






 文章介绍了如何利用Linux系统提供的queue.h头文件中的TAILQ结构和宏来实现非递归遍历目录。通过定义EntNode结构体,结合TAILQ的相关宏进行链表操作,如初始化、插入和删除节点,从而优化之前的目录遍历代码,减少不必要的空间分配。pushDir函数只将目录加入队列,对文件则直接处理,这改变了遍历顺序,但提高了效率。
文章介绍了如何利用Linux系统提供的queue.h头文件中的TAILQ结构和宏来实现非递归遍历目录。通过定义EntNode结构体,结合TAILQ的相关宏进行链表操作,如初始化、插入和删除节点,从而优化之前的目录遍历代码,减少不必要的空间分配。pushDir函数只将目录加入队列,对文件则直接处理,这改变了遍历顺序,但提高了效率。
Linux C语言非递归遍历指定目录下的所有文件及目录
书接上回,在上面的链接中,我们使用了自己编写的双向循环链表完成了非递归版本的目录遍历。
由于每个程序员对链表的定义及实现方式各不相同,其正确性也需要验证。因此,出于对编程规范性和统一性的考虑,我们应该使用Linux系统中提供的链表。这样不仅可以规范代码,代码的阅读者也无需关注链表的实现方式是否正确。
下面我们就来使用queue.h头文件中定义的结构体和接口来实现非递归目录的遍历,并对之前的版本进行一些优化。
queue.h
queue官方手册
在此头文件中,定义了五种链表形式:
- SLIST 单向链表
- LIST 双向链表
- STAILQ 单向有尾链表
- TAILQ 双向有尾链表
- CIRCLEQ 双向循环链表
其具体的定义及结构在下面的文章中有详细说明
Linux内嵌链表(sys/queue.h)详解
在使用时我们需要包含头文件#include <sys/queue.h>
双向链表TAILQ和CIRCLEQ均可以满足要求,这里我们选择TAILQ作为实现方式,其相关定义及接口如下
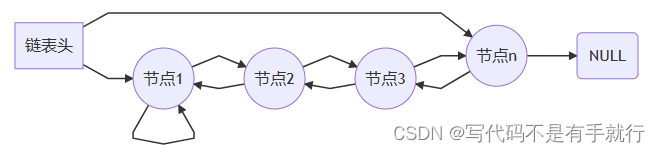
(图片来自大佬tissar的博客https://blog.csdn.net/tissar/article/details/86978743)
/*
* Singly-linked Tail queue declarations.
*/
#define STAILQ_HEAD(name, type) \
struct name { \
struct type *stqh_first; /* first element */ \
struct type **stqh_last; /* addr of last next element */ \
}
#define STAILQ_HEAD_INITIALIZER(head) \
{ NULL, &(head).stqh_first }
#define STAILQ_ENTRY(type) \
struct { \
struct type *stqe_next; /* next element */ \
}
/*
* Singly-linked Tail queue functions.
*/
#define STAILQ_INIT(head) do { \
(head)->stqh_first = NULL; \
(head)->stqh_last = &(head)->stqh_first; \
} while (/*CONSTCOND*/0)
#define STAILQ_INSERT_HEAD(head, elm, field) do { \
if (((elm)->field.stqe_next = (head)->stqh_first) == NULL) \
(head)->stqh_last = &(elm)->field.stqe_next; \
(head)->stqh_first = (elm); \
} while (/*CONSTCOND*/0)
#define STAILQ_INSERT_TAIL(head, elm, field) do { \
(elm)->field.stqe_next = NULL; \
*(head)->stqh_last = (elm); \
(head)->stqh_last = &(elm)->field.stqe_next; \
} while (/*CONSTCOND*/0)
#define STAILQ_INSERT_AFTER(head, listelm, elm, field) do { \
if (((elm)->field.stqe_next = (listelm)->field.stqe_next) == NULL) \
(head)->stqh_last = &(elm)->field.stqe_next; \
(listelm)->field.stqe_next = (elm); \
} while (/*CONSTCOND*/0)
#define STAILQ_REMOVE_HEAD(head, field) do { \
if (((head)->stqh_first = (head)->stqh_first->field.stqe_next) == NULL) \
(head)->stqh_last = &(head)->stqh_first; \
} while (/*CONSTCOND*/0)
#define STAILQ_REMOVE(head, elm, type, field) do { \
if ((head)->stqh_first == (elm)) { \
STAILQ_REMOVE_HEAD((head), field); \
} else { \
struct type *curelm = (head)->stqh_first; \
while (curelm->field.stqe_next != (elm)) \
curelm = curelm->field.stqe_next; \
if ((curelm->field.stqe_next = \
curelm->field.stqe_next->field.stqe_next) == NULL) \
(head)->stqh_last = &(curelm)->field.stqe_next; \
} \
} while (/*CONSTCOND*/0)
#define STAILQ_FOREACH(var, head, field) \
for ((var) = ((head)->stqh_first); \
(var); \
(var) = ((var)->field.stqe_next))
#define STAILQ_CONCAT(head1, head2) do { \
if (!STAILQ_EMPTY((head2))) { \
*(head1)->stqh_last = (head2)->stqh_first; \
(head1)->stqh_last = (head2)->stqh_last; \
STAILQ_INIT((head2)); \
} \
} while (/*CONSTCOND*/0)
/*
* Singly-linked Tail queue access methods.
