







// 清除请求
void clear();
// 暂停请求
void pause();
}
请求类已经设计好了,那么在Request的begin的时候就开始获取图片;
当图片请求完之后,或者加载失败,加载展位图,都需要对控件进行设置,因此还需要设计一个类,专门用于设置图片控件;
于是小明设计出了一个ImageViewTarget,用于设置图片控件,请看下面的伪代码;
public class ImageViewTarget {
public void onLoadStarted(@Nullable Drawable placeholder) {
// 开始加载,设置图片展位图
}
public void onLoadFailed(@Nullable Drawable errorDrawable) {
// 加载失败,设置图片加载失败展位图
}
public void onResourceReady(@NonNull Drawable resource) {
// 加载成功,设置图片
}
}
那么将这个简单组合一个,就成了一个小小的“框架”,有了获取图片进行加载的功能了;
当然,我这里省略了部分代码,你只要知道大概的加载流程就可以了,不必深究细节;
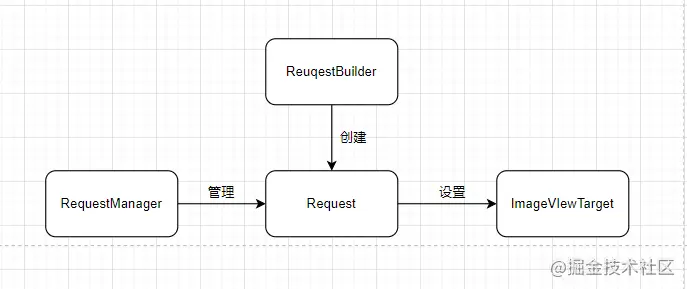
(1)通过RequestBuilder构建请求Request;
(2)通过RequestManager管理Request;
(3)Request请求成功或者失败回调ImageViewTarget设置给图片控件;
很简单,三步实现了一个小小的图片“框架”;
[]( )3、第三版本实现
----------------------------------------------------------------------
第一步我们已经简单实现了,通过网络请求,加载图片,设置给控件;
但是每一次都从网络上获取图片,在现实情况下,是非常不合理的;
因为每次都从网络上获取,不但会导致网络资源的浪费,并且还会影响加载速度,万一遇到网络不好的情况下,就容易加载很久才出来;
那么我们再对上面这个框架进行进一步的改造;
怎么改造呢? 很简单,引入缓存机制;
众所周知,Android的缓存机制可以分为几种,一种是网盘缓存,一种是磁盘缓存,一种是内存缓存;
那么我们就可以根据这三种情况来设计出具有三级缓存的图片加载机制;
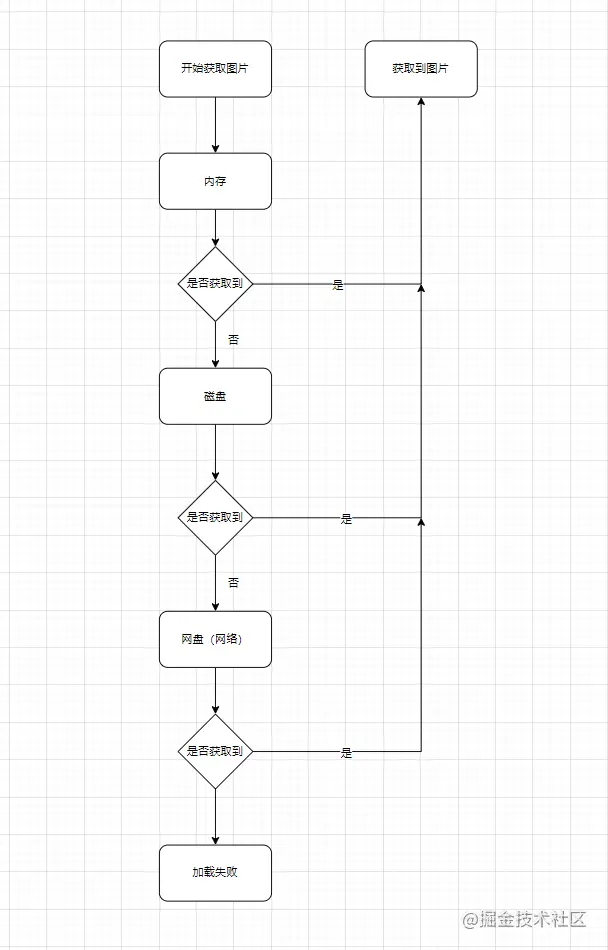
一个简单的缓存机制就设计完成了,接下来就是代码实现了;
要加载图片缓存机制,我们可以先设计出一个引擎类Engine,用来加载图片的三级缓存;
那么设计出来后大概是这个样子:
public class Engine {
public void load() {
// 从三级缓存里面加载图片
}
private Bitmap loadFromMemory() {
// 从缓存里获取图片
return null;
}
private Bitmap loadFromCache() {
// 从磁盘里获取图片
return null;
}
private Bitmap loadFromNetWork() {
// 从网络里获取图片
return null;
}
}
#### []( )3.1、内存缓存的设计
首先是内存缓存,内存缓存的设计,非常的重要,因为涉及到图片的回收;
回收早了,那么内存的缓存起不到实际作用,回收慢了,又会占用内存,浪费内存空间;
那么这个图片缓存的算法要怎么设计呢?
