







注:内容参考王道2024考研复习指导以及《数据结构》
*串的定义和实现
串的定义
串,即字符串(String)是由零个或多个字符组成的有限序列。一般记为 S = ′ a 1 a 2 . . . a n ′ ( n ≥ 0 ) S='a_1a_2 ...a_n'(n \geq 0) S=′a1a2...an′(n≥0)
其中,S是串名,单引号括起来的字符序列是串的值, a i a_i ai可以是字母。数字或其他字符;串中字符的个数n称为串的长度。n=0时的串称为空串。
名词概念:
- 子串:串中任意个连续的字符组成的子序列。
- 主串:包含子串的串。
- 字符在主串中的位置:字符在串中的序号。
- 子串在主串中的位置:子串的第一个字符在主串中的位置。
注:在不同的编程语言中,串可以使用单引号或者双引号;位序从1开始而不是从0开始;空串不同于空格串,空格串不是空串。
串与线性表的比较
串是一种特殊的线性表,元素之间称线性关系。
串的数据对象限定为字符集(如中文字符、英文字符、数字字符、标点字符等)。
串的基本操作,如增删改查等通常以子串为操作对象。
串的存储结构
串的顺序存储
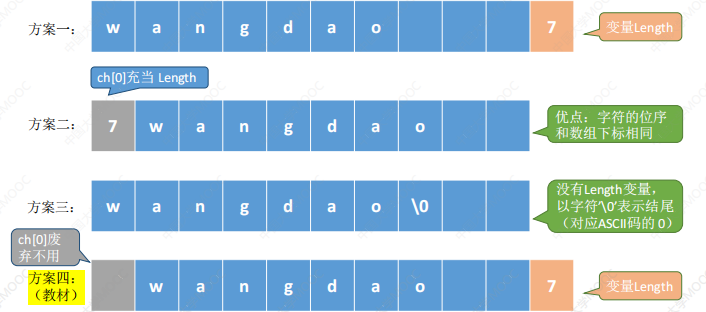
#define MaxLen 255
{//静态数组实现
typedef struct{
char ch[MaxLen];
int length;
}SString;
}
{//动态数组实现
typedef struct{
char *ch;
int length;
}HString;
HString S;
S.ch=(HString *)malloc(MaxLen*sizeof(HSring));
S.length=0;
}
不同方案的内存空间如下:
串的链式存储
typedef struct StringNode{
char ch;
struct StringNode *next;
}StringNode,*String;

typedef struct StringNode{
char ch[4];
struct StringNode *next;
}StringNode,*String;

