







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Web前端全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

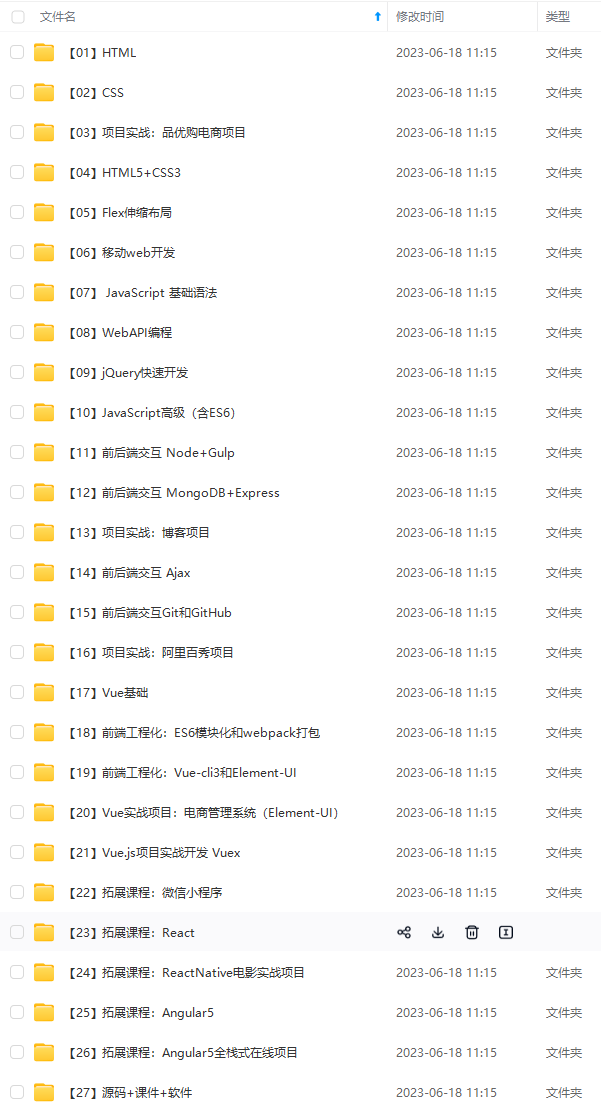
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注前端)

正文
var inherit = (function(c,p){
var F = function(){};
return function(c,p){
F.prototype = p.prototype;
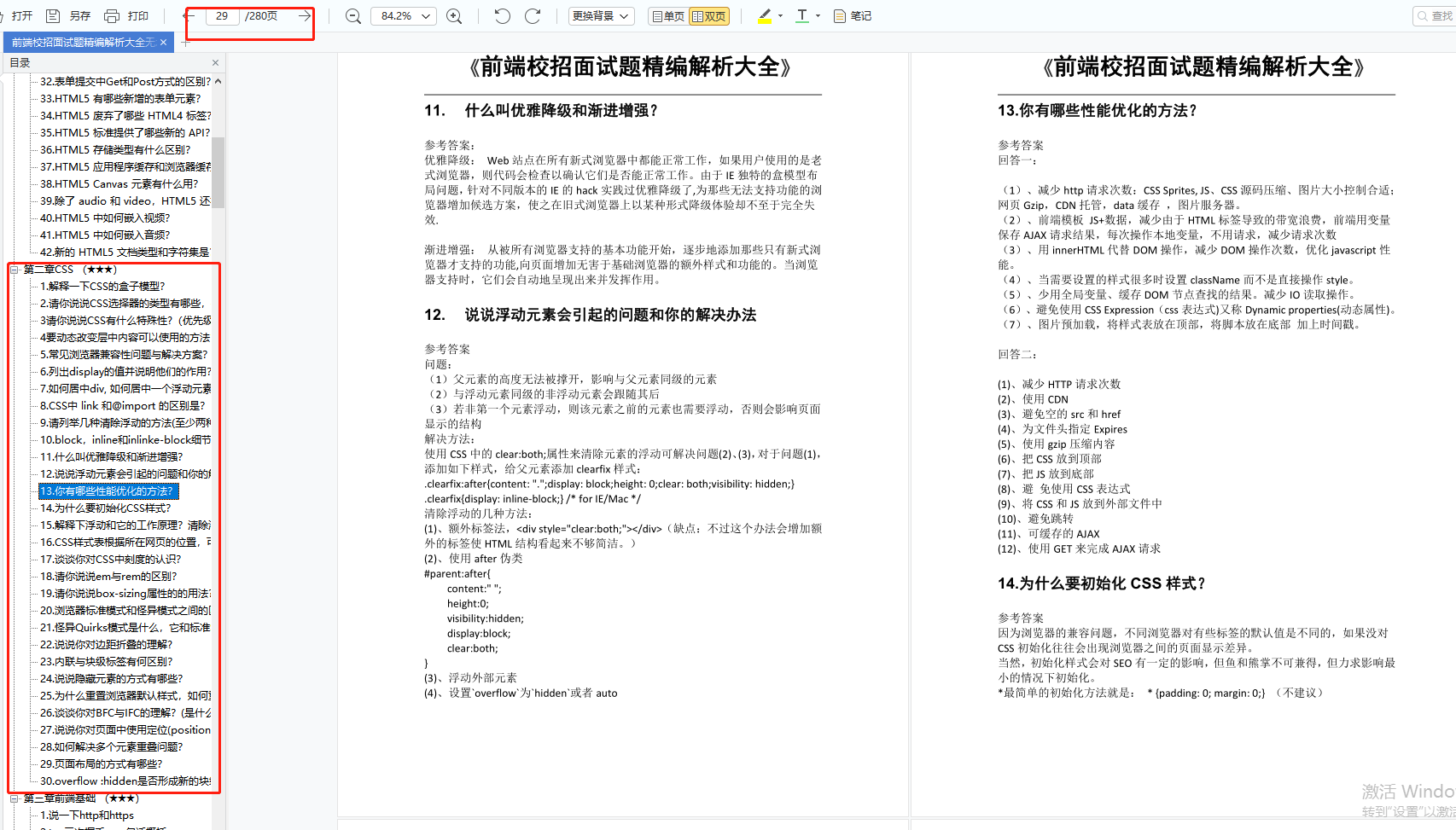
c.prototype = new F();
c.uber = p.prototype;
c.prototype.constructor = c;
}
})();
复制代码
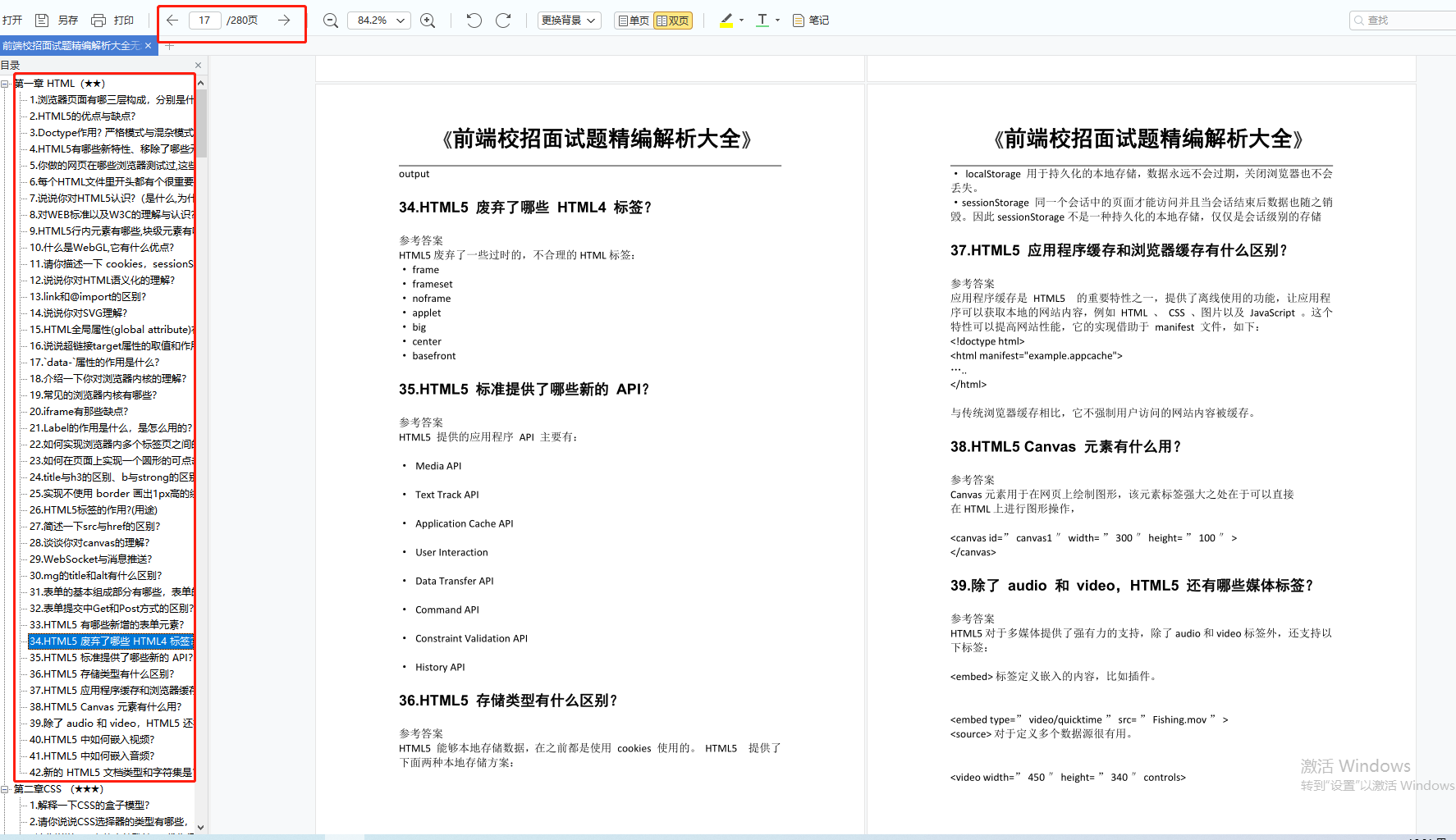
- 使用 ES6 的语法糖
class / extends
12. 类型转换
大家都知道 JS 中在使用运算符号或者对比符时,会自带隐式转换,规则如下:
-
-、*、/、% :一律转换成数值后计算
-
+:
-
数字 + 字符串 = 字符串, 运算顺序是从左到右
-
数字 + 对象, 优先调用对象的
valueOf->toString -
数字 +
boolean/null-> 数字 -
数字 +
undefined->NaN -
[1].toString() === '1' -
{}.toString() === '[object object]' -
NaN!==NaN、+undefined 为 NaN
13. 类型判断
判断 Target 的类型,单单用 typeof 并无法完全满足,这其实并不是 bug,本质原因是 JS 的万物皆对象的理论。因此要真正完美判断时,我们需要区分对待:
-
基本类型(
null): 使用String(null) -
基本类型(
string / number / boolean / undefined) +function: 直接使用typeof即可 -
其余引用类型(
Array / Date / RegExp Error): 调用toString后根据[object XXX]进行判断
很稳的判断封装:
let class2type = {}
‘Array Date RegExp Object Error’.split(’ ').forEach(e => class2type[ '[object ’ + e + ‘]’ ] = e.toLowerCase())
function type(obj) {
if (obj == null) return String(obj)
return typeof obj === ‘object’ ? class2type[ Object.prototype.toString.call(obj) ] || ‘object’ : typeof obj
}
复制代码
14. 模块化
模块化开发在现代开发中已是必不可少的一部分,它大大提高了项目的可维护、可拓展和可协作性。通常,我们 在浏览器中使用 ES6 的模块化支持,在 Node 中使用 commonjs 的模块化支持。
-
分类:
-
es6:
import / export -
commonjs:
require / module.exports / exports -
amd:
require / defined -
require与import的区别 -
require支持 动态导入,import不支持,正在提案 (babel 下可支持) -
require是 同步 导入,import属于 异步 导入 -
require是 值拷贝,导出值变化不会影响导入值;import指向 内存地址,导入值会随导出值而变化
15. 防抖与节流
防抖与节流函数是一种最常用的 高频触发优化方式,能对性能有较大的帮助。
- 防抖 (debounce): 将多次高频操作优化为只在最后一次执行,通常使用的场景是:用户输入,只需再输入完成后做一次输入校验即可。
function debounce(fn, wait, immediate) {
let timer = null
return function() {
let args = arguments
let context = this
if (immediate && !timer) {
fn.apply(context, args)
}
if (timer) clearTimeout(timer)
timer = setTimeout(() => {
fn.apply(context, args)
}, wait)
}
}
复制代码
- 节流(throttle): 每隔一段时间后执行一次,也就是降低频率,将高频操作优化成低频操作,通常使用场景: 滚动条事件 或者 resize 事件,通常每隔 100~500 ms执行一次即可。
function throttle(fn, wait, immediate) {
let timer = null
