








此篇文章与大家分享多线程的第一部分:引入线程以及创建多线程的几种方式
此文章是建立在前一篇文章进程的基础上的
如果有不足的或者错误的请您指出!
1.认识线程
我们知道现代的cpu大多都是多核心的cpu,此时通过特定的编程技巧,即可以将不同的进程调度到多个cpu上执行,也就是我们在进程章节里面讲到的"并发".在我们的日常开发中,往往一个服务器要同时面对多个客户端,为多个客户端提供服务,此时如果只利用一个cpu处理客户端的请求,那么响应速度就会变慢.那么此时"多核心"的cpu就能起到一定的效果,每一个客户端连上服务器的时候,服务器都创建一个进程给客户端提供服务,客户端断开了,服务器就把进程销毁
但是随之而来的又是一个问题,服务器频繁的创建,销毁进程实际上也会对服务器的响应速度造成影响
我们引入多线程的初心就是为了解决上述"进程太重"的问题,线程实际上也称为"轻量级进程",顾名思义,他的创建和销毁开销都比进程要小
线程可以当成是进程的一部分,一个线程中可能含有一个线程,也可能含有多个线程
我们在进程章节谈到的进程,就是只针对一个进程里面只有一个线程而言的
我们在前面说过,描述一个进程是使用pcb这样的结构体,但是实际上准确来说应该是:一个pcb描述的是一个线程,多个pcb共同描述一个进程
那么我们对pcb中有些属性就该有新的认识
(1)pid :实际上一个线程对应的是一个pid,因此不同线程的pid是不一样的
(2)内存指针和文件描述操作符:在若干个线程中,这两个属性实际上是一样的
(3)状态、上下文、优先级、记账信息对应的是每个线程自己的属性
(4)tgid:在一个进程内是一样的,不同进程就不一样
此时,在同一个进程内,若干个线程之间的资源(内存资源和文件资源)是共享的,但是每个线程又是独立地在cpu上调度执行
因此就有一个重要的结论:进程是系统进行资源分配的基本单位,线程是系统调度执行的基本单位
(在进程章节谈到的进程调度,实际上就是线程调度)
为什么说线程比进程更轻量级??为什么说线程的创建和销毁比进程开销更小??
本质上就是因为创建进程的时候就要涉及到资源的分配,销毁进程的时候涉及到资源的销毁,而创建线程,由于同一个线程之间的资源是共享的,相当于资源已经有了,就省去了分配资源 / 销毁资源的步骤,只是在创建第一个线程(也就是创建进程的时候)需要这个步骤,因此线程自然就轻量
但是多线程就没有缺点嘛??
首先,一个进程内的线程不能无限地引入,引入的线程一旦多了,单位时间内要进行调度的次数也就增多了,此时对加大线程调度的开销,当这种开销太大的时候,实际上性能可能不升反降
其次,当多个线程同时访问和操作某写共享资源时,如多个线程并发地读取、修改、写入共享数据时,如果没有适当的同步措施,就可能会引发数据竞争等一系列的问题,就会让程序出现bug,这就是我们后面要谈到的线程安全问题
再者,如果一个线程出现问题,就可能会影响到其他线程,如某个线程如果抛出异常,但是没有很好地处理异常,就会使整个进程退退出
2.第一个多线程代码
2.1通过继承Thread来创建一个线程类
class MyThread extends Thread{
@Override
public void run(){
while(true){
System.out.println("hello world");
}
}
}
public class Demo1 {
public static void main(String[] args) {
Thread t = new MyThread();
thread.start();
while(true){
System.out.println("main");
}
}
}
(1)在MyThread中的run方法,就是用来描述这个线程具体要干什么活
(2)在上述代码中,实际上存在着两个线程,一个是我们main线程(也称主线程),一个是t线程,此时main线程和t线程就在并发式的执行了
我们可以通过java提供的工具:jconsole来清楚地看到不同的进程
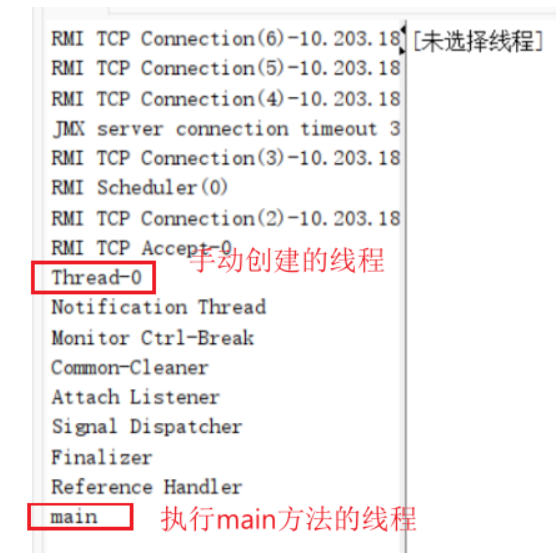
至于剩下的线程,就是Jvm帮我们做的一些其他的工作,例如垃圾回收等
(5)可以利用sleep让线程进入阻塞状态
实际上就是让当前线程主动放弃去cpu上执行,时间到了线程才会解除阻塞状态,重新有机会被调度到cpu上执行
class MyThread extends Thread{
@Override
public void run(){
while(true){
System.out.println("hello world");
try {
Thread.sleep(1000);//谁调用,谁就sleep
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
