







 本文以KingbaseES为例介绍分区表用法。先阐述创建分区表的两种基本语法,包括一级和二级分区;接着介绍范围、列表、哈希三种分区类型及具体分区方式;最后说明利用EXTRACT提取年份的应用场景,并对比分区表与普通表性能,指出分区表在大数据量无索引时性能优势明显。
本文以KingbaseES为例介绍分区表用法。先阐述创建分区表的两种基本语法,包括一级和二级分区;接着介绍范围、列表、哈希三种分区类型及具体分区方式;最后说明利用EXTRACT提取年份的应用场景,并对比分区表与普通表性能,指出分区表在大数据量无索引时性能优势明显。
数据库版本:KingbaseES V008R006C008B0014
简介
分区表是一种将大型数据库表拆分为更小、更可管理的部分的技术。它通过将表数据分散存储到多个物理存储单元中,可以提高查询和数据维护的性能,并优化对大型数据集的处理。本篇文章以kingbase为例介绍分区表的用法。
文章目录如下
1. 基本语法
1.1. 语法一
1.1.1. 一级分区
创建分区表有2种语法,第1种:在创建普通表后面加上指定的分区信息。
CREATE TABLE 表名
(
列名1 数据类型,
列名2 数据类型,
...
)
PARTITION BY RANGE (分区键) --要分区的列名
(
PARTITION 分区名1 VALUES LESS THAN (分区值), --存储的范围
PARTITION 分区名2 VALUES LESS THAN (分区值), --存储的范围
...
);
举个例子:创建一张列表分区,将性别分区存储
CREATE TABLE p1 (
id int,
name varchar(64),
sex varchar(4)
)
PARTITION BY LIST(sex) --指定sex列分区
(
PARTITION boy VALUES ('男'), --sex为男的数据存储到该分区
PARTITION girl VALUES ('女') --sex为女的数据存储到该分区
);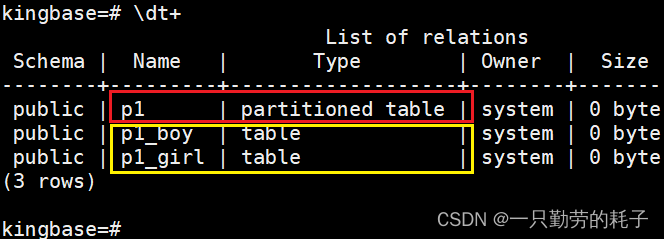
创建完成后包含一张分区表和n张子分区表。
此时向分区表插入3条数据
INSERT INTO
p1
VALUES
(1, '小李', '男'),
(2, '小张', '女'),
(3, '小王', '男');查询主表:存在3条数据
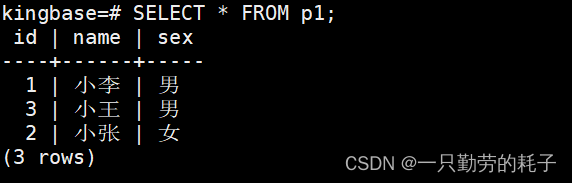
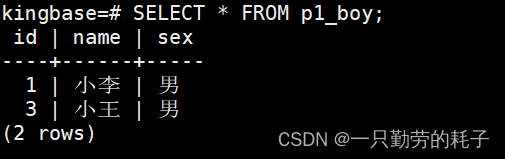
查询分区表p1_boy:存储性别为"男"的数据
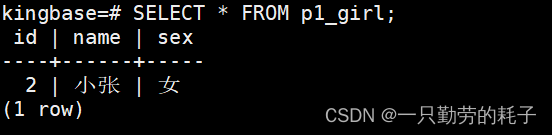
查询分区表p1_girl:存储性别为"女"的数据
总结
分区表利用不同的列数据来分别存储,插入数据后不同的子分区根据自己的规则存储不同的数据。主分区可以查询所有数据,子分区只包含规则内的数据。
1.1.2. 二级分区
《目录1.1》描述了如何创建一个分区表(一级分区),而真实场景会使得一级分区覆盖度远远不够,所以需要使用二级分区,语法如下:
CREATE TABLE 表名(
列名 数据类型
)
PARTITION BY RANGE (一级分区键) --指定一级分区
SUBPARTITION BY RANGE (二级分区键) --指定二级分区
(
PARTITION 一级分区名 VALUES LESS THAN (分区值)
(
SUBPARTITION 二级分区名 VALUES LESS THAN (分区值)
)
);- PARTITION BY:普通分区语法
- SUBPARTITION BY:子分区语法
注意:KingbasES的MySQL、Oracle模式最大支持二级分区,PG模式无限层级。
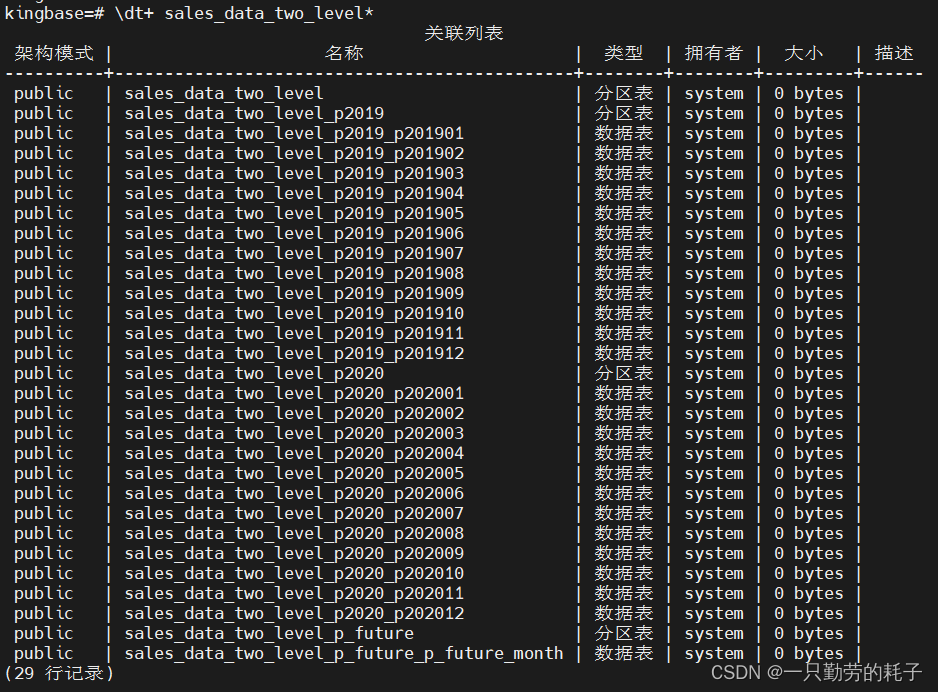
举个例子,年份作为一级分区、月份作为二级分区
CREATE TABLE sales_data_two_level (
sale_date DATE, --销售日期
amount DECIMAL(10,2) --销售金额
)
PARTITION BY RANGE (sale_date) --将销售日期分区
SUBPARTITION BY RANGE (sale_date) --作一级分区
(
/*一级分区为2020-01-01以前*/
PARTITION p2019 VALUES LESS THAN ('2020-01-01')
(
/*二级分区,按月份分区*/
SUBPARTITION p201901 VALUES LESS THAN ('2019-02-01'),
SUBPARTITION p201902 VALUES LESS THAN ('2019-03-01'),