let callNow = immediate
return function() {
let context = this,
args = arguments
if (callNow) {
fn.apply(context, args)
callNow = false
}
if (!timer) {
timer = setTimeout(() => {
fn.apply(context, args)
timer = null
}, wait)
}
}
}
复制代码
16. 函数执行改变this
由于 JS 的设计原理: 在函数中,可以引用运行环境中的变量。因此就需要一个机制来让我们可以在函数体内部获取当前的运行环境,这便是this。
因此要明白 this 指向,其实就是要搞清楚 函数的运行环境,说人话就是,谁调用了函数。例如:
-
obj.fn(),便是obj调用了函数,既函数中的this === obj -
fn(),这里可以看成window.fn(),因此this === window
但这种机制并不完全能满足我们的业务需求,因此提供了三种方式可以手动修改 this 的指向:
-
call: fn.call(target, 1, 2) -
apply: fn.apply(target, [1, 2]) -
bind: fn.bind(target)(1,2)
17. ES6/ES7
由于 Babel 的强大和普及,现在 ES6/ES7 基本上已经是现代化开发的必备了。通过新的语法糖,能让代码整体更为简洁和易读。
-
声明
-
let / const: 块级作用域、不存在变量提升、暂时性死区、不允许重复声明 -
const: 声明常量,无法修改 -
解构赋值
-
class / extend: 类声明与继承 -
Set / Map: 新的数据结构 -
异步解决方案:
-
Promise的使用与实现 -
generator: -
yield: 暂停代码 -
next(): 继续执行代码
function* helloWorld() {
yield ‘hello’;
yield ‘world’;
return ‘ending’;
}
const generator = helloWorld();
generator.next() // { value: ‘hello’, done: false }
generator.next() // { value: ‘world’, done: false }
generator.next() // { value: ‘ending’, done: true }
generator.next() // { value: undefined, done: true }
复制代码
await / async: 是generator的语法糖, babel中是基于promise实现。
async function getUserByAsync(){
let user = await fetchUser();
return user;
}
const user = await getUserByAsync()
console.log(user)
复制代码
18. AST
抽象语法树 (Abstract Syntax Tree),是将代码逐字母解析成 树状对象 的形式。这是语言之间的转换、代码语法检查,代码风格检查,代码格式化,代码高亮,代码错误提示,代码自动补全等等的基础。例如:
function square(n){
return n * n
}
复制代码
通过解析转化成的AST如下图:

19. babel编译原理
-
babylon 将 ES6/ES7 代码解析成 AST
-
babel-traverse 对 AST 进行遍历转译,得到新的 AST
-
新 AST 通过 babel-generator 转换成 ES5
20. 函数柯里化
在一个函数中,首先填充几个参数,然后再返回一个新的函数的技术,称为函数的柯里化。通常可用于在不侵入函数的前提下,为函数 预置通用参数,供多次重复调用。
const add = function add(x) {
return function (y) {
return x + y
}
}
const add1 = add(1)
add1(2) === 3
add1(20) === 21
复制代码
21. 数组(array)
-
map: 遍历数组,返回回调返回值组成的新数组 -
forEach: 无法break,可以用try/catch中throw new Error来停止 -
filter: 过滤 -
some: 有一项返回true,则整体为true -
every: 有一项返回false,则整体为false -
join: 通过指定连接符生成字符串 -
push / pop: 末尾推入和弹出,改变原数组,push返回数组长度,pop返回原数组最后一项; -
unshift / shift: 头部推入和弹出,改变原数组,unshift返回数组长度,shift返回原数组第一项 ; -
sort(fn) / reverse: 排序与反转,改变原数组 -
concat: 连接数组,不影响原数组, 浅拷贝 -
slice(start, end): 返回截断后的新数组,不改变原数组 -
