







数据结构_KMP算法
前言:此类笔记仅用于个人复习,内容主要在于记录和体现个人理解
文章目录
应用场景
有两条字符串,一条长,一条短,现在要求检查长的字符串,看看里面是不是包含短的字符串,如果包含,就返回短串的首元素在长串中的位置。如果没有的话,就返回-1。长串称为“主串”,短串称为“模式串”,简称“模式”。(不知道为啥这么叫,感觉有点抽象
为了解决这个问题,就诞生出了一种算法:BF算法(暴力算法)
指针i指向主串,j指向模式串
从主串的第一个元素、模式的第一个元素开始遍历,比较,如果相等,i、j后移,看后面的元素是否也都一样。如果在一个地方遇到了i、j指向的元素不同的情况,就称为“失配”,说明从主串第一个元素、模式第一个元素开始的话两个字符串没办法匹配
那么就让i起始位置变成主串的第二个元素,j起始位置指回模式的第一个元素(称为“回溯”),进行第二次遍历,看能否匹配上模式串。
直到,找到能完全匹配的情况下i的起始位置,或者,i的起始位置的剩余长度小于模式的长度(此时肯定没法匹配了,因为长度都不够了)
例如下面👇
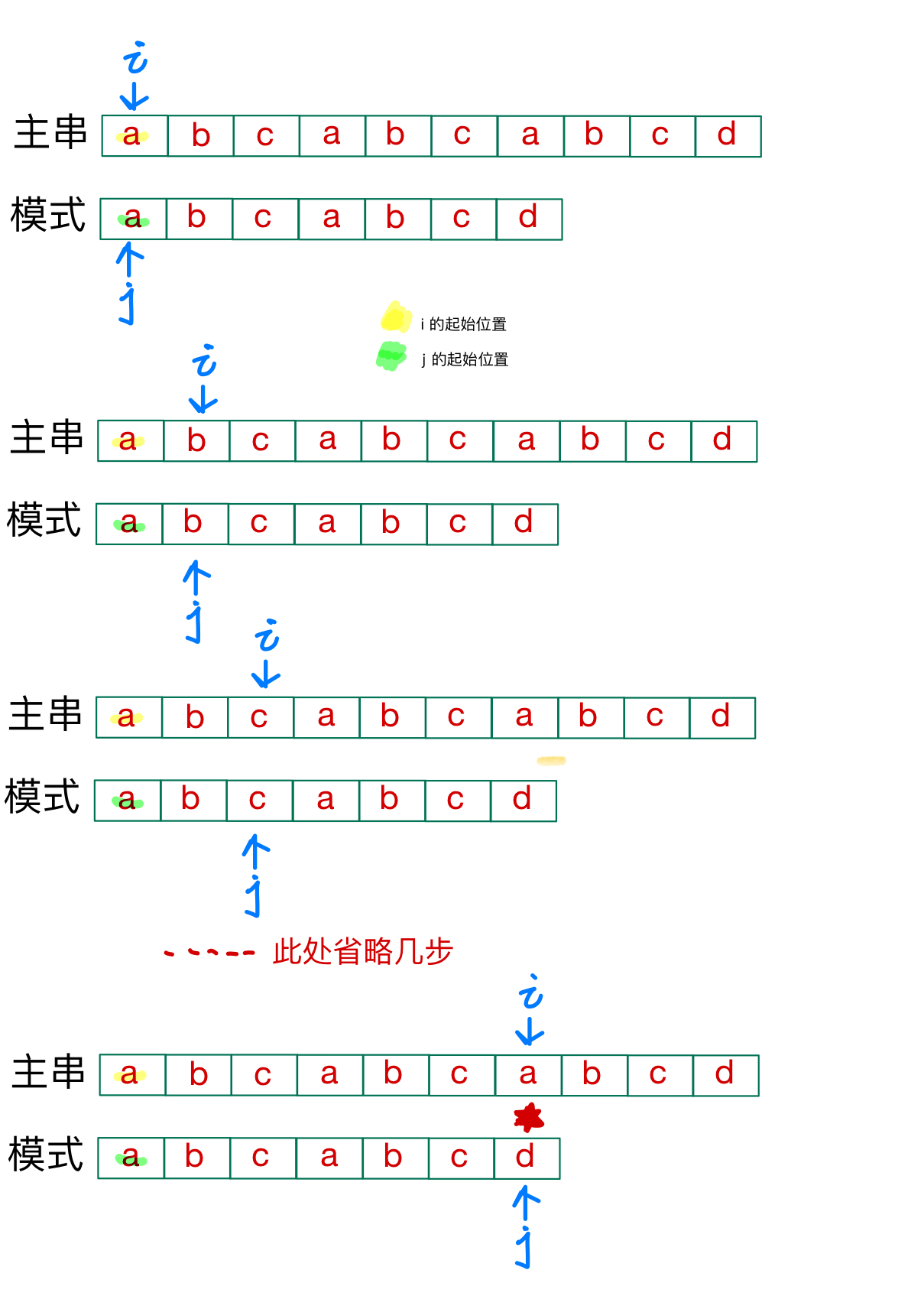
在此处,失配了,所以要进行回溯,i的初始位置变成第二个元素位置,j的初始位置变成第一个元素位置,再进行匹配