*/
#define STAILQ_EMPTY(head) ((head)->stqh_first == NULL)
#define STAILQ_FIRST(head) ((head)->stqh_first)
#define STAILQ_NEXT(elm, field) ((elm)->field.stqe_next)
上面的宏定义看起来很复杂,但我们只需要记住宏定义的本质就是替换,就不难理解上述代码。
我们在这里需要使用的仅有下面几个定义
- TAILQ_HEAD 定义头节点结构
- TAILQ_ENTRY 定义链表的前后指针结构体
- TAILQ_INIT 链表初始化
- TAILQ_INSERT_TAIL 在表尾插入节点
- TAILQ_REMOVE 删除任意节点
- TAILQ_EMPTY 链表判空
代码实现
参照我们之前的代码,我们使用如下方式定义链表节点的结构体。
typedef struct EntNode
{
TAILQ_ENTRY(EntNode) field;
struct dirent ent;
char path[MAX_FILENAME_LENGTH];
}EntNode;
typedef TAILQ_HEAD(Head, EntNode) Head;
可以看到,结构体中自己定义的成员不变,只是将前后指针换成了系统定义的宏。
判断链表为空的函数也做出更改
static int isEmpty(Head* head)
{
return TAILQ_EMPTY(head);
}
我们用链表实现的是队列,因此插入节点需要在尾部插入,弹出节点要在首部弹出。我们只需要将之前代码中有关链表指针的操作替换为系统定义的宏函数即可,非常简单。
static int push(Head* head, struct dirent ent, char* dirPath)
{
EntNode* node = (EntNode*)malloc(sizeof(EntNode));
if (node == NULL) return 0;
node->ent = ent;
strcpy(node->path, dirPath);
TAILQ_INSERT_TAIL(head, node, field);
return 1;
}
static int pop(Head* head, struct EntNode* node)
{
if (isEmpty(head)) return 0;
EntNode* tmp = head->tqh_first;
*node = *tmp;
TAILQ_REMOVE(head, tmp, field);
free(tmp);
return 1;
}
优化:在之前的代码中,我们将一个目录下的所有元素都加入队列,无论该对象是文件还是目录。但我们只需要将目录加入队列即可,对访问到的文件直接进行我们想要做的操作即可。从而大大减少了队列的长度,减少了不必要的空间分配。但这样做的结果就是,我们的遍历顺序不再是严格的宽度优先遍历。因为遇到文件后,不再加入队列,而是直接访问。
为此我们将原来的pushAll函数修改为pushDir函数,使其仅将目录加入队列,而对文件直接进行我们想要的操作。同时将生成目标路径的代码封装为一个函数genTargetPath
static int genTargetPath(char* orignPath, char* newName, char* targetPath)
{
// 判断目标路径是否过长
if (strlen(orignPath) + strlen(newName) + 1 >= MAX_FILENAME_LENGTH)
{
return ENAMETOOLONG;
}
// 拼接出目标目录的路径
sprintf(targetPath, "%s%c%s", orignPath, FILE_SEPERATOR, newName);
return 0;
}
// 将dirPath下的所有目录加入队列
static int pushDir(char* dirPath, Head* head)
{
// Bad address
if (!dirPath || !strlen(dirPath))
{
return EFAULT;
}
// 获得目录结构体指针
DIR* pDir = opendir(dirPath);
if (pDir == NULL)
{
return EFAULT;
}
// 遍历该目录下元素
struct dirent* ent = readdir(pDir);
int err = 0;
while (ent)
{
if (strcmp(ent->d_name, ".") == 0 || strcmp(ent->d_name, "..") == 0)
{
ent = readdir(pDir);
continue;
}
char targetPath[MAX_FILENAME_LENGTH];
err = genTargetPath(dirPath, ent->d_name, targetPath);
if (err) break;
// 目录,加入队列
if (ent->d_type == DT_DIR)
{
if (!push(head, *ent, dirPath))
{
err = ENOBUFS;
break;
}
}
// 文件,回调walk_cb
else if (ent->d_type == DT_REG)
{
// TODO
}
memset(targetPath, 0, MAX_FILENAME_LENGTH);
ent = readdir(pDir);
}
closedir(pDir);
return err;
}
最终的dirWalk函数如下
int dirWalk(char* dirpath)
{
if (walk_cb == NULL) return 0;
// 创建队列
Head head;
TAILQ_INIT(&head);
// 将当前目录下所有对象加入队列
int err = pushDir(dirpath, &head);
if (err) return err;
// 不断读取队列,直至队列为空
struct EntNode node;
while (!isEmpty(&head))
{
pop(&head, &node);
char targetPath[MAX_FILENAME_LENGTH];
err = genTargetPath(node.path, node.ent.d_name, targetPath);
if (err) break;
// 目录,将该目录下的所有目录加入队列
if (node.ent.d_type == DT_DIR)
{
err = pushDir(targetPath, &head);
if (err != 0) break;
}
memset(targetPath, 0, MAX_FILENAME_LENGTH);
}
return err;
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