splice(start, number, value...): 返回删除元素组成的数组,value 为插入项,改变原数组 -
indexOf / lastIndexOf(value, fromIndex): 查找数组项,返回对应的下标 -
reduce / reduceRight(fn(prev, cur), defaultPrev): 两两执行,prev 为上次化简函数的return值,cur 为当前值 -
当传入
defaultPrev时,从第一项开始; -
当未传入时,则为第二项
-
数组乱序:
var arr = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
arr.sort(function () {
return Math.random() - 0.5;
});
复制代码
- 数组拆解: flat: [1,[2,3]] --> [1, 2, 3]
Array.prototype.flat = function() {
return this.toString().split(’,’).map(item => +item )
}
复制代码
1. 跨标签页通讯
不同标签页间的通讯,本质原理就是去运用一些可以 共享的中间介质,因此比较常用的有以下方法:
-
通过父页面
window.open()和子页面postMessage -
异步下,通过
window.open('about: blank')和tab.location.href = '*' -
设置同域下共享的
localStorage与监听window.onstorage -
重复写入相同的值无法触发
-
会受到浏览器隐身模式等的限制
-
设置共享
cookie与不断轮询脏检查(setInterval) -
借助服务端或者中间层实现
2. 浏览器架构
-
用户界面
-
主进程
-
内核
-
渲染引擎
-
JS 引擎
-
执行栈
-
事件触发线程
-
消息队列
-
微任务
-
宏任务
-
网络异步线程
-
定时器线程
3. 浏览器下事件循环(Event Loop)
事件循环是指: 执行一个宏任务,然后执行清空微任务列表,循环再执行宏任务,再清微任务列表
-
微任务
microtask(jobs):promise / ajax / Object.observe(该方法已废弃) -
宏任务
macrotask(task):setTimout / script / IO / UI Rendering
4. 从输入 url 到展示的过程
-
DNS 解析
-
TCP 三次握手
-
发送请求,分析 url,设置请求报文(头,主体)
-
服务器返回请求的文件 (html)
-
浏览器渲染
-
HTML parser --> DOM Tree
-
标记化算法,进行元素状态的标记
-
dom 树构建
-
CSS parser --> Style Tree
-
解析 css 代码,生成样式树
-
attachment --> Render Tree
-
结合 dom树 与 style树,生成渲染树
-
layout: 布局
-
GPU painting: 像素绘制页面
5. 重绘与回流
当元素的样式发生变化时,浏览器需要触发更新,重新绘制元素。这个过程中,有两种类型的操作,即重绘与回流。
-
重绘(repaint): 当元素样式的改变不影响布局时,浏览器将使用重绘对元素进行更新,此时由于只需要UI层面的重新像素绘制,因此 损耗较少
-
回流(reflow): 当元素的尺寸、结构或触发某些属性时,浏览器会重新渲染页面,称为回流。此时,浏览器需要重新经过计算,计算后还需要重新页面布局,因此是较重的操作。会触发回流的操作:
-
页面初次渲染
-
浏览器窗口大小改变
-
元素尺寸、位置、内容发生改变
-
元素字体大小变化
-
添加或者删除可见的 dom 元素
-
激活 CSS 伪类(例如::hover)
-
查询某些属性或调用某些方法
-
clientWidth、clientHeight、clientTop、clientLeft
-
offsetWidth、offsetHeight、offsetTop、offsetLeft
-
scrollWidth、scrollHeight、scrollTop、scrollLeft
-
getComputedStyle()
-
getBoundingClientRect()
-
scrollTo()
回流必定触发重绘,重绘不一定触发回流。重绘的开销较小,回流的代价较高。
最佳实践:
-
css
-
避免使用
table布局 -
将动画效果应用到
position属性为absolute或fixed的元素上 -
javascript
-
避免频繁操作样式,可汇总后统一 一次修改
-
尽量使用
class进行样式修改 -
减少
dom的增删次数,可使用 字符串 或者documentFragment一次性插入 -
极限优化时,修改样式可将其
display: none后修改 -
避免多次触发上面提到的那些会触发回流的方法,可以的话尽量用 变量存住
6. 存储
我们经常需要对业务中的一些数据进行存储,通常可以分为 短暂性存储 和 持久性储存。
-
短暂性的时候,我们只需要将数据存在内存中,只在运行时可用
-
持久性存储,可以分为 浏览器端 与 服务器端
-
浏览器:
-
