






目录
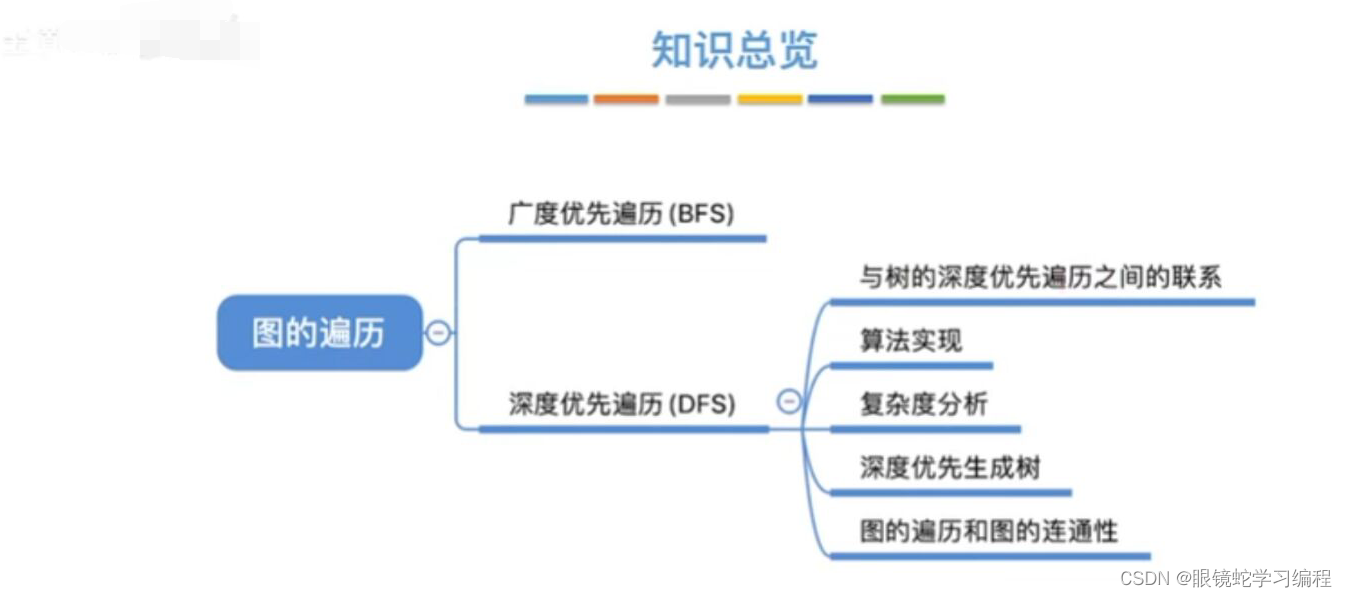
图的遍历
图的遍历是指从图中的某一顶点出发,按照某种搜索方法,沿着图中的边对图中的所有顶点访问一次,且仅访问一次。
注意到树是一种特殊的图,所以树的遍历实际上也可视为一种特殊的图的遍历。
图的遍历算法是求解图的连通性问题,拓扑排序和求关键路径等算法的基础。
图的遍历比树的遍历要复杂的多,因为图的任何一个顶点都可能和其余的顶点相连接。所以在访问某个顶点后,可能沿着某条路径搜索又回到该顶点上。为避免同一顶点被访问多次,在遍历图的过程中,必须记下每个已访问过的顶点。为此可以设一个辅助数组 visited[] 来标记顶点是否被访问过。图的遍历算法主要有两种,广度优先搜索和深度优先搜索。
