






 https://bz.zzzmh.cn/index
https://bz.zzzmh.cn/index一、混淆简介
1、为什么要进行混淆
- 保护开发工程师源码
- 反爬
- js代码运行于客户端,它必须在用户浏览器端加载并运行
- js代码是公开透明的,也就是说浏览器可以直接获取到正在运行的javascript的源码
1、压缩、混淆、加密技术
代码压缩:
去除js代码中的不必要的空格、换行等内容。使源码压缩为几行内容,降低代码可读性,提高网站的加载速度。
代码混淆:
使用变量替换、僵尸函数、字符串阵列化、控制流平坦化、调试保护等手段,使代码变得难以阅读和分析,达到最终保护的目的,不影响代码原有功能,是理想、实用的javascript保护方案。
代码加密:
可以通过某种手段将js代码进行加密,转成人无法阅读或者解析的代码,如将代码完全抽象化加密,如eval加密,.......
二、OB混淆。
两个代码,实现方式是一样的。
1、ob混淆的特点:
- 一般由一个大数组或者含有大数组的函数,一个自执行函数、解密函数和加密后的函数四部分组成。
- 函数名和变量名通常以_0x或者0x开头,后接1~6位数字或字母组合
- 自执行函数,进行移位操作,由明显的push、shift关键字
2、ob混淆结构
一般obfuscator 混淆的代码分为以下几部分
- 定义一个数组:
- 重构数组
- 自解密函数
- 真实代码
- 可以删除的垃圾代码
3、ob混淆介绍
Javascript混淆完全是在javascript上进行的处理,它的目的就是使得javascript变得难以阅读和分析,大大降低代码可读性,是一种很实用的javascript保护方案。
Javascript混淆技术主要有以下几种
1、变量混淆:
2、字符串混淆:
进行MD5或base64加密存储,使代码中不出现明文字符串,可以避免使用全局搜索字符串的方式定位到入口点。
3、属性加密:
4、控制流平坦化:
打乱函数原有代码执行流程及函数调用关系,使代码逻辑变得混乱无序。
5、僵尸代码:(假代码)
随机在代码中插入无用的僵尸代码、僵尸函数,使代码逻辑变得混乱
6、调试保护:
加一些强制调试debugger语句,使其在调试模式下难以顺利执行js代码。
7、多态变异:
8、锁定域名:
使js代码只能在指定域名下执行
9、反格式化,
如果对js代码进行格式化,则无法执行,导致浏览器假死
10、特殊编码:
表情符号,特殊表示内容等
4、实现ob混淆