cookie: 通常用于存储用户身份,登录状态等 -
http 中自动携带, 体积上限为 4K, 可自行设置过期时间
-
localStorage / sessionStorage: 长久储存/窗口关闭删除, 体积限制为 4~5M -
indexDB -
服务器:
-
分布式缓存 redis
-
数据库
7. Web Worker
现代浏览器为JavaScript创造的 多线程环境。可以新建并将部分任务分配到worker线程并行运行,两个线程可 独立运行,互不干扰,可通过自带的 消息机制 相互通信。
基本用法:
// 创建 worker
const worker = new Worker(‘work.js’);
// 向 worker 线程推送消息
worker.postMessage(‘Hello World’);
// 监听 worker 线程发送过来的消息
worker.onmessage = function (event) {
console.log('Received message ’ + event.data);
}
复制代码
限制:
-
同源限制
-
无法使用
document/window/alert/confirm -
无法加载本地资源
8. V8垃圾回收机制
垃圾回收: 将内存中不再使用的数据进行清理,释放出内存空间。V8 将内存分成 新生代空间 和 老生代空间。
-
新生代空间: 用于存活较短的对象
-
又分成两个空间: from 空间 与 to 空间
-
Scavenge GC算法: 当 from 空间被占满时,启动 GC 算法
-
存活的对象从 from space 转移到 to space
-
清空 from space
-
from space 与 to space 互换
-
完成一次新生代GC
-
老生代空间: 用于存活时间较长的对象
-
从 新生代空间 转移到 老生代空间 的条件
-
经历过一次以上 Scavenge GC 的对象
-
当 to space 体积超过25%
-
标记清除算法: 标记存活的对象,未被标记的则被释放
-
增量标记: 小模块标记,在代码执行间隙执,GC 会影响性能
-
并发标记(最新技术): 不阻塞 js 执行
-
压缩算法: 将内存中清除后导致的碎片化对象往内存堆的一端移动,解决 内存的碎片化
9. 内存泄露
-
意外的全局变量: 无法被回收
-
定时器: 未被正确关闭,导致所引用的外部变量无法被释放
-
事件监听: 没有正确销毁 (低版本浏览器可能出现)
-
闭包: 会导致父级中的变量无法被释放
-
dom 引用: dom 元素被删除时,内存中的引用未被正确清空
可用 chrome 中的 timeline 进行内存标记,可视化查看内存的变化情况,找出异常点。
1. http/https 协议
-
1.0 协议缺陷:
-
无法复用链接,完成即断开,重新慢启动和 TCP 3次握手
-
head of line blocking: 线头阻塞,导致请求之间互相影响
-
1.1 改进:
-
长连接(默认 keep-alive),复用
-
host 字段指定对应的虚拟站点
-
新增功能:
-
断点续传
-
身份认证
-
状态管理
-
cache 缓存
-
Cache-Control
-
Expires
-
Last-Modified
-
Etag
-
2.0:
-
多路复用
-
二进制分帧层: 应用层和传输层之间
-
首部压缩
-
服务端推送
-
https: 较为安全的网络传输协议
-
证书(公钥)
-
SSL 加密
-
端口 443
-
TCP:
-
三次握手
-
四次挥手
-
滑动窗口: 流量控制
-
拥塞处理
-
慢开始
-
拥塞避免
-
快速重传
-
快速恢复
-
缓存策略: 可分为 强缓存 和 协商缓存
-
Cache-Control/Expires: 浏览器判断缓存是否过期,未过期时,直接使用强缓存,Cache-Control的 max-age 优先级高于 Expires
-
当缓存已经过期时,使用协商缓存
-
唯一标识方案: Etag(response 携带) & If-None-Match(request携带,上一次返回的 Etag): 服务器判断资源是否被修改,
-
最后一次修改时间: Last-Modified(response) & If-Modified-Since (request,上一次返回的Last-Modified)
-
如果一致,则直接返回 304 通知浏览器使用缓存
-
如不一致,则服务端返回新的资源
-
Last-Modified 缺点:
-
周期性修改,但内容未变时,会导致缓存失效
-
最小粒度只到 s, s 以内的改动无法检测到
-
Etag 的优先级高于 Last-Modified
2. 常见状态码
-
1xx: 接受,继续处理
-
200: 成功,并返回数据
-
201: 已创建
-
202: 已接受
-
203: 成为,但未授权
-
204: 成功,无内容
-
205: 成功,重置内容
-
206: 成功,部分内容
-
301: 永久移动,重定向
-
302: 临时移动,可使用原有URI
-
304: 资源未修改,可使用缓存
-
305: 需代理访问
-
400: 请求语法错误
-
401: 要求身份认证
-
403: 拒绝请求
-
404: 资源不存在
-
500: 服务器错误
3. get / post
