







最后
不知道你们用的什么环境,我一般都是用的Python3.6环境和pycharm解释器,没有软件,或者没有资料,没人解答问题,都可以免费领取(包括今天的代码),过几天我还会做个视频教程出来,有需要也可以领取~
给大家准备的学习资料包括但不限于:
Python 环境、pycharm编辑器/永久激活/翻译插件
python 零基础视频教程
Python 界面开发实战教程
Python 爬虫实战教程
Python 数据分析实战教程
python 游戏开发实战教程
Python 电子书100本
Python 学习路线规划

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
以下是一个示例代码,演示如何使用决策树算法对大学生数据进行数据分析和数据挖掘:
# 导入必要的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
# 创建示例数据集
data = {
'student\_id': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'math\_score': [85, 92, 78, 88, 94, 87, 80, 75, 92, 89],
'english\_score': [88, 78, 85, 80, 92, 90, 83, 79, 87, 82],
'pass\_exam': [1, 0, 1, 0, 1, 1, 0, 0, 1, 1] # 1表示通过考试,0表示未通过考试
}
df = pd.DataFrame(data)
# 定义特征和目标变量
X = df[['math\_score', 'english\_score']]
y = df['pass\_exam']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建决策树模型
dt_classifier = DecisionTreeClassifier(random_state=42)
dt_classifier.fit(X_train, y_train)
# 预测测试集
y_pred = dt_classifier.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print(f'Confusion Matrix:\n{conf\_matrix}')
# 可视化决策树
plt.figure(figsize=(12, 8))
plot_tree(dt_classifier, feature_names=X.columns, class_names=['Fail', 'Pass'], filled=True)
plt.show()
在这个示例中,我们使用了决策树算法对大学生数据进行分析,预测学生是否通过考试。你可以根据实际情况和数据集的特点,调整特征、目标变量以及模型参数,以实现更加个性化和深入的数据分析和挖掘工作。决策树模型可以帮助你理解数据中的模式和关系,为进一步的数据解释和决策提供更多参考。
- 调整特征、目标变量以及模型参数示例代码
当涉及到个性化和深入的数据分析和挖掘工作时,你可以根据具体情况调整特征、目标变量以及模型参数。以下是一个更加灵活和通用的示例代码,演示如何根据实际情况调整特征、目标变量和模型参数,以实现个性化的数据分析和挖掘工作:
# 导入必要的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
# 读取数据集(这里以一个虚拟数据集为例)
data = {
'student\_id': [1, 2, 3, 4, 5],
'feature1': [10, 20, 15, 25, 30],
'feature2': [3, 7, 5, 9, 11],
'target\_variable': ['A', 'B', 'A', 'B', 'A'] # 例如,A和B可以是不同的类别
}
df = pd.DataFrame(data)
# 选择特征和目标变量
X = df[['feature1', 'feature2']]
y = df['target\_variable']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建决策树模型并调整参数
dt_classifier = DecisionTreeClassifier(criterion='entropy', max_depth=3, random_state=42)
dt_classifier.fit(X_train, y_train)
# 预测测试集
y_pred = dt_classifier.predict(X_test)