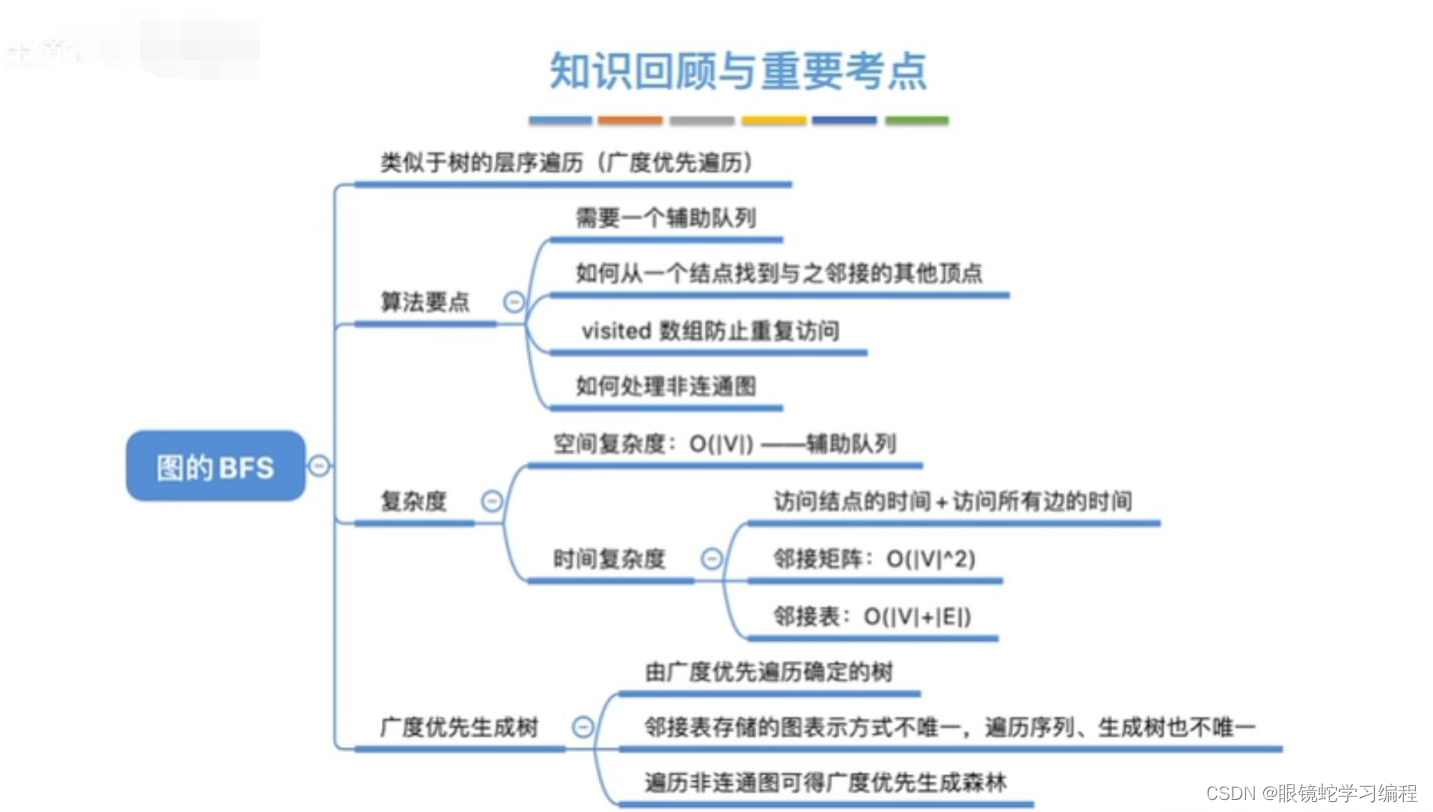
广度优先遍历(BFS)
图的广度优先遍历类比树的层次遍历
广度优先搜索(BFS)类似于二叉树的层次遍历算法,基本思想是,首先访问起始顶点v,接着由v出发,依次访问v的各个未访问过的邻接顶点W1、W2......Wi。然后依次访问W1、W2、....Wi的所有未访问过的邻接顶点,再从这些访问过的顶点出发,访问他们所有未被访问过的邻接顶点,直至图中的所有顶点都被访问过为止。若此时图中尚有顶点未被访问。则另选图中一个未曾被访问过的顶点作为始点,重复上述过程直至图中的所有顶点都被访问到为止。