SUBPARTITION p201903 VALUES LESS THAN ('2019-04-01'),
SUBPARTITION p201904 VALUES LESS THAN ('2019-05-01'),
SUBPARTITION p201905 VALUES LESS THAN ('2019-06-01'),
SUBPARTITION p201906 VALUES LESS THAN ('2019-07-01'),
SUBPARTITION p201907 VALUES LESS THAN ('2019-08-01'),
SUBPARTITION p201908 VALUES LESS THAN ('2019-09-01'),
SUBPARTITION p201909 VALUES LESS THAN ('2019-10-01'),
SUBPARTITION p201910 VALUES LESS THAN ('2019-11-01'),
SUBPARTITION p201911 VALUES LESS THAN ('2019-12-01'),
SUBPARTITION p201912 VALUES LESS THAN ('2020-01-01')
),
/*一级分区,2020-01-01 ~ 2020-12-31*/
PARTITION p2020 VALUES LESS THAN ('2021-01-01')
(
/*二级分区,按月份分区*/
SUBPARTITION p202001 VALUES LESS THAN ('2020-02-01'),
SUBPARTITION p202002 VALUES LESS THAN ('2020-03-01'),
SUBPARTITION p202003 VALUES LESS THAN ('2020-04-01'),
SUBPARTITION p202004 VALUES LESS THAN ('2020-05-01'),
SUBPARTITION p202005 VALUES LESS THAN ('2020-06-01'),
SUBPARTITION p202006 VALUES LESS THAN ('2020-07-01'),
SUBPARTITION p202007 VALUES LESS THAN ('2020-08-01'),
SUBPARTITION p202008 VALUES LESS THAN ('2020-09-01'),
SUBPARTITION p202009 VALUES LESS THAN ('2020-10-01'),
SUBPARTITION p202010 VALUES LESS THAN ('2020-11-01'),
SUBPARTITION p202011 VALUES LESS THAN ('2020-12-01'),
SUBPARTITION p202012 VALUES LESS THAN ('2021-01-01')
),
/*一级分区,存储2020-12-31以后的数据*/
PARTITION p_future VALUES LESS THAN (MAXVALUE)
(
SUBPARTITION p_future_month VALUES LESS THAN (MAXVALUE)
)
);
1.2. 语法二
1.2.1. 一级分区
- 这种语法来自于PG语法,与上述类似,将分区表和子分区分开创建。
创建范围分区
--创建范围分区表
CREATE TABLE t1(
id int
) PARTITION BY RANGE(id);
--创建子分区,将1~4的数值存储到t1_p1
CREATE TABLE t1_p1 PARTITION OF t1 FOR VALUES FROM(1) TO (5);
--创建子分区,将大于4的数值存储到t1_max
CREATE TABLE t1_max PARTITION OF t1 FOR VALUES FROM(5) TO (maxvalue);
创建列表分区
--创建列表分区表
CREATE TABLE t1(
id int,
sex varchar(4)
) PARTITION BY LIST(sex);
--创建子分区,将性别为男存储到t1_boy
CREATE TABLE t1_boy PARTITION OF t1 FOR VALUES IN ('男');
--创建子分区,将性别为女存储到t1_girl
CREATE TABLE t1_girl PARTITION OF t1 FOR VALUES IN ('女');
创建哈希分区
--创建列表分区表
CREATE TABLE t1(
id int
) PARTITION BY HASH(id);
--创建子分区,存储模为3余数为0的数据