# 模型评估
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print(f'Confusion Matrix:\n{conf\_matrix}')
# 可视化决策树
plt.figure(figsize=(12, 8))
plot_tree(dt_classifier, feature_names=X.columns, class_names=dt_classifier.classes_, filled=True)
plt.show()
这个示例代码展示了如何根据实际情况调整特征、目标变量以及模型参数,以实现更加个性化和深入的数据分析和挖掘工作。你可以根据自己的数据集和需求,灵活选择特征、目标变量以及调整决策树模型的参数,以更好地理解数据中的模式和关系,为进一步的数据解释和决策提供更多参考。
五、关联规则挖掘示例代码
- 关联规则挖掘示例代码
以下是一个示例代码,演示如何使用关联规则挖掘算法(Apriori算法)对大学生数据进行关联规则挖掘:
# 导入必要的库
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
# 创建示例数据集
data = {
'student\_id': [1, 2, 3, 4, 5],
'math\_score': [85, 92, 78, 88, 94],
'english\_score': [88, 78, 85, 80, 92],
'pass\_exam': [1, 0, 1, 0, 1] # 1表示通过考试,0表示未通过考试
}
df = pd.DataFrame(data)
# 对数据进行独热编码
df_onehot = pd.get_dummies(df, columns=['math\_score', 'english\_score'])
# 使用Apriori算法进行频繁项集挖掘
frequent_itemsets = apriori(df_onehot, min_support=0.2, use_colnames=True)
# 根据频繁项集生成关联规则
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.7)
print("频繁项集:")
print(frequent_itemsets)
print("\n关联规则:")
print(rules)
在这个示例中,我们使用了Apriori算法对大学生数据进行关联规则挖掘。你可以根据实际数据集的特点和需求,调整参数如min_support和min_threshold,以获得符合实际情况的频繁项集和关联规则。关联规则挖掘可以帮助你发现数据中的潜在关联和规律,为进一步的数据分析和决策提供更多见解。
- 调整参数,并进行关联规则挖掘示例代码
当调整参数如min_support和min_threshold时,可以根据实际数据集的特点和需求,以获得符合实际情况的频繁项集和关联规则。以下是一个示例代码,演示如何根据实际情况调整参数,并进行关联规则挖掘:
# 导入必要的库
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
# 创建示例数据集
data = {
'student\_id': [1, 2, 3, 4, 5],
'subject\_A': [1, 0, 1, 1, 0],
'subject\_B': [1, 1, 0, 1, 0],
'subject\_C': [0, 1, 1, 0, 1]
}
df = pd.DataFrame(data)
# 使用Apriori算法进行频繁项集挖掘
frequent_itemsets = apriori(df.drop(columns=['student\_id']), min_support=0.3, use_colnames=True)
# 根据频繁项集生成关联规则
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.6)
print("频繁项集:")
print(frequent_itemsets)
print("\n关联规则:")
print(rules)
在这个示例中,我们根据实际数据集的特点和需求,调整了min_support参数为0.3,min_threshold参数为0.6,以获取符合实际情况的频繁项集和关联规则。你可以根据具体情况灵活调整这些参数,以发现数据中的潜在关联和规律,为进一步的数据分析和决策提供更多见解。
六、神经网络示例代码

- 神经网络示例代码
以下是一个示例代码,演示如何使用神经网络对大学生数据进行分析和预测,以预测学生是否通过考试:
# 导入必要的库
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score
# 创建示例数据集
data = {