换句话说,广度优先搜索遍历途中的过程是以v为起始点,由近至远依次访问和v有路径相通,且路径长度为1、2.....的顶点。
广度优先搜索是一种分层的查找过程,每向前走一步,可能访问一批顶点,不像深度优先搜索那样有往回退的情况,因此广度优先搜索不是一个递归的算法。为了实现逐层的访问算法,必须借助一个辅助队列,以记忆正在访问的顶点的下一层顶点。

广度优先遍历的代码实现

辅助数组 visited[] 标志顶点是否被访问过,其初始状态为false。在图的遍历过程中,一旦某个顶点Vi被访问,就立即置visited[i]为true,防止它被多次访问。
广度优先遍历序列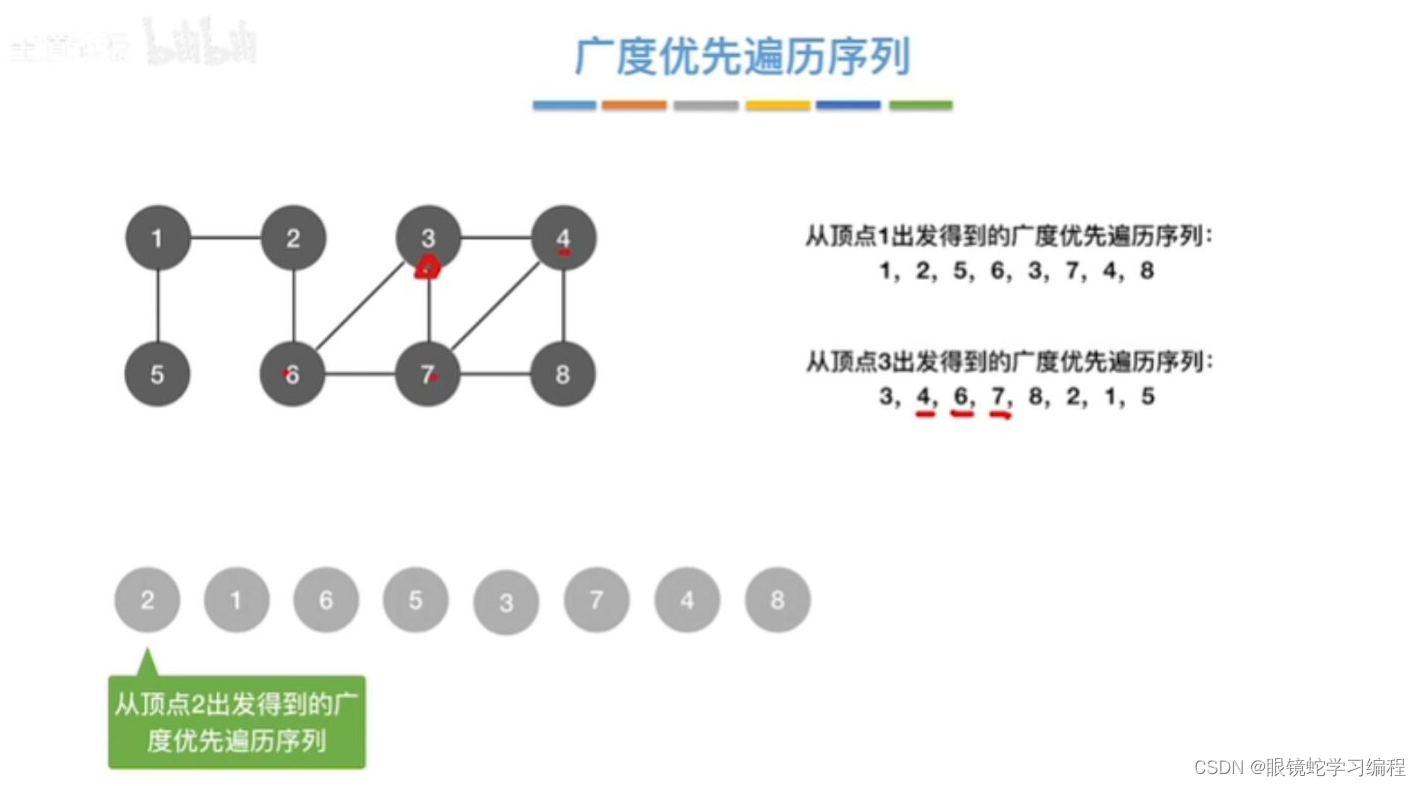
遍历序列的可变性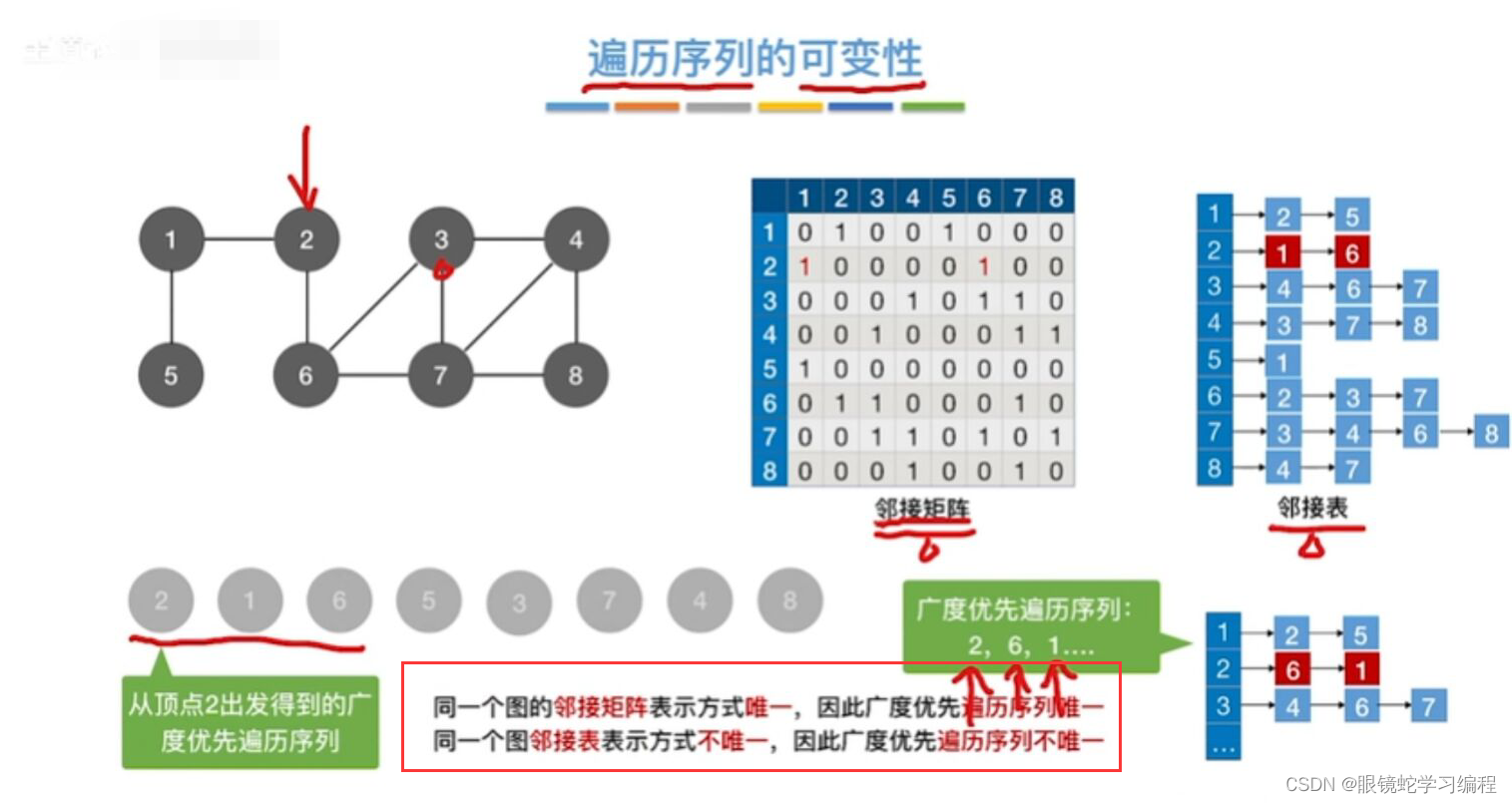
