






第一天的知识点总结。
一 内存图
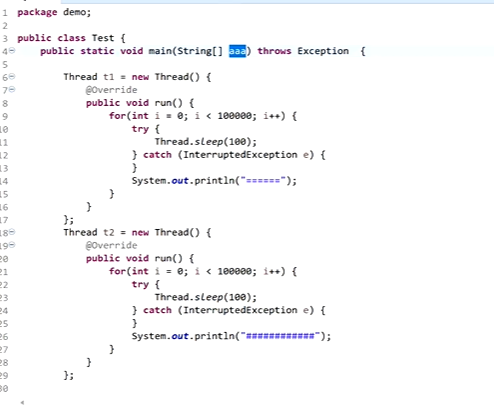
1 main方法先入栈,因为Main是由static修饰的所以main在方法区,拷贝一份放到栈里。Main方法的变量aaa先入栈,之后t1,t2压入栈。(在JAVA中t1,t2是引用类型变量,底层是c语言指针(两个入栈的变量说白了是两个指针))。
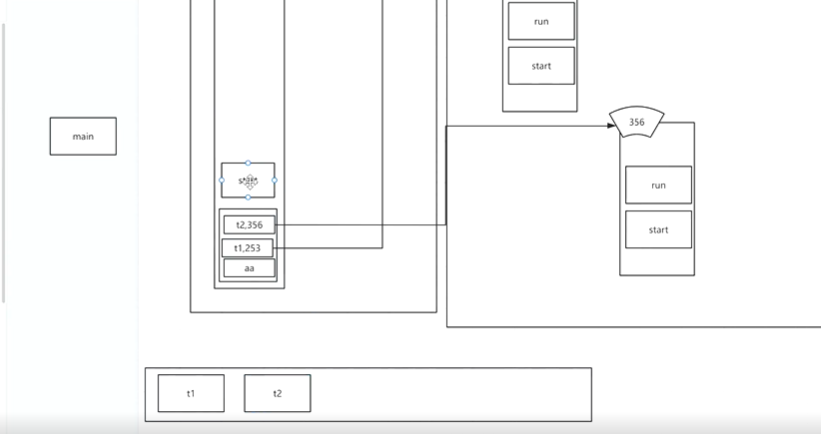
2 new了两个线程对象,就是在底层创建了两个对象(C语言malloc创建空间),在堆区域开辟两份空间。在已知的代码里t1,t2有重写的run()方法和调用的start()法都是非静态方法,在每一个对象(堆空间)里都有。创建好后并未执行。
3 t1.start()执行时,先拷贝堆里t1的start方法入栈,start方法会会把整个它的线程信息提交给操作系统的就绪队列,执行后出栈。t2同理。
4 t1和t2进入就绪队列后就随机选中创建t1或t2线程。假如先选择了t1线程,t1的run方法从堆里拷贝一份入t1线程栈,在调用run方法时会执行到Thread.sleep。由类(thread)直接调用的方法是静态方法,放在方法区。接着两个线程交互执行10000次。
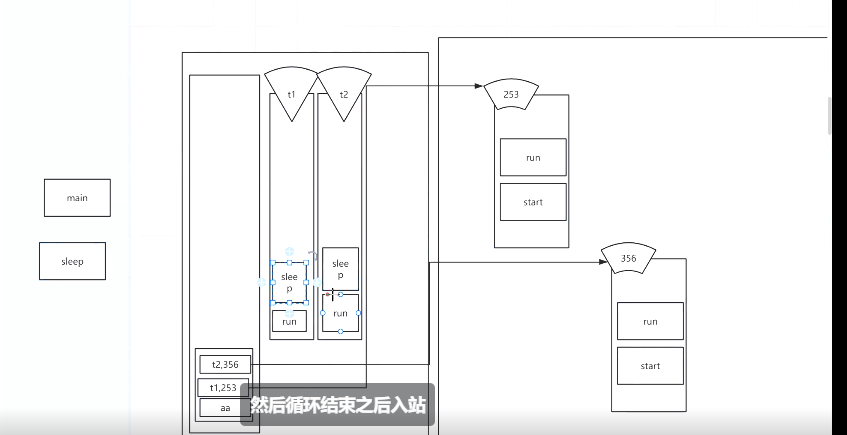
5 主线程创建子线程,进入就绪队列后相互独立。进入队列后谁都有可能先执行。(先进入的被选中的概率大,但顺序不确定)。
上下文切换
cpu每次执行后把把你记录下来执行到哪了,下次再执行你的时候从哪开始执行。
下文切换(Context Switch) 是指 CPU 从一个进程或线程切换到另一个进程或线程时执行的操作。这个过程涉及保存当前执行上下文(如寄存器值、程序计数器等)并加载新的执行上下文。上下文切换通常发生在以下场景:
- 多任务处理:操作系统需要在多个进程 / 线程之间共享 CPU 时间。
- 中断处理:当硬件中断发生时,CPU 需要暂停当前任务去处理中断。
- 系统调用:进程请求操作系统服务时,会触发从用户态到内核态的切换。
上下文切换的开销(毫秒级)
上下文切换的时间开销通常在 几微秒到几毫秒 之间,具体取决于:
- 硬件性能:现代 CPU 通过高速缓存(如 TLB、寄存器文件)优化切换速度。
- 操作系统:不同操作系统的上下文切换机制效率不同(如 Linux 的 O (1) 调度器)。
- 切换类型:
- 进程切换:涉及虚拟内存空间的切换,开销较大(通常几十微秒到毫秒级)。
- 线程切换:同一进程内的线程共享虚拟内存,仅切换线程上下文,开销较小(通常几微秒)。
上下文切换的步骤
- 保存上下文:将当前进程 / 线程的寄存器值、程序计数器等保存到内核空间。
- 调度决策:操作系统决定接下来执行哪个进程 / 线程(基于调度算法)。