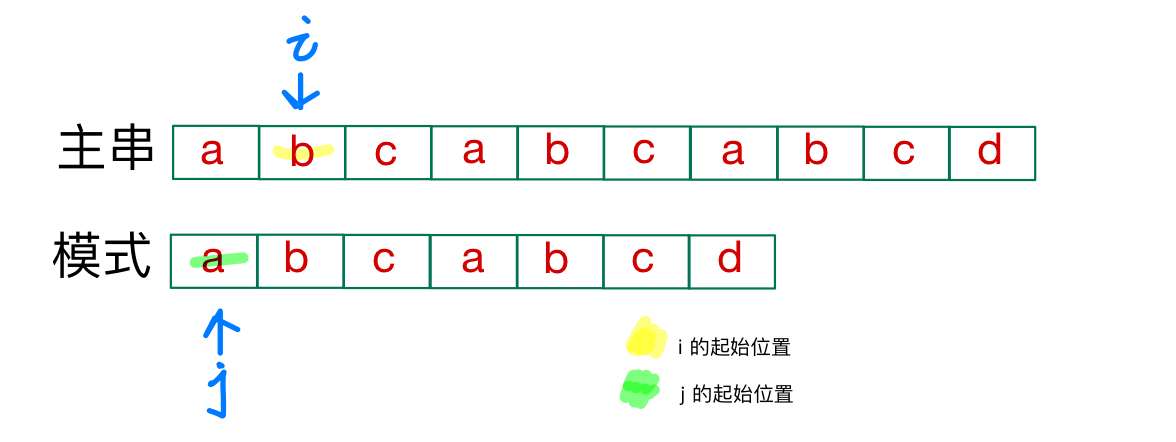
此处为了方便观看,将模式和主串的起始位置进行一下对齐👇
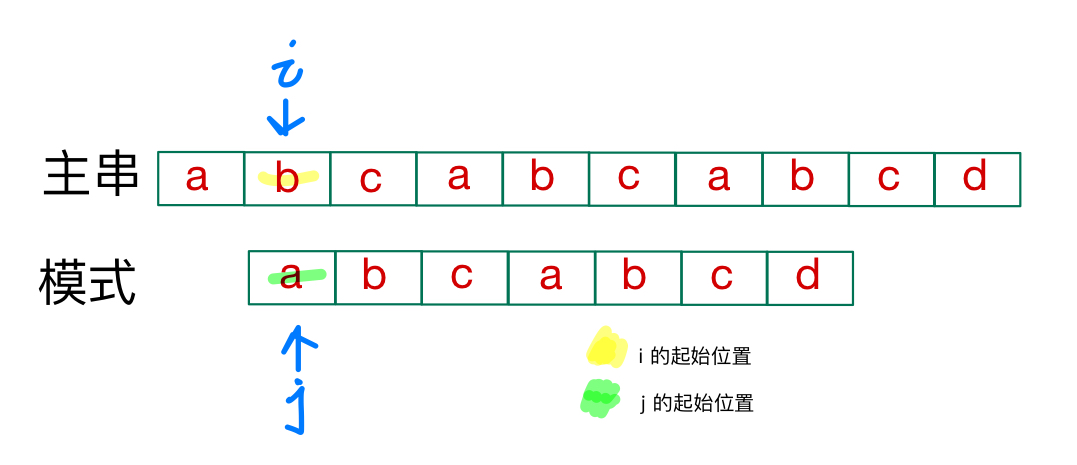
很明显,不匹配,主串的起始位置后移,模式的起始位置回溯到首元素
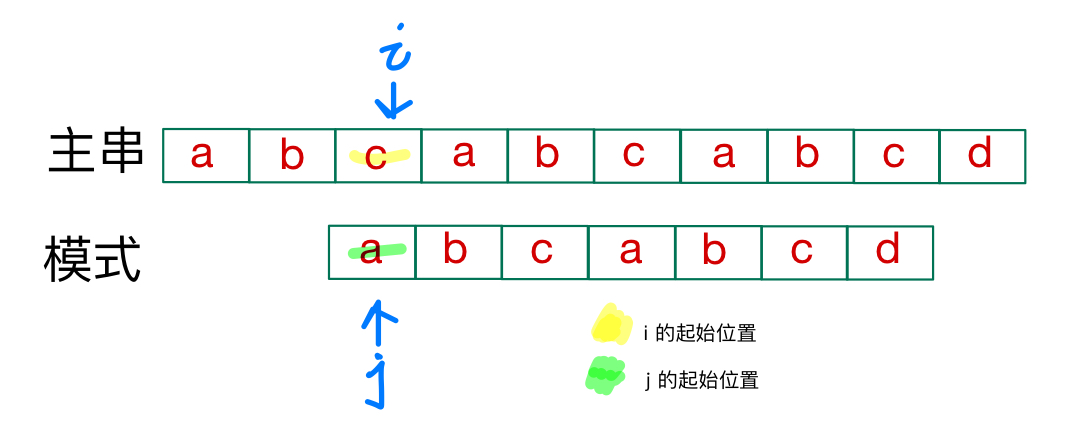
一直到匹配或者主串的剩余元素少于模式
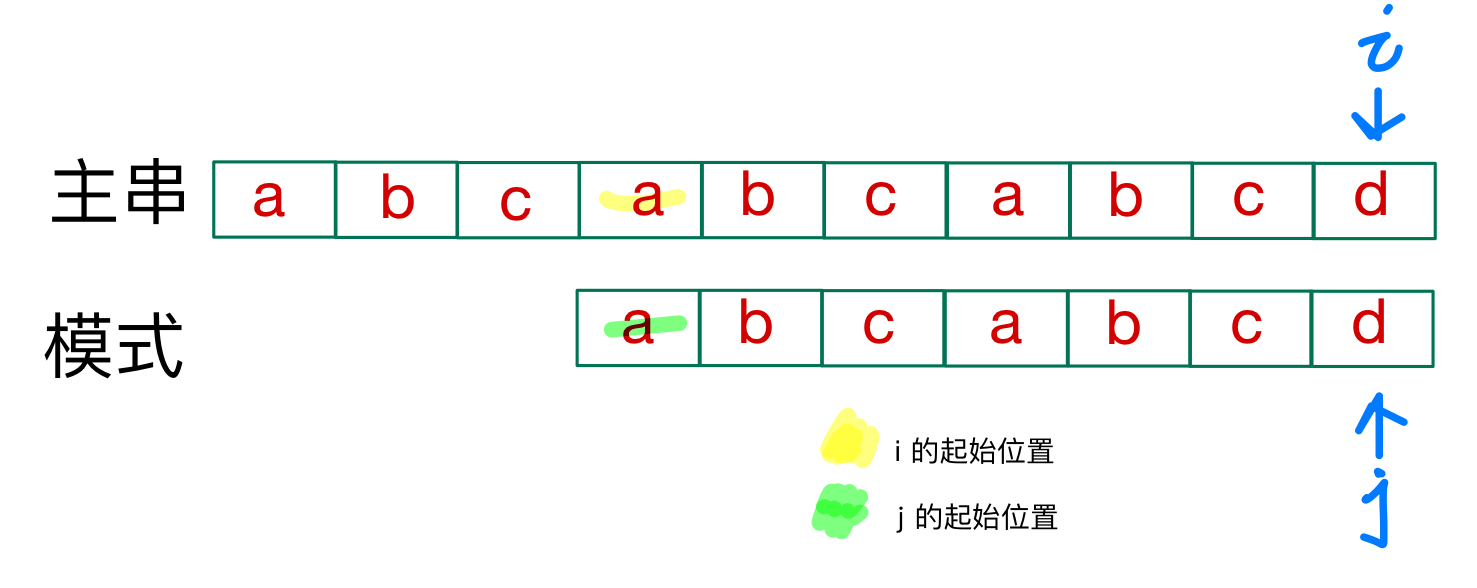
匹配成功
但是这算法,每次,都需要主串指针i回到起始位置的后一个位置作为新的起始位置,并且模式指针j回到首元素,效率很低
如果定主串长度为M,模式为N,则时间复杂度为O(M*N)
为了优化这种算法,曾经就有三位大佬创造出了一种效率极高的,时间复杂度为O(M+N)的算法:KMP算法
原理
并不一定在一开始模式就和主串不匹配,可能直到出现失配之前,模式从开头到模式的失配点这一段跟主串起始位置到自己失配点是匹配的,并且在匹配的这一小段中模式中后半段可能会有一段跟模式自己开头的一段是相同的,比如模式abcabcd中的abcd中的abc跟模式开头的abc是一样的,而因为匹配的这一小段,主串跟模式是一样的,所以说匹配的这一段中的主串的后面的一段和模式开头的一段也是相同的。