BFS算法完整版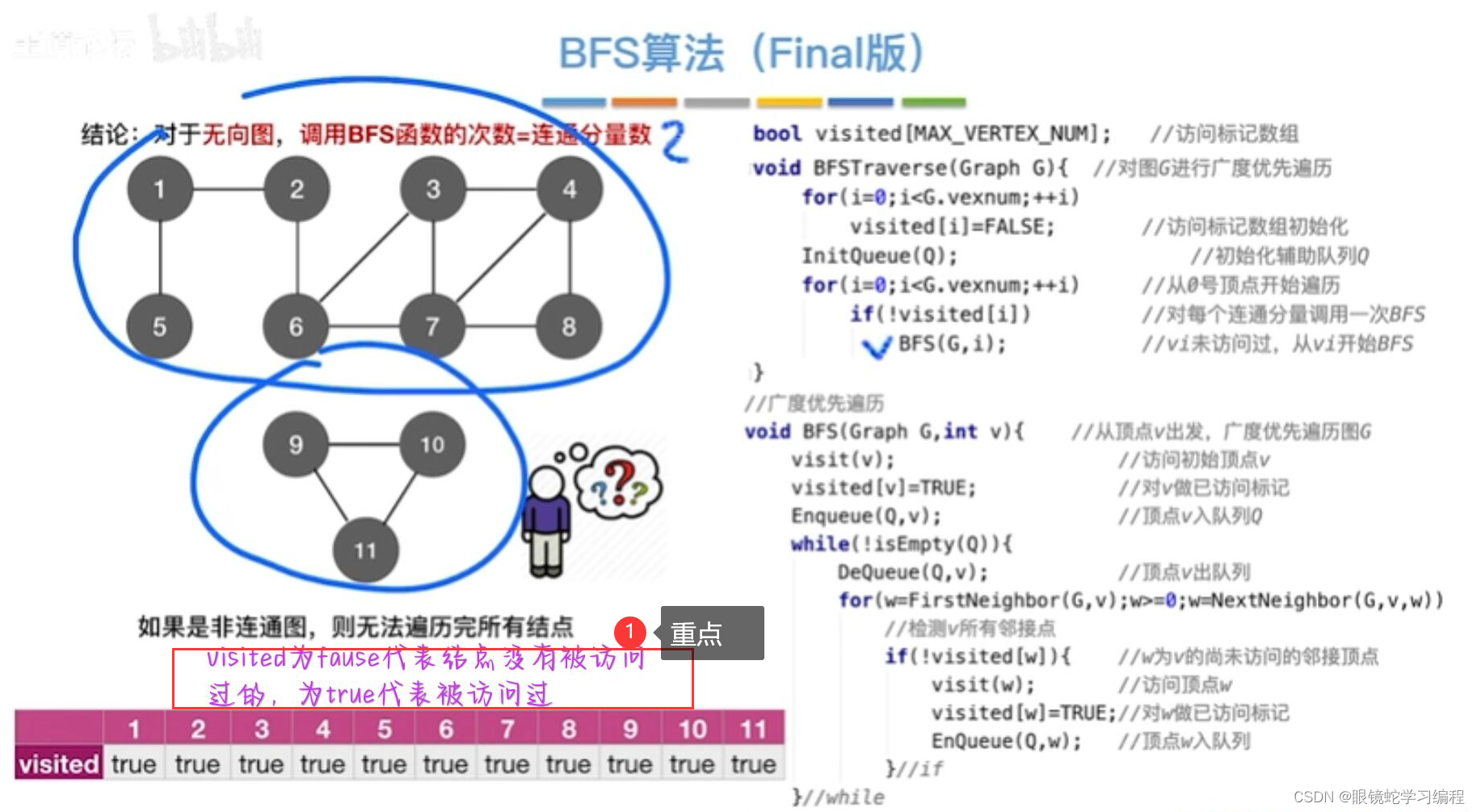
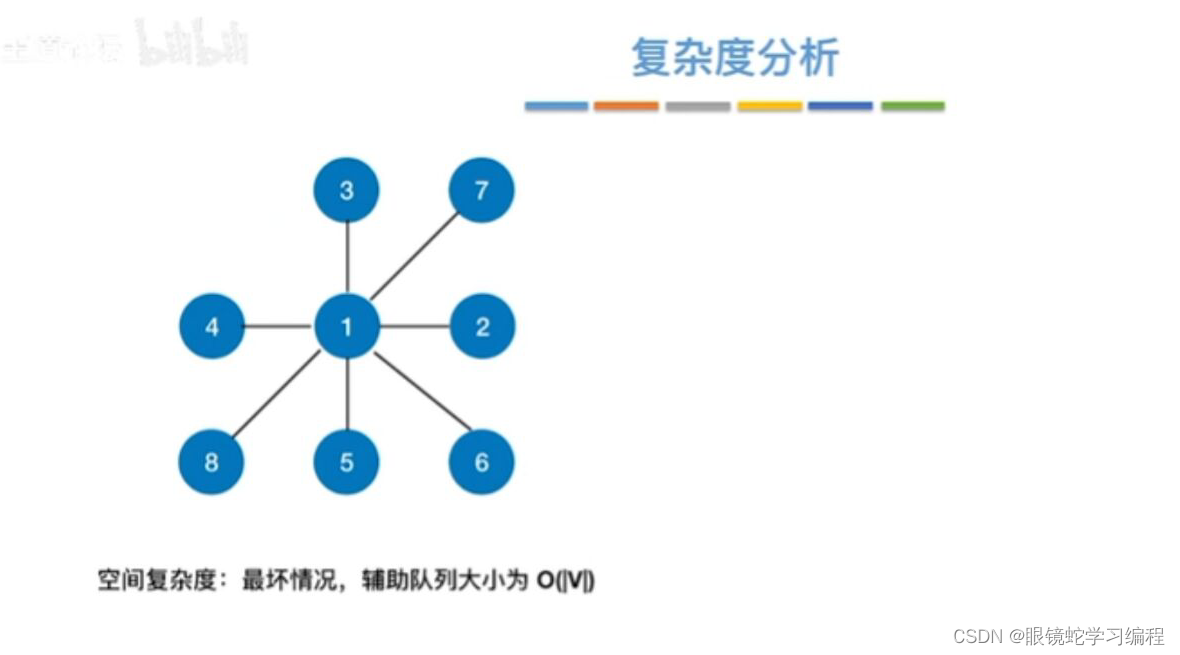
广度优先遍历复杂度分析

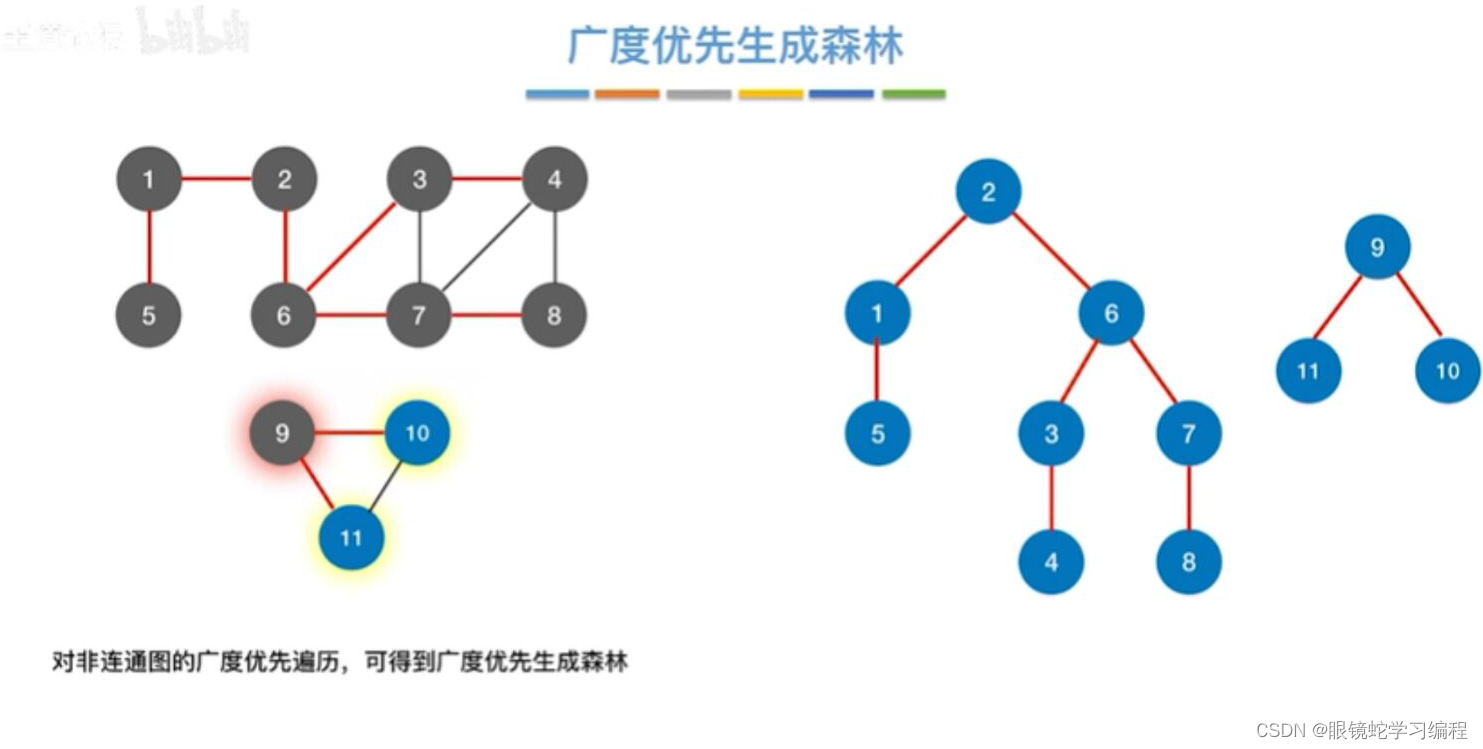
广度优先生成树
在广度遍历的过程中,我们可以得到一颗遍历树,称为广度优先生成树。需要注意的是,同一个图的邻接矩阵存储表示是唯一的。故其广度优先生成树也是唯一的。但是由于邻接表存储表示不唯一,故其广度优先生成树也是不唯一的。

广度优先生成森林
回顾广度优先遍历
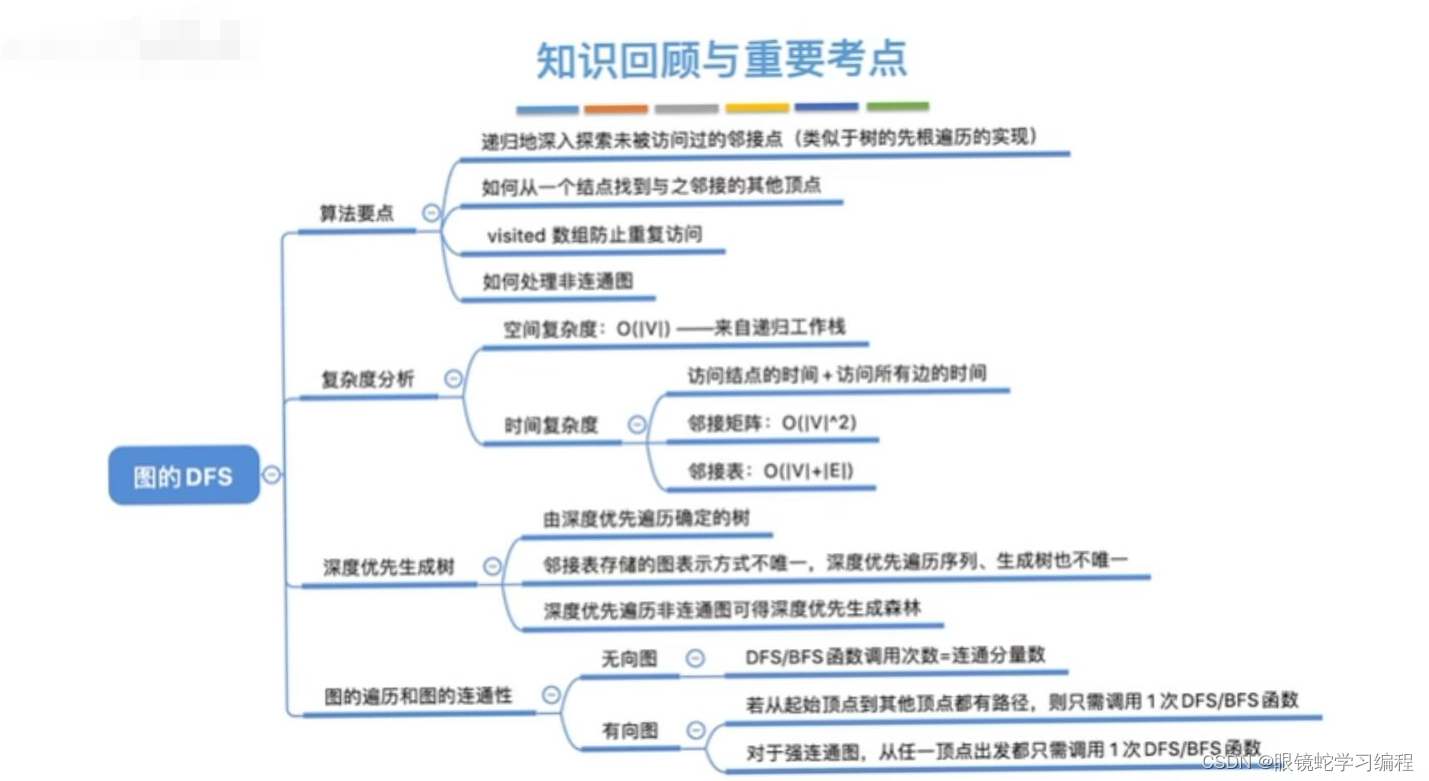