-
get: 缓存、请求长度受限、会被历史保存记录
-
无副作用(不修改资源),幂等(请求次数与资源无关)的场景
-
post: 安全、大数据、更多编码类型
两者详细对比如下图:

4. Websocket
Websocket 是一个 持久化的协议, 基于 http , 服务端可以 主动 push
-
兼容:
-
FLASH Socket
-
长轮询: 定时发送 ajax
-
long poll: 发送 --> 有消息时再 response
-
new WebSocket(url) -
ws.onerror = fn -
ws.onclose = fn -
ws.onopen = fn -
ws.onmessage = fn -
ws.send()
5. TCP三次握手
建立连接前,客户端和服务端需要通过握手来确认对方:
-
客户端发送 syn(同步序列编号) 请求,进入 syn_send 状态,等待确认
-
服务端接收并确认 syn 包后发送 syn+ack 包,进入 syn_recv 状态
-
客户端接收 syn+ack 包后,发送 ack 包,双方进入 established 状态
6. TCP四次挥手
-
客户端 – FIN --> 服务端, FIN—WAIT
-
服务端 – ACK --> 客户端, CLOSE-WAIT
-
服务端 – ACK,FIN --> 客户端, LAST-ACK
-
客户端 – ACK --> 服务端,CLOSED
7. Node 的 Event Loop: 6个阶段
-
timer 阶段: 执行到期的
setTimeout / setInterval队列回调 -
I/O 阶段: 执行上轮循环残流的
callback -
idle, prepare
-
poll: 等待回调
-
- 执行回调
-
- 执行定时器
-
如有到期的
setTimeout / setInterval, 则返回 timer 阶段 -
如有
setImmediate,则前往 check 阶段 -
check
-
执行
setImmediate -
close callbacks
跨域
- JSONP: 利用
<script>标签不受跨域限制的特点,缺点是只能支持 get 请求
function jsonp(url, jsonpCallback, success) {
const script = document.createElement(‘script’)
script.src = url
script.async = true
script.type = ‘text/javascript’
window[jsonpCallback] = function(data) {
success && success(data)
}
document.body.appendChild(script)
}
复制代码
-
设置 CORS: Access-Control-Allow-Origin:*
-
postMessage
安全
-
XSS攻击: 注入恶意代码
-
cookie 设置 httpOnly
-
转义页面上的输入内容和输出内容
-
CSRF: 跨站请求伪造,防护:
-
get 不修改数据
-
不被第三方网站访问到用户的 cookie
-
设置白名单,不被第三方网站请求
-
请求校验
1. nextTick
在下次dom更新循环结束之后执行延迟回调,可用于获取更新后的dom状态
-
新版本中默认是
microtasks,v-on中会使用macrotasks -
macrotasks任务的实现: -
setImmediate / MessageChannel / setTimeout
2. 生命周期
-
_init_ -
initLifecycle/Event,往vm上挂载各种属性 -
callHook: beforeCreated: 实例刚创建 -
initInjection/initState: 初始化注入和 data 响应性 -
created: 创建完成,属性已经绑定, 但还未生成真实dom -
进行元素的挂载:
$el / vm.$mount() -
是否有
template: 解析成render function -
*.vue文件:vue-loader会将<template>编译成render function -
beforeMount: 模板编译/挂载之前 -
执行
render function,生成真实的dom,并替换到dom tree中 -
mounted: 组件已挂载 -
update: -
执行
diff算法,比对改变是否需要触发UI更新 -
flushScheduleQueue -
watcher.before: 触发beforeUpdate钩子 -watcher.run(): 执行watcher中的notify,通知所有依赖项更新UI -
触发
updated钩子: 组件已更新 -
actived / deactivated(keep-alive): 不销毁,缓存,组件激活与失活 -
destroy: -
beforeDestroy: 销毁开始 -
销毁自身且递归销毁子组件以及事件监听
-
remove(): 删除节点 -
watcher.teardown(): 清空依赖 -
vm.$off(): 解绑监听 -
destroyed: 完成后触发钩子
