






awk
逐行读取输入文本,逐行匹配查找,广泛用于shell脚本,完成各种自动化配置任务,文本去重不需要连续
awk ‘BEGIN{X=1};{x++};END{print x}' test1.txt 行数+1
free -h
free -m
top
-F ‘分隔符’指名输入时用到的字段分隔符
-v 变量赋值 var=value
注意一定是单引号:‘模式或条件’
{ }外指定操作,print {i} 内直接跟变量
$0 当前处理行的整行内容
$n 当前处理的第几列(n列)
NR当前处理行的行号
NF当前处理行的字段个数
FS列分割符,输入
OFS
RS

awk {print}默认1打印为0不打印
awk ‘{print NR,$0}’ test1.txt
awk 'NR==3{print}' test1.txt
awk 'NR==3,NR==5{print}' test1.txt //3到5行
awk 'NR==3;NR=={print}' test1.txt //3和5行
awk '(NR>=4)&&(NR
打印第4到9行的内容
awk ‘NR%2==0{print}’ test1
奇数行
awk ‘NR%2==1{print}’ test1
偶数行
awk 'BEGIN{print 100+200}'
awk 'BEGIN{print 3^2}'
awk 'BEGIN{print 3**2}'
getline
左右无重定向符号("<")

awk '{geline;print $0}' test1.txt //偶数行
awk'{print $0;getline}' test1.txt //奇数行
awk '{getline < "test1.txt";print $0 > "ky27.txt"}' test1.txt
ls | awk '{getline line; print $0,line;}'

BEGIN打印模式awk 'BEGIN{...} ;{...};END{print x}' test1。txt
循环行数
-F以指定分隔符赋值
![]()
把:换成+(只适用于分隔符)
print{$1,$3} //与sed和NS不同不是到二十1行和3行
echo $PATH | awk -v RS=':' '{print $0}' //RS默认形势是换行

awk -F: '!($3>10){print $0}' /etc/passwd
awk -F: '{if ($3>500){print $0}}' /etc/passwd
awk 三元表达式
awk -F: '{max=($3>=$4)?$3:$4;{print max,$0}' /etc/passwd |sed -n '1,6p' //?等于if(为真)赋值$3 否则为$4
cat -n /etc/passwd | head -n 10
awk -F: '$7!~"nologin" {print $1,$NF}' /etc/passwd //第一个字段和最后一个字段
![]()
找名字为dn的普通用户RS默认换行
$NF最后一个字段
$0所有内容
OFS: 输出内容的列分隔符$n=$n用于激活,否则不生效
替换前面
echo a b c d | tr " " ":"
echo a b c d | awk '{0FS=":";$1=$1;print $0}'
法二
echo a b c d | awk 'BEGIN{OFS=":"};{$1=$1;print $0}'
awk结合数组
awk 'BEGIN{a[0]=10;a[1]=20;a[2]=30} ' //在awk中不需要$
awk 遍历多少行多少行有关索引
awk默认以空格为分割
简单日志分割
awk '{print $1, $7, $9}' /var/log/messages
result=$(awk 'BEGIN{printf "%.2f", 2.331*2.542}') //取小数点后2位
getline 和printf一个意思函数
%.F 取整
awk -F'[ .]

awk '{print $2}' host.txt | awk -F. '{print $1}'
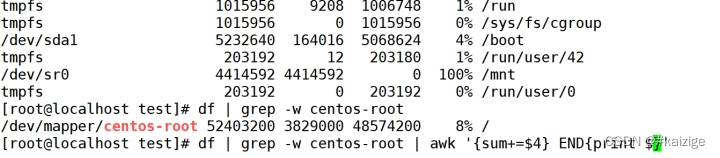
END表示 执行前面的内容
ls -l /etc/ | awk '/^-/ {sum+=$5} END{print "文件总大小:"sum/1024"M"}'
grep -w " " //取行 top -b -n 1
统计cpu 统计内存free -m















 5333
5333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









