






1.KMP
解决str2是否为str1子串且如果是子串从str1哪个位置开始的问题
暴力方法时间复杂度: O(N*M),N、M分别为str1和str2长度
KMP:
思路:
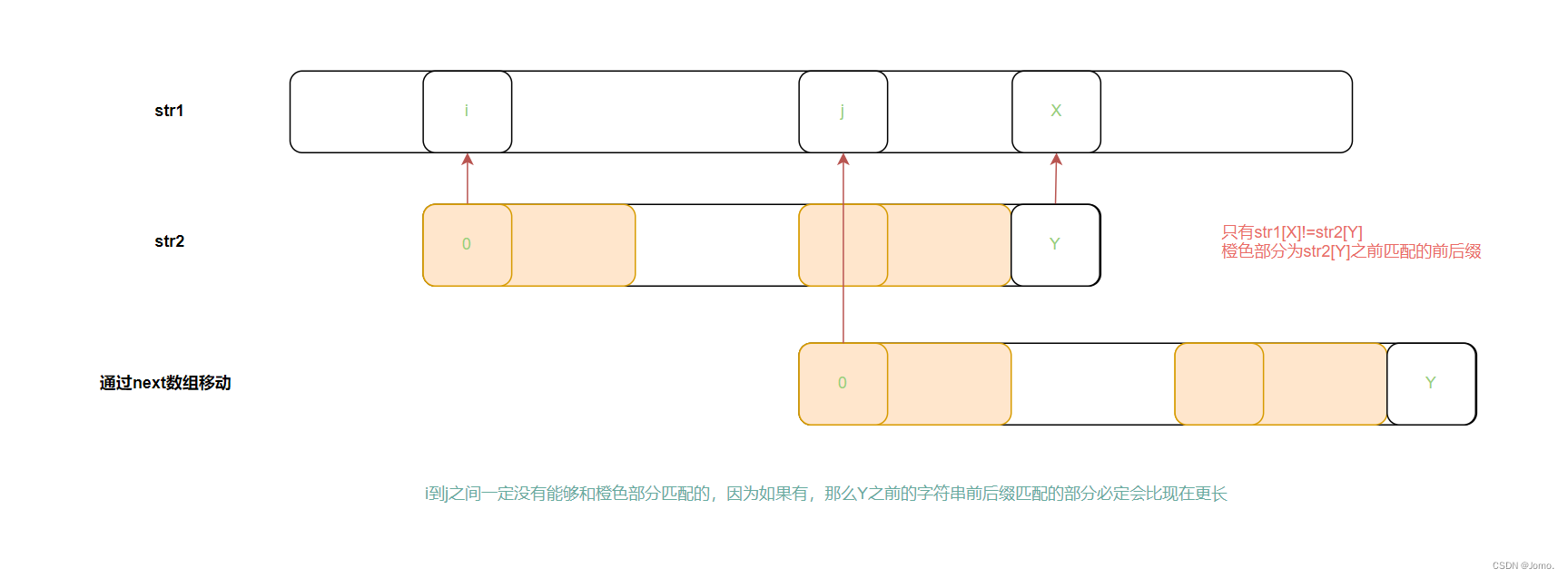
1.找str[i]字符前的字符串前缀后缀的最大匹配长度,且不能取整体
2.需要str2每个字符的信息(该字符前的字符串的前缀后缀的最大匹配长度)放入next数组中
3.人为规定next[0]=-1,next[1]=0
4.实际代码过程中不是把str2[0]向后移,而是让str2中不同的字符索引Y=next[Y](跳到前缀的后一个字符),但
逻辑上相同
int kmp(string str1, string str2) {
int i1 = 0;//str1中比对的位置
int i2 = 0;//str2中比对的位置
vector<int>next = getNext(str2);//O(M)
//O(N)
while (i1 < str1.length() && i2 < str2.length()) {
if (str1[i1] == str2[i2]) {
i1++;
i2++;
}else if(i2==0) {//next[i2]==-1
//说明第一个字符就不等,str2中比对的位置已经无法往前跳了,让str1换一个开头去匹配
i1++;
}
else {
//str2比对的位置跳到前缀的后一个字符
i2 = next[i2];
}
}
//i1越界 或者 i2越界
//如果匹配成功,i1到达str1中匹配的最后一个字符,i2也到达str2中最后一个字符,start=i1-i2.length()+1=i1-i2
return i2 == str2.length() ? i1 - i2 : -1;
}
vector<int>getNext(string str) {
if (str.length() == 1) {
return { -1 };
}
vector<int>next(str.length());
next[0] = -1;
int i = 2;
int cn = 0;//cn是用来和i-1字符比较的字符索引,且cn恰好等于next[i-1]
while (i < next.size()) {
if (str[i - 1] == str[cn]) {
next[i++] = ++cn;
}
else if (cn > 0) {
cn = next[cn];
}
else {
next[i++] = 0;
}
}
return next;
}