上面是vue的声明周期的简单梳理,接下来我们直接以代码的形式来完成vue的初始化
new Vue({})
// 初始化Vue实例
function _init() {
// 挂载属性
initLifeCycle(vm)
// 初始化事件系统,钩子函数等
initEvent(vm)
// 编译slot、vnode
initRender(vm)
// 触发钩子
callHook(vm, ‘beforeCreate’)
// 添加inject功能
initInjection(vm)
// 完成数据响应性 props/data/watch/computed/methods
initState(vm)
// 添加 provide 功能
initProvide(vm)
// 触发钩子
callHook(vm, ‘created’)
// 挂载节点
if (vm.$options.el) {
vm. m o u n t ( v m . mount(vm. mount(vm.options.el)
}
}
// 挂载节点实现
function mountComponent(vm) {
// 获取 render function
if (!this.options.render) {
// template to render
// Vue.compile = compileToFunctions
let { render } = compileToFunctions()
this.options.render = render
}
// 触发钩子
callHook(‘beforeMounte’)
// 初始化观察者
// render 渲染 vdom,
vdom = vm.render()
// update: 根据 diff 出的 patchs 挂载成真实的 dom
vm._update(vdom)
// 触发钩子
callHook(vm, ‘mounted’)
}
// 更新节点实现
funtion queueWatcher(watcher) {
nextTick(flushScheduleQueue)
}
// 清空队列
function flushScheduleQueue() {
// 遍历队列中所有修改
for(){
// beforeUpdate
watcher.before()
// 依赖局部更新节点
watcher.update()
callHook(‘updated’)
}
}
// 销毁实例实现
Vue.prototype.$destory = function() {
// 触发钩子
callHook(vm, ‘beforeDestory’)
// 自身及子节点
remove()
// 删除依赖
watcher.teardown()
// 删除监听
vm.$off()
// 触发钩子
callHook(vm, ‘destoryed’)
}
复制代码
3. 数据响应(数据劫持)
看完生命周期后,里面的watcher等内容其实是数据响应中的一部分。数据响应的实现由两部分构成: 观察者( watcher ) 和 依赖收集器( Dep ),其核心是 defineProperty这个方法,它可以 重写属性的 get 与 set 方法,从而完成监听数据的改变。
-
Observe (观察者)观察 props 与 state
-
遍历 props 与 state,对每个属性创建独立的监听器( watcher )
-
使用
defineProperty重写每个属性的 get/set(defineReactive) -
get: 收集依赖 -
Dep.depend() -
watcher.addDep() -
set: 派发更新 -
Dep.notify() -
watcher.update() -
queenWatcher() -
nextTick -
flushScheduleQueue -
watcher.run() -
updateComponent()
大家可以先看下面的数据相应的代码实现后,理解后就比较容易看懂上面的简单脉络了。
let data = {a: 1}
// 数据响应性
observe(data)
// 初始化观察者
new Watcher(data, ‘name’, updateComponent)
data.a = 2
// 简单表示用于数据更新后的操作
function updateComponent() {
vm._update() // patchs
}
// 监视对象
function observe(obj) {
// 遍历对象,使用 get/set 重新定义对象的每个属性值
Object.keys(obj).map(key => {
defineReactive(obj, key, obj[key])
})
}
function defineReactive(obj, k, v) {
// 递归子属性
if (type(v) == ‘object’) observe(v)
// 新建依赖收集器
let dep = new Dep()
// 定义get/set
Object.defineProperty(obj, k, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