有一个著名算法,就是最近最少使用算法,非常适合用来做内存缓存的回收;
什么叫最近最少使用算法,当然字如其名;
即:长期不被使用的数据,在未来被用到的几率也不大。因此,当数据所占内存达到一定阈值时,要移除掉最近最少使用的数据。
具体的算法逻辑可以看下这个:[什么是LRU(最近最少使用)算法?]( )
那么我们这里就可以用这个算法来设计图片缓存;
public class LruResourceCache<T, Y> {
private final Map<T, Y> cache = new LinkedHashMap<>(100, 0.75f, true);
public synchronized Y put(@NonNull T key, @Nullable Y item) {
// 缓存图片
return null;
}
public synchronized Y get(@NonNull T key) {
// 获取图片
return null;
}
public void clearMemory() {
// 清除所有缓存
trimToSize(0);
}
protected synchronized void trimToSize(long size) {
// 回收内存到指定大小,将最近最少使用的,移除到指定大小
}
}
这里设计了几个方法,存和取的操作,还有清除缓存,回收图片内存的操作;
这时候你是否有疑问,我存取图片的key要用那个呢?
很简单,用图片的url,因为每一张图片的url都是不一样的,所以可以把这个作为唯一的key;
那么这个简单的内存缓存就设计好了;
接下来我们来看看磁盘缓存要怎么设计;
#### []( )3.2、磁盘缓存的设计
磁盘缓存的设计,其实没有那么复杂,无非就是将图片文件存储到手机存储卡里,读也是从存储卡里读;
和内存不同的是,从磁盘里读写的速度较慢,好处就是,磁盘可以存储比内存更多更大的图片文件;
因为和内存相比,存储卡的容量要远远高于内存的大小;
和内存意义,我们设计了一个读,一个写的操作; 读:负责从磁盘读取图片文件 写:负责将图片文件写入到磁盘
public class DiskLruCache {
public synchronized <T> T get(String key){
// 获取磁盘的数据
return null;
}
public synchronized <T> void put(String key, T value){
// 存储图片数据到磁盘中
}
}
#### []( )3.3、网络缓存的设计
网络缓存的设计就很简单了,也就是直接访问获取,获取图片文件;
public class NetWorkLruCache {
public synchronized <T> T request(String url){
// 获取网络的数据
return null;
}
}
那么到这里,一个简单的缓存机制就设计完成了;
#### []( )3.4、总结
那么一个简单的图片框架就这样实现了,相较于之前的框架,多了缓存机制,对于图片的利用有了很大的提升;
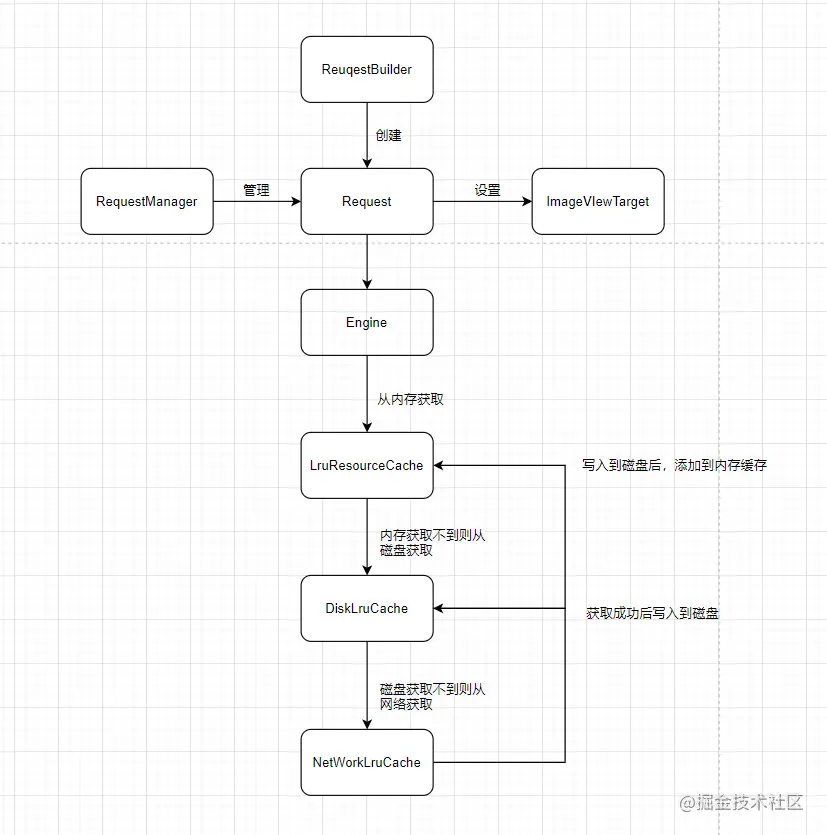
如果我告诉你,恭喜你,你已经成功掌握了Glide源码的实现,我想我可能会被一巴掌拍扁了;
但是我想要告诉你的是,上面的原理,就是一个Glide源码的简化,看懂了上面那个逻辑,基本上Glide源码的基本流程,你就已经搞懂了;
剩下的基本上就是更加细节的实现;
事实上,一个图片框架的实现基本上离不开这几步,更细节的实现,无非就是基于这几步来进行扩展,封装;
基础的原理搞明白了,再去深入研究源码,才会有意义;
[]( )4、Glide版本实现
-------------------------------------------------------------------------
我们上面通过抽取实现了一个简单的图片框架,虽然功能都有了,但是总是感觉缺少了点什么!