“后面的一段跟前面一段相同”有个专业的说法,先听下面的引入:
“前缀”就是从字符串的 开头 开始,从前往后构成的子串,比如abcabc中,a、ab、abc、abca、abcab、abcabc
“后缀”就是从字符串的 结尾 开始,从前往后构成的子串,比如abcabc中,c、bc、abc、cabc、bcabc、abcabc
我们会发现,除了当整个字符串作为自己的前缀或者后缀之外(当然,单个元素的字符串就是整个字符串是自己的前缀和后缀),会有前缀跟后缀相等的情况,比如前缀abc和后缀abc,其中这种情况下最长的前缀就叫“最长前缀”,后缀就叫”最长后缀“,(所以单个元素的字符串没有所谓“最长前/后缀”)
”后面这一段跟前面这一段相等”的情况下,后面这一段就是“最长后缀”,前面这一段就是“最长前缀”
这样的话,只需要找到模式的失配点之前这一段里,“最长前缀”的位置就可以
因为在匹配上的这一段中,模式中的“最长前缀”跟主串中的“最长后缀”是相等的,所以这里就不用再判断前面是不是相等了,一定是相等的
从模式中的”最长前缀“的下一个元素开始跟主串中的”最长后缀“的下一个元素(也就是主串的失配点)开始进行比较就行,而不用回溯(还是因为不用判断,前面一定是相等的)
比如用上面的例子,在第一次检查的时候遇到了失配
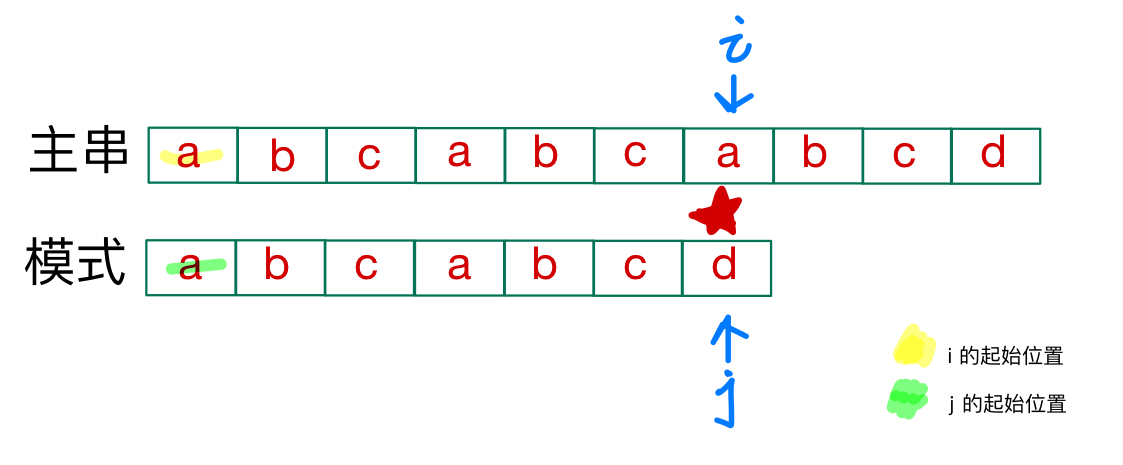