// 当有获取该属性时,证明依赖于该对象,因此被添加进收集器中
if (Dep.target) {
dep.addSub(Dep.target)
}
return v
},
// 重新设置值时,触发收集器的通知机制
set: function reactiveSetter(nV) {
v = nV
dep.nofify()
},
})
}
// 依赖收集器
class Dep {
constructor() {
this.subs = []
}
addSub(sub) {
this.subs.push(sub)
}
notify() {
this.subs.map(sub => {
sub.update()
})
}
}
Dep.target = null
// 观察者
class Watcher {
constructor(obj, key, cb) {
Dep.target = this
this.cb = cb
this.obj = obj
this.key = key
this.value = obj[key]
Dep.target = null
}
addDep(Dep) {
Dep.addSub(this)
}
update() {
this.value = this.obj[this.key]
this.cb(this.value)
}
before() {
callHook(‘beforeUpdate’)
}
}
复制代码
4. virtual dom 原理实现
-
创建 dom 树
-
树的
diff,同层对比,输出patchs(listDiff/diffChildren/diffProps) -
没有新的节点,返回
-
新的节点
tagName与key不变, 对比props,继续递归遍历子树 -
对比属性(对比新旧属性列表):
-
旧属性是否存在与新属性列表中
-
都存在的是否有变化
-
是否出现旧列表中没有的新属性
-
tagName和key值变化了,则直接替换成新节点 -
渲染差异
-
遍历
patchs, 把需要更改的节点取出来 -
局部更新
dom
// diff算法的实现
function diff(oldTree, newTree) {
// 差异收集
let pathchs = {}
dfs(oldTree, newTree, 0, pathchs)
return pathchs
}
function dfs(oldNode, newNode, index, pathchs) {
let curPathchs = []
if (newNode) {
// 当新旧节点的 tagName 和 key 值完全一致时
if (oldNode.tagName === newNode.tagName && oldNode.key === newNode.key) {
// 继续比对属性差异
let props = diffProps(oldNode.props, newNode.props)
curPathchs.push({ type: ‘changeProps’, props })
// 递归进入下一层级的比较
diffChildrens(oldNode.children, newNode.children, index, pathchs)
} else {
// 当 tagName 或者 key 修改了后,表示已经是全新节点,无需再比
curPathchs.push({ type: ‘replaceNode’, node: newNode })
}
}
// 构建出整颗差异树
if (curPathchs.length) {
if(pathchs[index]){
pathchs[index] = pathchs[index].concat(curPathchs)
} else {
pathchs[index] = curPathchs
}
}
}
// 属性对比实现
function diffProps(oldProps, newProps) {
let propsPathchs = []
// 遍历新旧属性列表
// 查找删除项
// 查找修改项
// 查找新增项
forin(olaProps, (k, v) => {
if (!newProps.hasOwnProperty(k)) {
propsPathchs.push({ type: ‘remove’, prop: k })
} else {
if (v !== newProps[k]) {
propsPathchs.push({ type: ‘change’, prop: k , value: newProps[k] })
}
}
})
forin(newProps, (k, v) => {
if (!oldProps.hasOwnProperty(k)) {
propsPathchs.push({ type: ‘add’, prop: k, value: v })
}
})
return propsPathchs
}
// 对比子级差异
function diffChildrens(oldChild, newChild, index, pathchs) {
// 标记子级的删除/新增/移动
let { change, list } = diffList(oldChild, newChild, index, pathchs)