缺了什么呢?
缺了更多的细节,比如设计模式的封装,怎样解耦以及更好的复用!
还有就是性能优化,上面我们这个框架,虽然引入了缓存机制,但是还有更多的性能优化的点待挖掘;
下面我将根据上面这个简单的图片框架,来讲一讲Glide框架的实现的细节,相较于我们这个框架,有了什么更进一步的优化点;
### []( )4.1、RequestManager
我们上面在实现RequestManager的时候,提到了RequestManager的实现思路,手动的在Activity或者Fragment里面进行回调;
而Glide的实现更加的巧妙,通过创建一个不可见的Fragment来实现生命周期的回调;
Glide在调用Glide.with(this)方法的时候,就会返回一个创建好的RequestManager,在创建RequestManager会创建一个不可见的Fragment,并将其设置给RequestManager,让其具有生命周期的监听;
创建Fragment的实现逻辑是在RequestManagerRetriever的ragmentGet这个方法里面;
看一下大概的实现;
private RequestManager fragmentGet(
@NonNull Context context,
@NonNull android.app.FragmentManager fm,
@Nullable android.app.Fragment parentHint,
boolean isParentVisible) {
// 通过传进来的FragmentManager来创建一个不可见的RequestManagerFragment
RequestManagerFragment current = getRequestManagerFragment(fm, parentHint);
// 通过RequestManagerFragment获取RequestManager
RequestManager requestManager = current.getRequestManager();
if (requestManager == null) {
Glide glide = Glide.get(context);
// 如果RequestManager为空,则通过抽象工厂来创建RequestManger
requestManager =
factory.build(
glide, current.getGlideLifecycle(), current.getRequestManagerTreeNode(), context);
// 判断当前页面是否是可见的,是的话则回调开始方法;
if (isParentVisible) {
requestManager.onStart();
}
// 将RequestManager设置给了fragment
current.setRequestManager(requestManager);
}
return requestManager;
}
这里面的实现没有很复杂,就做了两件事,创建不可见的RequestManagerFragment,创建RequestManager,并将RequestManger设置给RequestManagerFragment,而RequestManagerFragment里面生命周期的回调,都会回调到RequestManager里;
这样就让RequestManager有了生命周期的监听;
这里的Lifecycle不是Jectpack的Lifecycle组件,而是自己定义的一个监听,用于回调生命周期;
这里有哪个优化细节值得探讨的呢?
这个细节就在于RequestManagerFragment的创建;
RequestManagerFragment的创建,并不是每次获取都会重新创建的;
总共有三步逻辑,请看下面的源码
private RequestManagerFragment getRequestManagerFragment(
@NonNull final android.app.FragmentManager fm, @Nullable android.app.Fragment parentHint) {
// 先通过FragmentManager来获取对应的fragment
RequestManagerFragment current = (RequestManagerFragment) fm.findFragmentByTag(FRAGMENT_TAG);
// 如果获取为空,则从一个HashMap集合中获取;
if (current == null) {
current = pendingRequestManagerFragments.get(fm);
// 如果从集合中获取为空,那么就新建一个Fragment并添加到页面去,然后再将其放到HashMap中,并发送消息,将该Fragment从HashMap中移除掉;
if (current == null) {
current = new RequestManagerFragment();
current.setParentFragmentHint(parentHint);
...
fm.beginTransaction().add(current, FRAGMENT_TAG).commitAllowingStateLoss();
...