2.Manacher算法

1.经典方法:
依次以每个字符为中心,向两边扩,两边字符相同就继续向外扩,直至两边字符不同。
问题:当回文子串长度为偶数时,该方法失效。
解决:在字符串两边和每两个字符之间添加特殊符号'#'(并不一定要与原字符串的字符不同,因为都
是"实"与"实"比,"虚"与"虚"比),再依次遍历新字符去扩。
时间复杂度: O(n^2)
2.Manacher算法:
回文直径:从中心出发向两边扩,包含的子串长度。
回文半径:回文直径的一半。
(1)创建回文半径数组,每个字符都有回文半径。
(2)右边界(int)R记录每次扩到的最右边界,如果比上次扩得远则更新。
(3)中心点(int)C记录由哪个点扩到最右边界,和R同步更新。
(4)分类讨论:假设开始扩展的点为str[i],以下我们简称为i
4.1 i>=R:直接暴力扩(向两边扩),无优化。
4.2 i<R:
左边界L:R关于C的对称点
i关于C的对称点j
4.2.1 j的回文区域彻底属于(L,R):i的回文区域长度与j相同
4.2.2 j的回文区域的左半区域部分在L左边:i的回文半径=R-i
4.2.3 j的回文区域左边界=L(压线):至少有一个回文区域,但是不确定会不会更大。
string manacherString(string str) {
string res;
int index = 0;
for (int i = 0; i < str.length() * 2 + 1; i++) {
char c = (i & 1) == 0 ? '#' : str[index++];
res.push_back(c);
}
return res;
}
int maxLcpsLength(string s) {
if (s.length() == 0)return 0;
string str = manacherString(s);
vector<int>pArr(str.length());
int C = -1;
int R = -1;
int maxLen = INT_MIN;
for (int i = 0; i != str.length(); i++) {
//先算出每种情况下不用至少不用验的区域,再去扩展
pArr[i] = R > i ? min(pArr[2 * C - i], R - i) : 1;
while (i + pArr[i]<str.length() && i - pArr[i]>-1) {
if (str[i + pArr[i]] == str[i - pArr[i]]) pArr[i]++;
else break;
}
if (i + pArr[i] > R) {
R = i + pArr[i];
C = i;
}
maxLen = max(maxLen, pArr[i]);
}
return maxLen - 1;
}
时间复杂度分析:
由于四个分支中,i都是增加,R要么增加要么不变,总增长幅度是2n,所以时间复杂度是 O(n)
Manacher算法保证了i和R都是增长状态,所以可以把时间复杂度从O(n^2)优化到O(n)
3.窗口更新最大最小值