深度优先遍历(DFS)
图的深度优先遍历类似于树的先根遍历
与广度优先搜索不同,深度优先搜索(DFS)类似于树的先序遍历,如其名称中所暗含的意思一样。这种搜索算法所遵循的搜索策略是尽可能“深”地搜索一个图,它的基本思想如下,首先访问图中的某一起始顶点v,然后由v出发,访问与v邻接并且未被访问的任意一个顶点W1。在访问与W1邻接且未被访问的任意一个顶点W2.....重复上述过程,当不能再继续往下访问时,依次退回到最近被访问的顶点,如果他还有邻接顶点未被访问过。则从该顶点开始继续上述搜索过程,直至图中的所有顶点均被访问过为止。
回顾树的先根遍历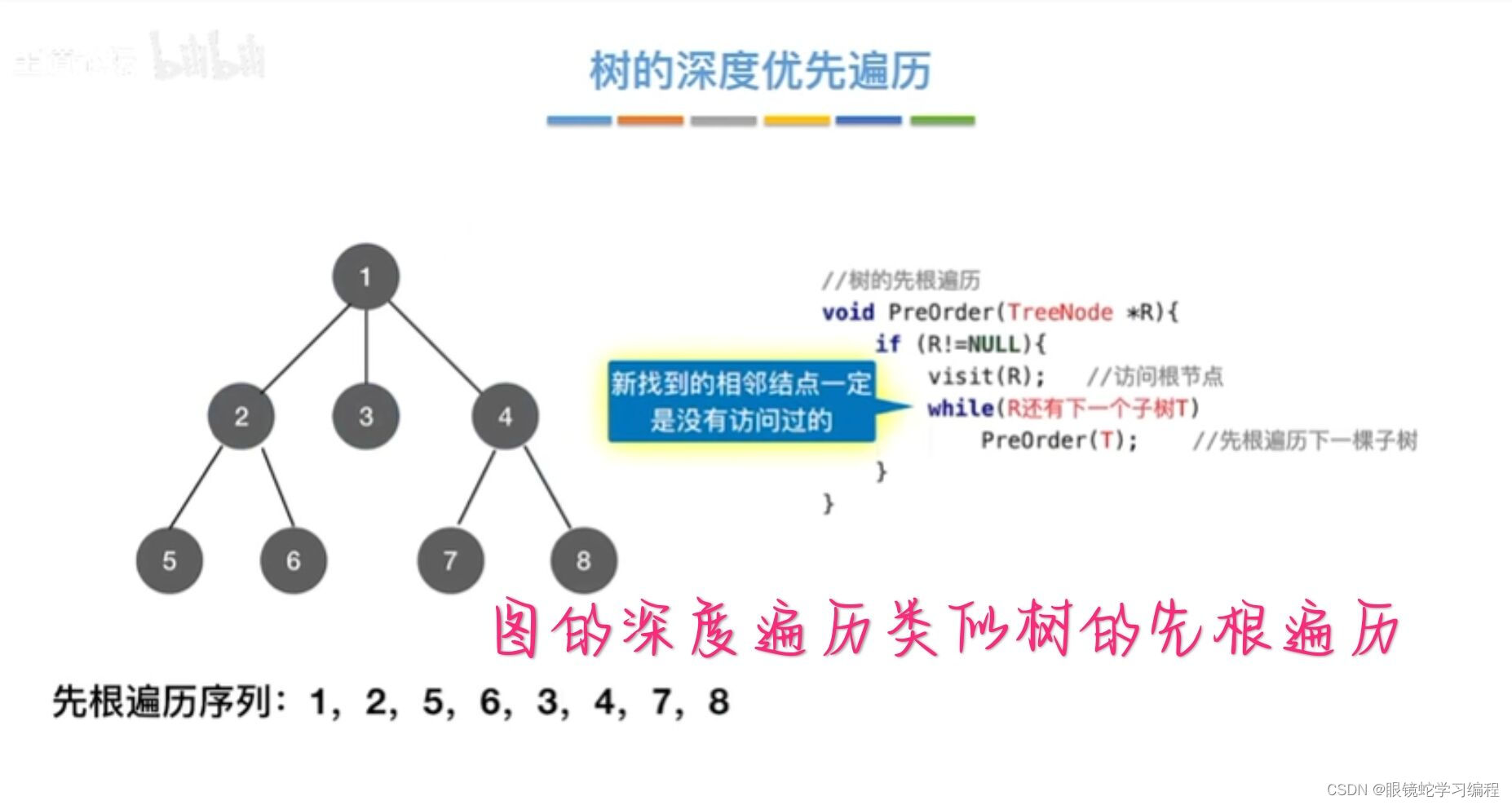