}
}
return current;
}
这里主要做了两步操作:
第一步:通过FragmentManager来查找Fragment,如果获取到了则返回;
第二步:第一步没有获取到Fragment,则新建一个Fragment,将其添加到页面;
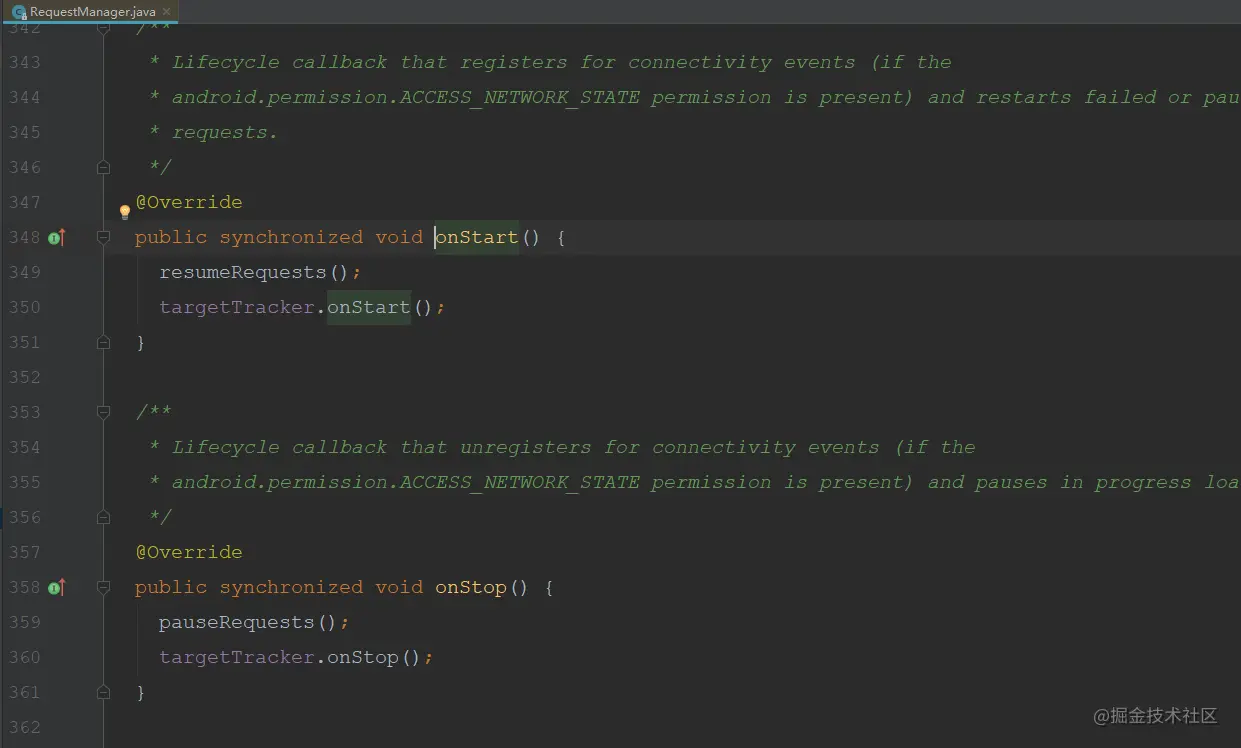
在RequestManagerFragment的生命周期方法里,通过lifecycle进行回调,而RequestManger注册了这个监听,那么就可以获取到生命周期;
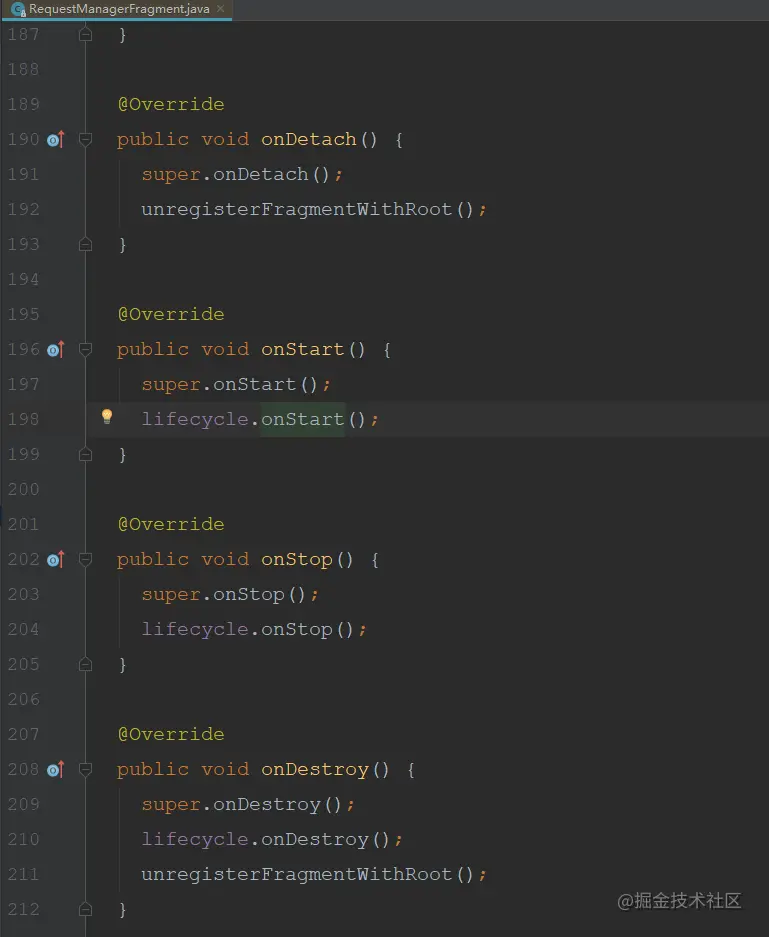
最终在RequestManger的生命周期里,开启了图片的加载和停止的操作;
### []( )4.2、RequestBuilder
RequestBuilder的职责很明确,用于创建获取图片的请求;
这个类使用了建造者模式来构建参数,这样有一个好处就是,可以很方便的添加各种各样复杂的参数;
这个RequestBuilder没有build方法,但是有into方法,原理其实一样,没有说一定要写成build;
最终加载图片的逻辑,就是在into方法里面实现的;
private <Y extends Target> Y into(
@NonNull Y target,
@Nullable RequestListener<TranscodeType> targetListener,
BaseRequestOptions<?> options,
Executor callbackExecutor) {
…
// 创建图片请求
Request request = buildRequest(target, targetListener, options, callbackExecutor);
// 获取当前图片控件是否已经有设置图片请求了,如果有且还没有加载完成,
// 或者加载完成但是加载失败了,那么就将这个请求再重新调用begin,再一次进行请求;
Request previous = target.getRequest();
if (request.isEquivalentTo(previous)
&& !isSkipMemoryCacheWithCompletePreviousRequest(options, previous)) {
…
if (!Preconditions.checkNotNull(previous).isRunning()) {
...
previous.begin();
}
return target;
}
//清除当前图片控件的图片请求
requestManager.clear(target);
// 设置请求给控件
target.setRequest(request);
// 再将请求添加到requestManager中
requestManager.track(target, request);
return target;
}
**这里有两个细节:**
**第一个细节:**
在开始请求之前,会先获取之前的请求,如果之前的请求还没有加载完成,或者加载完成了但是加载失败了,那么则会再次重试请求;
**第二个细节:**
将请求设置给了封装了图片控件的target,这样做有什么好处呢?