串的基本操作
StrAssign(&T,chars):赋值操作。把串T赋值为chars。
StrCopy(&T,S):复制操作。由串s复制得到串T。
StrEmpty(S):判空操作。若s为空串,则返回TRUE,否则返回FALSE。
StrLength(S):求串长。返回串s的元素个数。
ClearString(&S):清空操作。将s清为空串。
DestroyString(&S):销毁串。将串s销毁(回收存储空间)
Concat(&T,S1,S2):串联接。用T返回由S1和S2联接而成的新串
SubString(&Sub,S,pos,len):求子串。用sub返回串s的第pos个字符起长度为len的子串。
Index(S,T):定位操作。若主串s中存在与串T值相同的子串,则返回它在主串s中第一次出现的位置,否则函数值为0。
StrCompare(S,T):比较操作。若S>T,则返回值>O;若S=T,则返回值=O;若S<T,则返回值<0。
求子串
bool SubString(SString &Sub,SString S,int pos,int len){//用Sub返回串S的第pos个字符起长度为len的子串。
if(pos+len-1>S.length){
return false;
}
for(int i=pos;i<pos+len;i++){
Sub.ch[i-pos+1]=S.ch[i];
}
Sub.length=len;
return 0;
}
比较操作
int StrCompare(SString S,SString T){//若S>T,则返回值>0;若S=T,则返回值=0;若S<T,则返回值<0。
for(int i=1;i<S.length && i<T.length;i++){
if(S.ch[i]!=T.ch[i]){
return false;
}
}
return S.length-T.length;
}
定位操作
int Index(SString S,SString T){//若主串S中存在与串T值相同的子串,则返回它在主串S中第一次出现的位置;否则函数值为0。
int i=1,n=StrLength(S),m=StrLength(T);
SString sub;
while(i<n-m+1){
SubString(sub,S,i,m);
if(StrCompare(sub,T) != 0){
i++;
}else {
return i;
}
return 0;
}
}
串的模式匹配
字符串模式匹配:在主串中找到与模式串相同的⼦串,并返回其所在位置。
子串——主串的一部分,一定存在。
模式串——不一定能在主串中找到。
朴素模式匹配算法(BF算法)
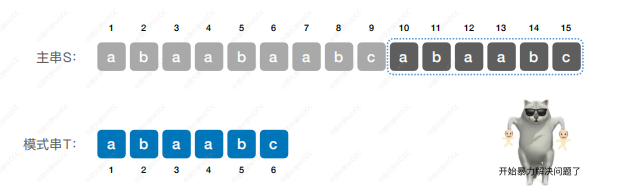
朴素模式匹配算法:将主串中所有长度为m的子串依次与模式串对比,直到找到⼀个完全匹配的子串,或所有的子串都不匹配为止。
int Index(SString S,SString T){
int i=1,j=1;
while(i<=S.length && j<=T.length){
if(S.ch[i]==T.ch[j]){
i++;
j++;
}else{//当前⼦串匹配失败,则主串指针 i 指向下⼀个⼦串的第⼀个位置,模式串指针 j 回到模式串的第⼀个位置
i=i-j+2;
j=1;
}
if(j>T.length){
return i-T.length;//当前⼦串匹配成功,返回当前⼦串第⼀个字符的位置i - T.length
}else{
return 0;
}
}
}
设主串⻓度为 n,模式串⻓度为 m,则最坏时间复杂度 = O(nm)。
最坏的情况,n >> m,每个子串都要对比 m 个字符,共 n-m+1 个⼦串,复杂度 = O((n-m+1)m) = O(nm)
串的模式匹配算法——KMP算法
字符串的前缀、后缀和部分匹配值
前缀指除最后一个字符以外,字符串的所有头部子串
后缀指除第一个字符外,字符串的所有尾部子串
部分匹配值则为字符串的前缀和后缀的最长相等前后缀长度
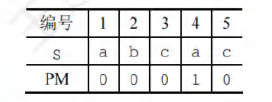
下面以ababa为例进行说明:
- 'a’的前缀和后缀都为空集,最长相等前后缀长度为0。
- 'ab’的前缀为{a},后缀为{b},{a}n{b}=0,最长相等前后缀长度为0。
- 'aba’的前缀为{a,ab},后缀为{a,ba},{a,ab}n{a,ba}={a),最长相等前后缀长度为1。
- 'abab’的前缀{a,ab,aba}n后缀{b,ab,bab}={ab},最长相等前后缀长度为2。
- 'ababa’的前缀{a,ab,aba,abab}n后缀{a,ba,aba,baba}={a,aba},公共元素有两个,最长相等前后缀长度为3。
KMP算法
利用已经部分匹配的结果而加快模式串的滑动速度,且主串S的指针i不必回溯,可提速到O(n+m)。
n e x t [ j ] next[j] next[j]:表明当模式中第j个字符与主串中相应字符“失配”时,在模式中需重新和主串中该字符进行比较的字符的位置。
int Index_KMP(SString S,SString T,int next[]){
int i=1,j=1;
while(i<=S.length && j<=T.length){
if(j==0 || S.ch[i]==T.ch[j]){
i++;
j++;
}else{//模式串回溯,但主串指针不回溯
j=next[j];
}
if(j>T.length){
return i-T.length;//当前⼦串匹配成功,返回当前⼦串第⼀个字符的位置i - T.length
}else{
return 0;
}
}
}
设主串s的长度为n,模式串t长度为m,在KMP算法中求next数组的时间复杂度为O(m),在后面的匹配中因主串s的下标不减即不回溯,比较次数可记为n,所以KMP算法总的时间复杂度为O(n+m)。
计算next数组
手算思路(给出主串时)
next[1]都⽆脑写0;next[2]都⽆脑写1;其他 next,在不匹配的位置前,划⼀根美丽的分界线,模式串⼀步⼀步往后退,直到分界线之前“能对上”,或模式串完全跨过分界线为⽌。此时 j 指向哪⼉,next数组值就是多少。
手算思路(部分匹配值)
根据上文部分匹配值的计算方法,算出PM表,将PM表右移一位,在整体+1,得到next数组。
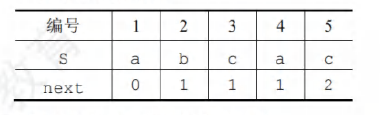
函数公式

代码实现
void get_next(SString T,int &next[]){
int i=1,j=0;
next[1]=0;
while(i<T.length){
if(j==0 || T.ch[i]==T.ch[j]){
i++;
j++;
next[i]=j;
}else{
j=next[j];
}
}
}
KMP算法的近一步优化
如果当前字符与其next数组指向的字符相同,则当前字符的next指针值可以更改为其指向的字符的next值。
代码实现
void get_next(SString T,int &nextval[]){
int i=1,j=0;
next[1]=0;
while(i<T.length){
if(j==0 || T.ch[i]==T.ch[j]){
i++;
j++;
if(T.ch[i] != T.ch[j]){
nextval[i]=j;
}else{
nextval[i]=nextval[j];
}
}else{
j=nextval[j];
}
}
}
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









