






论文题目
Partial Vessels Annotation-Based Coronary Artery Segmentation with Self-training and Prototype Learning
论文代码
面对的问题
标记困难:目标区域分散,分支和外部血管边界模糊。
复杂的拓扑:(冠状动脉在不同个体之间存在差异)
主要创新点
- 基于冠状动脉分割挑战和临床诊断特征的部分血管标注(PVA)方法。
- 一种渐进式弱监督学习框架
首先,我们的框架学习血管的局部特征,将这些知识传播到未标记的区域。随后,它利用传播的知识学习全局结构,并纠正传播过程中引入的错误。最后,它利用特征嵌入和特征原型之间的相似性来增强测试输出。在临床数据上的实验证明,我们提出的框架在PVA(24.29%的血管)下优于竞争方法,并在与使用完整标注(100%的血管)的基线模型中的主干连续性方面实现了相当的性能。
解决方法
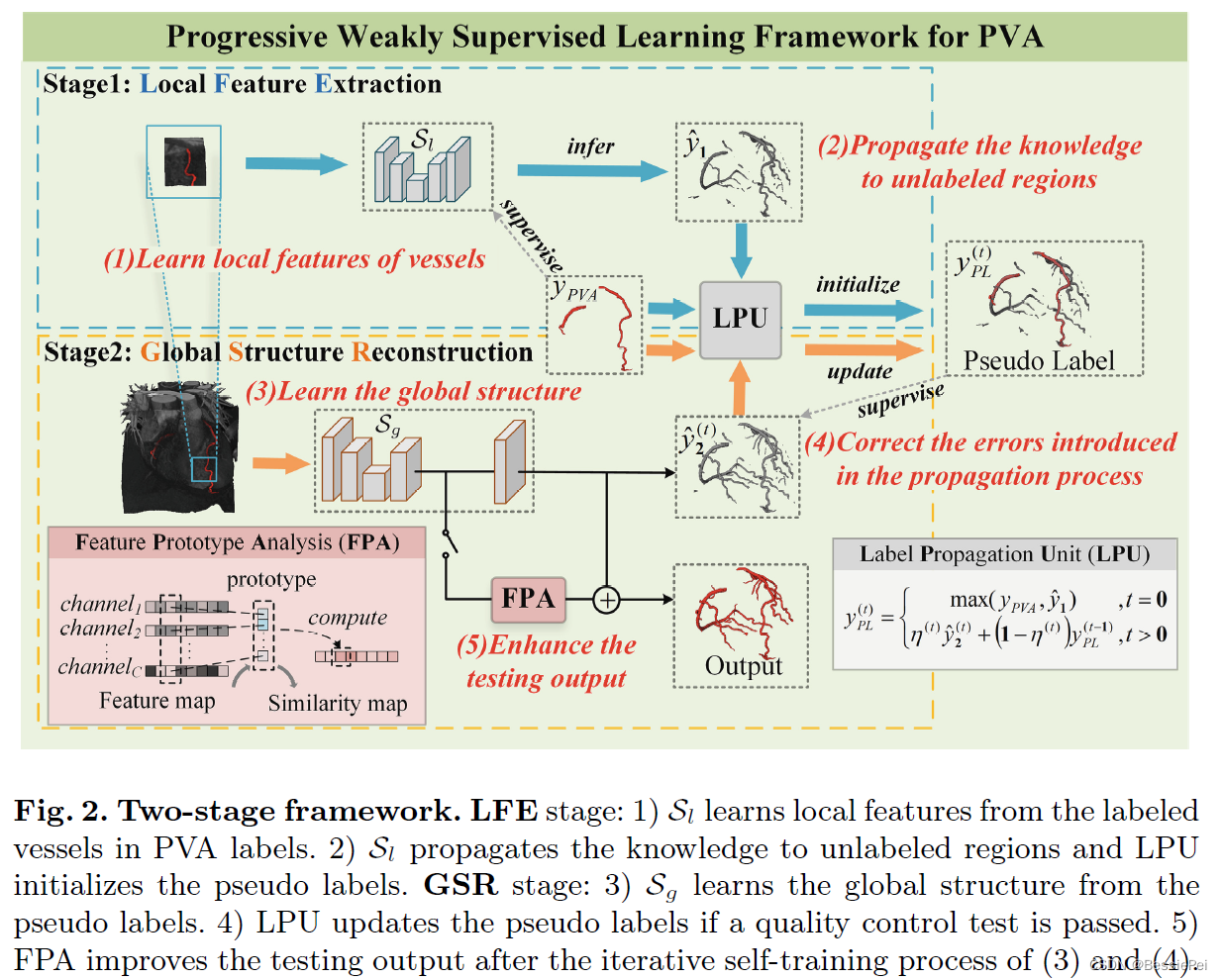
LFE
Local Feature Extraction Stage
在LFE阶段,我们的假设是标记区域周围的小区域包含有效信息。基于此假设,我们训练了一个轻量级的分割模型Sl,用于在局部学习血管特征,其中以标记区域为中心的小补丁作为输入和输出。通过这种方式,也减少了未标记区域中不准确监督信息的负面影响。
伪标签初始化
