






文章目录
前言
模块化设计,就是把 整体 拆分成 若干小零件,而且还能把小零件 组装 到一起的设计思想。
模块化的优点
更利于维护(比如电脑屏幕坏了,只换屏幕就可以了;比如想升级显卡,只换显卡就行了);
更好的复用性(比如有一块移动硬盘或U盘,大家都能用;我电脑上拆下的硬盘,你也能用等等)
提示:以下是本篇文章正文内容,下面案例可供参考
一、什么是模块化?
1.Node中的模块化如何实现?
a 文件,通过 module.exports = 导出的内容 导出内容
b 文件,通过 require(’./a’); 导入内容
2.Node中的模块分类
自定义模块:用户自己创建的每个JS文件,都是自定义模块
内置模块(核心模块):Node安装后,即可使用的模块,Node环境自带。
第三方模块:其他人或公司、组织开发的模块,发布到 npm 网站,我们需要下载使用的模块
二、自定义模块
1.加载自定义模块
a 文件,必须通过 module.exports 共享(导出、暴露)当前模块中的变量
b 文件,需要通过 require() 加载(导入)。(a 文件导出什么,b 文件就得到什么)
加载自定义模块时,必须要带路径 (相对路径、绝对路径都可以;但必须带路径,哪怕是 ./ 也不能省略)
加载自定义模块时,可以省略后缀
代码如下(示例):自定义模块
let str1 = str[0].toUpperCase();// 首字母大写
let str2 = str.slice(1).toLowerCase(); // 其他的小写;
return str1 + str2;
}
// 导出,让其他模块使用;
// module.exports.setString = setString;
module.exports = {
setString
}
代码如下(示例): 导入功能模块
// 导入功能模块
// 导入文件前缀不能省略,后缀可以省略
const obj = require('./05-自定义模块');
// 使用方法
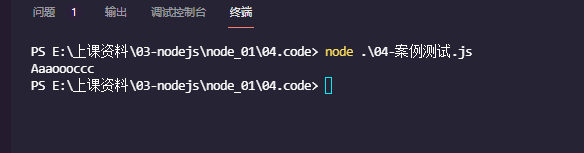
let str = obj.setString('aaaOOOccc');
console.log(str);
终端输出
三、内置模块
1.fs.readFile读取文件
// 导入 核心/内置模块
const fs = require('fs');
// 读取文件信息 错误对象放前面,被称为错误优先!
// 编码集不一定全写,读取的文件是: 图片/音频/视频... 多媒体文件; 一般用指定软件打开;
fs.readFile('./txt/1.txt', 'utf8', (err, data) => {
// 读取无错误,err=null; 读取有错误,err=错误对象
// 读取无错误,data是信息; 读取有错误,data=undefined
if (err != null) {
// 所有的错误对象,有两个属性,name和message
return console.log(err.message);
}
// 成功后,打印出读取的信息
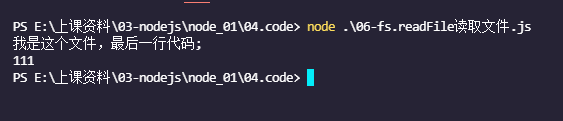
console.log(data);
})
// 读取文件是异步操作
console.log('我是这个文件,最后一行代码;');
2.fs.writeFile写入文件
// 导入模块
const fs = require('fs');
// 写入内容
fs.writeFile('./txt111/2.txt', '我是writeFile写入的内容', err => {
// 写入成功err为null, 写入失败,err为对象;
if (err) {
return console.log(err.message);
}
// 成功提示
console.log('恭喜您,写入文件内容成功!');
})
// 注意1: 文件里面有内容会覆盖原有内容;
// 注意2: 如果文件不存在; 就创建文件;
// 注意3: 如果文件夹不存在; 就报错;
// 写入文件是异步操作
console.log('我是这个文件,最后一行代码;');

3.path模块两个方法
// 导入模块
const path = require("path");
// 定义一个路径
let url = 'http://www.baidu.com/aaa/bbb/index.html';
// 1. path.extname(); 扩展名;
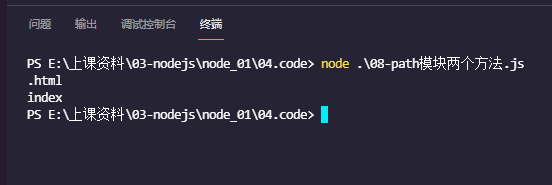
let str1 = path.extname(url);
console.log(str1);
// 2. path.basename(); 基础名;
let str2 = path.basename(url, str1);
console.log(str2);
4.path.join方法
// 导入模块
const fs = require('fs');
// 相对路劲不安全: 相对路径在node中相对的是执行文件的时候所在的目录;
// 相对路径不是以文件所在目录为基准;
let url = './txt/1.txt';
// 就使用绝对路径:
// url = 'E:/workspace/06-武汉校区/071期/10_node(6天)/node_01/04.code/txt/1.txt';
// console.log(__dirname);// 所在文件夹
// console.log(__filename);// 所在文件
// 利用path.join()和__dirname进行拼接;
const path = require('path');
url = path.join(__dirname, 'txt', '1.txt');
console.log(url);
// 读取文件
fs.readFile(url, 'utf8', (err, data) => {
if (err) {
return console.log(err.message);
}
console.log(data);
});