我们的页面大多数都是列表页,那么基本上会使用RecycleView这种列表控件来加载数据,而这种列表在加载图片的时候,快速滑动时会出现加载错乱的问题,其原因是RecycleView的Item复用的问题;
而Glide就是在这里通过这样的操作来避免这样的问题;
在调用setRequest的时候,将当前的Request作为tag设置给了View,那么在获取Request进行加载的时候,就不会出现错乱的问题;
private void setTag(@Nullable Object tag) {
…
view.setTag(tagId, tag);
}
### []( )4.3、Engine
从上面我们知道,一切的请求都是在Request的begin里开始的,而其实现是在SingleRequest的begin里面,最终会走到SingleRequest的onSizeReady里,通过Engine的load来加载图片数据;
这个load方法主要分为两步:
第一步:从内存加载数据
第二步:从磁盘或者网络加载数据
public LoadStatus load(…) {
…
synchronized (this) {
// 第一步
memoryResource = loadFromMemory(key, isMemoryCacheable, startTime);
// 第二步
if (memoryResource == null) {
return waitForExistingOrStartNewJob(
glideContext,
model,
signature,
width,
height,
resourceClass,
transcodeClass,
priority,
diskCacheStrategy,
transformations,
isTransformationRequired,
isScaleOnlyOrNoTransform,
options,
isMemoryCacheable,
useUnlimitedSourceExecutorPool,
useAnimationPool,
onlyRetrieveFromCache,
cb,
callbackExecutor,
key,
startTime);
}
}
…
return null;
}
简单回顾一些,我上面设计了一个LruResourceCache的类来做内存缓存,里面使用了LRU算法;
相较于我们上面设计的从内存加载数据的逻辑,Glide这里的细节体现在哪里呢?
private EngineResource<?> loadFromMemory(
EngineKey key, boolean isMemoryCacheable, long startTime) {
…
// 从弱引用里获取图片资源
EngineResource<?> active = loadFromActiveResources(key);
if (active != null) {
...
return active;
}
// 从LRU缓存里面获取图片资源
EngineResource<?> cached = loadFromCache(key);
if (cached != null) {
...
return cached;
}
return null;
}
**首先第一个细节:**
Glide设计了一个弱引用缓存,当从内存里面加载时,会先从弱引用里面获取图片资源;
为什么要多设计一层弱引用的缓存呢?