'student\_id': [1, 2, 3, 4, 5],
'math\_score': [85, 92, 78, 88, 94],
'english\_score': [88, 78, 85, 80, 92],
'pass\_exam': [1, 0, 1, 0, 1] # 1表示通过考试,0表示未通过考试
}
df = pd.DataFrame(data)
# 准备特征和目标变量
X = df[['math\_score', 'english\_score']]
y = df['pass\_exam']
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 创建神经网络模型
model = MLPClassifier(hidden_layer_sizes=(50, 50), max_iter=1000, random_state=42)
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
在这个示例中,我们使用了多层感知器(MLP)神经网络模型对大学生数据进行分析和预测。你可以根据实际数据集的特点和需求,调整神经网络模型的参数如hidden_layer_sizes、max_iter等,以获得更好的预测效果。神经网络模型可以帮助你对数据进行深入分析和预测,为进一步的数据挖掘工作提供更多见解。

- 调整神经网络模型的参数示例代码
当调整神经网络模型的参数以获得更好的预测效果时,可以根据实际数据集的特点和需求,调整参数如hidden_layer_sizes、max_iter等。以下是一个示例代码,演示如何根据实际情况调整神经网络模型的参数:
# 导入必要的库
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score
# 创建示例数据集
data = {
'student\_id': [1, 2, 3, 4, 5],
'math\_score': [85, 92, 78, 88, 94],
'english\_score': [88, 78, 85, 80, 92],
'pass\_exam': [1, 0, 1, 0, 1] # 1表示通过考试,0表示未通过考试
}
df = pd.DataFrame(data)
# 准备特征和目标变量
X = df[['math\_score', 'english\_score']]
y = df['pass\_exam']
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 创建神经网络模型并调整参数
model = MLPClassifier(hidden_layer_sizes=(100, 50), max_iter=2000, random_state=42) # 调整hidden\_layer\_sizes和max\_iter参数
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
在这个示例中,我们根据实际数据集的特点和需求,调整了神经网络模型的参数,包括hidden_layer_sizes=(100, 50)和max_iter=2000。你可以根据具体情况灵活调整这些参数,以获得更好的预测效果。神经网络模型可以帮助你对数据进行深入分析和预测,为进一步的数据挖掘工作提供更多见解。
七、支持向量机示例代码
- 支持向量机示例代码
以下是一个示例代码,演示如何使用支持向量机(Support Vector Machine, SVM)对大学生数据进行分析和预测,以预测学生是否通过考试:
# 导入必要的库
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 创建示例数据集
data = {
'student\_id': [1, 2, 3, 4, 5],
'math\_score': [85, 92, 78, 88, 94],
'english\_score': [88, 78, 85, 80, 92],
'pass\_exam': [1, 0, 1, 0, 1] # 1表示通过考试,0表示未通过考试
}
df = pd.DataFrame(data)
# 准备特征和目标变量
X = df[['math\_score', 'english\_score']]
y = df['pass\_exam']
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 创建SVM模型
model = SVC(kernel='linear', C=1.0, random_state=42)
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