5.增删改查案例(含金量高)
// 1.我们有一个json文件,可以读取文件中所有的信息;
// 2.把信息转换为对象,然后进行增删改查(四个方法);
// 3.最后把满足条件的数据,转换为json写入文件中;
// 导入fs模块, 和path模块
const fs = require('fs');
const path = require('path');
// 拼接json文件的绝对路径
const url = path.join(__dirname, './data.json');
// 获取数据 - 直接获取,不需要添加;
function getData() {
// 这个方法是异步代码
fs.readFile(url, 'utf8', (err, data) => {
// 判断
if (err) {
return console.log(err.message);
}
// 输出结果 - 无法做到返回该函数外面
let obj = JSON.parse(data);
console.log(obj);
});
}
// // 测试获取数据
// getData();
// 添加数据 - 数据以参数的形式传递给方法;(传递什么,添加什么)
function addData(obj) {
// 1.获取信息
fs.readFile(url, 'utf8', (err, data) => {
// 判断
if (err) return console.log(err.message);
let arr = JSON.parse(data);
// 2.操作 - 把一个图书信息对象,添加到数组中
// 添加对象之前,生成id;(最后一项元素的id+1做新的id)
obj.id = arr[arr.length-1].id + 1;
arr.push(obj);
// 3.写入
fs.writeFile(url, JSON.stringify(arr), err => {
// 判断
if (err) return console.log(err.message);
// 提示成功
console.log('恭喜您,添加图书成功!');
})
})
}
// // 测试添加 - id的值,不是调用方法的时候定义的;
// addData({
// author: '刘慈欣',
// bookname: '三体3-黑暗森林',
// publisher: '武汉人民出版社'
// });
// 删除数据 - 根据id删除数据;
function delData(id) {
// 1.读取信息
fs.readFile(url, 'utf8', (err, data) => {
// 判断
if (err) return console.log(err.message);
// 转换为对象
const arr = JSON.parse(data);
// 删除数据: 1.遍历判断元素的id不等于参数id就添加到一个新数组;
// 删除数据: 2.filter()可以直接过滤产生一个新数组!
const newArr = arr.filter(ele => id !== ele.id)
// 添加到文件中
fs.writeFile(url, JSON.stringify(newArr), err => {
// 判断
if (err) return console.log(err.message);
// 成功提示
console.log('恭喜您,删除数据成功!');
});
})
}
// // 测试删除数据
// delData(6)
// 修改数据 - 删除原来的,添加最新的;
// - 要求传递的对象中必须存在 id
function updateData(obj) {
// 读取文件信息
fs.readFile(url, 'utf8', (err, data) => {
// 判断
if (err) return console.log(err.message);
// 转换成数组
const arr = JSON.parse(data);
// 根据id查询要删除的原来的对象索引值;
const index = arr.findIndex(ele => obj.id == ele.id);
// 根据索引值删除原有的,添加最新的;
arr.splice(index, 1, obj);
// 写入文件数据
fs.writeFile(url, JSON.stringify(arr), err => {
// 判断
if (err) return console.log(err.message);
// 提示
console.log('恭喜您,修改数据成功!');
})
})
}
// // 测试修改数据
// updateData({
// "id": 5,
// "author": "大刘",
// "bookname": "三体",
// "publisher": "湖北人民出版社"
// });
// 注意: 增删改不能同时操作;
[
{
"id": 1,
"author": "罗贯中",
"bookname": "三国演义",
"publisher": "武汉人民出版社"
},
{
"id": 2,
"author": "施耐庵",
"bookname": "水浒传",
"publisher": "武汉人民出版社"
},
{
"id": 3,
"author": "吴承恩",
"bookname": "西游记",
"publisher": "武汉人民出版社"
},
{
"id": 4,
"author": "曹雪芹",
"bookname": "红楼梦",
"publisher": "武汉人民出版社"
},
{
"id": 5,
"author": "刘慈欣",
"bookname": "三体1-地球往事",
"publisher": "武汉人民出版社"
},
{
"author": "刘慈欣",
"bookname": "三体2-死神永生",
"publisher": "武汉人民出版社",
"id": 6
},
{
"author": "刘慈欣",
"bookname": "三体3-黑暗森林",
"publisher": "武汉人民出版社",
"id": 7
}
]
四、第三方模块
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。















 1258
1258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