1、安装ob混淆库:npm install javascript-obfuscator -g(-g是安装到全局)
npm install javascript-obfuscator -s
安装完成后,javascript-obfuscator就是一个独立的可执行命令了。
三、案例一-极简壁纸_逆向分析
1、逆向目标
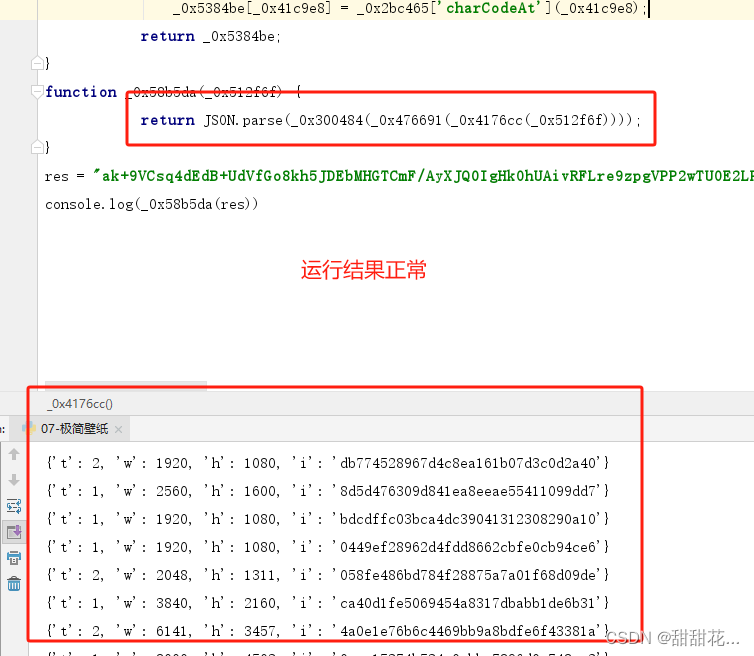
目标:result `ak+9VCsq4dEdB+UdVfGo8kh5JDEbMHGTCmF/`
2、逆向分析
1、XHR断点,点击页数发包,ajax错误的回调。(这是一个ajax错误请求的发包)
2、在调用堆栈分析,从上往下找,直到找到ajax发包的位置。
post、then关键字
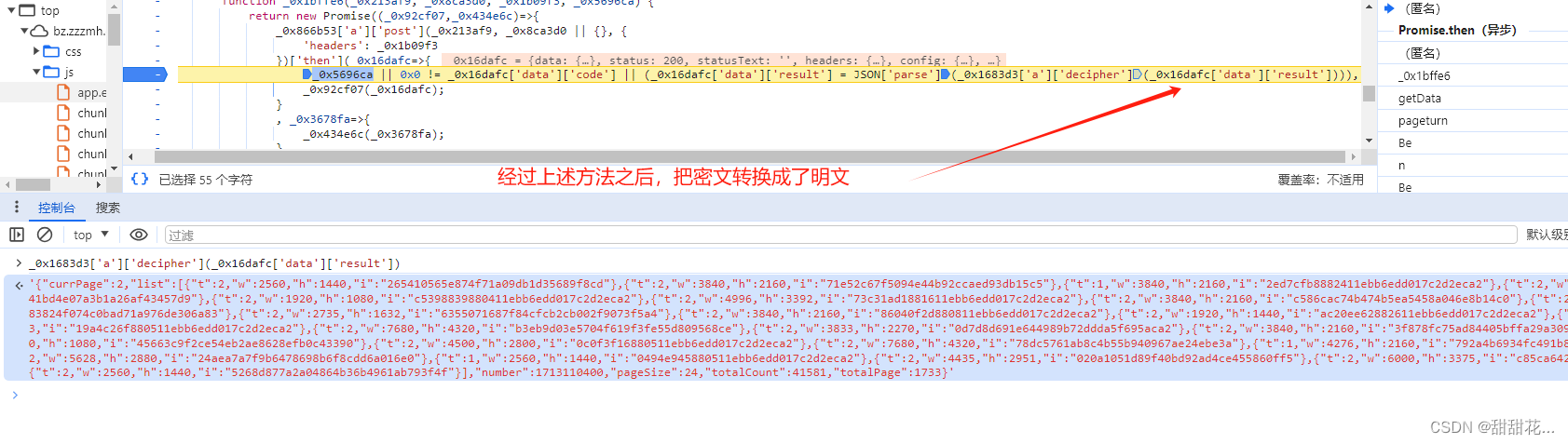
进入该方法:
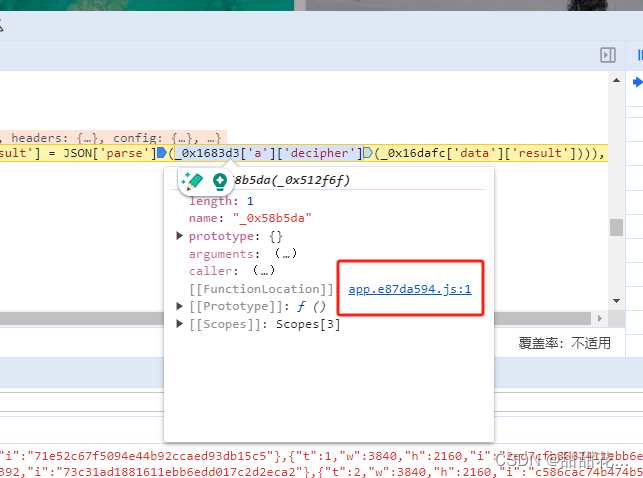
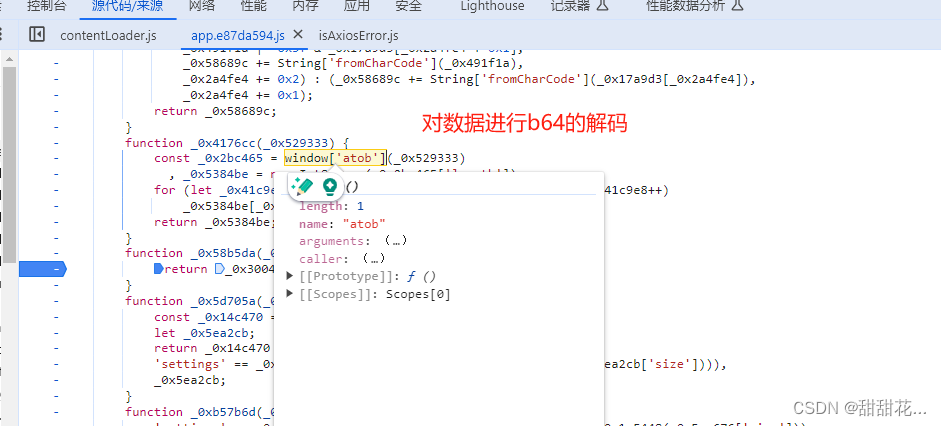
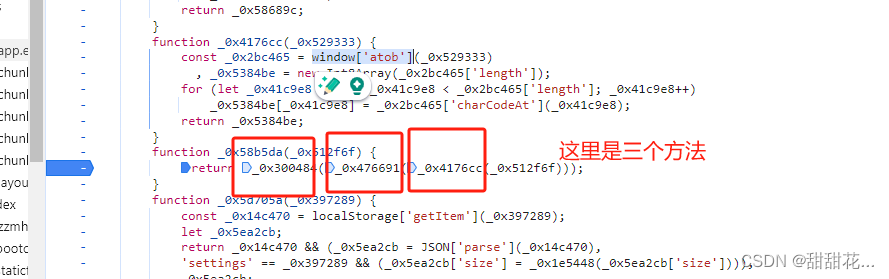
进入第三个方法的内部:
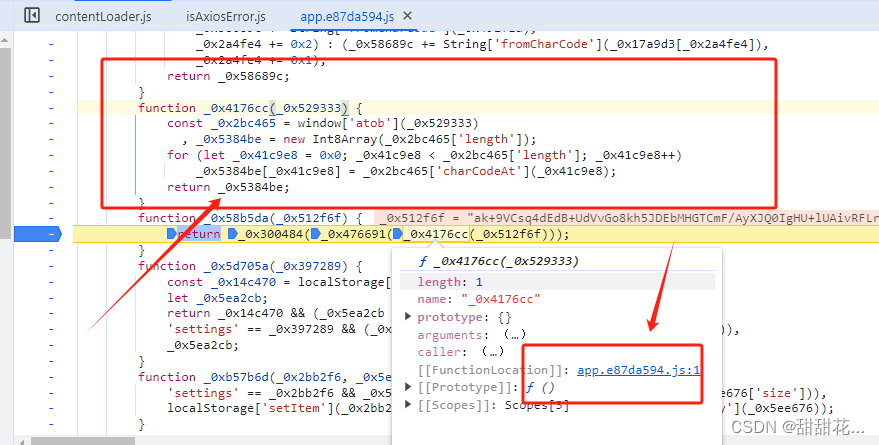
2.1分析解密数据
1、分析代码:(对数据解密的代码)
扣代码结果: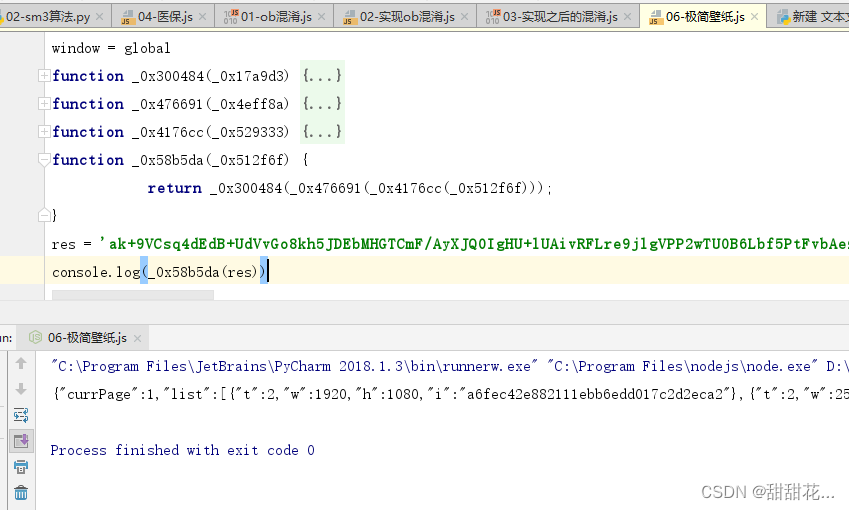
2.2 分析壁纸信息
1、清空浏览器发包数据,清除断点,点击壁纸重新发包。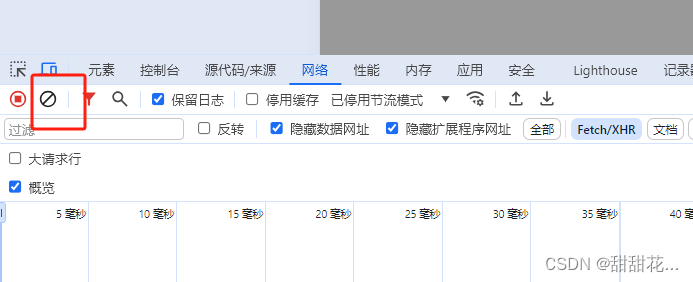
这里的数据其实是一样的。
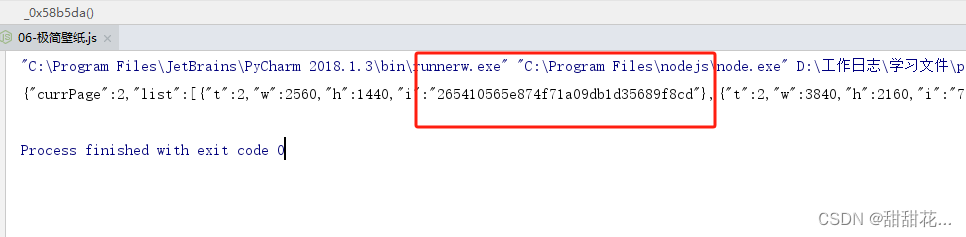
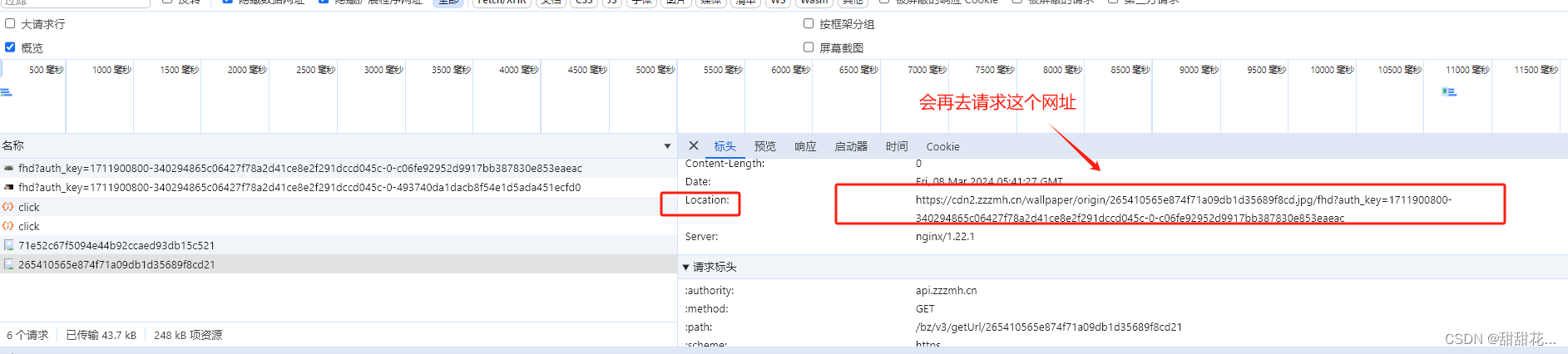
重定向多半会响应一个location

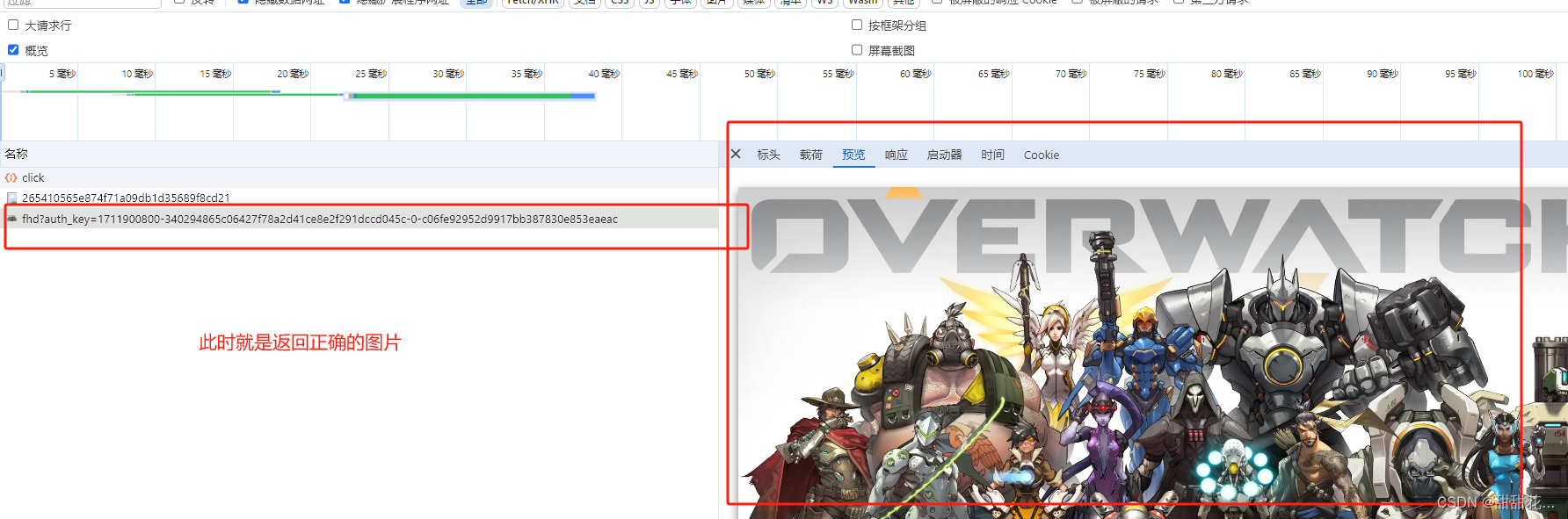
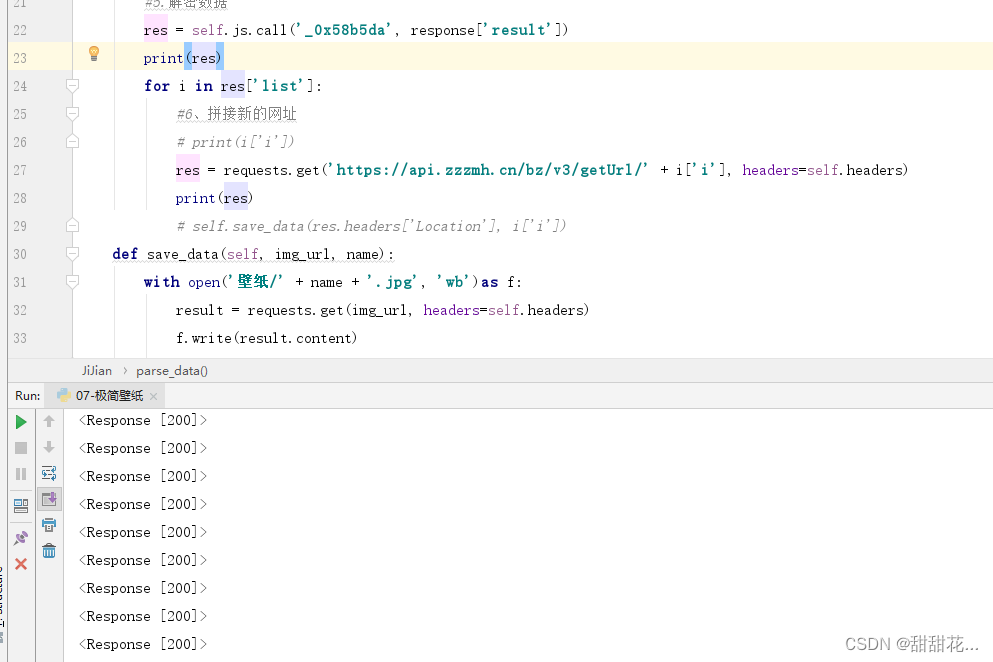
2、复制python代码,结果报错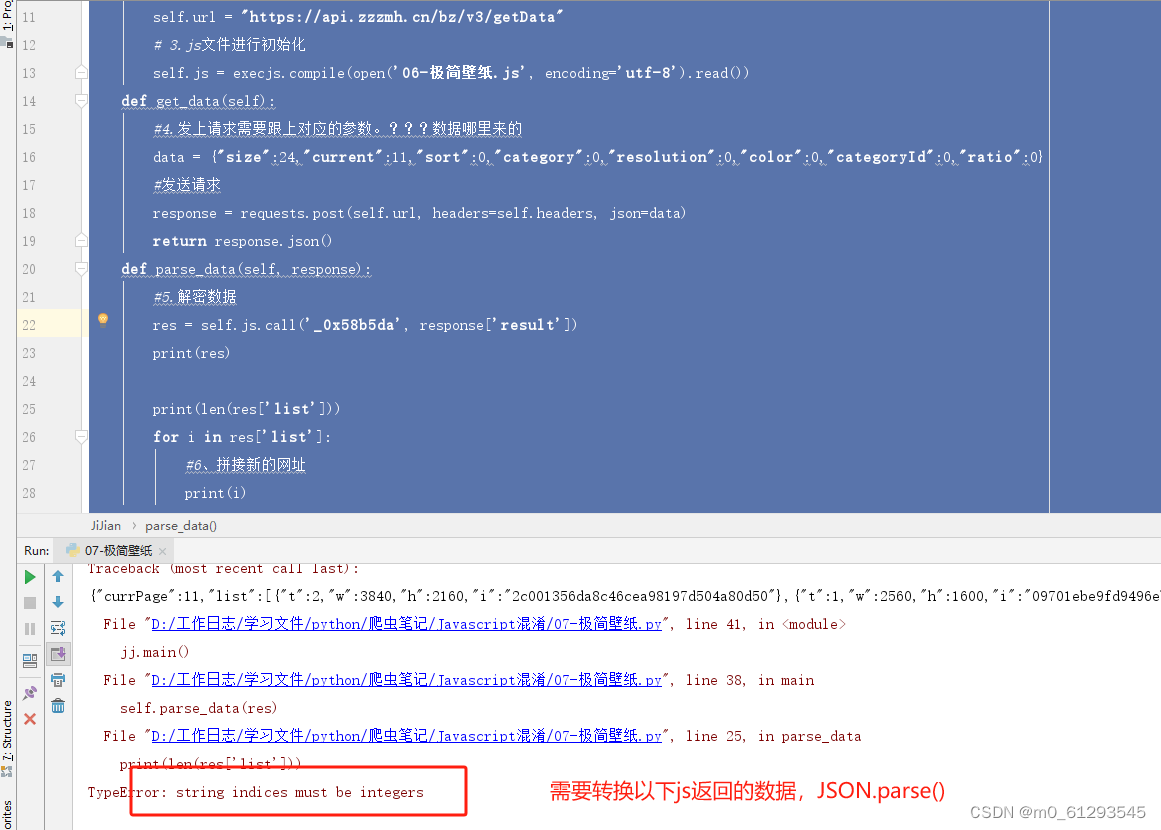
1、怎么获取响应头的location
禁止当前请求地址跳转

需要注意当前参数,后面都跟着一个21,所以需要在代码里面拼接上,才能执行代码成功输出Location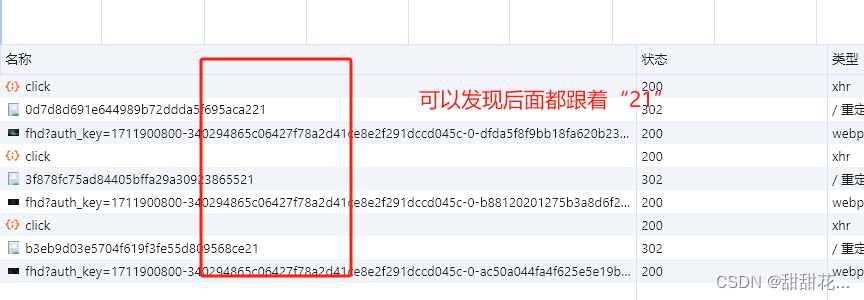