在LPU中的伪标签初始化。在训练完成后,Sl将学习到的局部特征知识传播到未标记区域。对于形状为H×W×D的每个图像,Sl的相应输出logit ˆy1 ∈ [0, 1]H×W×D提供了血管分布的完整估计,尽管有一定的近似。同时,PVA标签yPVA ∈ {0, 1}H×W×D提供了关于血管分布的准确信息,但仅在有限程度上。因此,LPU将ˆy1和yPVA整合起来初始化伪标签yPL(公式1),该伪标签将在GSR阶段中使用,并在迭代自训练过程中进行更新。
伪标签初始化的公式如下: 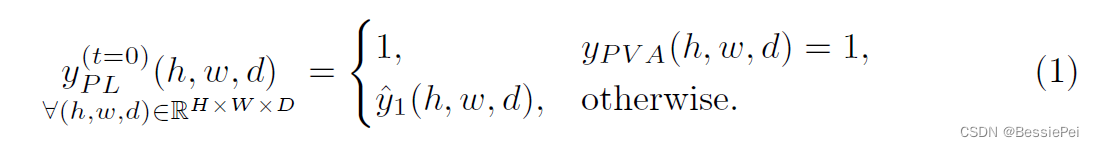
其中,y(t=0)_PL表示迭代次数为0时的伪标签,(h,w,d)表示图像中的像素位置,H×W×D表示图像的尺寸。如果PVA标签中的像素为1,则对应的伪标签为1,否则使用Sl的输出作为伪标签的值。这样初始化的伪标签将在后续的GSR阶段中使用,并在迭代的自训练过程中进行更新。
GSR
Global Structure Reconstruction Stage
GSR阶段主要包括三个部分:1)分割模型Sg用于学习全局的树状结构;2)LPU用于改进伪标签;3)FPA块用于改善测试时的分割结果。
通过初始化(公式1),初始伪标签y(t=0)PL包含了PVA标签的信息以及Sl中的局部特征知识。因此,在这个阶段的开始时,Sg从y(t=0)PL中进行预热学习。之后,Sg的逻辑数被用于在迭代的自训练过程中更新伪标签。
伪标签更新