- 加载上下文:从内核空间恢复新进程 / 线程的上下文。
- 刷新缓存:可能需要刷新 TLB(转换旁路缓冲器)以更新内存映射。
虽然单次上下文切换的时间看似很短,但在高并发场景下(如每秒数千次切换),其累积开销可能显著降低系统性能
测量上下文切换
Lmbench3 是测试上下文切换时长。
vmstat指令测量上下文切换次数。
减少上下文切换
减少上下文切换的方法有无锁并发编程、CAS算法、使用最少线程和使用协程。
多线程
何时使用多线程?(io 访问网络,访问硬盘)
-
CPU 密集型任务:
- 适用场景:计算密集型(如科学计算、图像处理),且多核 CPU 可用。
- 原理:多线程可并行利用多核 CPU,加速计算。
- 示例:视频编码、矩阵运算。
比如网络爬虫,电脑向网络爬取数据,来回各25ms,网络执行处理2ms,cpu执行1ms。那么在这53ms的时间里只有1mscpu在运行,其余时间就浪费了。cpu可用剩余52ms做别的事情,爬虫的工作也并行执行。
-
I/O 密集型任务:
- 适用场景:频繁等待 I/O(如网络、磁盘),需保持响应性。
- 原理:线程在 I/O 等待时让出 CPU,其他线程可继续执行。
- 示例:Web 服务器、数据库读写、文件上传下载。
-
异步或并行操作:
- 适用场景:需同时执行多个独立任务(如后台任务与 UI 交互)。
- 示例:
- 桌面应用中,主线程处理 UI,子线程执行耗时操作(如文件解压)。
- 微服务中,并行调用多个外部 API。
-
提高资源利用率:
- 适用场景:需充分利用 CPU 和 I/O 资源(如数据库连接池)。
- 示例:数据库客户端使用多线程同时处理多个查询请求。
何时避免使用多线程?
-
单线程即可高效完成:
- 场景:任务简单且无需并发,多线程反而增加开销。
- 示例:简单脚本、一次性数据处理。
比如说执行for循环(1-1亿),若只有一个cpu。把循环拆成多个线程,一会执行这个线程,一会执行那个,就会不断的切换上下文。速度就慢。
-
资源竞争严重:
- 场景:多线程频繁访问共享资源(如全局变量),需频繁同步。
- 风险:锁竞争导致性能下降,甚至死锁。
- 替代方案:使用无锁数据结构(如原子操作)或协程。
-
任务间强依赖:
- 场景:任务需按顺序执行,后序任务依赖前序结果。
- 示例:串行数据流处理(如数据清洗→分析→存储)。
-
维护成本过高:
- 场景:多线程调试复杂(如竞态条件、死锁),且收益不明显。
- 替代方案:使用异步编程(如 Python 的 asyncio、JavaScript 的 Promise)。
-
单核 CPU 环境:
- 场景:多线程无法并行,仅能通过切换实现 “伪并发”。
- 例外:I/O 密集型任务仍可能受益(如等待 I/O 时切换线程)。
多线程一定快吗?