在这个示例中,我们使用了支持向量机(SVM)模型对大学生数据进行分析和预测。你可以根据实际数据集的特点和需求,调整SVM模型的参数如kernel、C等,以获得更好的预测效果。支持向量机是一种强大的分类算法,在处理小样本、高维度数据和非线性数据时表现优秀,可以帮助你进行数据分析和挖掘工作,发现数据中的模式和关系。
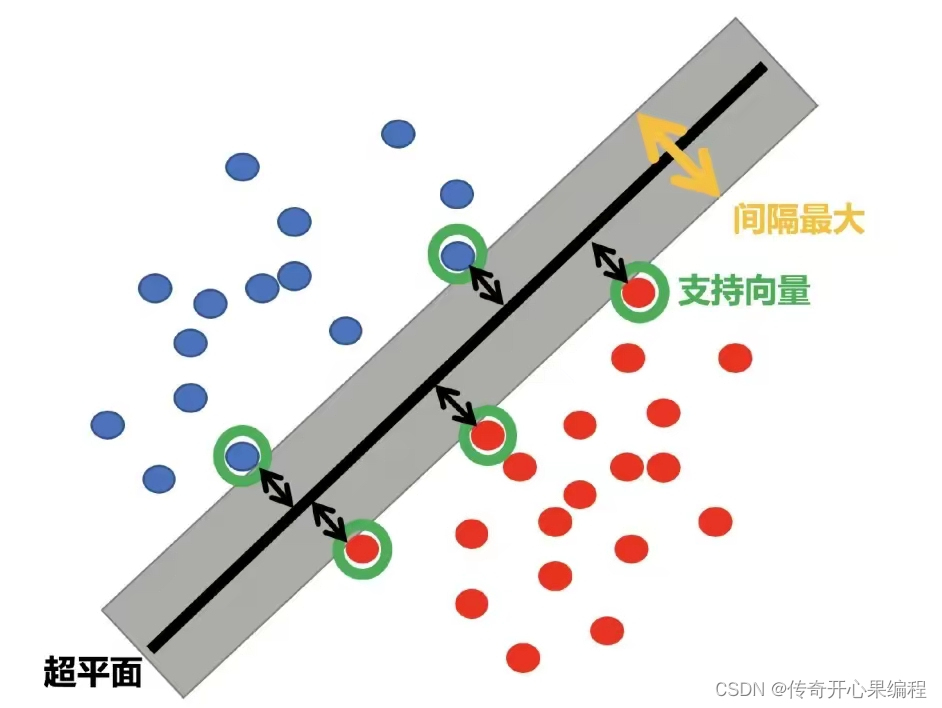
- 调整SVM模型的参数示例代码
当调整SVM模型的参数时,你可以根据实际数据集的特点和需求进行优化。以下是一个重写的示例代码,展示如何根据实际情况调整SVM模型的参数来获得更好的预测效果:
# 导入必要的库
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 创建示例数据集
data = {
'student\_id': [1, 2, 3, 4, 5],
'math\_score': [85, 92, 78, 88, 94],
'english\_score': [88, 78, 85, 80, 92],
'pass\_exam': [1, 0, 1, 0, 1] # 1表示通过考试,0表示未通过考试
}
df = pd.DataFrame(data)
# 准备特征和目标变量
X = df[['math\_score', 'english\_score']]
y = df['pass\_exam']
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 创建SVM模型
# 你可以根据实际情况调整以下参数来优化模型
# kernel: 核函数,可以选择'linear', 'poly', 'rbf', 'sigmoid'等
# C: 惩罚参数,控制间隔的硬度,值越大表示对误分类样本的惩罚越大
model = SVC(kernel='rbf', C=1.0, random_state=42)
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
在这个示例中,你可以根据实际情况调整kernel和C等参数来优化SVM模型,以获得更好的预测效果。你可以尝试不同的核函数和惩罚参数,根据数据集的特点进行调整,以找到最适合的模型参数组合,从而提高预测准确性。
八、聚类分析示例代码
- 聚类分析示例代码
以下是一个示例代码,演示如何对大学生数据进行聚类分析,以发现数据中的潜在模式和群集:
# 导入必要的库
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 创建示例数据集
data = {
'student\_id': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'math\_score': [85, 92, 78, 88, 94, 70, 75, 89, 80, 85],
'english\_score': [88, 78, 85, 80, 92, 70, 82, 79, 88, 90]
}
df = pd.DataFrame(data)
# 准备特征数据
X = df[['math\_score', 'english\_score']]
# 创建KMeans模型进行聚类分析
kmeans = KMeans(n_clusters=2, random_state=42) # 设置聚类簇数为2
# 训练KMeans模型
kmeans.fit(X)
# 获取每个样本的簇标签
clusters = kmeans.labels_
# 将簇标签添加到数据集中
df['cluster'] = clusters
# 可视化聚类结果
plt.figure(figsize=(8, 6))
plt.scatter(df['math\_score'], df['english\_score'], c=df['cluster'], cmap='viridis', s=50)
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=200, c='red', label='Centroids')
plt.xlabel('Math Score')
plt.ylabel('English Score')
plt.title('Clustering of Student Data')
plt.legend()
plt.show()
这段代码将完成KMeans聚类分析,并将每个学生数据点根据所属簇进行可视化展示。簇中心点用红色标记。通过这种方式,你可以观察数据中的模式和群集,从而更好地理解大学生数据集的结构和关系。

- 扩展示例代码
当然,我可以帮你扩展示例代码,让它更加完整和有趣。以下是一个扩展示例,包括数据预处理、选择最佳聚类数、以及展示不同聚类数下的聚类效果:
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import silhouette_score
# 数据预处理:标准化特征数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 选择最佳的聚类数
silhouette_scores = []
for n_clusters in range(2, 6):
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
cluster_labels = kmeans.fit_predict(X_scaled)
silhouette_avg = silhouette_score(X_scaled, cluster_labels)
silhouette_scores.append(silhouette_avg)
best_n_clusters = silhouette_scores.index(max(silhouette_scores)) + 2 # 获得最佳聚类数
# 重新训练KMeans模型
best_kmeans = KMeans(n_clusters=best_n_clusters, random_state=42)
best_kmeans.fit(X_scaled)
best_clusters = best_kmeans.labels_
df['best\_cluster'] = best_clusters
# 可视化不同聚类数下的聚类效果
plt.figure(figsize=(16, 6))
for i, n_clusters in enumerate([2, 3, 4]):
plt.subplot(1, 3, i+1)
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
clusters = kmeans.fit_predict(X_scaled)
plt.scatter(X['math\_score'], X['english\_score'], c=clusters, cmap='viridis', s=50)
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=200, c='red', label='Centroids')
plt.xlabel('Math Score')
plt.ylabel('English Score')
plt.title(f'Clustering with {n\_clusters} clusters')
plt.legend()
plt.tight_layout()
plt.show()
这段代码扩展了示例,添加了数据预处理步骤、选择最佳聚类数的过程,并展示了不同聚类数下的聚类效果。通过这个扩展示例,你可以更全面地了解如何进行数据预处理、选择最佳聚类数,并比较不同聚类数对聚类效果的影响。
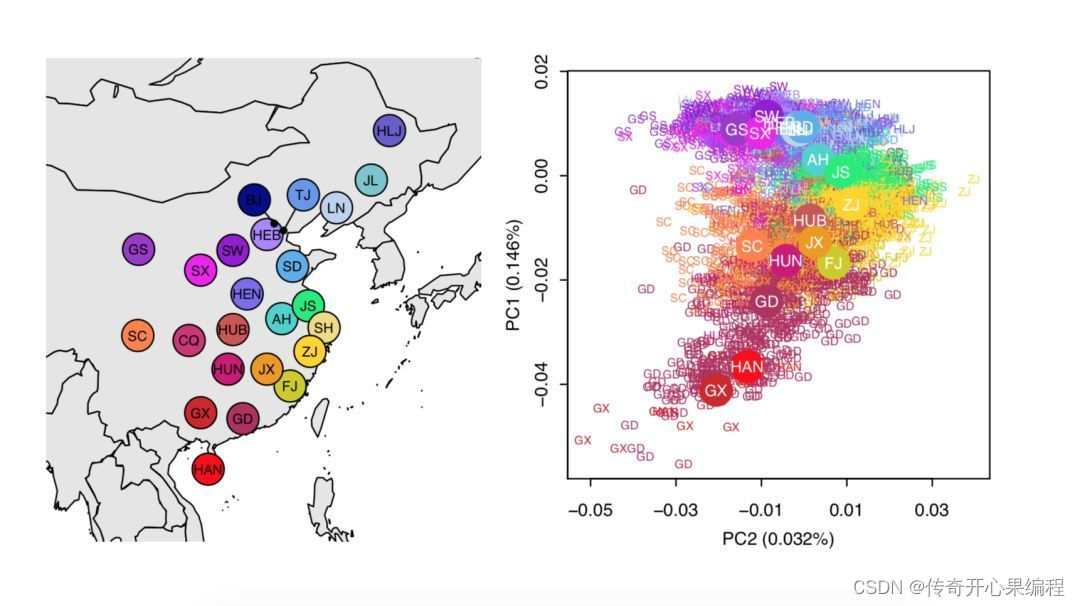
九、主成分分析示例代码
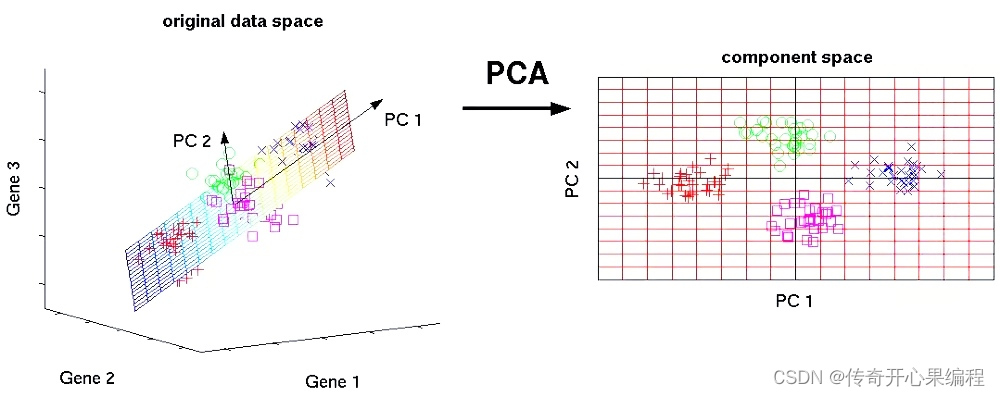
- 主成分分析示例代码
当涉及到大学生数据分析和数据挖掘时,主成分分析(PCA)是一个常用的技术,用于降维和发现数据中的模式。以下是一个示例代码,展示如何使用PCA对大学生数据进行降维处理:
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# 假设X是包含大学生数据的特征矩阵
# 实例化PCA模型,选择要保留的主成分数量
n_components = 2 # 选择保留的主成分数量
pca = PCA(n_components=n_components)
# 对数据进行PCA降维处理
X_pca = pca.fit_transform(X)
# 可视化PCA降维后的数据
plt.figure(figsize=(8, 6))
plt.scatter(X_pca[:, 0], X_pca[:, 1], s=50)
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA of Student Data')
plt.show()
# 查看各主成分的解释方差比例
explained_variance_ratio = pca.explained_variance_ratio_
print("Explained Variance Ratio:")
for i, ratio in enumerate(explained_variance_ratio):
print(f"Principal Component {i+1}: {ratio}")