在LPU中的伪标签更新。这个过程的原则是更可靠的逻辑数logit对应的伪标签分布影响更大。基于这个原则,首先我们计算置信度度量值η(t) ∈ [0, 1],对应于\hat{y_2}^{(t)}。根据公式2定义,η(t)的值等于标记区域中logit的平均值。这个定义是有意义的,因为在血管区域中期望的logit值为1,在背景区域中为0。越接近期望的logit值,\hat{y_2}^{(t)}置信度度量值η(t)越高。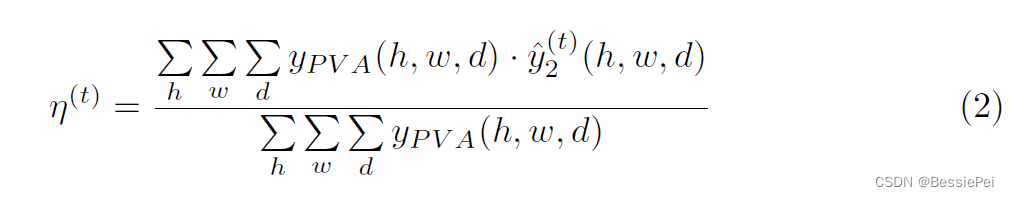
然后,我们进行质量控制测试,以尽可能避免负面优化。由于置信度度量值η(t)评估了预测的质量,低置信度的预测更容易产生错误,因此我们的质量控制测试会拒绝低置信度的预测,以减少错误累积的风险。如果η(t)高于集合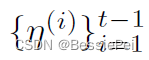
中的所有元素,当前的logit就可以通过测试,以改进伪标签。然后,通过伪标签和logit的指数加权移动平均值(EWMA)来更新伪标签,如公式3所示。这个过程类似于预测集成技术,用于过滤伪标签。然而,与其他方法不同的是,我们的方法中的因子η(t)是自适应的,而不是一个固定的超参数系数,并且伪标签在每个迭代步骤或每几个周期更新一次。我们的EWMA通过对多个阶段的预测进行加权平均,逐渐减小现有错误的负面影响。
伪标签更新的公式如下: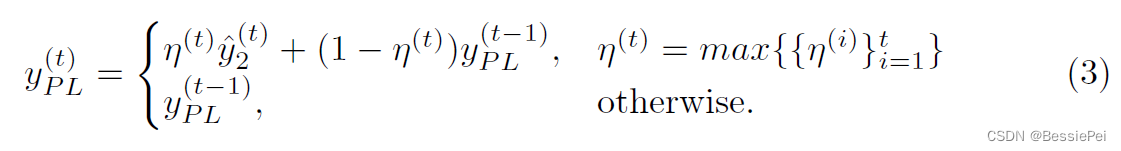