下面的代码演示串行和并发执行并累加操作的时间,请分析:下面的代码并发执行一定比 串行执行快吗
public class ConcurrencyTest {
private static final long count = 10000l; // 循环次数
public static void main(String[] args) throws InterruptedException {
concurrency(); // 先执行并发测试
serial(); // 再执行串行测试
}
private static void concurrency() throws InterruptedException {
long start = System.currentTimeMillis();
Thread thread = new Thread(() -> {
int a = 0;
for (long i = 0; i < count; i++) {
a += 5;
}
});
thread.start(); // 启动子线程
int b = 0;
for (long i = 0; i < count; i++) {
b--;
}
long time = System.currentTimeMillis() - start; // 计时错误点!
thread.join(); // 等待子线程完成
System.out.println("concurrency :" + time + "ms, b=" + b);
}
private static void serial() {
long start = System.currentTimeMillis();
int a = 0;
for (long i = 0; i < count; i++) {
a += 5;
}
int b = 0;
for (long i = 0; i < count; i++) {
b--;
}
long time = System.currentTimeMillis() - start;
System.out.println("serial:" + time + "ms, b=" + b + ", a=" + a);
}
}流程
定义循环次数为 10000 次(注意这里的l是小写字母 L,表示长整型,建议用大写L避免混淆)。
并发执行方法 concurrency()多线程
创建一个新线程执行累加操作(a += 5循环 10000 次)。主线程同时执行递减操作(b--循环 10000 次)。
计时错误:time的计算发生在thread.join()之前,这会导致统计的时间仅包含主线程(b--)执行时间,而不包含子线程(a+=5)的完整执行时间
thread.start();
// 主线程执行b--循环
thread.join(); // 等待子线程完成
long time = System.currentTimeMillis() - start; // 正确统计总耗时thread.join
在多线程编程中,thread.join() 是一个常用的方法,用于让主线程(或调用线程)等待某个子线程执行完毕后再继续执行。此题中在子线程执行后才能执行System.out.println("concurrency :" + time+"ms,b="+b);而time在子线程执行完之前就计算了。
- 阻塞主线程:当主线程调用
thread.join()时,主线程会暂停执行,直到被调用的子线程完成。 - 确保执行顺序:常用于需要等待子线程结果才能继续执行的场景(如并行计算后的结果汇总)。
concurrency 执行完后,子线程也就结束了。
串行执行方法 serial()单线程
主线程依次执行两个循环(从上往下执行):先执行 a += 5 循环,再执行 b-- 循环。主线程计时并打印完整耗时和结果。
死锁
锁是个非常有用的工具,运用场景非常多,因为它使用起来非常简单,而且易于理解。但 同时它也会带来一些困扰,那就是可能会引起死锁,一旦产生死锁,就会造成系统功能不可 用。让我们先来看一段代码,这段代码会引起死锁,使线程t1和线程t2互相等待对方释放锁。
public class DeadLockDemo {
privat static String A = "A";
private static String B = "B";
public static void main(String[] args) {
new DeadLockDemo().deadLock();
}