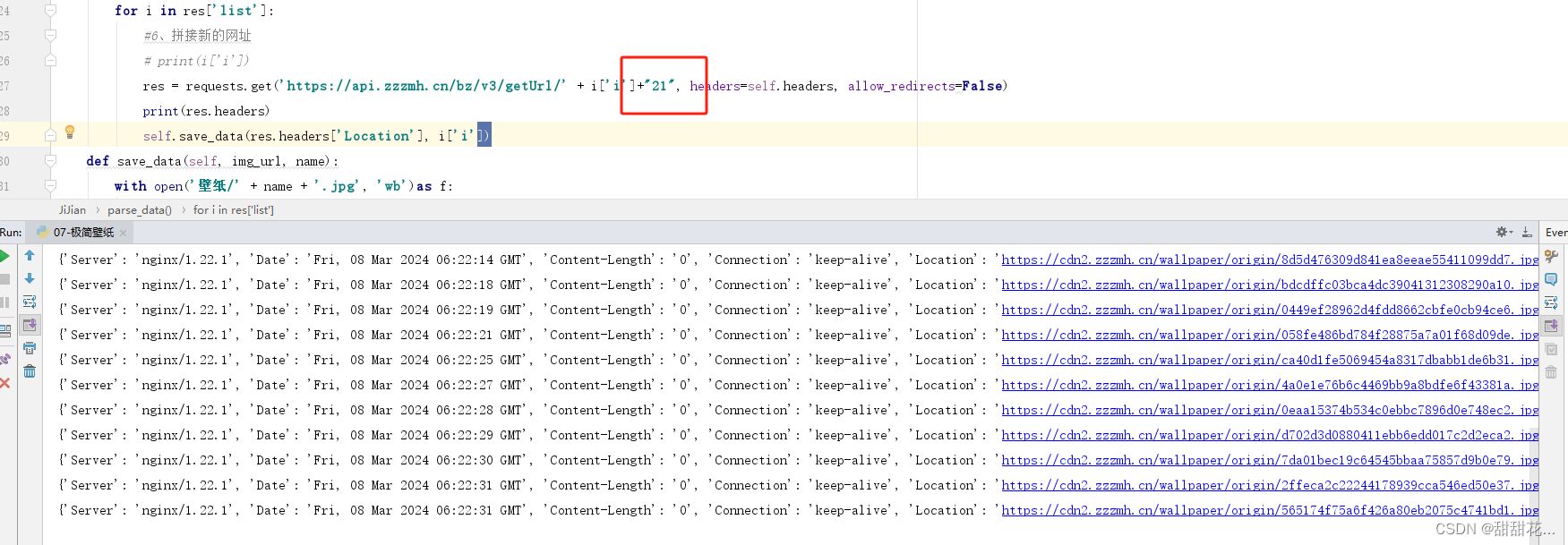
注意:后面报错,可能是壁纸文件夹没有创建。
2、源代码:
import requests
import execjs
class JiJian():
def __init__(self):
#1.请求头
self.headers = {
"referer": "https://bz.zzzmh.cn/",
"user-agent": "Mozilla/5.0 (X11; Linux aarch64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.188 Safari/537.36 CrKey/1.54.250320"
}
#2 .请求网址
self.url = "https://api.zzzmh.cn/bz/v3/getData"
# 3.js文件进行初始化
self.js = execjs.compile(open('06-极简壁纸.js', encoding='utf-8').read())
def get_data(self):
#4.发上请求需要跟上对应的参数。???数据哪里来的
data = {"size":24,"current":11,"sort":0,"category":0,"resolution":0,"color":0,"categoryId":0,"ratio":0}
#发送请求
response = requests.post(self.url, headers=self.headers, json=data)
return response.json()
def parse_data(self, response):
#5.解密数据
res = self.js.call('_0x58b5da', response['result'])
print(res)
for i in res['list']:
#6、拼接新的网址
# print(i['i'])
res = requests.get('https://api.zzzmh.cn/bz/v3/getUrl/' + i['i']+"21", headers=self.headers, allow_redirects=False)
print(res.headers)
self.save_data(res.headers['Location'], i['i'])
