







基本信息
-
发表刊物:ACM Special Interest Group on Information Retrieval,ACM SIGIR2023
-
发表年份:2023
-
第一完成单位(国内):武汉大学国家网络安全学院
-
作者:博士研究生王妍灵, 硕士研究生刘昱忱
-
关键词(中文):自我监督学习、顺序推荐、中毒攻击
-
关键词(英文):Self-supervised Learning, Poisoning Attack ,Sequential Recommendation
综述
工作:首次证明基于自监督学习的推荐系统易受到投毒攻击,并提出一种具有普适性的投毒攻击方案。
方法:攻击者在黑盒模型背景与无API访问的情况下,生成极少量的恶意用户来影响自监督学习的预训练模块,从而操纵下游推荐模型的推荐结果。
实验:该研究在基于自监督学习的主流推荐系统和商业数据集上进行了验证,证明了自监督推荐系统为攻击者提供了新的攻击面。
背景知识
自监督学习
自监督学习是一种无需人工标注数据的机器学习方法,它通过构建良好的先决任务,从大规模未标注数据中学习更加鲁棒的表示,从而减少模型对高质量手动标注的依赖。
主要方法
-
基于上下文:图像修复、图像着色、NLP中预测中间词。主要是基于样本自身信息。
-
基于时序(有样本间的约束关系):判断视频序列是否是正确的顺序。
-
基于对比:通过学习对两个事物的相似或不相似进行编码来构建表征。主要思想是通过构建正样本(positive)和负样本(negative),然后度量正负样本的距离来实现自监督学习,即样本和正样本之间的距离远远大于样本和负样本之间的距离,可以使用点积的方式构造距离函数,然后构造一个 softmax 分类器,以正确分类正样本和负样本。
常见推荐系统到基于自监督学习的推荐系统
在推荐系统中item有几十万,甚至上百万,用户能给予反馈的只有一小部分。这样对于大部分item,训练样本就很稀疏,item就表现出长尾的属性。造成数据稀疏的原因主要有两种:
1)user和item交互式有偏的,头部的item占据了绝大部分的曝光和点击,而尾部的item几乎没有曝光和点击,进一步反馈到训练数据上,大部分item的样本都很稀疏。
2)用户大部分行为是点击、点赞,例如评分评论等显式反馈是缺失的,如果是预测评分的场景,数据也是稀疏的。
为了解决数据稀疏模型学习不好的问题,Google在2021年提出了应用于推荐系统的自监督学习框架。基本思想是进行数据增强,利用自监督学习用户与商品隐性关联。然后使用一个辅助任务来区分原数据和增强后的数据,使得同一个样本增强前后相似,不同的样本增强前后不同,辅助模型学习。由此可见,自监督学习能引入更多的数据,对于长尾的item让模型学习更加充分,学习到以前学习不到的内在表达。
存在缺陷及问题提出
因为预训练阶段可以从精心设计的数据对中学习错误的相关性,并通过参数传递、参数共享或作为特征提取器将中毒 参数传输给下游模型。
作者采用毒化推荐系统来实施攻击,主要考虑三个因素:有效性、 隐蔽性和开销。SSL 将攻击面从 整个模型转移到了较浅的预训练阶段,这使得攻击者能以较少的开销更隐蔽 地实施攻击。
同时这种攻击可能会恶化个性化推荐,从而导致 平台用户的流失,而无需进行任何 API 查询,甚至无需了解推荐模型的具 体结构或参数。
因此,不需要重建整个目标模型的代理模型(成本很高),只需要模仿预训练阶段的操作即可。然而 ,模仿预训练阶段和模仿整个推荐模型一样,都是代价高昂的优化问题:两 者都需要模型反馈。SSL 的性质摆脱了上述难题:在 SSL 中,预训练阶段的角色是一个二元分类器,用于判断两个增强样本是否来自同一个原始 样本。因此,只需要构建一个简单的二进制分类器来模仿预训练阶段的行为。