CREATE TABLE t1_h1 PARTITION OF t1 FOR VALUES WITH(modulus 3, remainder 0);
1.2.2. 二级分区
二级分区在一级分区的基础上增加
CREATE TABLE p1 (
id int,
name varchar(64),
sex varchar(4)
)
PARTITION BY LIST(sex); --指定sex列分区
--创建一级子分区,将id列指定为范围分区
CREATE TABLE p1_boy PARTITION OF p1 FOR VALUES IN ('男') PARTITION BY RANGE(id);
--创建二级子分区,目标表为p1_boy(作为它的二级分区),分区数据为id列1~10
CREATE TABLE p1_boy_id10 PARTITION OF p1_boy FOR VALUES FROM (1) TO (11) ;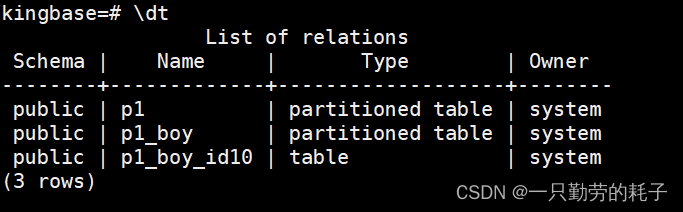
创建多个子分区根据上述语法继续写,例如:
--创建一级子分区
CREATE TABLE p1_girl PARTITION OF p1 FOR VALUES IN ('女') PARTITION BY RANGE(id);
--创建二级子分区
CREATE TABLE p1_girl_id10 PARTITION OF p1_girl FOR VALUES FROM (1) TO (11) ;
--创建二级子分区
CREATE TABLE p1_girl_id_max PARTITION OF p1_girl FOR VALUES FROM (11) TO (MAXVALUE) ;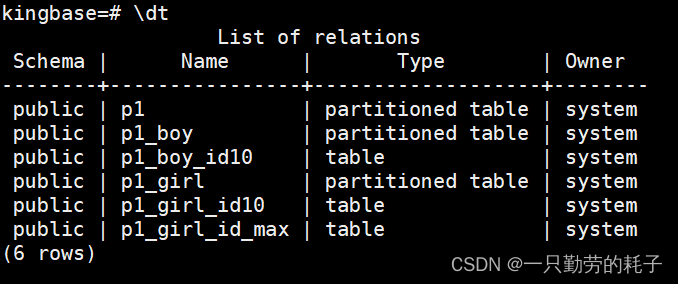
2. 分区类型
在目录1中理解了如何创建分区,那么分区的类型在这一目录介绍,包括:
- 范围分区:数值范围、日期范围等。
- 列表分区:固定列表值,如['北京', '上海']。
- 哈希分区:基于用户指定分区键上的哈希算法,自动将各个分区中均匀分布。
它们的语法在 PARTITION BY 后面
PARTITION BY RANGE(分区键) --范围分区
PARTITION BY LIST(分区键) --列表分区
PARTITION BY HASH(分区键) --哈希分区
2.1. 范围分区
范围分区是根据列的范围值将表数据分布到不同的分区中,常见的日期范围、数值范围等。
语法:
PARTITION BY RANGE (列名)(
PARTITION 分区名 VALUES LESS THAN (范围)
)2.1.1. 按金额范围分区
CREATE TABLE orders1 (
order_id INT PRIMARY KEY, --订单ID
order_date DATE, --订单日期
customer_id INT, --客户ID
total_amount DECIMAL(10, 2) --总金额
)
PARTITION BY RANGE (total_amount) ( --将总金额分区
PARTITION p_1 VALUES LESS THAN (1000), --存储<1000
PARTITION p_2 VALUES LESS THAN (10000), --存储<1w
PARTITION p_3 VALUES LESS THAN (100000), --存储<10w
PARTITION p_max VALUES LESS THAN (MAXVALUE) --存储>=10w
);p_1范围:0~999
p_2范围:1000~9999
p_3范围:10000~99999
p_max范围:100000~最大值
2.1.2. 按日期分区
CREATE TABLE sales_orders (
order_id INT PRIMARY KEY, --订单ID
order_date DATE, --订单日期
customer_id INT, --客户ID
total_amount DECIMAL(10, 2) --总金额
)
PARTITION BY RANGE (order_date) ( --将订单日期分区
PARTITION p2019 VALUES LESS THAN ('2020-01-01'),
PARTITION p2020 VALUES LESS THAN ('2021-01-01'),
PARTITION p2021 VALUES LESS THAN ('2022-01-01'),
PARTITION p2022 VALUES LESS THAN ('2023-01-01'),
PARTITION p_max VALUES LESS THAN (MAXVALUE)
);p2019范围:2020以前
p2020范围:2020年日期
p2021范围:2021年日期