窗口:
1. 左边界L、右边界R只能向右移动
2. L<R
3. 可以选择L或R二者之一往右动
思路:利用双端队列实现:存索引(即能知道值,还能知道索引)
1. R往右走时,从尾部添加新元素,并保证从头到尾严格单调递增,不满足就删掉队尾元素
2. L往右走时,如果队头元素与过期元素相同则删去,否则不管
3. 下标大且对应的值也大,那么就可以把前面比它小的元素删去了,因为前面小的元素再也没可能成为最大值了
原因:因为索引大且值大的元素比前面那些元素晚过期
双端队列维持的信息:如果目前窗口不再添加新元素,而L依次往右动,谁会依次成为最大值,最大值优先级信息。
最大值:
vector<int>getMaxWindow(vector<int>vec, int w) {
if (vec.size() == 0 || w < 1 || vec.size() < w)return {};
deque<int>qmax;
vector<int>res(vec.size() - w + 1);
int index = 0;
for (int i = 0; i < vec.size(); i++) {
while (!qmax.empty() && vec[qmax.back()] <= vec[i]) {//不满足严格递减的删去
qmax.pop_back();
}
//删掉一定数量的元素后加入新元素
qmax.push_back(vec[i]);
if (qmax.front() == i - w) {//因窗口右移过期
qmax.pop_front();
}
//i至少遍历到索引为2的元素窗口才处理过3个元素
if (i >= w - 1) {
res[index++] = vec[qmax.front()];
}
}
return res;
}
最小值:双端队列从头到尾严格递增,逻辑与求最大值类似。
时间复杂度分析:
每个元素进出队列最多各一次,所以是 O(n)4.单调栈
左右两边离得最近的比当前值大的元素的索引:
思路:
1.创建一个栈,从底到顶按从小到大排序,添加的元素对应的索引。
2.如果准备添加的元素不符合顺序,那么就删栈顶,同时我们知道栈里所有数右边离得最近且比这个数小的元素就是
准备新加的元素,左边离得最近且比这个数小的元素就是该元素在栈中底下的那一个元素。
3.遍历结束后,若栈中还有数,就进入清算阶段,弹出所有元素并处理。右边都没有比该元素小的元素。
//有重复元素的,把重复元素的索引按顺序放入vector中
vector<vector<int>>getNearLess(vector<int>vec) {
//创建二维数组,第一列存放左边最近小数索引,第二列存放右边最近小数索引
vector<vector<int>>res(vec.size(), vector<int>(2));
//单调栈
stack<vector<int>>stk;
//遍历数组
for (int i = 0; i < vec.size(); i++) {
//如果栈不为空,且待添加数不符合单调性,那就要删去栈顶,同时更新删去元素的信息
while (!stk.empty() && vec[stk.top()[0]] > vec[i]) {
vector<int>popIs = stk.top();
stk.pop();
//stk.top()[stk.top().size() - 1],相同元素的索引中最后一个加进来的。
int leftLessIndex = stk.empty() ? -1 : stk.top()[stk.top().size() - 1];
//可能有多个索引,所以要遍历完
for (int popi : popIs) {
res[popi][0] = leftLessIndex;
res[popi][1] = i;
}
}
if (!stk.empty() && vec[stk.top()[0]] == vec[i]) {
stk.top().push_back(i);
}
else {
vector<int>indexs;
indexs.push_back(i);
stk.push(indexs);
}
}
//清算
while (!stk.empty()) {
vector<int>popIs = stk.top();
stk.pop();
int leftLessIndex = stk.empty() ? -1 : stk.top() [stk.top().size() - 1];
for (int popi : popIs) {
res[popi][0] = leftLessIndex;
res[popi][1] = -1;
}
}
return res;
}
时间复杂度分析:
每个元素进栈出栈的次数都各位1次,所有时间复杂度是 O(n)5.最大指标

思路:单调栈
1.遍历数组,利用单调栈的信息,求每次以vec[i]作为最小值的子数组(范围是vec[i]左边最近小数到右边最近小
数)的指标,并记录遍历过程中的最大指标。
int max2(vector<int>vec) {
int size = vec.size();
vector<int>sums(size);
sums[0] = vec[0];
for (int i = 1; i < size; i++) {
sums[i] = sums[i - 1] + vec[i];
}
int maxVal = INT_MIN;
stack<int>stk;
for (int i = 0; i < size; i++) {
while (!stk.empty() && vec[stk.top()] >= vec[i]) {
int j = stk.top();
stk.pop();
//栈为空,说明弹出的元素左边没有比它更小的了
maxVal = max(maxVal, (stk.empty() ? sums[i - 1] : (sums[i - 1] - sums[stk.top()])) * vec[j]);
}
stk.push(i);
}
while (!stk.empty()) {
int j = stk.top();
stk.pop();
//栈为空,说明弹出的元素左边没有比它更小的了
maxVal = max(maxVal, (stk.empty() ? sums[size - 1]: (sums[size - 1] - sums[stk.top()])) * vec[j]);
}
return maxVal;
}















 348
348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