这里要说一下弱引用在内存里面的机制,弱引用对象在Java虚拟机触发GC时,会回收弱引用对象,不管此时内存是不是够用!
那么设计了一个弱引用缓存的好处在于,没有触发GC的这段时间,可以重复的利用图片资源,减少从LruCache里的操作;
看一下源码最终调用的地方:
synchronized EngineResource<?> get(Key key) {
// 根据Key获取到了一个弱引用对象
ResourceWeakReference activeRef = activeEngineResources.get(key);
if (activeRef == null) {
return null;
}
EngineResource<?> active = activeRef.get();
…
return active;
}
**第二个细节:**
从LruCache里获取图片资源后,并将其存入到弱引用缓存里;
private EngineResource<?> loadFromCache(Key key) {
//
EngineResource<?> cached = getEngineResourceFromCache(key);
if (cached != null) {
cached.acquire();
activeResources.activate(key, cached);
}
return cached;
}
还有一个操作就是在图片加载完成之后,会将该图片资源存入到弱引用缓存里,以便后续复用;
其源码位置在这里调用:Engine的onEngineJobComplete;
而这个方法是在图片加载的回调里调用的,也就是EngineJob的onResourceReady
public synchronized void onEngineJobComplete(
EngineJob<?> engineJob, Key key, EngineResource<?> resource) {
…
if (resource != null && resource.isMemoryCacheable()) {
// 存入到弱引用缓存里
activeResources.activate(key, resource);
}
…
}
其实这两个细节,都是由弱引用缓存来引入的,正是因为多了一个弱引用缓存,所以才能把图片的加载性能压榨到了极致;
有人会说,加了这个有啥用呢? 又不能快多少。
俗话说的好:性能都是一步步压榨出来的,在能优化的地方优化一点点,渐渐的积累,也就成河流了!
如果上面都获取不到图片资源,那么接下来就会从磁盘或者网络加载数据了;
### []( )4.4、DecodeJob
从磁盘或者网络读取,必然是一个耗时的任务,那么肯定是要放在子线程里面执行,而Glide里也正是这样实现的;
来看下大致的源码:
最终会创建一个叫DecodeJob的异步任务,来看下这个DecordJob的run方法做了什么操作?
public void run() {
…
runWrapped();
…
}
run方法里面主要有一个runWrapped方法,这个方法才是最终执行的地方;
在这个com.bumptech.glide.load.engine.DecodeJob#getNextGenerator方法里面,会获取内存生产者Generator,这几个内容生产者分别对应着不同的缓存数据;
private DataFetcherGenerator getNextGenerator() {
switch (stage) {
case RESOURCE_CACHE:
return new ResourceCacheGenerator(decodeHelper, this);
case DATA_CACHE:
return new DataCacheGenerator(decodeHelper, this);
case SOURCE:
return new SourceGenerator(decodeHelper, this);
case FINISHED:
return null;
...
}
}
### []( )4.5、DataCacheGenerator
ResourceCacheGenerator:对应转化后的图片资源生产者;
DataCacheGenerator:对应没有转化的原生图片资源生产者;
SourceGenerator:对应着网络资源内容生产者;
这里我们只关心从磁盘获取的数据,那么则对应着这个ResourceCacheGenerator和这个DataCacheGenerator的生产者;
这两个方法的实现差不多,都是通过获取一个File对象,然后再根据File对象来加载对应的图片数据;
从上面我们可以知道,Glide的磁盘缓存,是从DiskLruCache里面获取的;
下面我们来看一下这个DataCacheGenerator的startNext方法;
public boolean startNext() {
while (modelLoaders == null || !hasNextModelLoader()) {
sourceIdIndex++;
...