p2022范围:2022年日期
p_max范围:2023年~以后
2.1.3. 自动创建日期分区
CREATE TABLE sales_orders (
order_id INT PRIMARY KEY, --订单ID
order_date DATE, --订单日期
customer_id INT, --客户ID
total_amount DECIMAL(10, 2) --总金额
)
PARTITION BY RANGE (order_date) INTERVAL('3 MONTH'::INTERVAL) --自动创建
(
PARTITION p1 VALUES LESS THAN ('2020-01-01') --小于等于2020-01-01存储到p1
);p1存储2020-01-01以前的数据,后面插入的数据每隔3个月自动创建分区
- '1 YEAR':每隔1年创建一个分区
- '1 MONTH':每个1个月创建一个分区
- '1 DAY':每个1天创建一个分区
2.1.4. 自动创建整数分区
CREATE TABLE sales_orders (
order_id INT PRIMARY KEY, -- 订单ID
order_date DATE, -- 订单日期
customer_id INT, -- 客户ID
total_amount DECIMAL(10, 2) -- 总金额
)
PARTITION BY RANGE (order_id)INTERVAL('1000'::BIGINT) --自动创建
(
PARTITION p0 VALUES LESS THAN (0) --小于等于0存储到p0
);- '1000'::BIGINT:数字每增长1000自动创建1个分区,也就是说插入 order_id 列 2000 后自动创建1个分区,3000、4000...同理。
2.2. 列表分区
列表分区不同于范围,而是将每个分区基于列值的列表。比如指定列表为 ('aa', 'bb'),那么只会将该列为 aa 或 bb 值存储到指定分区中。
语法:
PARTITION BY LIST (列名)(
PARTITION 分区名 VALUES ('固定值1', '固定值2'),
)2.2.1. 按日志级别分区
CREATE TABLE log_entries (
log_id SERIAL PRIMARY KEY, --日志ID
log_message TEXT, --日志信息
log_date TIMESTAMP, --日志日期
log_type VARCHAR(50) --日志类型
)
PARTITION BY LIST (log_type) --将日志类型分区
(
PARTITION type_error VALUES ('ERROR', 'CRITICAL'),
PARTITION type_warning VALUES ('WARNING'),
PARTITION type_info VALUES ('INFO', 'DEBUG')
);- 将 'ERROR'、'CRITICAL' 存储到 type_error 中
- 将 'WARNING' 存储到 type_warning
- 将 'INFO'、'DEBUG' 存储到 type_info 中
- 其他类型无法插入
2.2.2. 按地区分区
CREATE TABLE sales_orders (
order_id SERIAL PRIMARY KEY, --订单ID
order_date DATE, --订单日期
customer_id INT, --客户ID
total_amount DECIMAL(10, 2), --总金额
region VARCHAR(50) --地区
)
PARTITION BY LIST (region)
(
PARTITION First_tier VALUES ('北京', '上海', '广州', '深圳'),
PARTITION second_tier VALUES ('天津', '南京', '杭州', '成都'),
PARTITION third_tier VALUES ('哈尔滨', '福州', '长春', '石家庄')
);- 将一线城市分区到 First_tier
- 将二线城市分区到 second_tier
- 将三线城市分区到 third_tier
2.3. 哈希分区
哈希分区是基于用户指定分区键上的哈希算法,数据库自动将各个分区中均匀分布,可用于划分大表,提高可管理性。当查询需要扫描整个表时,数据在各个分区上分布均匀,可以有效地利用并行查询来加速查询操作,提高查询性能。例如:将一张频繁更新的表创建为哈希分区,一张表被分为几个部分后,则这几个分区可以被同时更新,以减少锁冲突次数。
语法:
PARTITION BY HASH (列名) PARTITIONS 分区数;