在失配之前都是匹配的,模式和主串在失配点之前的段其中有最长前缀和最长后缀是
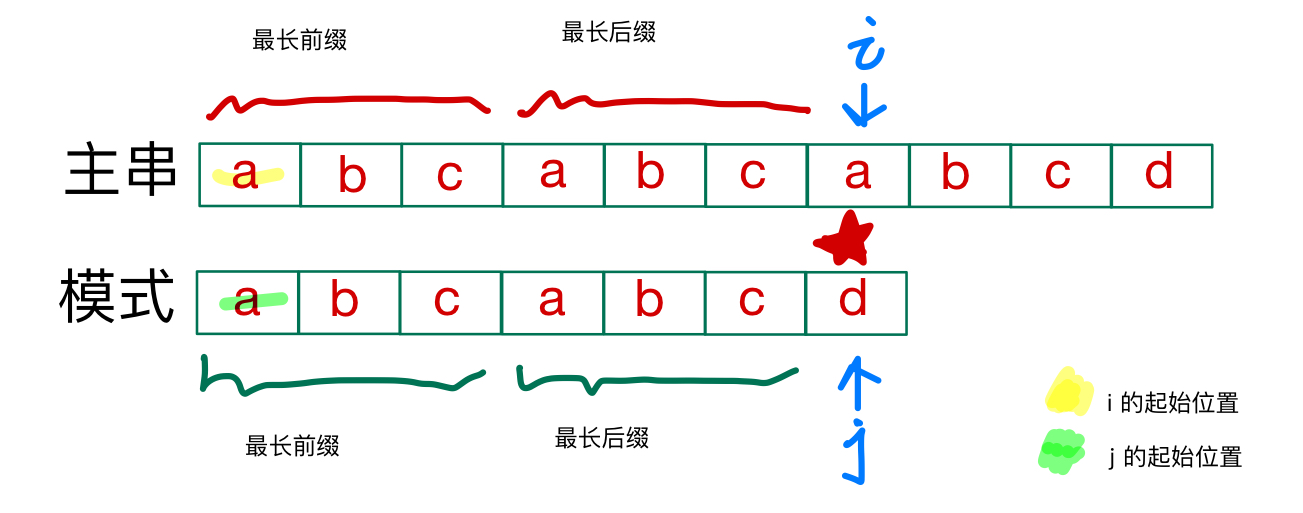
将模式的i的起始位置定为它的最长前缀的后一个元素,主串的起始位置就是失配点
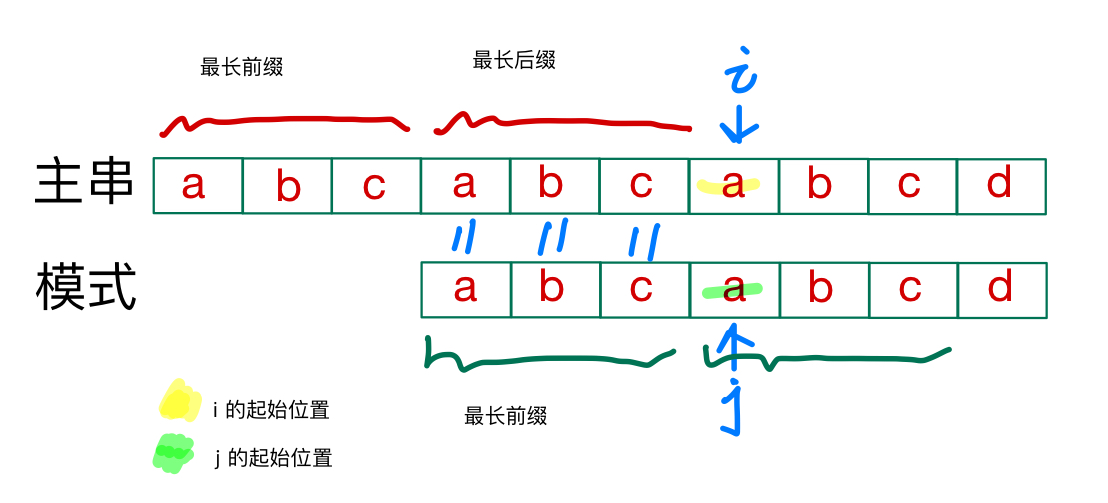
会发现模式中j起始位置之前的段就是之前的最长前缀,跟主串之前的最长后缀正好匹配,就不用从头开始检查了
所以模式的原最长前缀的后一个元素作为j的起始位置是合理且简单的
实现
面临一个问题
一旦失配,模式的j的起始位置就要变成失配点之前的段的最长前缀的后一个元素,但是在检查之前,我们并不知道模式会在什么位置失配,所以应该找到每个元素作为失配点的时候,j的起始位置应该在哪儿
所以要解决这个问题,就要先
找到模式中每个元素作为失配点的时候j的起始位置
如果失配点是模式的第一个元素,则没法回退(或者说不用回退),起始位置还是开头,但是主串的i需要向后后移
如果失配点是模式的第二个元素,它前面只有一个元素,没有“最长前缀”,只能向前回退,将第一个元素作为起始位置
剩下的第三到第N个元素的作为失配点的时候,起始位置就要找出来了
那就用指针x从第三个元素开始遍历模式
我们发现j的权重,正好等于j前面的字符串的长度,比如j=5,j之前的字符是从0~4,一共5个