private void deadLock() {
Thread t1 = new Thread(new Runnable() {
@Override
publicvoid run() {
synchronized (A) {
try { Thread.currentThread().sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (B) {
System.out.println("1");
}
}
}
});
Thread t2 = new Thread(new Runnable() {
@Override
publicvoid run() {
synchronized (B) {
synchronized (A) {
System.out.println("2");
}
}
}
});
t1.start();
t2.start();
}
}
注意到main方法是静态方法,在方法区直接调用,但deadLock是非静态的,不能直接用类调用。必须先创建对象。
public static void main(String[] args) {
new DeadLockDemo().deadLock();
}
private void deadLock() {synchronized (A)只能锁引用类型(类,数组,借口以及这里的字符串)。在{}内执行完才会释放锁。
sleep当进入睡眠状态后会立即让出cpu。也不会释放锁。
synchronized (A) {
try { Thread.currentThread().sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (B) {
System.out.println("1");
}
}sleep和wait区别 (sleep让出cpu,不释放锁)(wait让出cpu,也释放锁)。
此代码会出现死锁,但小概率会让t2先执行(t2.start),若是t2顺利执行完就不会死锁。
如何避免死锁
破坏互斥条件
- 互斥条件是指资源在某一时刻只能被一个进程所占有。在一些情况下,可以通过使用可共享的资源来替代独占资源,以此破坏互斥条件。例如,将打印机等独占设备改造为可共享的网络打印机,多个进程可以按照一定的顺序排队使用,而不是独占该设备。
破坏请求和保持条件
- 静态分配资源:要求进程在开始执行前一次性申请它所需要的所有资源,只有当系统能满足进程的所有资源请求时,才把资源分配给该进程,这样进程在执行过程中就不会再请求其他资源,从而破坏了请求和保持条件。例如,一个程序需要使用到数据库连接、文件读写权限和网络端口等资源,在程序启动时就一次性申请这些资源,若有任何一个资源申请失败,则整个程序都不启动。
- 逐步分配并释放:进程可以逐步请求资源,但在请求新资源时,不能持有其他资源。如果进程需要新的资源,必须先释放当前已持有的资源,然后再尝试请求新资源和重新获取已释放的资源。例如,一个进程在处理完一部分数据后,先释放用于存储该部分数据的内存空间,再去请求用于处理下一部分数据的其他资源。
破坏不可抢占条件
- 当一个进程占有了某些资源但又不能满足其对新资源的请求时,系统可以强行剥夺该进程已占有的资源分配给其他进程。例如,对于内存资源,如果一个进程占用了大量内存且长时间不释放,而其他进程又急需内存空间,操作系统可以根据一定的策略,如优先级等,将该进程的部分内存空间剥夺并分配给其他更需要的进程。
破坏循环等待条件
- 资源按序分配:给系统中的资源编号,规定进程必须按照资源编号的顺序请求资源。例如,系统中有打印机、扫描仪、绘图仪等设备,分别编号为 1、2、3。进程在请求资源时,只能先请求编号小的资源,再请求编号大的资源,这样就不会形成循环等待链。
- 检测和解除:系统可以设置一个死锁检测机制,定期检查系统中是否存在死锁。如果检测到死锁,可以通过撤销某些进程、释放它们所占有的资源来解除死锁。例如,当检测到死锁时,系统可以选择撤销优先级较低的进程,释放其资源,使其他进程能够继续执行,从而打破死锁状态。
volatile的应用
synchronized读和写都安全,volatile读安全写不安全。
volatile它在多处理器开发中保证了共享变量的“可见性”。可见性的意思是当一个线程 修改一个共享变量时,另外一个线程能读到这个修改的值。如果volatile变量修饰符使用恰当 的话,它比synchronized的使用和执行成本更低,因为它不会引起线程上下文的切换和调度。(这句不太准确,因为上下文切换调度是操作系统决定的)
volatile定义