2.3.1. 按用户ID分区
CREATE TABLE users (
user_id INT PRIMARY KEY, --用户ID
username VARCHAR(50), --用户名
email VARCHAR(100) --用户邮箱
) PARTITION BY HASH (user_id) PARTITIONS 4; --将用户ID分4个区- PARTITIONS 4:表示分4个区
2.3.2. 按订单号分区
CREATE TABLE product_orders (
order_id INT PRIMARY KEY, --订单ID
product_id INT, --产品ID
quantity INT, --产品数量
order_date DATE --订单日期
) PARTITION BY HASH (order_id) PARTITIONS 8; --将订单ID分8个区- PARTITIONS 8:表示分8个区
2.3.3. 自定义hash模
CREATE TABLE t1(
id INT
) PARTITION BY HASH (id);
CREATE TABLE t1_hash_m3_r0 PARTITION OF t1 FOR VALUES WITH(modulus 3, remainder 0);
CREATE TABLE t1_hash_m3_r1 PARTITION OF t1 FOR VALUES WITH(modulus 3, remainder 1);
CREATE TABLE t1_hash_m3_r2 PARTITION OF t1 FOR VALUES WITH(modulus 3, remainder 2);创建完成后会存在如下4张表:

向 t1 表插入数值 3。按正常来讲 3 的模是0,应该插入到 t1_hash_m3_r0,实际上插入在 t1_hash_m3_r1 中
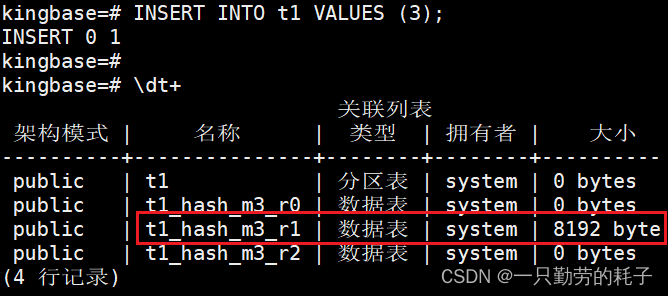
这里的模并不是平时数学中的模,是通过哈希算法得出的结果:
SELECT ora_hash(3, 3);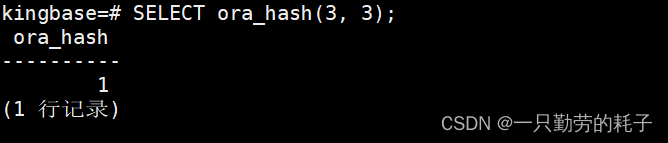
3. 应用场景
3.1. 利用EXTRACT提取年份
正常情况下创建一个日期分区
CREATE TABLE sales (
id SERIAL PRIMARY KEY, --销售ID
sale_date DATE --销售日期
) PARTITION BY RANGE (sale_date);
CREATE TABLE sales_2019 PARTITION OF sales FOR VALUES FROM ('2019-01-01') TO ('2020-01-01');
CREATE TABLE sales_2020 PARTITION OF sales FOR VALUES FROM ('2020-01-01') TO ('2021-01-01');
CREATE TABLE sales_2021 PARTITION OF sales FOR VALUES FROM ('2021-01-01') TO ('2022-01-01');- 自动将sale_date列2019年的数据存储到sales_2019表
- 自动将sale_date列2020年的数据存储到sales_2020表
- 自动将sale_date列2021年的数据存储到sales_2021表
利用EXTRACT函数创建年份分区(在创建子分区时可以简写)
CREATE TABLE sales (
id SERIAL PRIMARY KEY, --销售ID
sale_date DATE --销售日期
) PARTITION BY RANGE (EXTRACT(YEAR FROM sale_date));
CREATE TABLE sales_2019 PARTITION OF sales FOR VALUES FROM (2019) TO (2020);
CREATE TABLE sales_2020 PARTITION OF sales FOR VALUES FROM (2020) TO (2021);
CREATE TABLE sales_2021 PARTITION OF sales FOR VALUES FROM (2021) TO (2022);- 存储信息与案例一相同,写法不同
EXTRACT的各种用法
EXTRACT(类型 FROM 列名)
类型如下:/*
YEAR:提取年份部分
QUARTER:提取季度部分
MONTH:提取月份部分
DAY:提取日期中的天部分
HOUR:提取小时部分
MINUTE:提取分钟部分
SECOND:提取秒部分 */提取年份、季度、月份,在创建子分区时直接使用数值
CREATE TABLE sales (