论文内容
问题定义
受害者模型
受害模型是指本文中使用的序列推荐模型,它是一个黑盒子模型,可以接受用户历史行为序列作为输入,并输出推荐的物品列表。本文中的攻击方法可以针对任何基于自监督学习的序列推荐模型进行攻击。
威胁模型(攻击者)
威胁模型是指攻击者的目标和能力。攻击者的目标是通过精心构造的输入数据来毒化预训练模型,从而降低下游推荐模型的准确性。随机选择一个不受欢迎的项目作为目标项目, 以评估定向晋升攻击。
攻击者的能力是可以访问和修改一部分用户历史行为数据,并将其注入到训练数据中(but数量有限),以便在训练过程中影响模型的学习结果。
攻击者所知:
-
黑盒受害者模型。攻击者只知道目标机型使用 了 SSL 技术,不知道机型结构和参数的详细信息。
-
无 API 查询。这意味 着攻击者只能引导生成中毒数据,而无法从目标模型中获得任何反馈。
-
可用的用户-项目交互矩阵。在许多推荐平台(如 Amazon、Netflix 和 Yelp)中, 用户的历史评分都是公开的。
中毒攻击(一个优化过程)
攻击者的目标是找到一组最佳的假用户及其交互序列,使攻击成功率最大化,同时使假用户数量最小化。本文将该问题表述为一个优化问题,并提出了一种基于梯度下降的求解方法。本节还讨论了所提出的优化问题的局限性,并为未来的研究提出了方向。
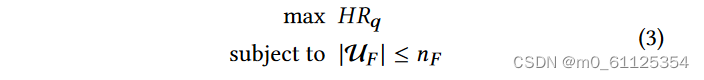
模型设计
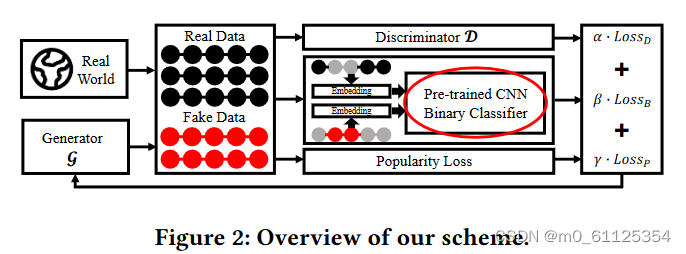
根据上述的背景和问题定义,作者设计了一种针对基于 SSL 的顺序推荐系统的定向推广攻击。作者使用生成式智能网络(GAN) 生成虚假序列,并由三个模块共同 指导生成。第一部分是 GAN 中的判别器,用于判断序列是否虚假。第二部分是在 SSL 中的预训练阶段。第三部分是确保目标项目出现在每个假冒用户的交互记录中。
中毒攻击方法
总述
这部分所有的内容都是基于下面的伪代码:

伪代码概述了所提出的中毒攻击方法的训练过程,该方法包括训练生成器(G_theta)来生成伪用户-项目交互序列,以及训练鉴别器(D_phi)来区分真序列和伪序列。该算法首先用随机权重初始化生成器和鉴别器,并对生成器进行预训练,以生成第一批假用户。鉴别器还被预先训练以区分真实序列和伪序列。
然后,算法进入一个循环,在那里它在更新鉴别器和生成器之间交替。在每次迭代中,生成器生成伪序列s_1:T,该伪序列被馈送到鉴别器中以使用多种方法计算损失(loss_total)。
-
Loss_B:真假序列的距离(0、1)
-
Loss_P:目标项外观
-
Loss_D:判断是否为假序列
然后使用梯度下降来更新鉴别器,以使损失最小化。
在下一步中,使用新的 G_theta 生成负样本(negative samples)。使用正样本和负样本重新训练判别器 D_phi,以减小判别器的损失。
这段伪代码描述了一个基本的生成对抗网络(GAN)框架,其中生成器和判别器相互竞争,生成器试图生成逼真的用户-物品互动序列,而判别器试图区分真实序列和虚假序列。通过反复迭代训练,生成器和判别器的性能逐渐提高,最终生成的虚假序列更加逼真。
LOSS_D(生成逼真的伪序列)
鉴别器𝐷(𝜙) 将实序列集S中的序列作为正样本,并将生成器生成的伪序列𝐺(𝜃) 作为其自身训练的负样本。鉴别器的目标是区分真实序列和伪序列,并向生成器提供反馈以提高生成序列的质量。
生成器𝐺(𝜃) 基于真实数据生成伪序列,其任务是从起始状态𝜏0生成序列以最大化序列的奖励。奖励由鉴别器计算,鉴别器对上述奖励进行计算,以便于生成器生成更逼真的伪序列。
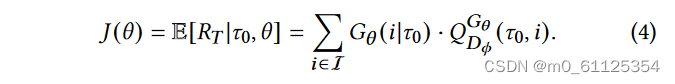
LOSS_B(计算真假数据的距离)