那么j之前的字符串的前缀的长度k最长只能是5-1=4(因为最长前缀不能是字符串自己),也就是k=j-1
所以最长前缀的长度k取值范围是1~j-1,k也是最长后缀的长度
如果字符串长度j=5,k=4,那么j-k=1,这是正好是最长后缀的开头的权重,而最长前缀的开头永远都是字符串首元素,也就是权重是0
这就好办了,我们只要从最长前/后缀的长度开始下手就行,假设最长前缀长度k=j-1,检验前缀和后缀是否匹配,也就是前缀指针p从0开始,后缀指针q从j-k开始,往后比较。而因为p、q同步移动,且p从0开始,所以q其实等于j-k+p,我们比较p和j-k+q就可以
如果不匹配,就说明假设的这个最长前缀长度k比实际的最长前缀长度大了,我们只需要减小k就可以了
最后得出的k就是实际的最长前缀长度,而,k正好是最长前缀的后一个元素(比如k=3,则0~2是最长前缀,3上就是最长前缀的后一个元素)
可以自己画图理解
这样就找到了模式中每个元素作为失配点的时候j的起始位置
int *nextValue(const string &t) { int *next, q, j, k; //定义了一个next数组用来存放每个元素作为失配点的时候j的起始位置权重 if (t.length() == 0) //如果字符串是空的 return