Java语言规范第3版中对volatile的定义如下:Java编程语言允许线程访问共享变量,为了确保共享变量能被准确和一致地更新,线程应该确保通过排他锁单独获得这个变量。Java语言提供volatile,在某些情况下比锁要更加方便。如果一个字段被声明成volatile,Java线程内存模型确保所有线程看到这个变量的值是一致的。
1)将当前处理器缓存行的数据写回到系统内存。
2)这个写回内存的操作会使在其他CPU里缓存了该内存地址的数据无效
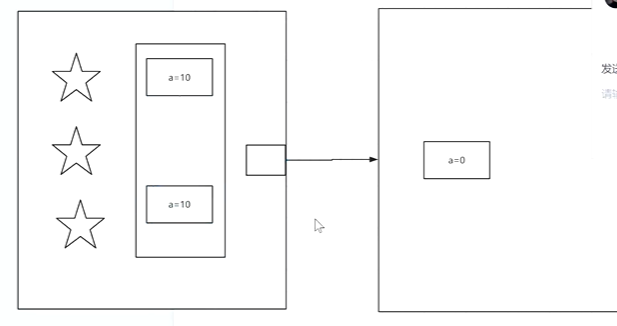
比如上面的a=10回到内存,那么下面的就会失效。
前置知识:
比如说这么个例子当cpu是三核并且只有一条总线的情况下,现在有三个线程都要执行for循环1000次。当A进入cpu了,其他的都不能进入。第一次循环后A放回内存,紧接这第二次循环,A再进入cpu。abc还是顺序执行,多核cpu就没有意义。
通过总线cpu向内存传输指令(单个导线同一时刻只能过一个电压信号)。指令在总线处要排队传输,这也就意味着我们的内存同一时刻只能被一个指令所访问。同一时刻只能被指令所指挥。
解决方法:在cpu放一个内存,A进入cpu并执行后,放到cpu的内存里,再调用的时候直接从cpu里找。BC也能通过总线进入cpu。
在任务管理器里可以看到

L1L2L3缓存就是上面说到的cpu内存
那么要是单个核心,我这里的单个核心的速度是2.5GHz 就是1秒2.5*10^30次。cpu利用不充分。
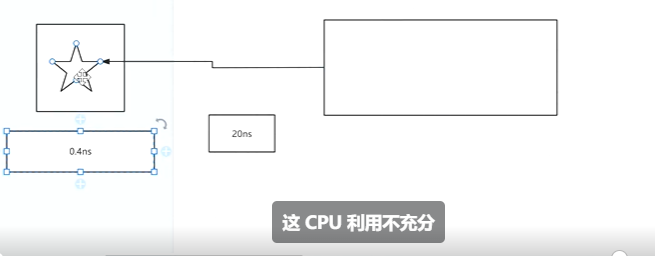
设计多核缓存是为了提高每个核心利用率。
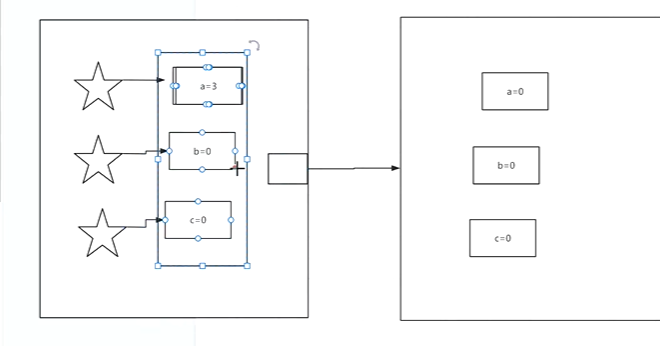
相互覆盖问题。
两个核心都+10,本来是=20,但在传回内存后相互覆盖还是10。此外高速缓存往内存回更新后会清空。

cpu术语
 原子操作
原子操作
一、基础概念
1. 什么是原子操作?
- 定义:不可被中断的一个或一组操作,要么全部执行成功,要么全部失败。
- 示例:
- Java 中的
int a = 1是原子操作,但a++不是。 - CAS(Compare-And-Swap)是典型的原子操作。
- Java 中的
2. 为什么需要原子操作?
- 解决竞态条件:多线程同时修改共享变量时,原子操作可避免数据不一致。
- 替代锁:相比
synchronized,原子操作更轻量,性能更高。
二、Java 中的原子类
1. 常用原子类及其应用场景
| 分类 | 典型类 | 应用场景 |
|---|---|---|
| 基本类型 | AtomicInteger | 计数器、ID 生成器 |
AtomicLong | 统计累计值 | |
AtomicBoolean | 状态标志(如初始化完成) | |
| 引用类型 | AtomicReference | 原子更新对象引用 |
AtomicStampedReference | 解决 ABA 问题(带版本号) | |
| 数组类型 | AtomicIntegerArray | 原子更新数组元素 |
| 字段更新 | AtomicIntegerFieldUpdater | 原子更新对象的字段 |
任务
System.out.println() 是静态方法还是非静态方法
System.out.println() 是一个静态方法调用链。System 是 Java 标准库中的一个静态类(final 类,所有成员都是静态的)。out 是 System 类中的一个静态字段(static PrintStream out),它代表标准输出流。println() 是 PrintStream 类的实例方法(非静态方法)。由于 System.out 返回的是一个 PrintStream 实例,因此可以直接调用该实例的方法。
System.out.println("Hello");
↑ ↑ ↑
静态类 静态字段 实例方法验证
如果 println() 是静态方法,以下代码应该合法。
PrintStream.println("Hello"); // 错误!无法编译但实际上必须通过实例调用:
PrintStream ps = System.out;
ps.println("Hello"); // 正确总结
System.out是静态的:通过类名直接访问(System.out)。println()是非静态的:必须通过PrintStream实例调用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