Key originalKey = new DataCacheKey(sourceId, helper.getSignature());
// 通过生成的key从DiskLruCache里面获取File对象
cacheFile = helper.getDiskCache().get(originalKey);
if (cacheFile != null) {
this.sourceKey = sourceId;
modelLoaders = helper.getModelLoaders(cacheFile);
modelLoaderIndex = 0;
}
}
…
while (!started && hasNextModelLoader()) {
ModelLoader<File, ?> modelLoader = modelLoaders.get(modelLoaderIndex++);
loadData =
modelLoader.buildLoadData(
cacheFile, helper.getWidth(), helper.getHeight(), helper.getOptions());
if (loadData != null && helper.hasLoadPath(loadData.fetcher.getDataClass())) {
started = true;
loadData.fetcher.loadData(helper.getPriority(), this);
}
}
return started;
}
这里主要分为两步:
第一步是通过生成的key从DiskLruCache里面获取File对象;
第二步是将File对象,通过LoadData将File对象转化为Bitmap对象;
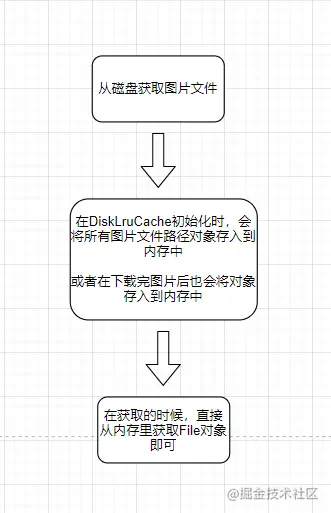
**第一步:获取File对象**
Glide在加载DiskLruCache的时候,会将所有图片对应的路径信息加载到内存中,当调用DiskLruCache的get方法时,其实是从DiskLruCache里面维护的一个Lru内存缓存里直接获取的;
所以第一步的get方法,其实是从LruCache内存缓存里面获取File对象的;
这个处理逻辑是在DiskLruCache的open方法里面操作的,里面会触发一个读取本地文件的操作,也就是DiskLruCache的readJournal方法;
最终走到了readJournalLine方法;
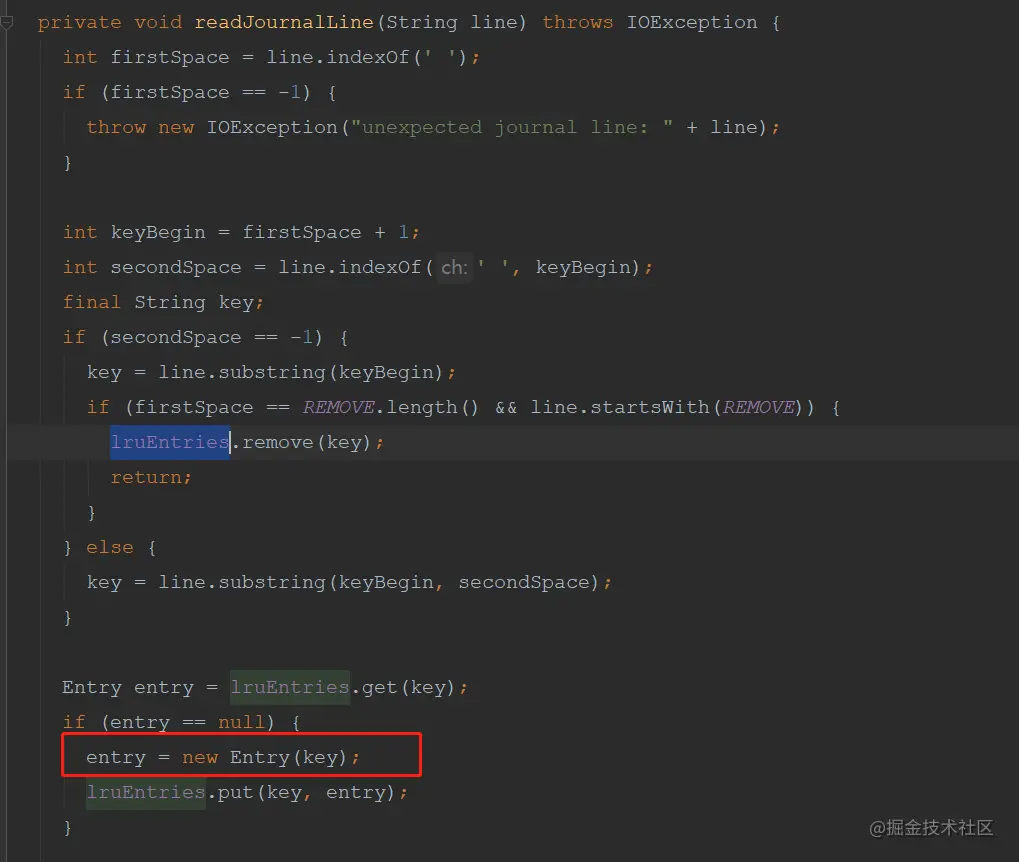
这个文件主要存放了图片资源的key,用于获取本地图片路径的文件;
最终是在DiskLruCache的readJournalLine方法里面,会创建一个Entry对象,在Entry对象的构造方法里面创建了File对象;
private Entry(String key) {
…
for (int i = 0; i < valueCount; i++) {
// 创建图片文件File对象
cleanFiles[i] = new File(directory, fileBuilder.toString());
fileBuilder.append(".tmp");
dirtyFiles[i] = new File(directory, fileBuilder.toString());
...