id SERIAL PRIMARY KEY, --销售ID
sale_date DATE --销售日期
) PARTITION BY RANGE (
EXTRACT(YEAR FROM sale_date), --年份
EXTRACT(QUARTER FROM sale_date), --季度
EXTRACT(MONTH FROM sale_date) --月份
);
/*2020年子分区*/
CREATE TABLE sales_2020_q1_m1 PARTITION OF sales FOR VALUES FROM (2020, 1, 1) TO (2020, 1, 2);
CREATE TABLE sales_2020_q1_m2 PARTITION OF sales FOR VALUES FROM (2020, 1, 2) TO (2020, 1, 3);
CREATE TABLE sales_2020_q1_m3 PARTITION OF sales FOR VALUES FROM (2020, 1, 3) TO (2020, 1, 4);
CREATE TABLE sales_2020_q2_m4 PARTITION OF sales FOR VALUES FROM (2020, 2, 4) TO (2020, 2, 5);
CREATE TABLE sales_2020_q2_m5 PARTITION OF sales FOR VALUES FROM (2020, 2, 5) TO (2020, 2, 6);
CREATE TABLE sales_2020_q2_m6 PARTITION OF sales FOR VALUES FROM (2020, 2, 6) TO (2020, 2, 7);
CREATE TABLE sales_2020_q3_m7 PARTITION OF sales FOR VALUES FROM (2020, 3, 7) TO (2020, 3, 8);
CREATE TABLE sales_2020_q3_m8 PARTITION OF sales FOR VALUES FROM (2020, 3, 8) TO (2020, 3, 9);
CREATE TABLE sales_2020_q3_m9 PARTITION OF sales FOR VALUES FROM (2020, 3, 9) TO (2020, 3, 10);
CREATE TABLE sales_2020_q4_m10 PARTITION OF sales FOR VALUES FROM (2020, 4, 10) TO (2020, 4, 11);
CREATE TABLE sales_2020_q4_m11 PARTITION OF sales FOR VALUES FROM (2020, 4, 11) TO (2020, 4, 12);
CREATE TABLE sales_2020_q4_m12 PARTITION OF sales FOR VALUES FROM (2020, 4, 12) TO (2021, 1, 1);
/*2021年子分区*/
CREATE TABLE sales_2021_q1_m1 PARTITION OF sales FOR VALUES FROM (2021, 1, 1) TO (2021, 1, 2);
CREATE TABLE sales_2021_q1_m2 PARTITION OF sales FOR VALUES FROM (2021, 1, 2) TO (2021, 1, 3);
CREATE TABLE sales_2021_q1_m3 PARTITION OF sales FOR VALUES FROM (2021, 1, 3) TO (2021, 1, 4);
CREATE TABLE sales_2021_q2_m4 PARTITION OF sales FOR VALUES FROM (2021, 2, 4) TO (2021, 2, 5);
CREATE TABLE sales_2021_q2_m5 PARTITION OF sales FOR VALUES FROM (2021, 2, 5) TO (2021, 2, 6);
CREATE TABLE sales_2021_q2_m6 PARTITION OF sales FOR VALUES FROM (2021, 2, 6) TO (2021, 2, 7);
CREATE TABLE sales_2021_q3_m7 PARTITION OF sales FOR VALUES FROM (2021, 3, 7) TO (2021, 3, 8);
CREATE TABLE sales_2021_q3_m8 PARTITION OF sales FOR VALUES FROM (2021, 3, 8) TO (2021, 3, 9);
