16;
for (int i = 1; i <= hashSize; i++) {
int combinedHash = hash1 + (i * hash2);
if (combinedHash < 0) {
combinedHash = ~combinedHash;
}
// 生成一个二进制的索引
int index = combinedHash % bitSize;
// 查询第index位置的二进制是否为0
if (!get(index)) return false;
// 101010101010010101
// | 000000000000000100 1 << index
// 101010111010010101
}
return true;
}
===============================================================================
package com.mj;
public class BloomFilter<T> {
/**
* 二进制向量的长度(一共有多少个二进制位)
*/
private int bitSize;
/**
* 二进制向量
*/
private long[] bits;
/**
* 哈希函数的个数
*/
private int hashSize;
/**
* 布隆过滤器的构造
* @param n 数据规模
* @param p 误判率, 取值范围(0, 1)
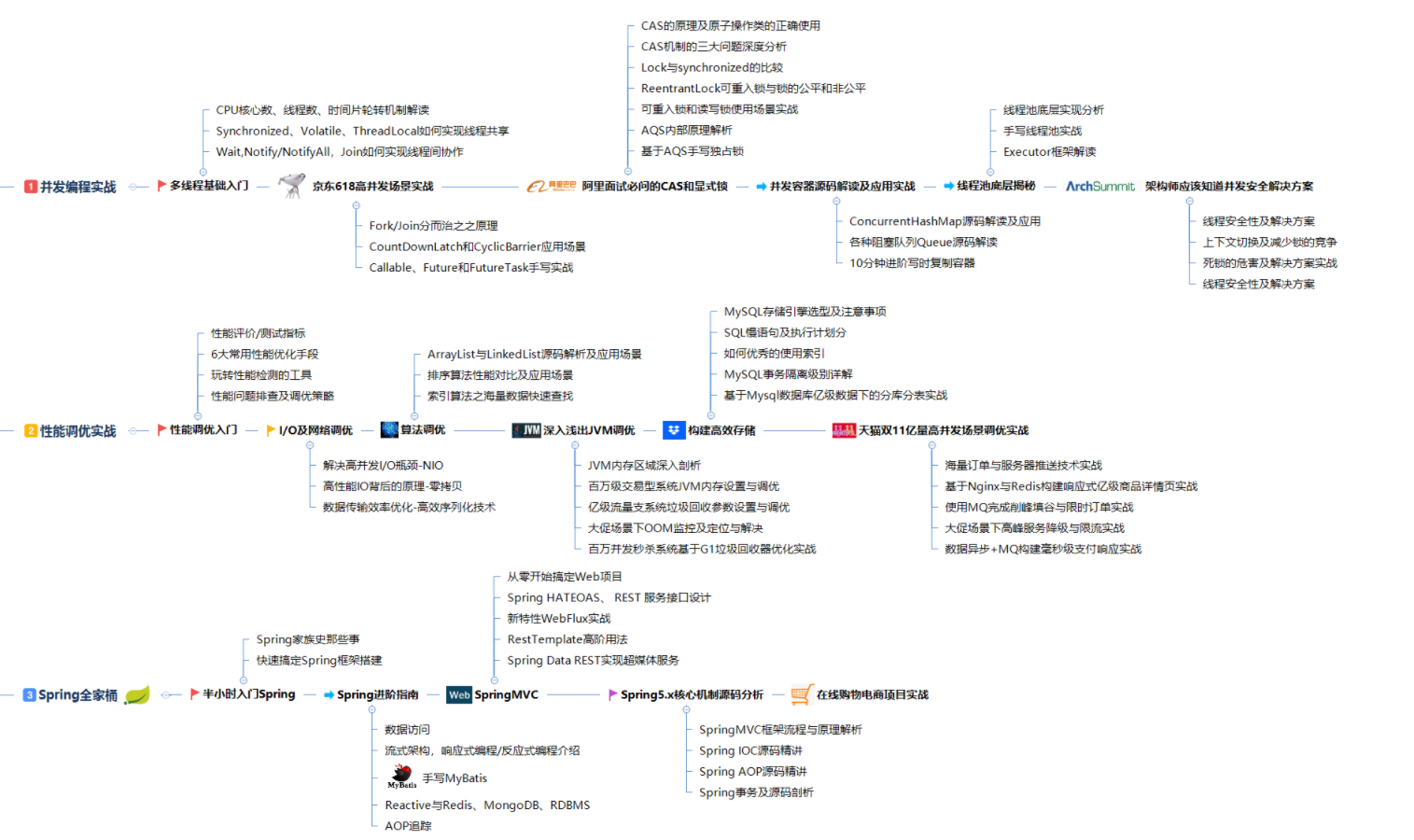
# 技术学习总结
学习技术一定要制定一个明确的学习路线,这样才能高效的学习,不必要做无效功,既浪费时间又得不到什么效率,大家不妨按照我这份路线来学习。


# 最后面试分享
大家不妨直接在牛客和力扣上多刷题,同时,我也拿了一些面试题跟大家分享,也是从一些大佬那里获得的,大家不妨多刷刷题,为金九银十冲一波!

* 二进制向量的长度(一共有多少个二进制位)
*/
private int bitSize;
/**
* 二进制向量
*/
private long[] bits;
/**
* 哈希函数的个数
*/
private int hashSize;
/**
* 布隆过滤器的构造
* @param n 数据规模
* @param p 误判率, 取值范围(0, 1)
# 技术学习总结
学习技术一定要制定一个明确的学习路线,这样才能高效的学习,不必要做无效功,既浪费时间又得不到什么效率,大家不妨按照我这份路线来学习。
[外链图片转存中...(img-5izcW6gE-1628428275051)]
[外链图片转存中...(img-f2TDdjJZ-1628428275052)]
[外链图片转存中...(img-vwFkVJgG-1628428275053)]
# 最后面试分享
大家不妨直接在牛客和力扣上多刷题,同时,我也拿了一些面试题跟大家分享,也是从一些大佬那里获得的,大家不妨多刷刷题,为金九银十冲一波!
[外链图片转存中...(img-BLfiMRVv-1628428275055)]
[外链图片转存中...(img-mUuWuStu-1628428275057)]
**最后,若需要完整pdf版,可以点赞本文后[点击这里免费领取](https://gitee.com/vip204888/java-p7)**















 1825
1825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