其中,y(t)_PL表示第t个迭代步骤时的伪标签,η(t)表示当前迭代步骤中的置信度度量值,{η(i)}t表示迭代步骤1到t的置信度度量值的集合。如果当前的置信度度量值η(t)高于集合{η(i)}t-1 i=1中的所有元素,当前的logit就被认为是可信的,可以通过测试来改进伪标签。伪标签的更新通过对logit和伪标签的指数加权移动平均值来实现,其中权重由置信度度量值决定。如果当前的置信度度量值η(t)不高于集合{η(i)}t-1 i=1中的所有元素,则伪标签保持不变。
FPA 特征原型分析块Feature Prototype Analysis Block
FPA的输出用于增强测试时卷积输出的连续性。
在网络的倒数第二层,紧跟着一个1×1×1的卷积层用于输出logits,我们将特征图Z ∈ R^{C×H×W×D}并行输入到FPA块中。通过公式5计算输出相似性图O ∈ R1×H×W×D,其中Z(h,w,d) ∈ RC表示体素voxel(h,w,d)的特征嵌入向量,ρθ ∈ RC表示FPA的核参数。
相似性图O的计算公式如下: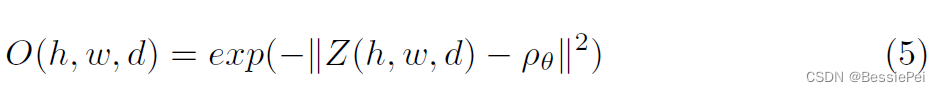
FPA块的学习过程发生在测试之前,此时整个模型(除FPA块外)被冻结。为了减少额外的开销,ρθ通过一次计算的ρc进行初始化,并通过损失函数Lfpa(Eq. 6)进行微调。在计算损失时,只有标记的体素对更新核参数起作用。
FPA块的损失函数如下: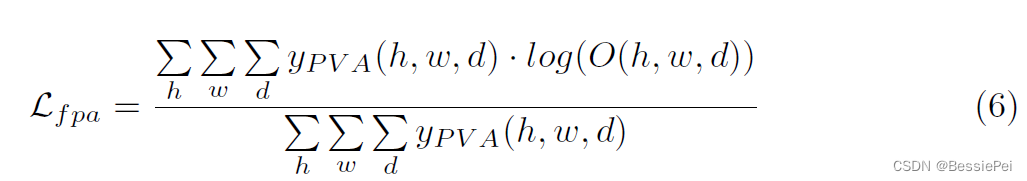
实验效果