NULL; next = new int[t.length()]; next[0] = -1; //当第一个元素作为失配点的时候,不用退回,返回-1来告知 next[1] = 0; //当第二个元素为失配点的时候,j退回到首元素 for (j = 2; j < t.length(); j++) { for (k = j - 1; k > 0; k--) //从假设最长后缀长度为j-1开始 { for (q = 0; q < k; q++) //最长前缀q从开头开始,到假定的长度位置结束,与最长后缀进行匹配 { if (t.at(q) != t.at(j - k + q)) //如果匹配失败,就结束匹配 break; } if (q == k) //说明此时最长前缀已经匹配完,q已经指向了最长前缀的下一给元素 break; } next[j] = k; } return next; }int KMP(const string &s, const string &t, int start) //主串是s,模式是t,不一定从s的开头开始检查是否包含t,可能从s的start位置开始检查 { int *next; int pos = -1; int curStart; //模式的首元素在主串中的位置 int i = start, j = 0; next = nextValue(t); while (i <= (s.length() - t.length())) { curStart = i - j; //因为i、j是起始位置,但不两个串首元素位置,而模式中j到首元素之间的这些元素与主串中是匹配的,所以主串中从i往前j个元素就是模式首元素在主串中的位置 while (j < t.length() && (s.at(i) == t.at(j))) //先检查匹配 { i++; j++; } if (j == t.length()) //模式遍历完了,说明完全匹配 { pos = curStart; break; } else //出现失配 { if (next[j] == -1) //如果首元素就失配,只能让i后移 { ++i; j = 0; } else //说明失配点之前的段是匹配的,j去往相应初始位置 { j = next[j]; } } } return pos; }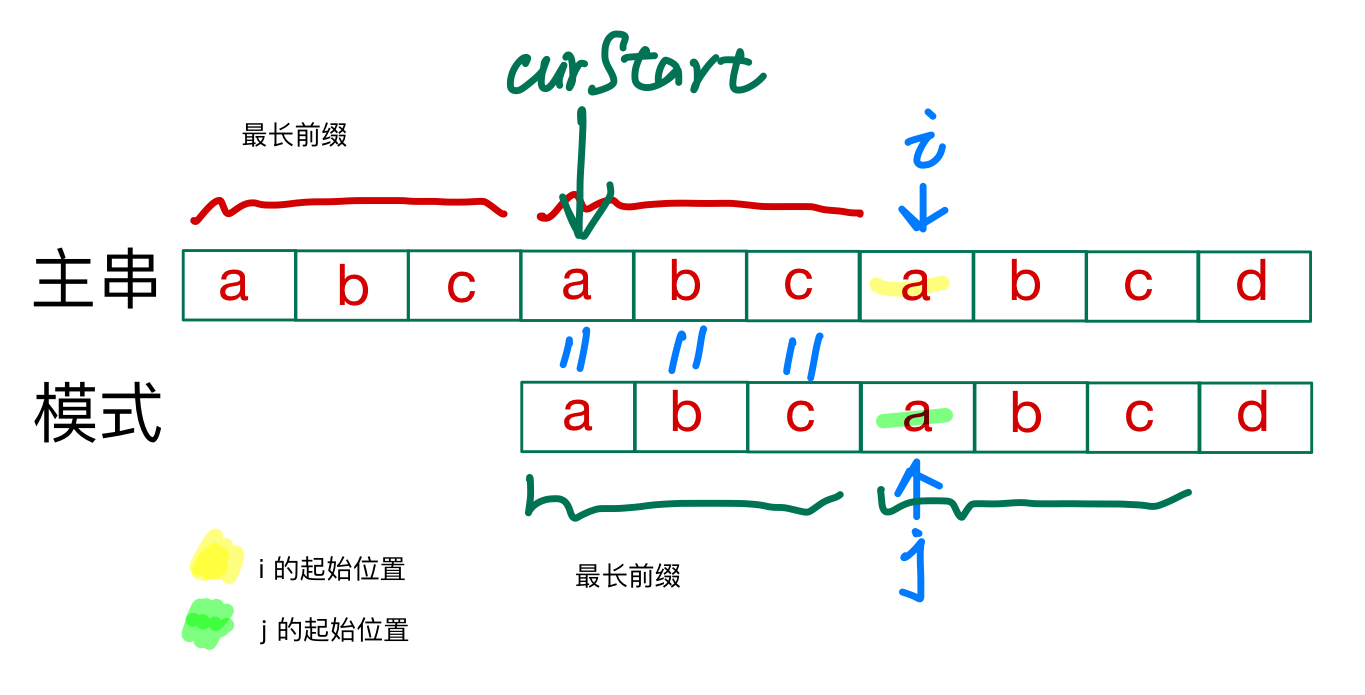
结束
That’s all, thanks for reading!💐















 533
533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