def save_data(self, img_url, name):
with open('壁纸/' + name + '.jpg', 'wb')as f:
result = requests.get(img_url, headers=self.headers)
f.write(result.content)
print('正在下载{}'.format(name))
def main(self):
res = self.get_data()
self.parse_data(res)
if __name__ == '__main__':
jj = JiJian()
jj.main()运行成功
3、解除无限debugger
Function.prototype.__constructor_back = Function.prototype.constructor;
Function.prototype.constructor = function() {
if(arguments && typeof arguments[0]==='string'){
if("debugger" === arguments[0]){
return
}
}
return Function.prototype.__constructor_back.apply(this,arguments);
}四、案例二-产业政策大数据平台
1、逆向目标
名称:octet-stream指任意类型的二进制流数据。
参数:
2、逆向分析
1、网页一打开就有一个无限debugger,可以判断这个网址是OB混淆自动防护。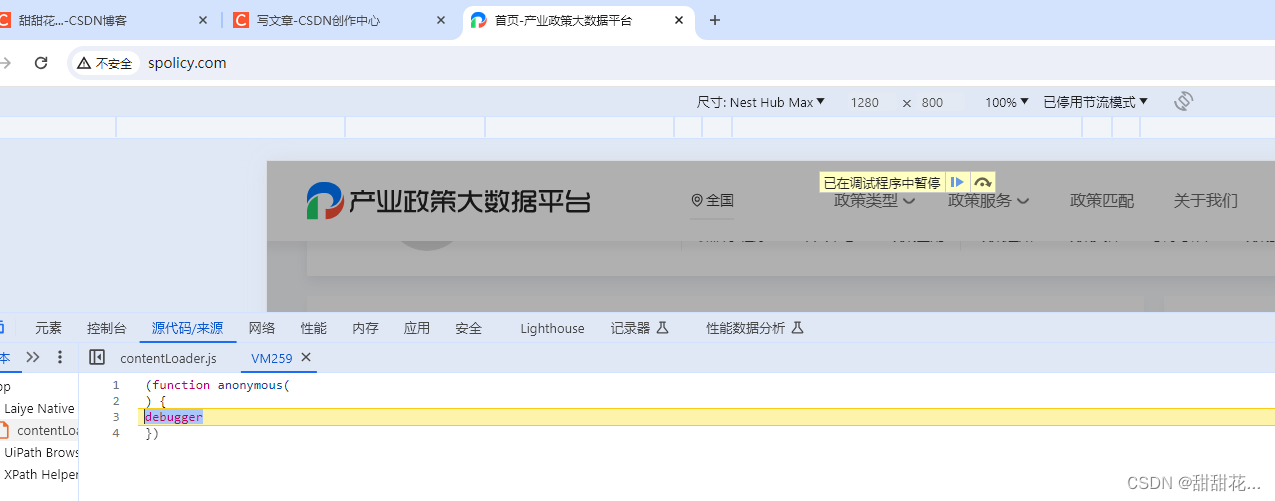
2、点击下一个栈分析数据
3、观察传递的两个参数是什么。(通过构造器创建debbuger的信息)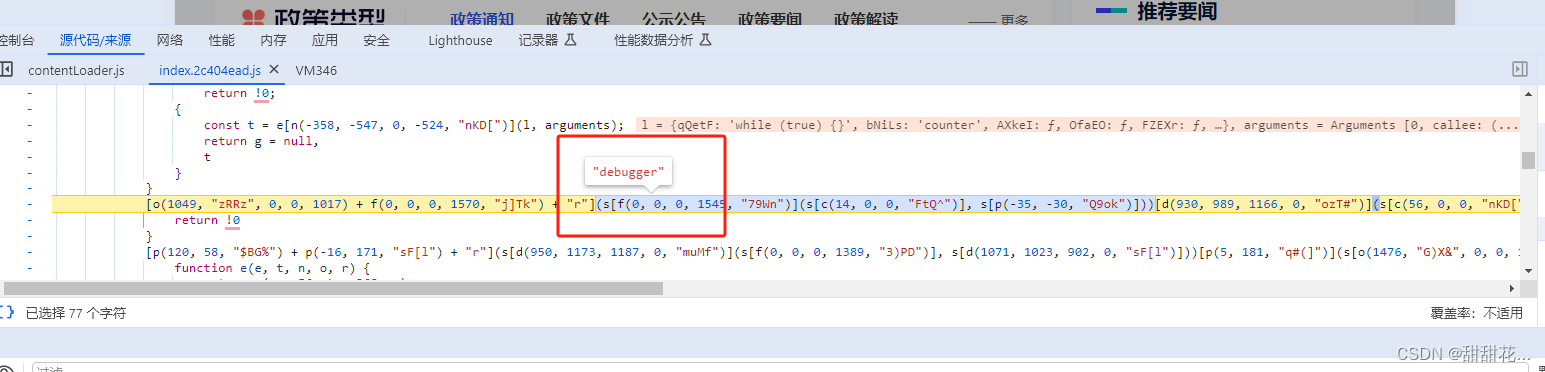
4、注意ob混淆无限debbuger,可能会导致你的网站很卡。因为ob会不断生成,我们需要置空,用【解除无限debugger】代码在控制台运行即可.
5、分析发包内容。点击发包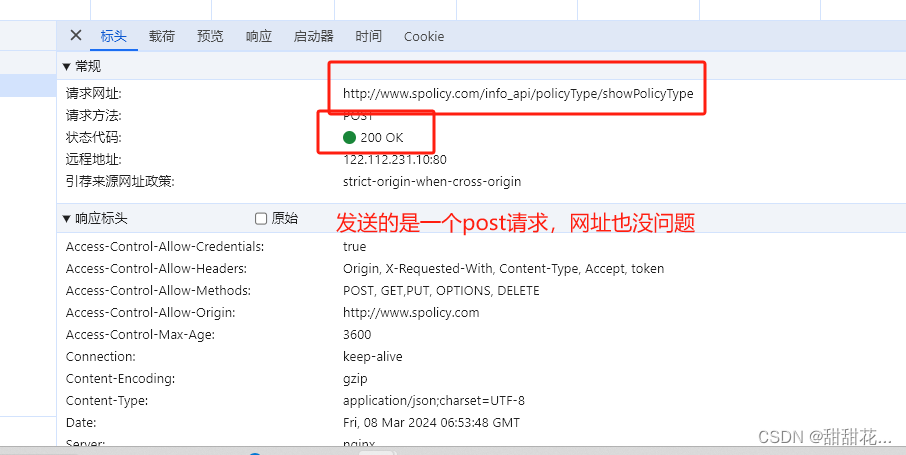
6、具体传什么参数,和标头请求头有关系。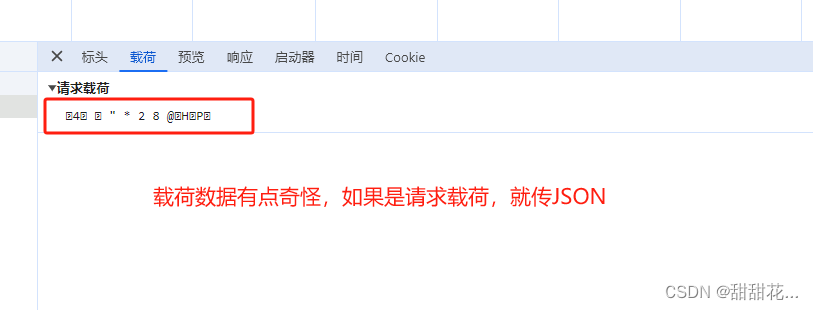
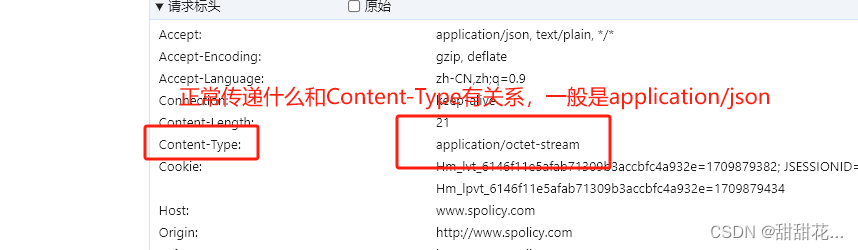
这传递的其实是一个进制内容。byte.