在这个示例中,我们使用PCA对大学生数据进行降维处理,并将数据可视化在二维空间中。通过查看各主成分的解释方差比例,我们可以了解每个主成分对数据方差的贡献程度。这有助于我们理解数据的结构并选择合适的主成分数量来保留最重要的信息。
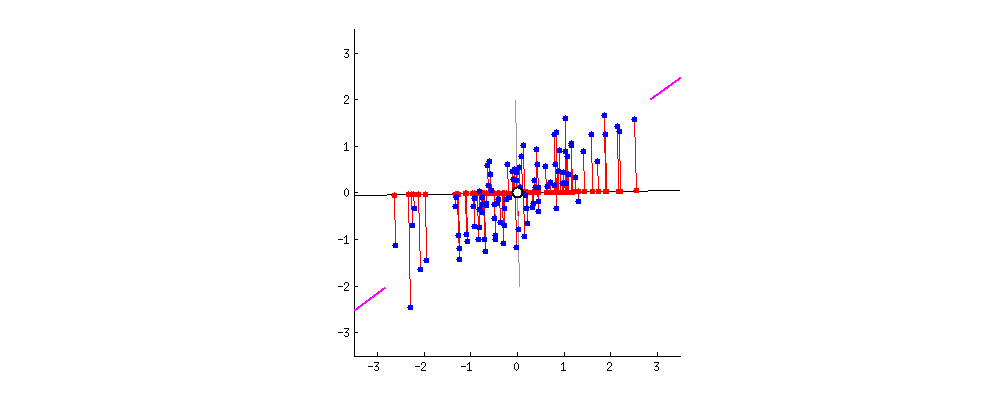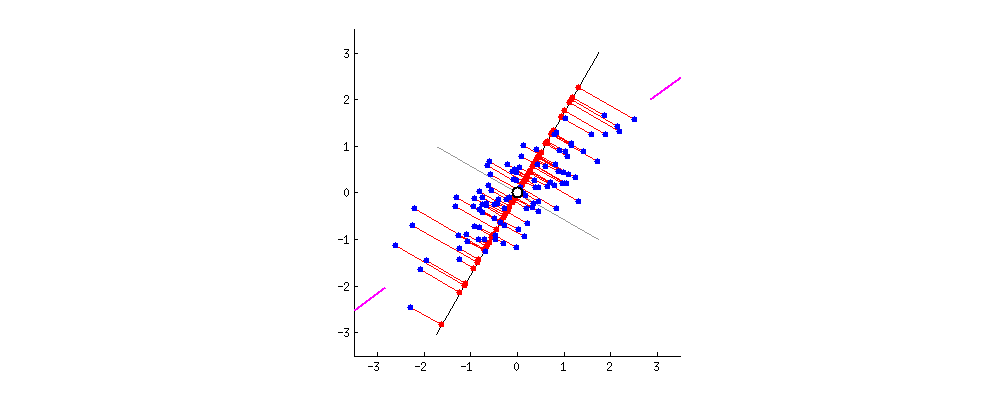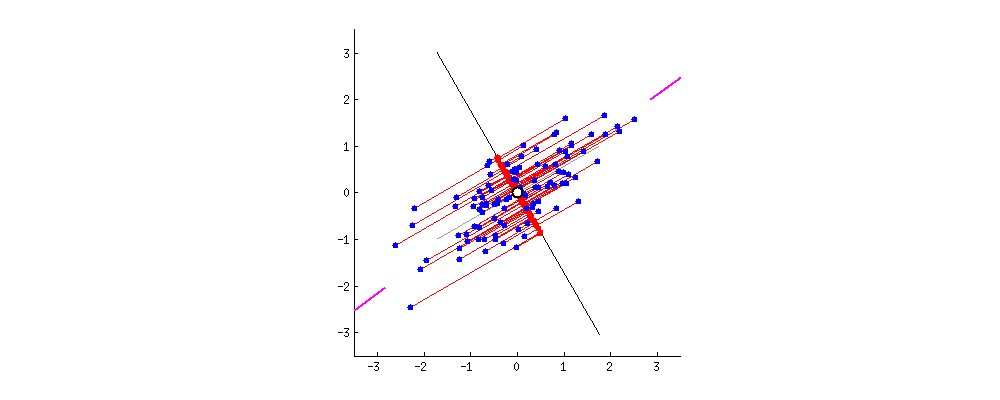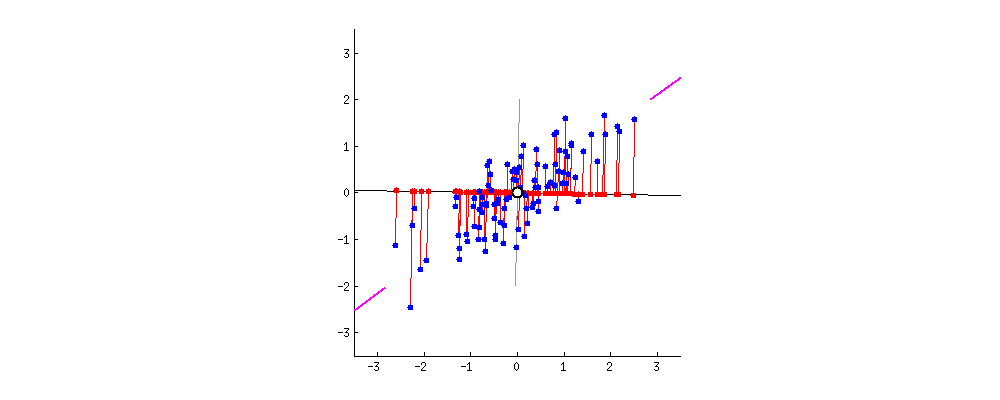
- 扩展示例代码
当涉及到主成分分析(PCA)的示例代码时,我们可以进一步扩展代码,包括更详细的解释方差比例、可视化主成分和原始特征之间的关系,以及如何利用PCA降维后的数据进行后续分析。以下是一个扩展示例代码:
from sklearn.datasets import make_classification
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import numpy as np
import matplotlib.pyplot as plt
# 生成模拟的大学生数据
X, _ = make_classification(n_samples=100, n_features=5, n_informative=3, n_redundant=1, random_state=42)
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 实例化PCA模型,选择要保留的主成分数量
pca = PCA(n_components=2)
# 对数据进行PCA降维处理
X_pca = pca.fit_transform(X_scaled)
# 查看各主成分的解释方差比例
explained_variance_ratio = pca.explained_variance_ratio_
print("Explained Variance Ratio:")
for i, ratio in enumerate(explained_variance_ratio):
print(f"Principal Component {i+1}: {ratio}")
# 可视化主成分和原始特征之间的关系
plt.figure(figsize=(12, 6))
# 绘制原始特征与第一个主成分的关系
plt.subplot(1, 2, 1)
for feature in range(X.shape[1]):
plt.scatter(X_scaled[:, feature], X_pca[:, 0], label=f'Feature {feature + 1}')
plt.xlabel('Original Features')
plt.ylabel('Principal Component 1')
plt.title('Relationship between Original Features and PC1')
plt.legend()
# 绘制原始特征与第二个主成分的关系
plt.subplot(1, 2, 2)
for feature in range(X.shape[1]):
plt.scatter(X_scaled[:, feature], X_pca[:, 1], label=f'Feature {feature + 1}')
plt.xlabel('Original Features')
plt.ylabel('Principal Component 2')
plt.title('Relationship between Original Features and PC2')
plt.legend()
plt.tight_layout()
plt.show()
这段代码扩展了示例,包括生成模拟的大学生数据、数据标准化、查看各主成分的解释方差比例、可视化主成分和原始特征之间的关系等步骤。通过这个扩展示例,你可以更深入地了解主成分分析的应用和效果。
十、时间序列分析示例代码

- 时间序列分析示例代码
在进行大学生数据分析和数据挖掘时,时间序列分析是一个常用的技术,用于揭示数据随时间变化的模式和趋势。以下是一个简单的时间序列分析示例代码,展示如何使用Python中的Pandas和Matplotlib库对大学生数据进行时间序列分析:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 创建模拟的大学生数据
np.random.seed(42)
dates = pd.date_range(start='2024-01-01', periods=100, freq='D')
scores = np.random.randint(60, 100, size=100)