作者提出了一个预训练部分的代理模型,将对自监督学习的攻击表述为双层优化问题。该代理模型的目标是近似真实序列和伪序列的扩增数据之间的距离。
优化问题分为两部分:外部优化和内部优化。外部优化问题旨在使伪序列和真实序列(均在掩蔽后)在特征空间中的距离更近,进而诱导下游推荐者对真实用户和伪用户进行类似的推荐。
内部优化问题训练分类器作为预训练部分的代理模型。
(代理或代理模型是一种简化的模型,用于代替更复杂或计算成本更高的模型。在本文的背景下,在推荐系统的预训练阶段,使用代理模型来近似真实序列和伪序列的扩增数据之间的距离。该代理模型用于将对自监督学习的攻击表述为一个双层优化问题,该问题可用于生成中毒数据来攻击推荐系统中的预训练模型。代理模型的使用使攻击者能够减少生成中毒数据所需的计算开销,从而使攻击更加高效。)
LOSS_P(将目标项目放到伪序列)
先前的研究表明,当虚假用户与目标物品互动时,中毒攻击更有效。这是因为基于协作过滤的推荐者倾向于过度推荐受欢迎的产品。然而,部分A和部分B都不能导致目标项目被包括在伪序列中。
因此,引入C部分来解决这个问题。作者将序列中每个项目的标签设置为目标项目,并相应地计算序列的损失。例如,如果目标项目的id是887,则对于序列{1,2,3,4,887},该序列的标签是{887,887,887,887}。
形式上,对于序列𝑠 长度为𝑇, 损失𝐿𝑜𝑠𝑠𝑃 计算如下:
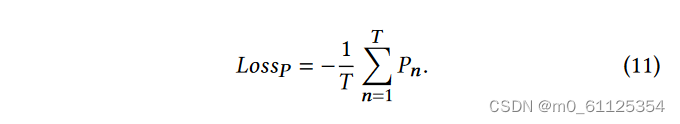
𝑃𝑛 表示项目 I𝑛 是否与其标签相同(如上所述,这里的标签是目标项目的 id)。就是有几个目标项目。计算出 𝐿𝑜𝑠𝑠𝑃 之后,我们使用梯度下降算法来更新 我们的模型。引入了概率阈值𝑝来防止过拟合。
对下游的影响(为什么我们的方法对整个推荐系统有效果)
下游推荐器继承预训练参数并对其进行微调。因此,在预训练模型中被判定为距离相似的连续模式在下游微调中也会被认为是相似的。因此,下游模型会继承中毒预训练模型的行为,并倾向于向真实用户推荐原本推荐给虚假用户的目标项目。
实验部分
实验设置
数据集
作者使用了四个在推荐系统评估中常用的真实世界商业数据集来实现他们的攻击。这些数据集是亚马逊真实客户公开记录中的Beauty、Sports and Outdoors、Toys and Games,以及知名商业推荐平台Yelp(2020年发布的第二个版本)。
目标推荐系统
从理论上讲,该攻击适用于所有基于 SSL 的顺序推荐模型。
在实验中选择了两个经典的基于 SSL 的顺序推荐模型来实现我们的攻击:𝑆 -Rec 3和 CL4SRec 。
基准攻击(用来对比)
-
流行项攻击。中毒数据由目标项和填充项组成。填充项是用户与项目交互序列原始集合中流行度排名前 𝑘% 的项目。设置𝑘 = 10。
-
随机项目攻击。 随机选择填充项。
-
RecommPoison 。攻击者假设与该论文类似 。他们建立了整个目标模型的代理模型来指导假序列的生成,而本论文只建立了预训练阶段的代理模型。
除此之外,作者还进行了消融研究,以证明B部分在他们提出的方法中的重要性。他们将其完整模型生成的中毒数据的性能与缺乏B部分的模型生成的毒害数据的性能进行了比较。
目标项目
按照商品出现的次数对商品进行排序,将它们等 比例地分为三组:受欢迎的、常见的和不受欢迎的,然后在不受欢迎的商品组 中随机选择一个商品作为目标商品。
评估指标
本文使用了推荐系统中常用的几种评估指标来衡量所提出的中毒攻击方法和基线方法的性能。这些指标包括:
-
最高K命中率(HR@K):测量基本事实项目在前K个推荐项目中的测试用例的比例。
-
最高K标准化贴现累计收益(NDCG@K):通过给与用户更相关的项目分配更高的分数来提高推荐项目的质量。
-
平均倒数排名(MRR):测量推荐列表中第一个相关项目的平均排名。
