







 这篇博客探讨了循环神经网络中梯度爆炸的问题,重点分析了LSTM和GRU如何通过门控机制避免梯度消失。作者推导了LSTM和GRU的参数梯度,指出LSTM的遗忘门、输入门和输出门有助于梯度的稳定传递。GRU则通过update gate实现类似效果。此外,文章还讨论了LSTM和GRU的选择场景,指出GRU在大数据量下训练速度更快。
这篇博客探讨了循环神经网络中梯度爆炸的问题,重点分析了LSTM和GRU如何通过门控机制避免梯度消失。作者推导了LSTM和GRU的参数梯度,指出LSTM的遗忘门、输入门和输出门有助于梯度的稳定传递。GRU则通过update gate实现类似效果。此外,文章还讨论了LSTM和GRU的选择场景,指出GRU在大数据量下训练速度更快。
习题6-3 当使用公式(6.50)作为循环神经网络得状态更新公式时,分析其可能存在梯度爆炸的原因并给出解决办法.
公式(6.50)为:
在计算误差项时,可能会出现梯度过大的情况,解决办法为:使用长短期神经网络。
习题6-4推导LSTM 网络中参数的梯度,并分析其避免梯度消失的效果.

其中E EE为损失函数,由于LSTM中通过门控机制解决梯度问题,遗忘门,输入门和输出门是非0就是1的,并且三者之间都是相加关系,梯度能够很好的在LSTM传递,减轻了梯度消失发生的概率,门为0时,上一刻的信息对当前时刻无影响,没必要接受传递更新参数了。
习题6-5推导GRU网络中参数的梯度,并分析其避免梯度消失的效果. (选做)



分析:
把LSTM的input gate和forget gate整合成一个update gate,也是通过gate机制来控制梯度:
 可以通过控制
可以通过控制 ![]() 来控制梯度。
来控制梯度。
附加题 6-1P 什么时候应该用GRU? 什么时候用LSTM?

概括的来说,LSTM和GRU都能通过各种Gate将重要特征保留,保证其在long-term 传播的时候也不会被丢失。
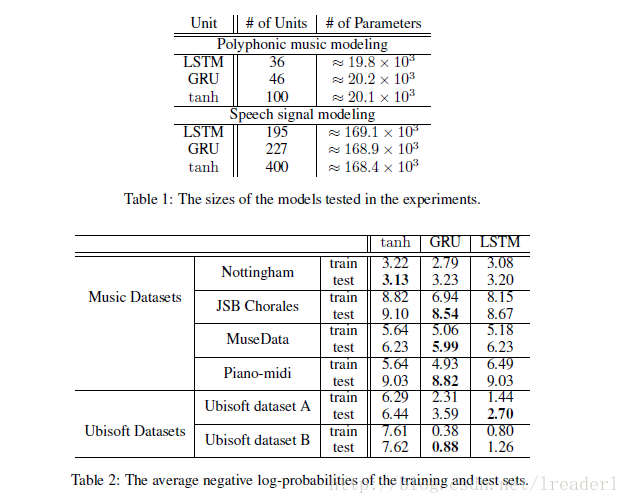
可以看出,标准LSTM和GRU的差别并不大,但是都比tanh要明显好很多,所以在选择标准LSTM或者GRU的时候还要看具体的任务是什么。
使用LSTM的原因之一是解决RNN Deep Network的Gradient错误累积太多,以至于Gradient归零或者成为无穷大,所以无法继续进行优化的问题。GRU的构造更简单:比LSTM少一个gate,这样就少几个矩阵乘法。在训练数据很大的情况下GRU能节省很多时间。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