# 创建时间序列DataFrame
data = pd.DataFrame({'Date': dates, 'Score': scores})
data.set_index('Date', inplace=True)
# 可视化时间序列数据
plt.figure(figsize=(12, 6))
plt.plot(data.index, data['Score'], marker='o')
plt.xlabel('Date')
plt.ylabel('Score')
plt.title('Student Scores Over Time')
plt.grid(True)
plt.show()
在这个示例中,我们生成了一个模拟的大学生数据集,其中包含了日期和分数。然后,我们使用Pandas库创建了一个时间序列DataFrame,并利用Matplotlib库将学生分数随时间变化的趋势可视化出来。
这只是一个简单的时间序列分析示例,你可以根据实际情况进一步扩展分析,比如季节性分析、趋势分析、周期性分析等。

- 扩展示例代码
当涉及到时间序列分析时,我们可以进一步扩展示例代码,包括趋势分析、季节性分析、移动平均线等。以下是一个扩展示例代码,展示了如何进行简单的移动平均线计算和季节性分析:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 创建模拟的大学生数据
np.random.seed(42)
dates = pd.date_range(start='2024-01-01', periods=100, freq='D')
scores = np.random.randint(60, 100, size=100)
# 创建时间序列DataFrame
data = pd.DataFrame({'Date': dates, 'Score': scores})
data.set_index('Date', inplace=True)
# 计算并绘制移动平均线
data['MA\_7'] = data['Score'].rolling(window=7).mean()
# 季节性分析
data['Month'] = data.index.month
seasonal_data = data.groupby('Month')['Score'].mean()
# 可视化时间序列数据、移动平均线和季节性趋势
plt.figure(figsize=(12, 8))
# 时间序列数据和移动平均线
plt.subplot(2, 1, 1)
plt.plot(data.index, data['Score'], label='Original Data', marker='o')
plt.plot(data.index, data['MA\_7'], label='7-Day Moving Average', color='red')
plt.xlabel('Date')
plt.ylabel('Score')
plt.title('Student Scores Over Time with 7-Day Moving Average')
plt.legend()
# 季节性分析
plt.subplot(2, 1, 2)
plt.bar(seasonal_data.index, seasonal_data.values, color='skyblue')
plt.xlabel('Month')
plt.ylabel('Average Score')
plt.title('Seasonal Analysis of Student Scores')
plt.xticks(np.arange(1, 13), ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'])
plt.tight_layout()
plt.show()
这段代码扩展了示例,包括计算和绘制移动平均线,以及进行季节性分析。通过这个扩展示例,你可以更全面地了解时间序列分析中的一些常见技术和方法。
十一、集成学习示例代码

- 集成学习随机森林算法示例代码
集成学习是一种强大的机器学习技术,可以通过结合多个模型的预测结果来提高整体预测性能。以下是一个示例代码,展示如何在大学生数据分析中应用集成学习技术(以随机森林为例):
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 读取大学生数据集,假设包含特征和目标变量
data = pd.read_csv('student\_data.csv')
# 假设数据集包含特征列 X 和目标列 y
X = data.drop('Target', axis=1)
y = data['Target']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化随机森林分类器