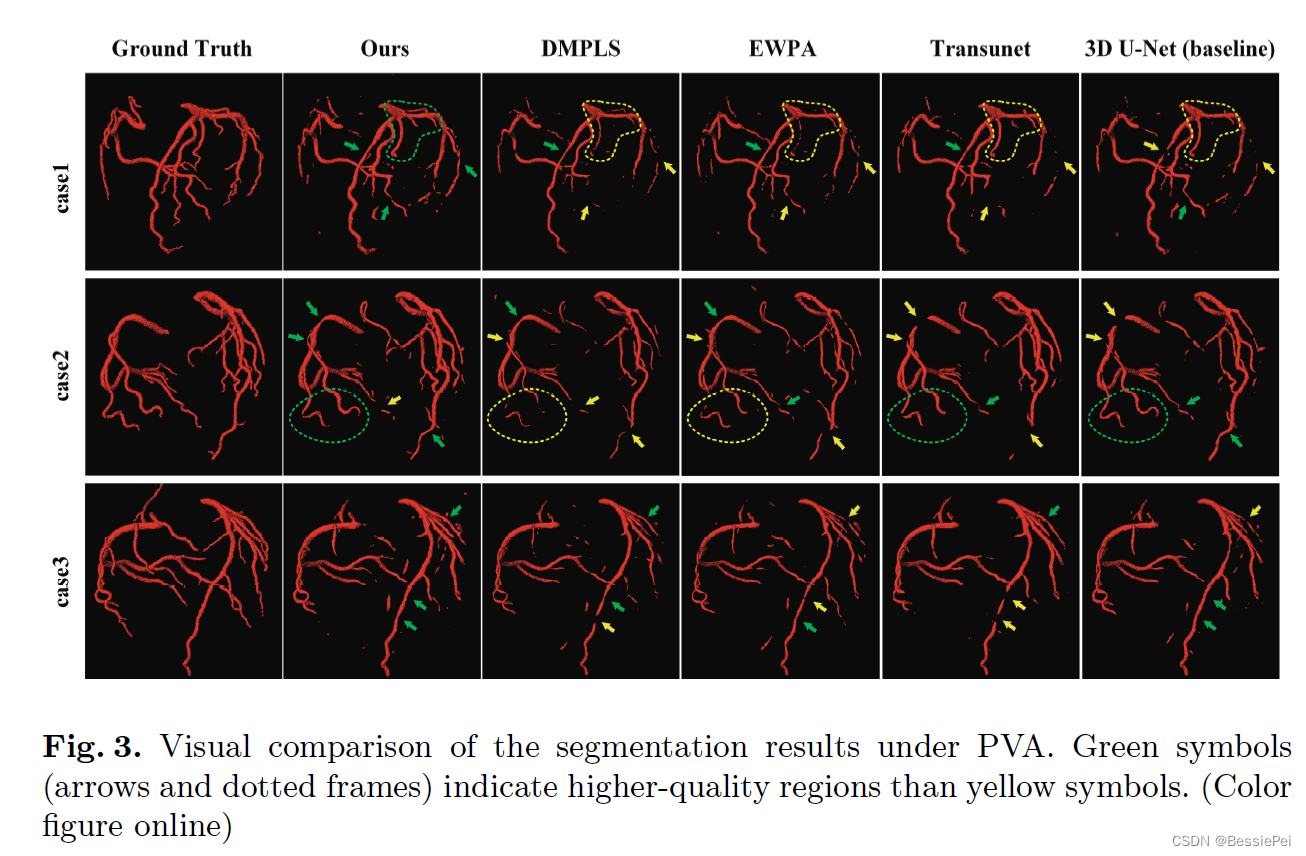
数据集:a clinical dataset,includes 108 subjects 在训练集中,PVA标签是由临床医生进行注释的,其中只有24.29%的血管被标记。用于量化结果的指标包括完整性和连续性评估指标。完整性评估指标包括平均Dice系数(Dice)、相关Dice系数(RDice)、重叠度(OV);连续性评估指标是三条主要血管(LAD、LCX和RCA)上的首次错误重叠度(OF)。
baseline model -> 3D-UNet
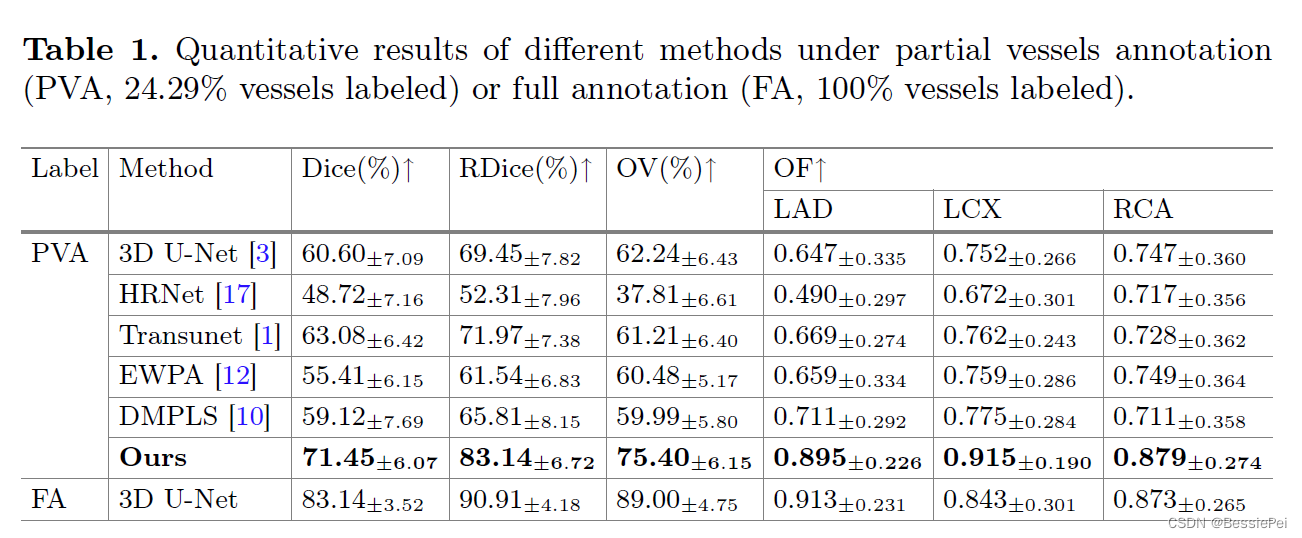
在表格1中总结了不同方法的定量结果,表明我们提出的方法在PVA下优于竞争方法。竞争框架(EWPA和DMPLS)在部分注释任务中取得了最佳结果,但我们提出的方法在基于PVA的冠状动脉分割方面取得了更好的结果。值得一提的是,我们提出的方法在使用PVA(24.29%血管标记)进行血管主干连续性评估(由指标OF衡量)方面,与使用完全注释(100%血管标记)的基准模型的性能相当。
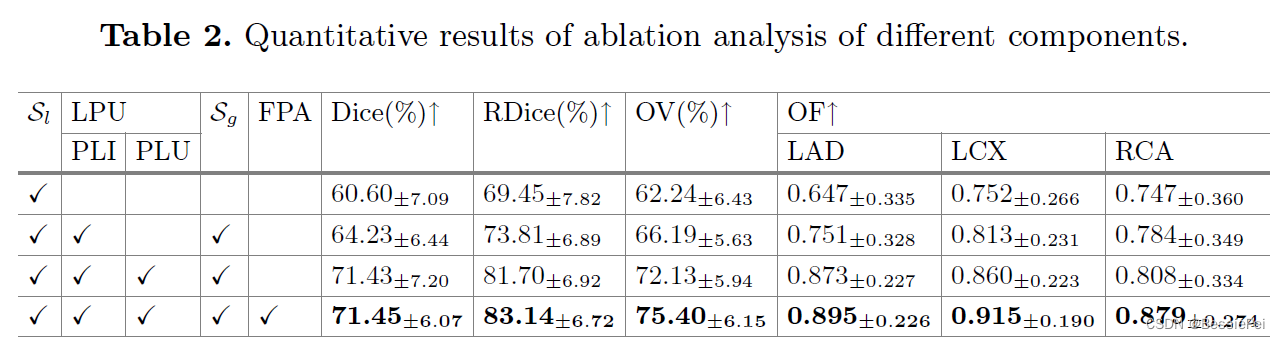
消融实验
PLI Pseudo label initialization
LPU the label propagation unit
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