图的深度优先遍历代码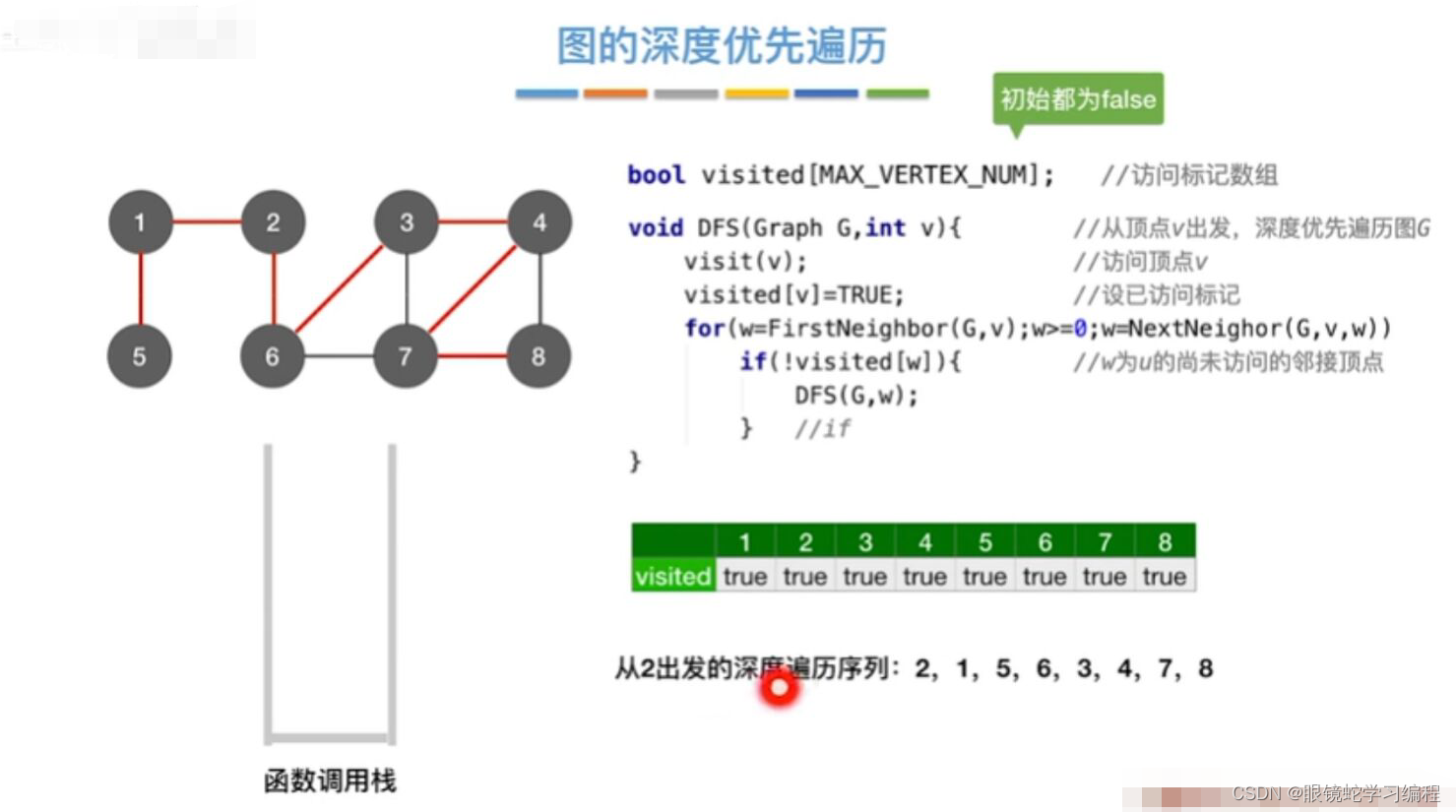
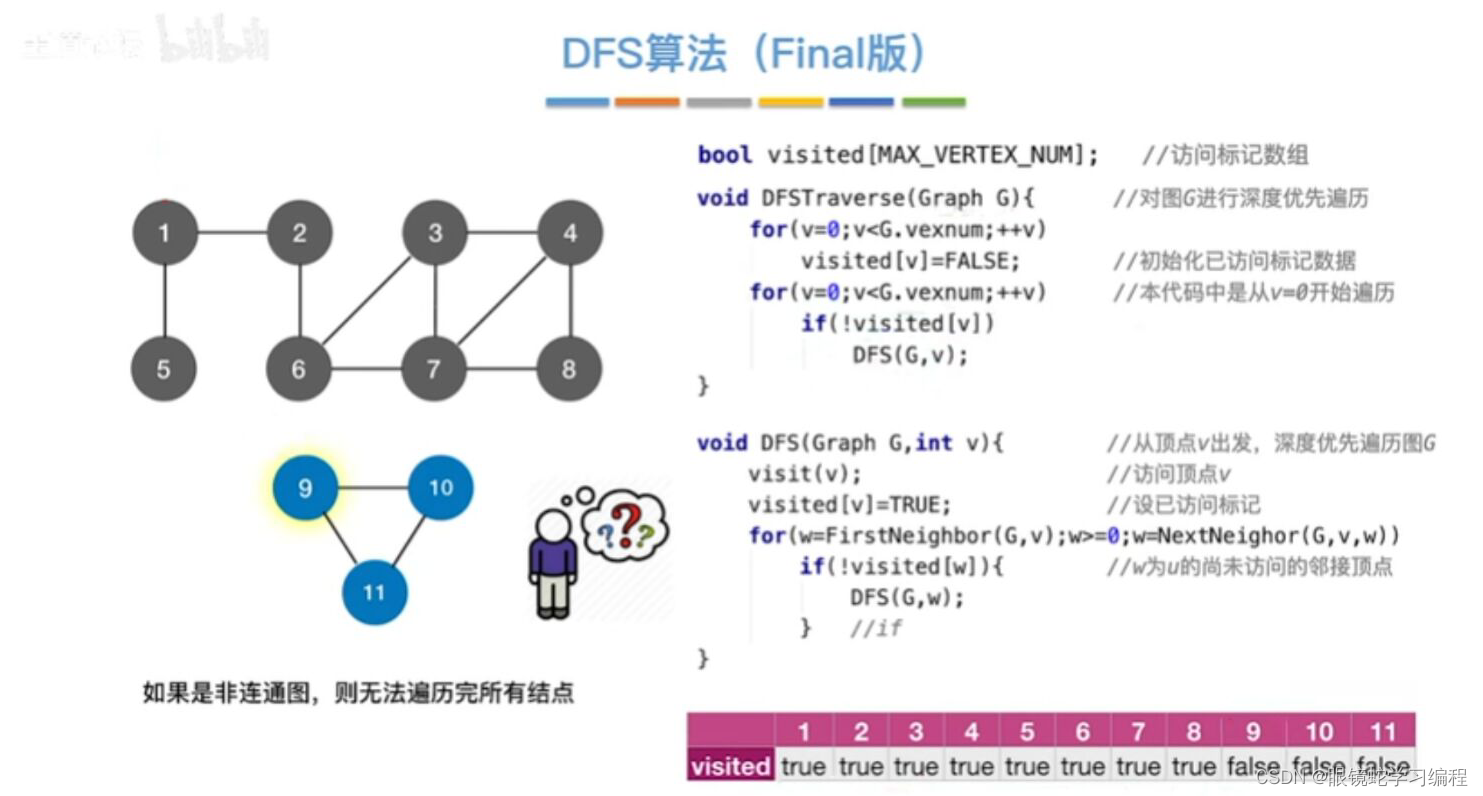
深度优先遍历(DFS)算法完整版
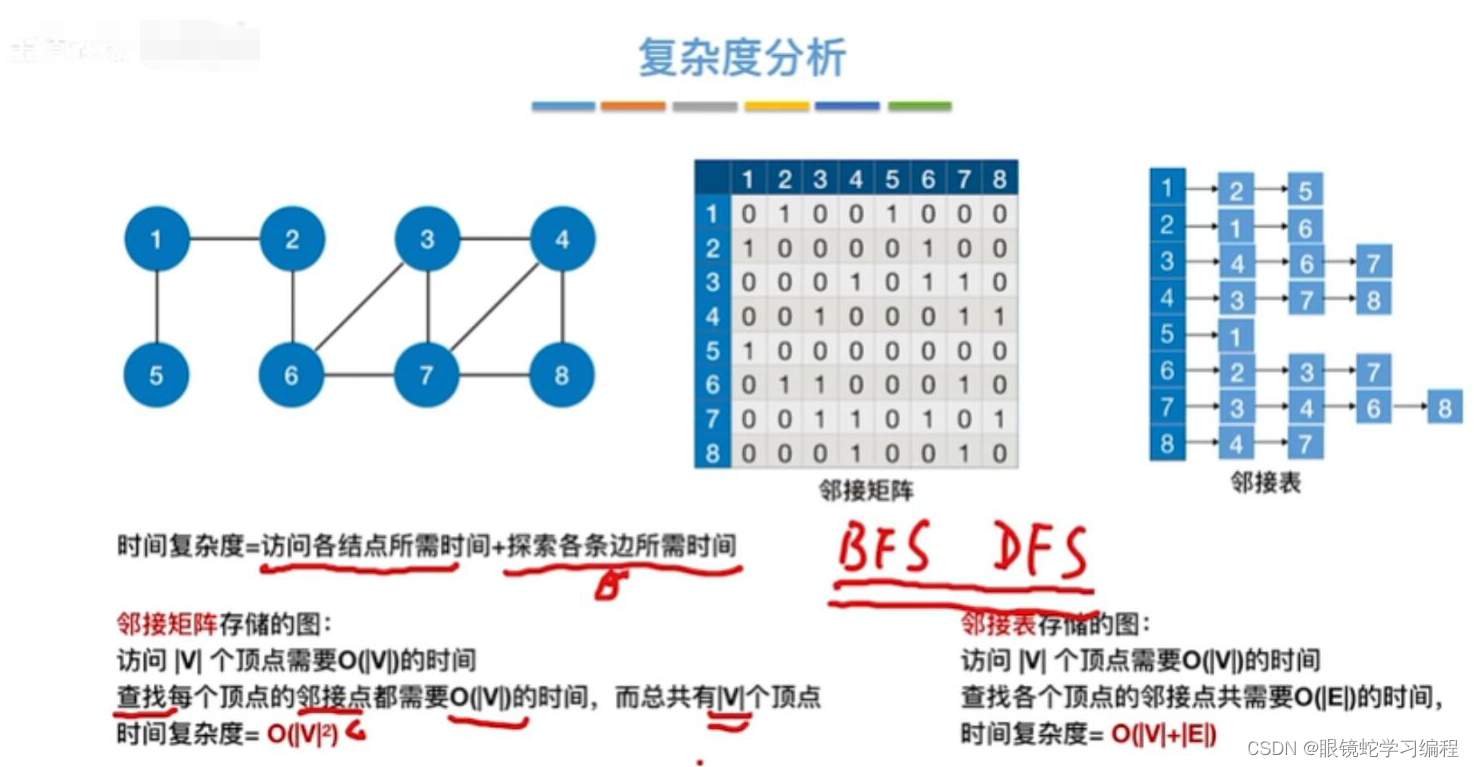
图的深度遍历复杂度问题
空间复杂度
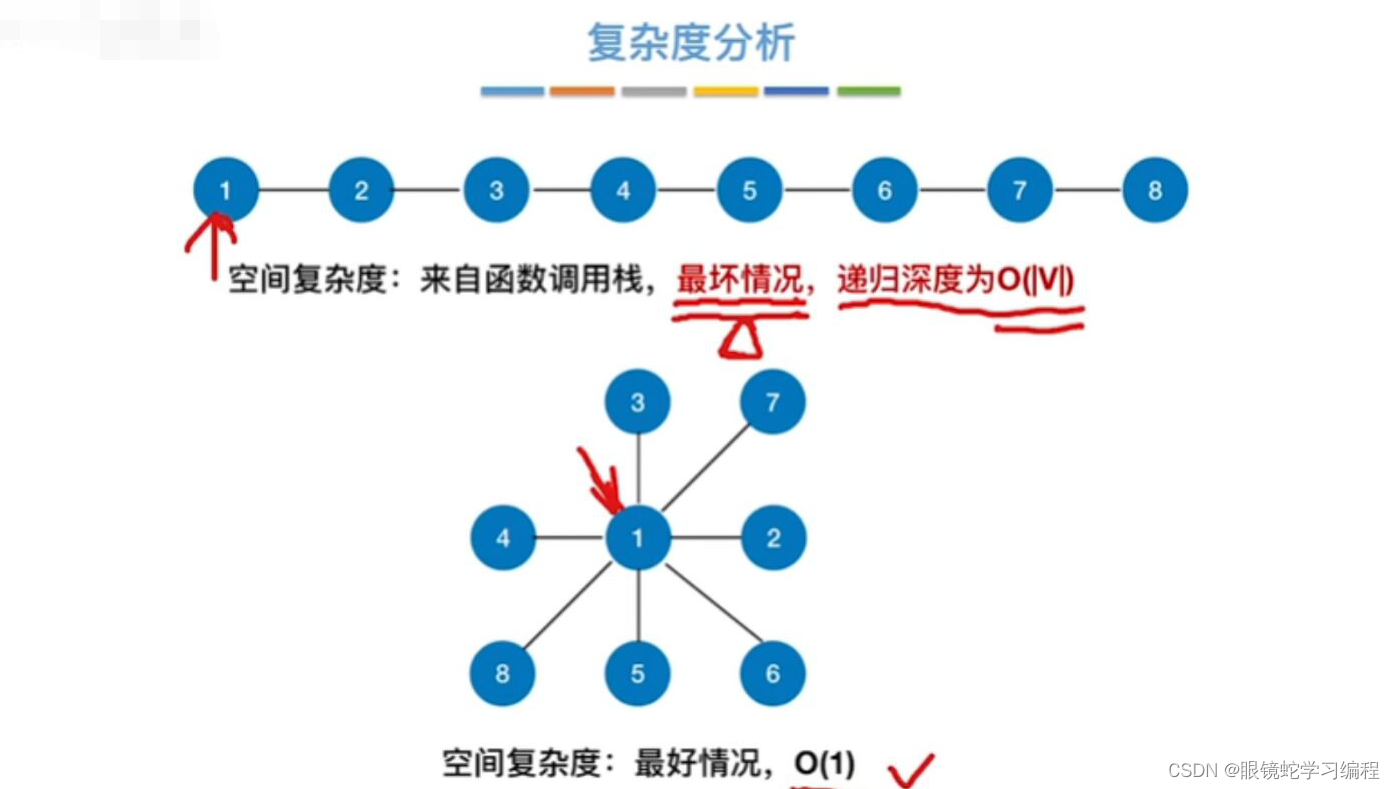
时间复杂度
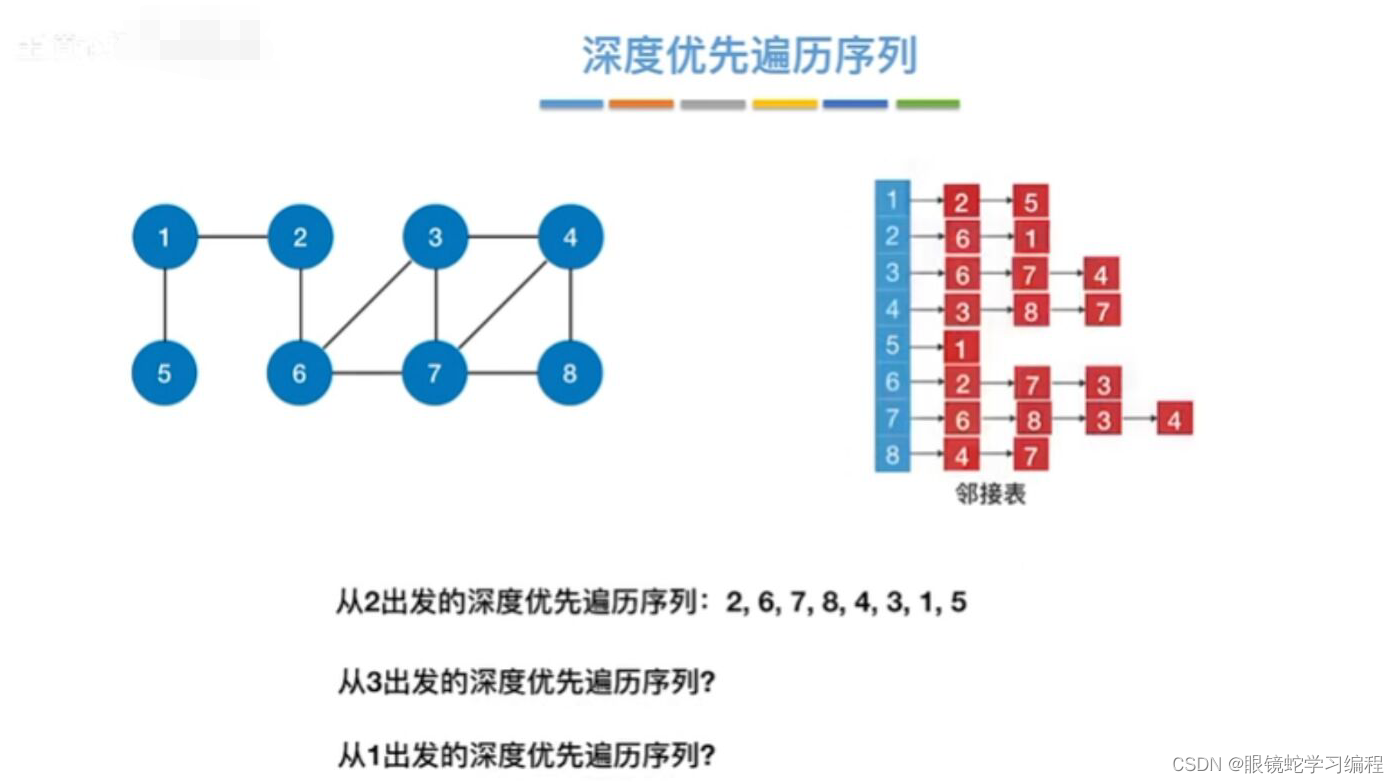
深度优先遍历序列
深度优先的生成树和生成森林
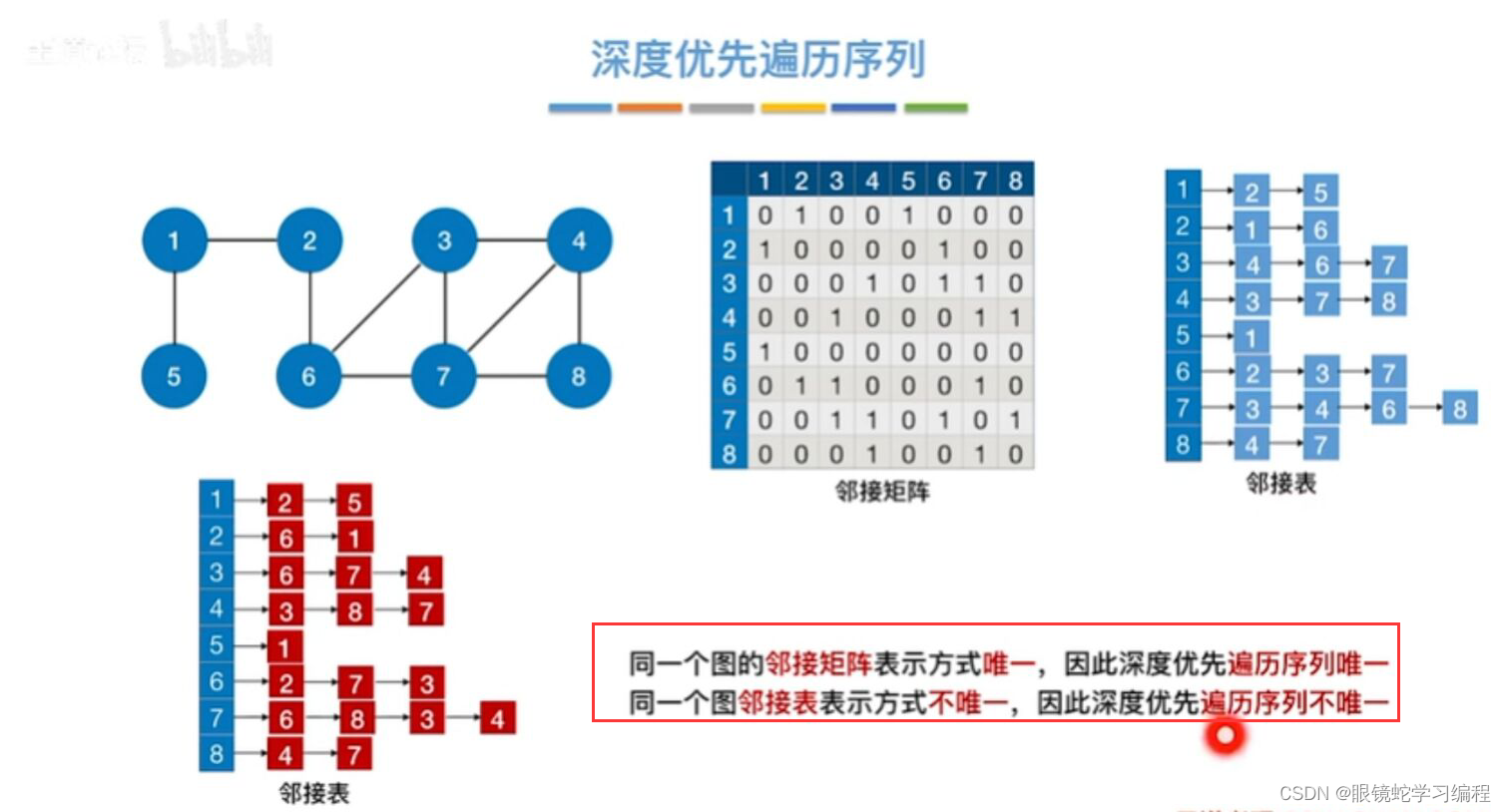