if (change.length) {
if (pathchs[index]) {
pathchs[index] = pathchs[index].concat(change)
} else {
pathchs[index] = change
}
}
// 根据 key 获取原本匹配的节点,进一步递归从头开始对比
oldChild.map((item, i) => {
let keyIndex = list.indexOf(item.key)
if (keyIndex) {
let node = newChild[keyIndex]
// 进一步递归对比
dfs(item, node, index, pathchs)
}
})
最后
在面试前我花了三个月时间刷了很多大厂面试题,最近做了一个整理并分类,主要内容包括html,css,JavaScript,ES6,计算机网络,浏览器,工程化,模块化,Node.js,框架,数据结构,性能优化,项目等等。
包含了腾讯、字节跳动、小米、阿里、滴滴、美团、58、拼多多、360、新浪、搜狐等一线互联网公司面试被问到的题目,涵盖了初中级前端技术点。
-
HTML5新特性,语义化
-
浏览器的标准模式和怪异模式
-
xhtml和html的区别
-
使用data-的好处
-
meta标签
-
canvas
-
HTML废弃的标签
-
IE6 bug,和一些定位写法
-
css js放置位置和原因
-
什么是渐进式渲染
-
html模板语言
-
meta viewport原理
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注前端)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
iffProps(oldProps, newProps) {
let propsPathchs = []
// 遍历新旧属性列表
// 查找删除项
// 查找修改项
// 查找新增项
forin(olaProps, (k, v) => {
if (!newProps.hasOwnProperty(k)) {
propsPathchs.push({ type: ‘remove’, prop: k })
} else {
if (v !== newProps[k]) {
propsPathchs.push({ type: ‘change’, prop: k , value: newProps[k] })
}
}
})
forin(newProps, (k, v) => {
if (!oldProps.hasOwnProperty(k)) {
propsPathchs.push({ type: ‘add’, prop: k, value: v })
}
})
return propsPathchs
}
// 对比子级差异
function diffChildrens(oldChild, newChild, index, pathchs) {
// 标记子级的删除/新增/移动
let { change, list } = diffList(oldChild, newChild, index, pathchs)
if (change.length) {
if (pathchs[index]) {
pathchs[index] = pathchs[index].concat(change)
} else {
pathchs[index] = change
}
}
// 根据 key 获取原本匹配的节点,进一步递归从头开始对比
oldChild.map((item, i) => {
let keyIndex = list.indexOf(item.key)
if (keyIndex) {
let node = newChild[keyIndex]
// 进一步递归对比
dfs(item, node, index, pathchs)
}
})
最后
在面试前我花了三个月时间刷了很多大厂面试题,最近做了一个整理并分类,主要内容包括html,css,JavaScript,ES6,计算机网络,浏览器,工程化,模块化,Node.js,框架,数据结构,性能优化,项目等等。
包含了腾讯、字节跳动、小米、阿里、滴滴、美团、58、拼多多、360、新浪、搜狐等一线互联网公司面试被问到的题目,涵盖了初中级前端技术点。
-
HTML5新特性,语义化
-
浏览器的标准模式和怪异模式
-
xhtml和html的区别
-
使用data-的好处
-
meta标签
-
canvas
-
HTML废弃的标签
-
IE6 bug,和一些定位写法
-
css js放置位置和原因
-
什么是渐进式渲染
-
html模板语言
-
meta viewport原理
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注前端)
[外链图片转存中…(img-EWLgRNmR-1713446839847)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 422
422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