}
}
到这里你是否会有疑问了,如果我是在DiskLruCache初始化之后下载的图片呢? 这时候DiskLruCache的Lru内存里面肯定没有这个数据,那这个数据是哪来的?
相信聪明的你已经猜到了,就是图片文件在存入本地的时候也会将其加入到DiskLruCache的Lru内存里;
其实现是在DiskLruCache的edit()方法;
private synchronized Editor edit(String key, long expectedSequenceNumber) throws IOException {
…
Entry entry = lruEntries.get(key);
…
if (entry == null) {
entry = new Entry(key);
lruEntries.put(key, entry);
}
…
Editor editor = new Editor(entry);
entry.currentEditor = editor;
…
return editor;
}
这里先把生成的Entry对象加入到内存中,然后再通过Editor将图片文件写入到本地,通过IO操作,这里就不多赘述了;
存的方法有了,来看一下DiskLruCache的get方法吧;
public synchronized Value get(String key) throws IOException {
…
// 直接通过内存获取Entry对象;
Entry entry = lruEntries.get(key);
…
return new Value(key, entry.sequenceNumber, entry.cleanFiles, entry.lengths);
}
**第二步:File对象转化**
当根据key拿到File对象时,那么接下来就是将File文件转化为bitmap数据了;
这一段代码的设计非常有意思,下面我们来看一下具体是怎么实现的!
DataCacheGenerator的startNext方法:
public boolean startNext() {
while (modelLoaders == null || !hasNextModelLoader()) {
...
modelLoaders = helper.getModelLoaders(cacheFile);
...
}
while (!started && hasNextModelLoader()) {
// 遍历获取ModelLoader
ModelLoader<File, ?> modelLoader = modelLoaders.get(modelLoaderIndex++);
// 获取LoadData
loadData =
modelLoader.buildLoadData(
cacheFile, helper.getWidth(), helper.getHeight(), helper.getOptions());
if (loadData != null && helper.hasLoadPath(loadData.fetcher.getDataClass())) {
// 加载数据
started = true;
loadData.fetcher.loadData(helper.getPriority(), this);
}
}
return started;
}
### []( )4.6、ModelLoader
这里通过设计了ModelLoader类,来用于加载数据逻辑;
这一段代码都是基于接口来实现的,没有依赖具体实现,好处就是非常的解耦与灵活,坏处就是代码阅读性降低,因为你很一时半会很难找到这里的实现类到底是哪个!
这个ModelLoader类的职责具体是做什么的呢? 我们可以先来看看注释;

翻译过来的意思就是:将任意复杂的数据模型转换为具体数据类型的工厂接口;
怎么理解这句话呢? 可以理解为适配器模式,将某一类数据转化为另外一类数据;
public interface ModelLoader<Model, Data> {
结语
由于篇幅限制,文档的详解资料太全面,细节内容太多,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!以下是目录截图:

由于整个文档比较全面,内容比较多,篇幅不允许,下面以截图方式展示 。
再附一部分Android架构面试视频讲解:
olean startNext() {
while (modelLoaders == null || !hasNextModelLoader()) {
...
modelLoaders = helper.getModelLoaders(cacheFile);
...
}
while (!started && hasNextModelLoader()) {
// 遍历获取ModelLoader
ModelLoader<File, ?> modelLoader = modelLoaders.get(modelLoaderIndex++);
// 获取LoadData
loadData =
modelLoader.buildLoadData(
cacheFile, helper.getWidth(), helper.getHeight(), helper.getOptions());
if (loadData != null && helper.hasLoadPath(loadData.fetcher.getDataClass())) {
// 加载数据
started = true;
loadData.fetcher.loadData(helper.getPriority(), this);
}
}
return started;
}
### []( )4.6、ModelLoader
这里通过设计了ModelLoader类,来用于加载数据逻辑;
这一段代码都是基于接口来实现的,没有依赖具体实现,好处就是非常的解耦与灵活,坏处就是代码阅读性降低,因为你很一时半会很难找到这里的实现类到底是哪个!
这个ModelLoader类的职责具体是做什么的呢? 我们可以先来看看注释;

翻译过来的意思就是:将任意复杂的数据模型转换为具体数据类型的工厂接口;
怎么理解这句话呢? 可以理解为适配器模式,将某一类数据转化为另外一类数据;
public interface ModelLoader<Model, Data> {
结语
由于篇幅限制,文档的详解资料太全面,细节内容太多,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!以下是目录截图:
[外链图片转存中…(img-MxTLVY98-1630930020261)]
由于整个文档比较全面,内容比较多,篇幅不允许,下面以截图方式展示 。
再附一部分Android架构面试视频讲解:
[外链图片转存中…(img-xdSw0Qvl-1630930020265)]















 1097
1097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