如果是请求载荷就传json,但是最准确的是看content-Type.
那载荷数据是怎么生成的呢。
7、触发XHR(加断点),请求的是当前的r、r是一个byte内容
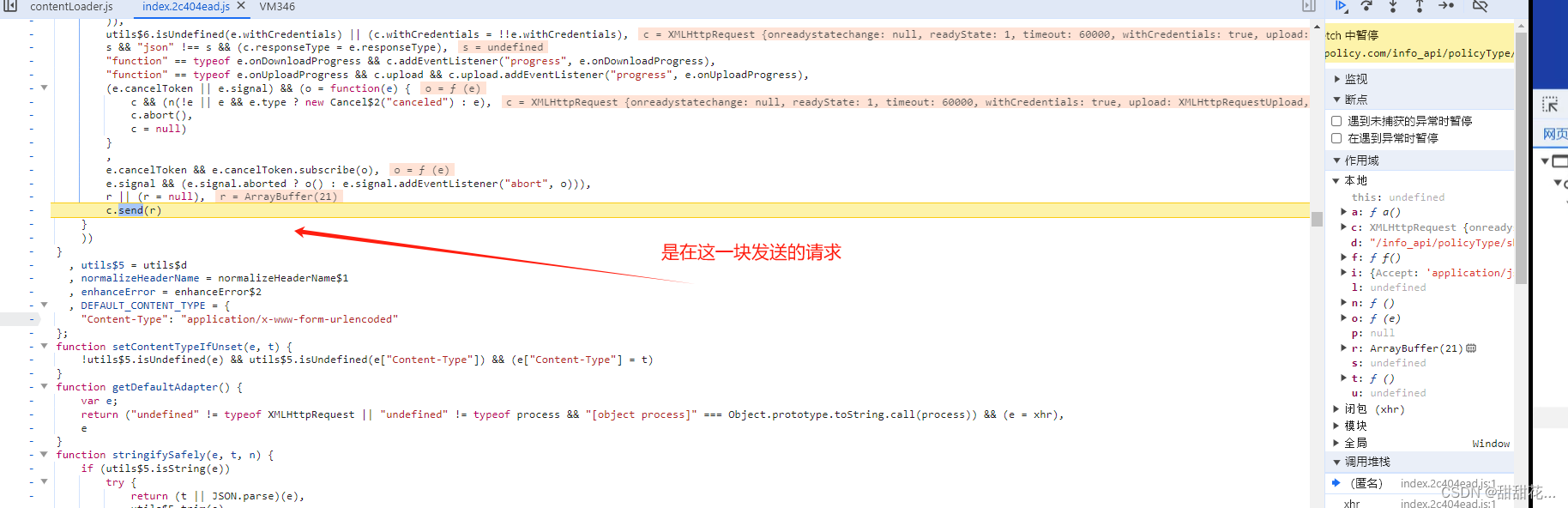
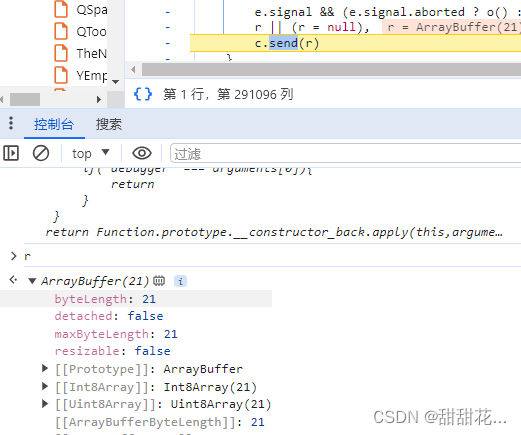
8、我们需要定位这个byte数据是在哪里生成的。看它发包的位置,看数据是不是一个明文。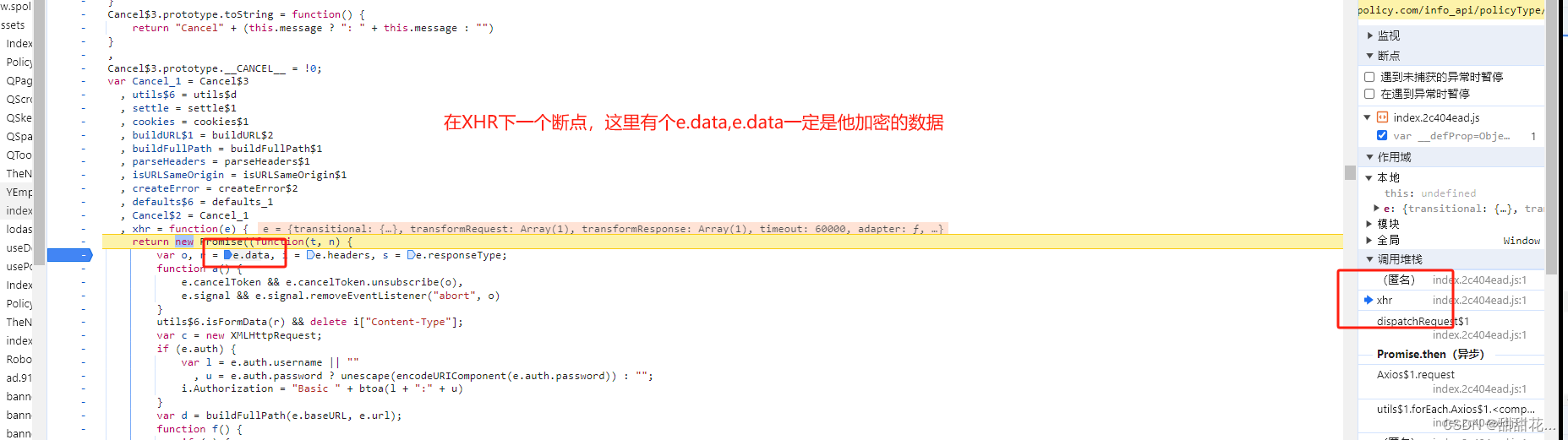
9、可以看到已经是加密的,可以判断是在上一步生成的。e的值是加密的,下个断点看一下。
这种情况,可能会在哪里进行加密。
三种情况
- 可能是在异步中间的代码生成的。
- 要么就在请求的拦截器里面(概率大一些)
- 或者是在之前的代码中生成的。
找拦截器的方式
1、先找响应拦截器。(会容易一些)往下调试,找响应拦截器的位置。要多注意观察Intercepors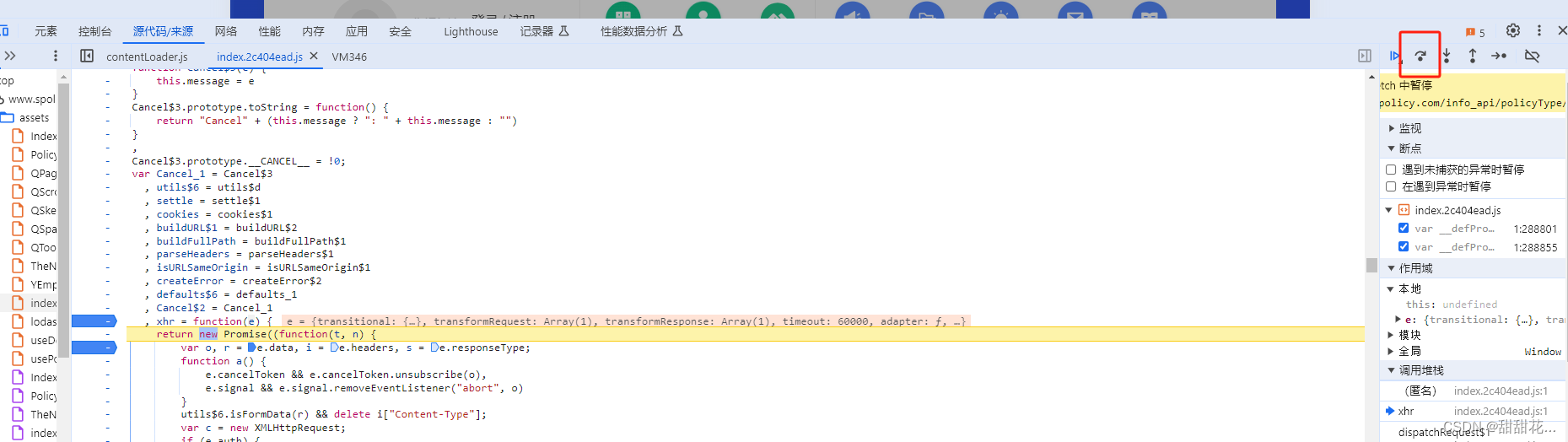
2、还是关注有没有axios关键词旁边有没有interceptors
跳出当前函数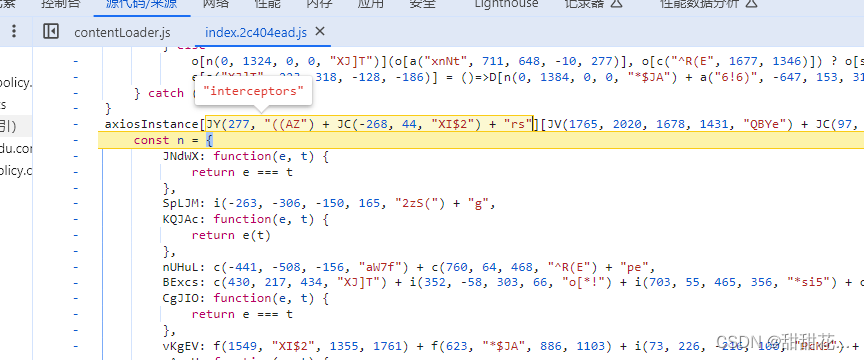
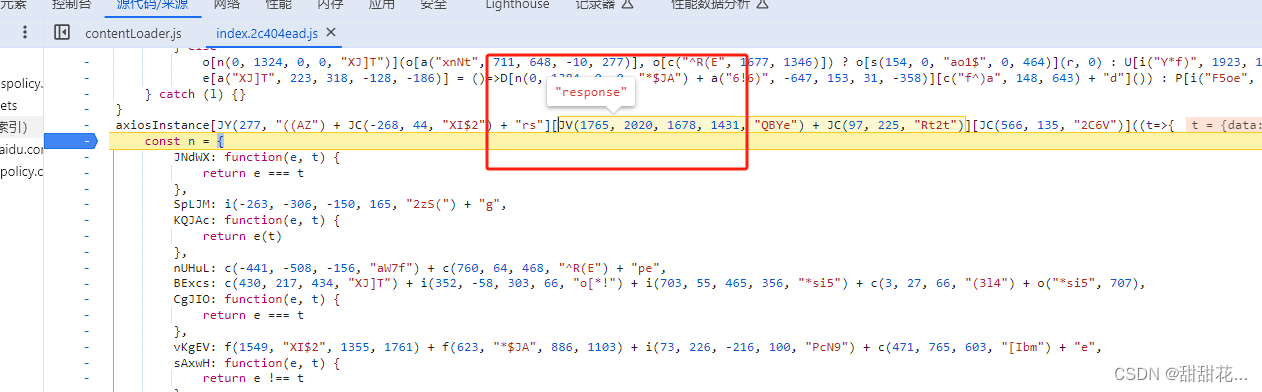
3、请求拦截器也可以找该关键字。下个断点,重新发包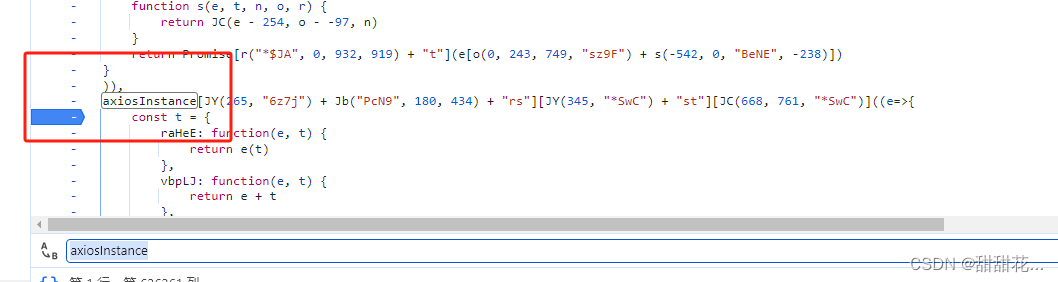
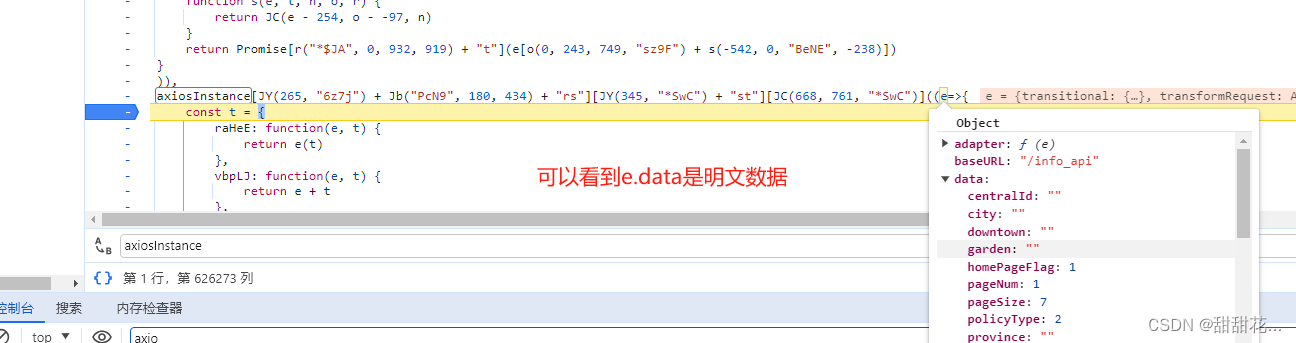
在请求拦截器里面是明文,加密多半是在拦截器里面生成的。
正常网站都是先考虑拦截器的问题。
4、下一步调试,数据如果还是明文就下一步。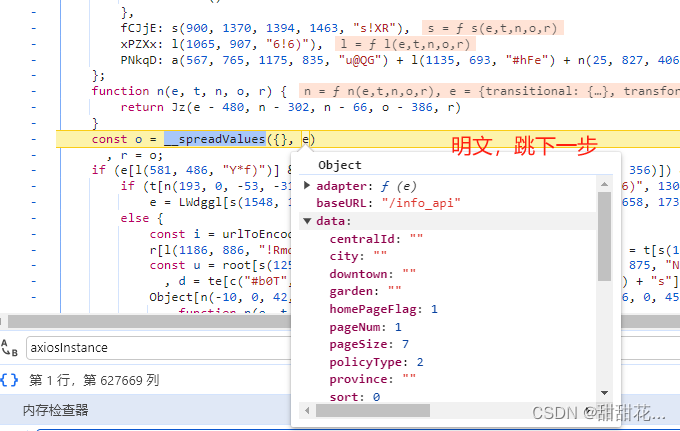
5、后面又把数据赋值给了r 观察r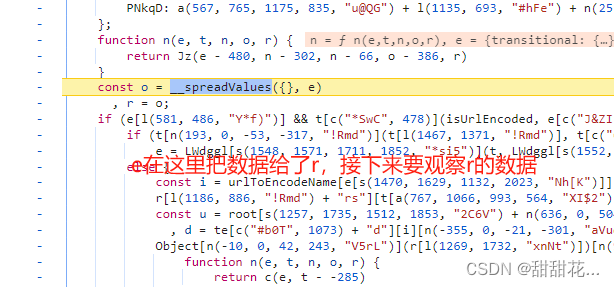