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
# 训练模型
rf_classifier.fit(X_train, y_train)
# 预测
y_pred = rf_classifier.predict(X_test)
# 评估模型性能
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
# 可以根据需要进一步优化参数、尝试其他集成学习算法等
在这个示例中,我们使用了随机森林分类器作为集成学习模型,对大学生数据集进行分类任务。你可以根据实际情况调整代码中的数据读取部分,确保数据集的特征和目标变量正确加载。此外,你还可以根据需要对模型进行参数调优、尝试其他集成学习算法(如梯度提升树、AdaBoost等)来进一步提高预测性能。

- 集成学习梯度提升树算法示例代码
以下是一个示例代码,展示了如何在大学生数据分析中使用梯度提升树(Gradient Boosting)作为集成学习算法:
import pandas as pd
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 读取大学生数据集,假设包含特征和目标变量
data = pd.read_csv('student\_data.csv')
# 假设数据集包含特征列 X 和目标列 y
X = data.drop('Target', axis=1)
y = data['Target']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化梯度提升树分类器
gb_classifier = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
# 训练模型
gb_classifier.fit(X_train, y_train)
# 预测
y_pred = gb_classifier.predict(X_test)
# 评估模型性能
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
# 可以根据需要调整学习率、树的数量等参数,进一步优化模型
在这个示例中,我们使用了梯度提升树作为集成学习算法,对大学生数据集进行分类任务。你可以根据实际情况调整代码中的数据读取部分,确保数据集的特征和目标变量正确加载。此外,你还可以根据需要调整学习率、树的数量等参数来优化模型的性能。
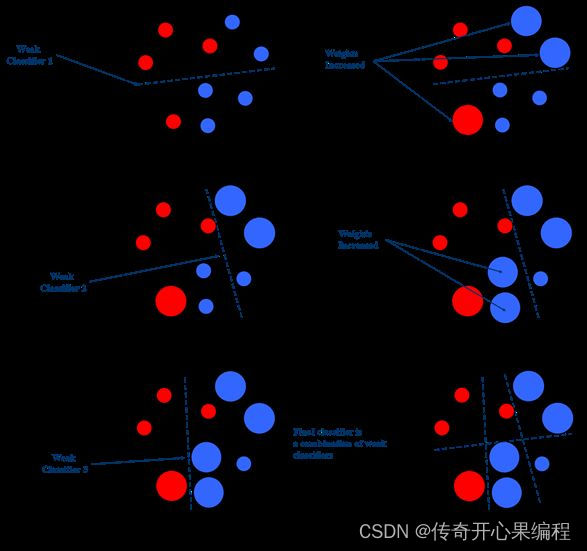
- 集成学习AdaBoost算法示例代码
以下是一个示例代码,展示了如何在大学生数据分析中使用AdaBoost算法作为集成学习算法:
import pandas as pd
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 读取大学生数据集,假设包含特征和目标变量
data = pd.read_csv('student\_data.csv')
# 假设数据集包含特征列 X 和目标列 y
X = data.drop('Target', axis=1)
y = data['Target']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化AdaBoost分类器
adaboost_classifier = AdaBoostClassifier(n_estimators=50, learning_rate=1.0, random_state=42)
# 训练模型
adaboost_classifier.fit(X_train, y_train)
# 预测
y_pred = adaboost_classifier.predict(X_test)
# 评估模型性能
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
### 最后
> **🍅 硬核资料**:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
> **🍅 技术互助**:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
> **🍅 面试题库**:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
> **🍅 知识体系**:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化学习资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