与广度优先搜索一样,深度优先搜索也会产生一颗深度优先生成树,当然这是有条件的,即对连通图调用深度优先遍历(DFS)才能产生深度优先生成树,否则产生的将是深度优先生成森林。与广度优先遍历(BFS)类似,基于邻接表存储的深度优先生成树是不唯一的。
图的遍历和连通性
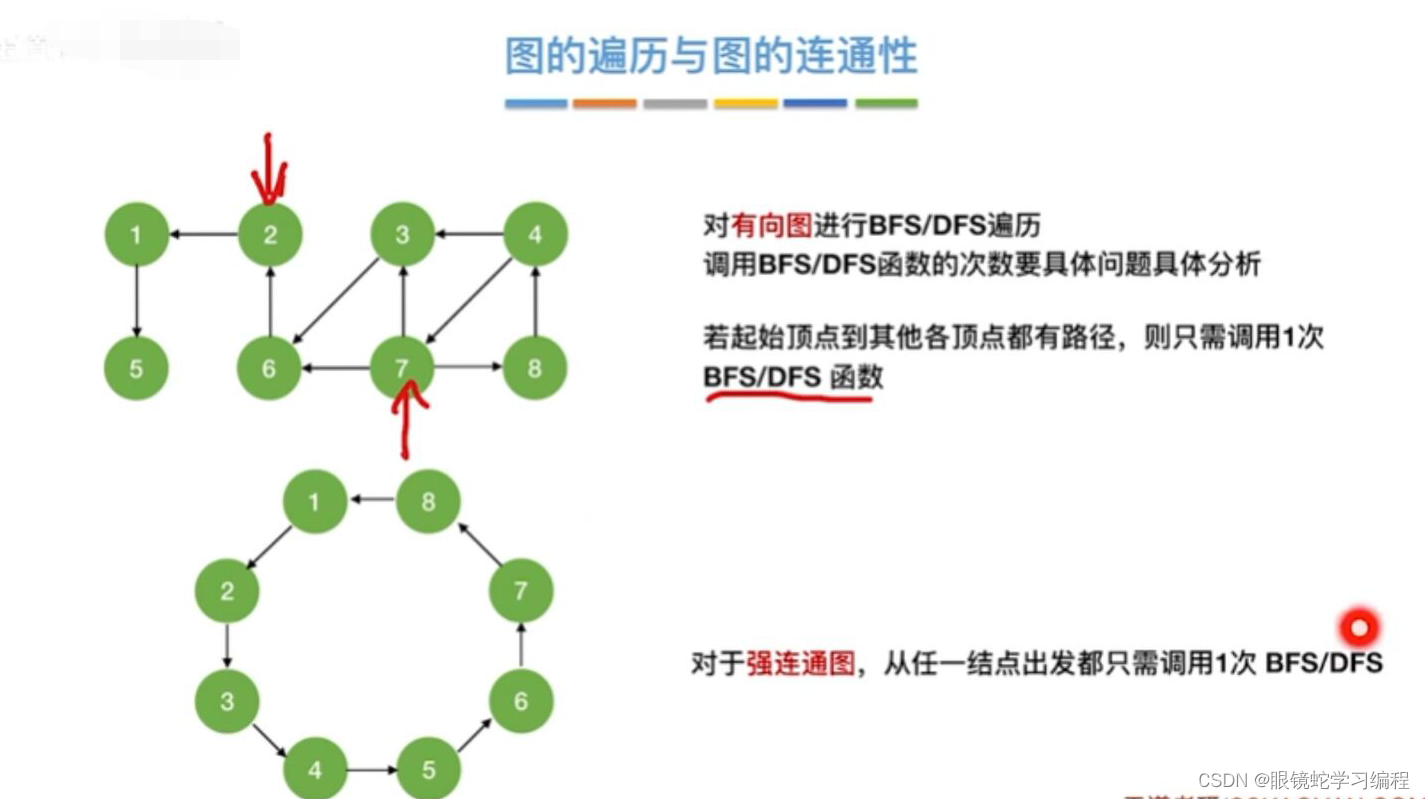
图的遍历算法可以用来判断图的连通性。
对于无向图来说,若无向图是连通的,则从任意一个节点出发,仅需一次遍历,就能够访问图中的所有顶点;若无向图是非连通的。则从某一个顶点出发,一次遍历只能访问到该顶点所在连通分量的所有顶点,而对于图中其他连通分量的顶点,则无法通过这次遍历访问。
对于有向图来说,若从初始点到图中的每个顶点都有路径,则能够访问到图中的所有顶点,否则不能访问到所有的顶点。
故在BFSTraverse()或DFSTraverse()中添加了第二个for循环,在选取初始点,继续进行遍历,以防止一次无法遍历图的所有顶点。对于无向图,上述两个函数调用BFS(G,i)或DFS(G,i)的次数等于该图的连通分量数;而对于有向图则不是这样,因为一个连通的有向图,分为强连通的和非强连通的,它的连通子图也分为强连通分量和非强连通分量,非强连通分量一次调用BFS(G,i)或DFS(G,i)无法访问到该连通分量的所有顶点。

回顾深度优先遍历















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