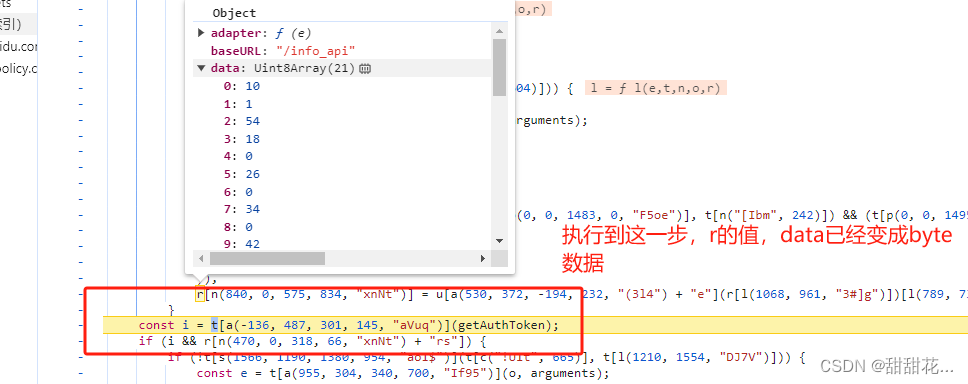
6、说明在上面部分进行了加密。

7、分析各部分。
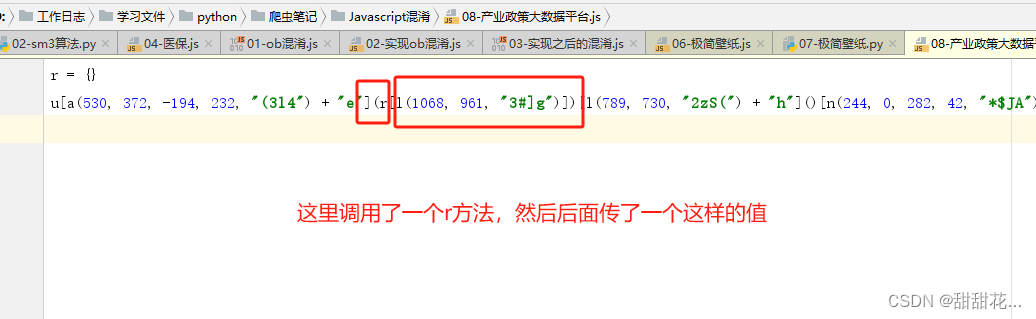
8、分析第一个部分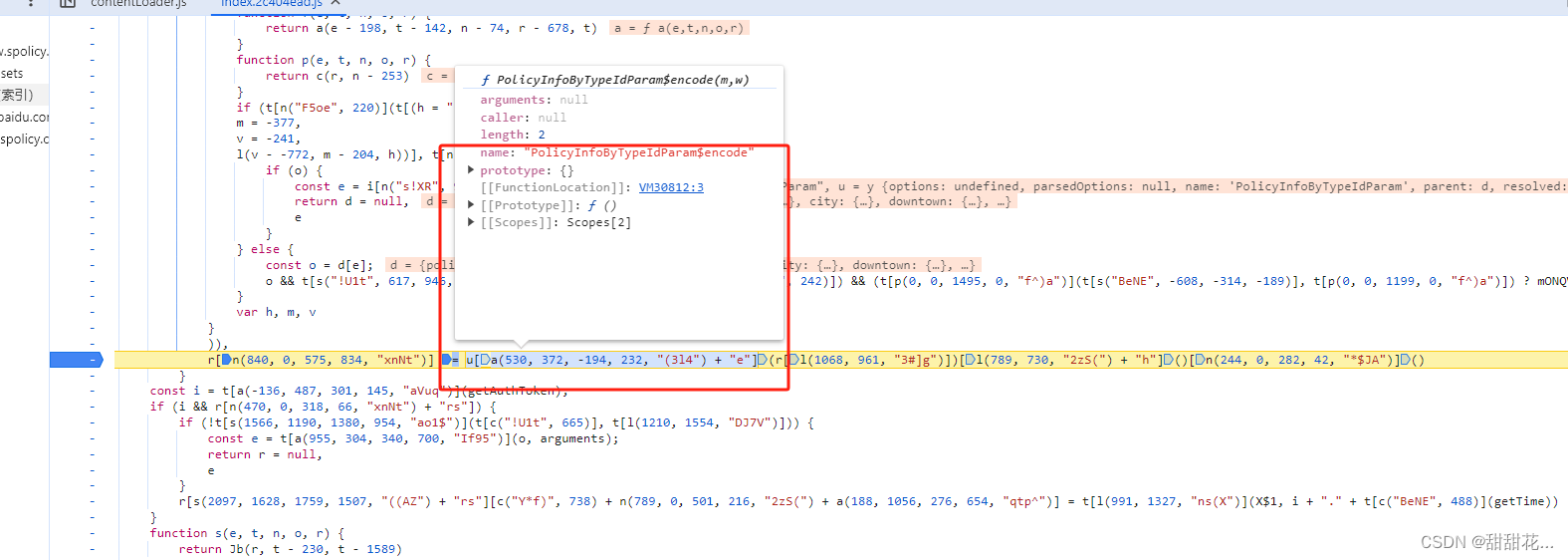
9、这其实是一个VM文件,VM文件后面会讲。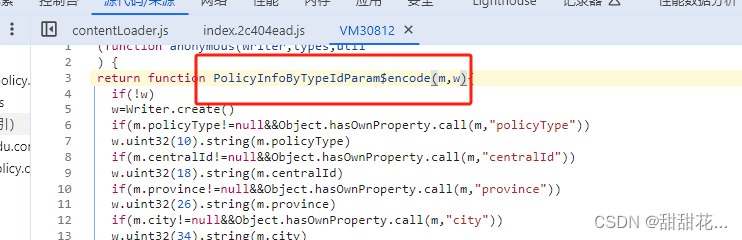

m传递的是一个数组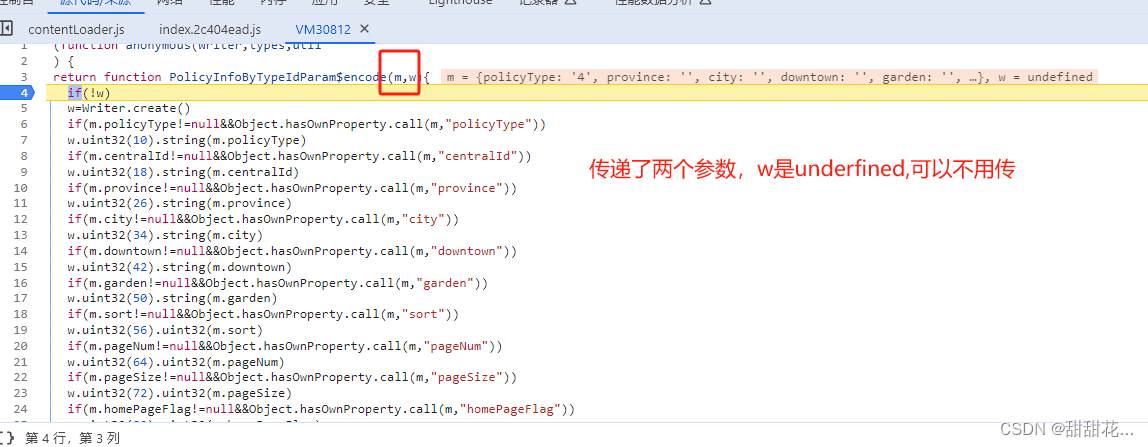
2、扣代码一
-
PolicyInfoByTypeIdParam$encode
- w为underfined ,if(!w)这部分可以删掉
- copy(m)
- 调用PolicyInfoByTypeIdParam$encode(m)
- 运行报错: Writer is not defined
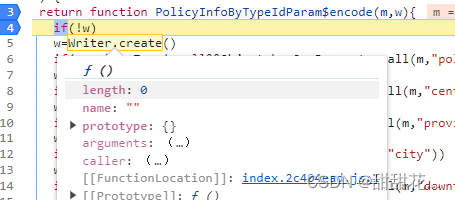
- 点击writer.create
- 赋值这个js文件里面全部的代码,找到 return new d
- 现在需要找到调用这个js代码的位置。
- 看【return new d】这个方法是包含在哪里的。
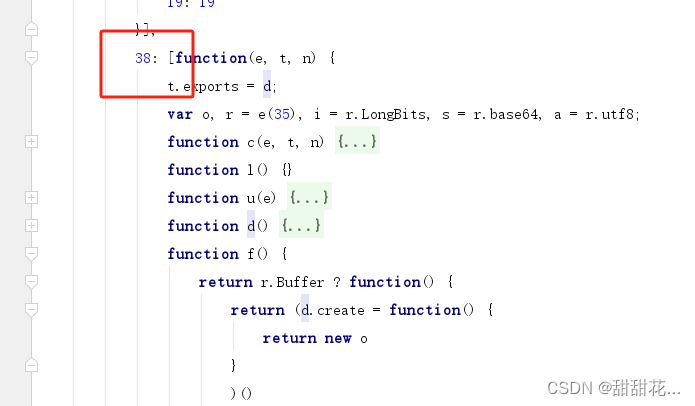
- 再往上走,发现包含在一个自执行方法中。把这个自执行方法放到自己需要分析的代码中。扣方法的时候不单单只扣方法,还可以扣整个js代码。

- 我们需要的代码在38方法里面,说明这里是一个加载器。是一个webpack打包的方式。
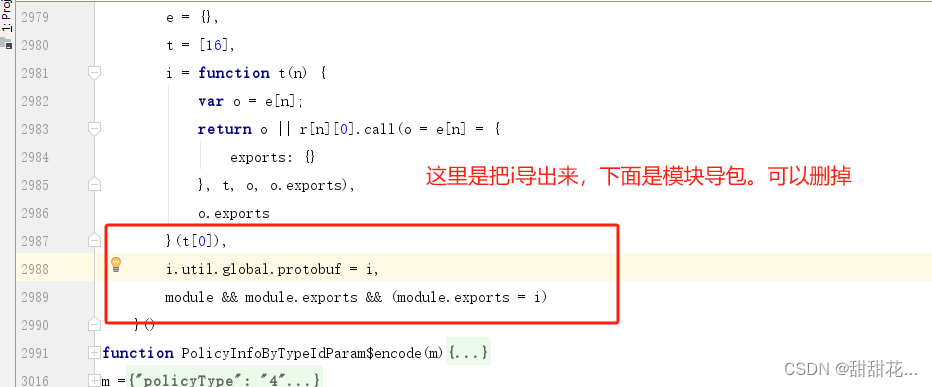
- 通过下面的一些参数可以判断i是一个webpack的加载器。