实验任务及结果(要证明的问题)
消融研究
作者进行了消融研究,以证明B部分在中毒发作中的重要性。B部分旨在利用推荐系统中自我监督学习(SSL)的弱点。
作者通过从他们的方案中删除B部分来生成中毒数据,并将其与他们的完整模型生成的中毒数据进行比较。结果如表3所示。
作者使用推荐系统中常用的指标来评估中毒攻击的性能:top-𝐾 命中率(HR@K),顶部-𝐾 归一化贴现关系累计收益(NDCG@K)和平均倒数排名(MRR)。
结果表明,完整模型生成的中毒数据优于缺少B部分的模型生成的数据,表明了B部分在中毒攻击中的重要性。

总体而言,作者进行的消融研究证明了B部分在中毒攻击中的重要性,并强调了推荐系统中自我监督学习带来的潜在安全威胁。
有效性验证
作者使用推荐系统中常用的指标来评估他们对推荐系统的中毒攻击的有效性:top-𝐾 命中率(HR@K),顶部-𝐾 归一化贴现关系累计收益(NDCG@K)和平均倒数排名(MRR)。
作者将中毒攻击的表现与基础攻击的表现进行了比较。结果如表4所示。
作者还记录了在第5.1节所述的实验设置中,当数据集为Beauty时,训练伪序列生成器所需的时间。结果表明,与比较方案相比,他们的方案具有显著更小的计算开销。
总体而言,结果证明了针对推荐系统的中毒攻击的有效性,并突出了推荐系统中自我监督学习带来的潜在安全威胁。
在这部分实验中,作者也发现了一些缺陷:就数据集 Toys 而言,在 CL4SRec 中,我们的攻击只在样本99 设置中有效。这可能是由于数据集 Toys 中的用户-项目内聚度较高,使得我们需要更多的假用户才能形成有效的攻击 。
隐蔽性检验
作者表明,随着训练前时期数量的增加,中毒程度也会增加。然而,他们也证明了当预训练时期增加时,基本真实的度量变得更差的假设是不正确的。
为了说明这一点,作者使用他们的中毒数据对目标模型进行了预训练和微调,并计算了不同预训练时期下地面实况项目的结果。实验是在数据集Beauty in The Sample 99设置上针对S3-Rec进行的。结果表明,当使用不同时期的预训练模型进行微调时,地面实况项目的各种指标没有显著变化。
所以,即使推荐服务提供商意识到其平台可能存在恶意用户,也无法在轻量 级微调阶段通过简单观察地面实况项的性能来确认。此外,重新训练预训练模 型需要大量的计算开销,这可能是推荐平台无法接受的。
总结(实验优点说明)
与以往的中毒攻击不同,我们的攻击不需要模拟整个推荐系统的功能,也不需要任何应用程序接口查询,同时我们还需要用生成的 虚假输入创建虚假用户。我们的设计只在预训练阶段建立了一个结构简单的轻量级代理模型,大大减少了部署和计算开销。此外,我们还证明了我们的攻击在 某些具有代表性的检测方案下具有隐蔽性和鲁棒性。
思考
论文的主要优点
1.新颖性:本文提出了一种新的中毒攻击方法,专门针对基于自监督学习的序列推荐系统设计,同时极大减少了攻击的代价。兼具隐蔽性和鲁棒性。此方法是新颖的,以前从未在文献中提出过。
2.真实世界的适用性:本文在推荐系统评估中常用的四个真实世界商业数据集上评估了所提出的方法,证明了它们在真实世界场景中的有效性。
3.严格的评估:本文对所提出的方法进行了彻底的评估,将其与几种基线方法进行了比较,并进行了消融研究,以证明所提出方法的不同组成部分的重要性。该评估是使用推荐系统中几种常用的评估指标进行的。
4.实际意义:本文强调了推荐系统中自我监督学习带来的潜在安全威胁,并对如何攻击和防御这些系统提供了实际见解。该文件还强调了改进这些系统的安全措施的必要性。















 4056
4056











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