public class Demo1 {
public static void main(String[] args) throws InterruptedException {
Thread thread = new MyThread();
thread.start();
while(true){
System.out.println("main");
Thread.sleep(1000);
}
}
}
此时运行后可以明显发现打印速度变慢了
(6)在上面代码中,某一时刻先打印main还是Thread是不确定的,这是因为多个线程之间的调度顺序是"无序"的,在操作系统内部也称为抢占式执行.即任何一个线程在执行到任何一段代码的时候,都会被其他线程抢占了他的cpu资源,就会给别的线程执行,就会充满"随机性".也正是因为这样的随机性,导致我们很多程序的执行结果是"不可预估的",甚至可能带来bug
(7)关于start
我们前面说到到run方法,只是描述了一个线程具体应该干什么,而start方法才是操作系统提供的"创建线程"的api,此时调用start方法,在内核中才会真正创建一个pcb,真正为这个线程分配资源,进一步系统调度到这个线程的时候,才会执行到run方法
而如果我们直接执行run方法,那么就只是简单的执行run方法里面的代码逻辑,并没有创建一个线程
像这样创建一个方法(run),不去手动调用,而是交给系统 / 其他的库 / 其他的框架调用,就是回调函数
3.2通过实现runnable接口创建线程
class MyRunnable implements Runnable {
@Override
public void run(){
while(true){
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
public class Demo2 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(new MyRunnable());
t.start();
System.out.println("hello main");
}
}
Runnable的作用就只是描述了一个任务,这个任务与具体的执行机制无关,也就是我们是通过线程的方式执行还是通过其他的方式执行无所谓,这样的话就能把"任务"本身和"线程"概念分割开来了,这样的任务就可以交给其他地方来执行
对比刚刚的第一种方法,区别就是,刚刚第一种方法是线程自己记录我要干啥,而这种写法就是别人记录我要干啥,线程只是负责执行
这种方法方便代码的解耦合
3.3匿名内部类来实现
本质上就是上面两种,只不过换了一种方法来实现
public class Demo3 {
public static void main(String[] args) {
Thread thread = new Thread(){
@Override
public void run() {
....
}
};
}
}
public class Demo1 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(new Runnable() {
@Override
public void run() {
while(true){
System.out.println("hello Thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
});
t.start();
while(true){
System.out.println("hello main");
Thread.sleep(1000);
}
}
}
3.5使用lambda表达式
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while(true){
System.out.println("hello t");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
t.start();
while(true){
System.out.println("hello main");
Thread.sleep(1000);
}
}
我们会发现,用这种写法貌似没有重写run方法??
实际上lambda方法就是对run方法的实现,通过lambda这种方式,我们可以直接在Thread对象的构造函数中执行线程的任务逻辑,无需显示地重写run方法
感谢您的访问!!期待您的关注!!!














 1227
1227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