- 调用- var aaa; 把i赋值给aaa 输出aaa, 不用调用i,因为i是自执行的方法。 之前调用加载器的时候一般是aaa('1111'),现在不需要写东西。
- 运行报错:commonjsGlobal is not defined ,在网页js代码里面找commonjsGlobal。找到该参数打断点,分析该参数是什么。有问题是我可能不会触发这个断点。
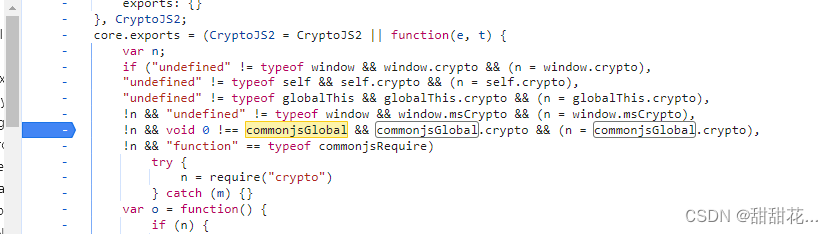
- 为什么不会触发这个断点。(因为这个方法已经被初始化过了,刷新才会执行当前方法。
- 在随便断住的时候,在控制台输出commonjsGlobal。当前数据就是window对象的赋值。补window即可,加window = global;
commonjsGlobal = window;
即可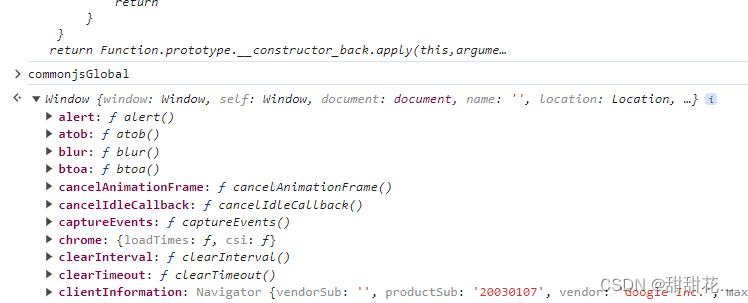
- 输出报错:aaa is not a function 改aaa() 为aaa,aaa不要调用。输出了数据,说明aaa已经获取到了i的值。
- 输出报错:Writer is not defined,我其实是现在有这个方法的 需要通过aaa调用
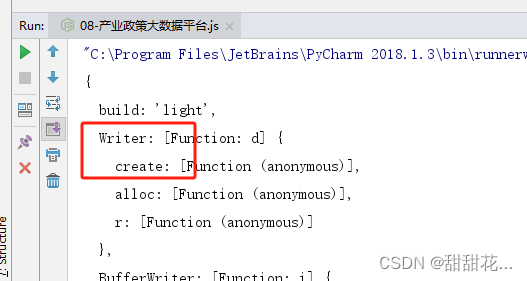
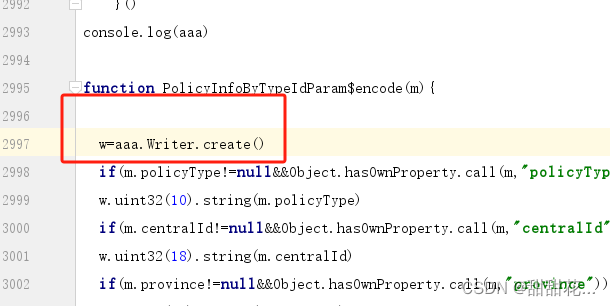
- 我们扣代码需要扣的多一些,看是不是有自执行方法和加载器

3、扣代码二、三
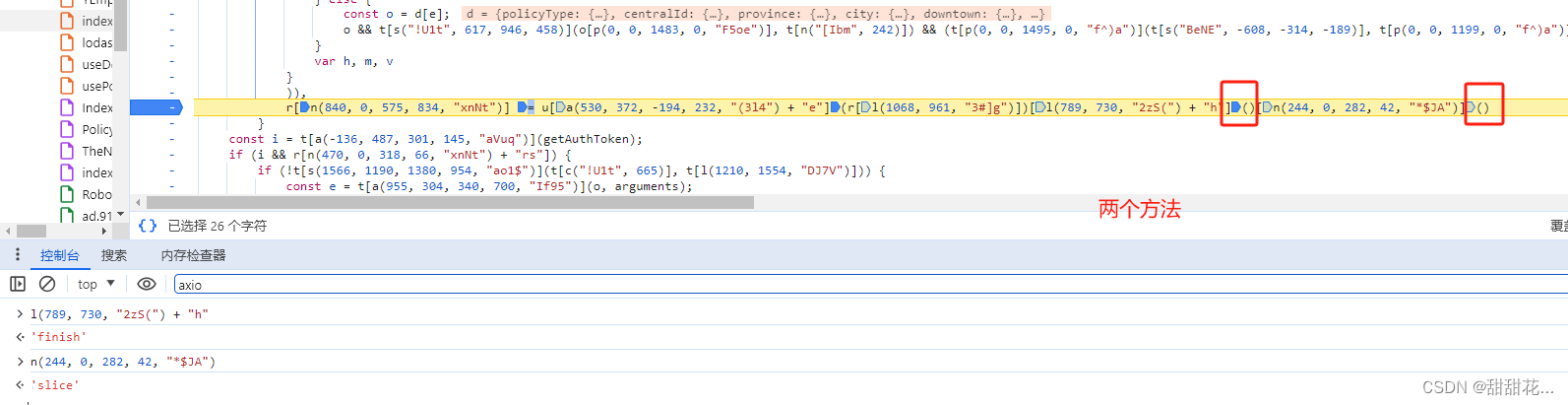
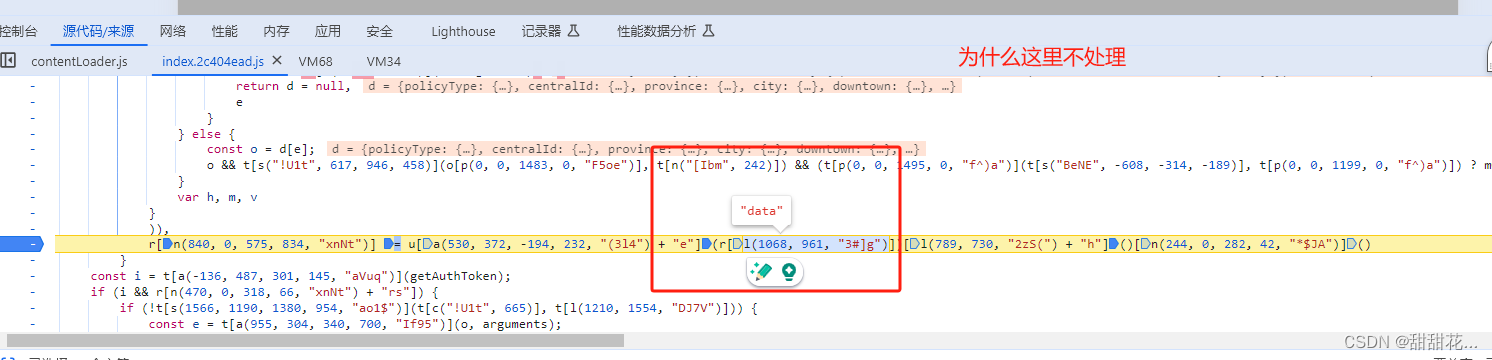
4、怎么调用加载器数据
导出到aaa
需要定义var aaa;
aaa=i;
输出aaa
5、python怎么调用。
5.1、爬虫工具库网址:
5.2、源代码
import requests
import execjs
class dsj():
def __init__(self):
self.url = 'http://www.spolicy.com/info_api/policyType/showPolicyType'
self.headers = {'User-Agent':'Mozilla/5.0 (X11; Linux aarch64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.188 Safari/537.36 CrKey/1.54.250320',
'Content-Type':'application/octet-stream'
}
self.data = {
"policyType": "4",
"province": "",
"city": "",
"downtown": "",
"garden": "",
"centralId": "",
"sort": 0,
"homePageFlag": 1,
"pageNum": 1,
"pageSize": 7
}
self.js = execjs.compile(open('08-产业政策大数据平台.js',encoding='utf-8').read())
def request_data(self):
data = self.js.call('PolicyInfoByTypeIdParam$encode',self.data)
print(data)
res = requests.post(self.url,headers =self.headers,data=bytes(data['data']))
print(res.text)
if __name__ == '__main__':
ds = dsj()
ds.request_data()
















 1400
1400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