CREATE TABLE sales_2021_q3_m9 PARTITION OF sales FOR VALUES FROM (2021, 3, 9) TO (2021, 3, 10);
CREATE TABLE sales_2021_q4_m10 PARTITION OF sales FOR VALUES FROM (2021, 4, 10) TO (2021, 4, 11);
CREATE TABLE sales_2021_q4_m11 PARTITION OF sales FOR VALUES FROM (2021, 4, 11) TO (2021, 4, 12);
CREATE TABLE sales_2021_q4_m12 PARTITION OF sales FOR VALUES FROM (2021, 4, 12) TO (2022, 1, 1);
3.2. 分区表性能对比
- 简介中说到了分区表性能比普通表更好,这里直接举例说明
1、创建一张分区表,数据100w行,每个分区存储1w行,共100分区
--创建一个按数值自动分区的分区表,每1w行自动分1个区
CREATE TABLE t1 (
c1 INT,
c2 TEXT
)
PARTITION BY RANGE (c1)INTERVAL('10000'::BIGINT)
(
PARTITION p0 VALUES LESS THAN (0)
);
--插入100w行数据
INSERT INTO t1 VALUES(generate_series(1, 1000000), md5(random()));
2、创建一张普通表,数据100w行,结构与分区表一样
CREATE TABLE t2 (
c1 INT,
c2 TEXT
);
INSERT INTO t2 VALUES(generate_series(1, 1000000), md5(random()));
执行t1和t2的查询语句
explain analyze select * from t1 where c1 = 900000;
explain analyze select * from t2 where c1 = 900000;结果如下:
kingbase=# explain analyze select * from t1 where c1 = 900000;
QUERY PLAN
---------------------------------------------------------------------------------------------------
Seq Scan on t1_p91 (cost=0.00..210.00 rows=1 width=37) (actual time=0.020..0.777 rows=1 loops=1)
Filter: (c1 = 900000)
Rows Removed by Filter: 9999
Planning Time: 28.207 ms
Execution Time: 0.895 ms
(5 rows)
kingbase=# explain analyze select * from t2 where c1 = 900000;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------
Gather (cost=1000.00..14612.43 rows=1 width=37) (actual time=94.872..120.737 rows=1 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on t2 (cost=0.00..13612.33 rows=1 width=37) (actual time=31.346..35.375 rows=0 loops=3)
Filter: (c1 = 900000)
Rows Removed by Filter: 333333
Planning Time: 0.150 ms
Execution Time: 120.775 ms
(8 rows)如上:分区表成本 0.777,普通表成本 120.737。从100w数据耗时看,分区表性能是普通表的155倍,那么为什么性能提升这么多呢?
从t1表的扫描结果来看,查询的是 t1_p91 表,这张表仅存储1w行数据。而普通表t2扫描的是全表(100w行),相较之下,分区表自然快得多。
需要注意的是,这个例子没有索引,当加上索引后若非超大数据,分区表与普通表性能相差无几。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









