







做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

(4)200多本电子书
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
+ [安装浏览器驱动](#font_colororangefont_31)
+ - [确定浏览器版本](#font_color33CCCCfont_42)
- [下载驱动](#font_color33CCCCfont_48)
+ [定位页面元素](#font_colororangefont_66)
+ - [打开指定页面](#font_color33CCCCfont_67)
- [id 定位](#font_color33CCCCid_font_104)
- [name 定位](#font_color33CCCCname_font_115)
- [class 定位](#font_color33CCCCclass_font_125)
- [tag 定位](#font_color33CCCCtag_font_135)
- [xpath 定位](#font_color33CCCCxpath_font_145)
- [css 定位](#font_color33CCCCcss_font_176)
- [link 定位](#font_color33CCCClink_font_196)
- [partial\_link 定位](#font_color33CCCCpartial_link_font_206)
+ [浏览器控制](#font_colororangefont_218)
+ - [修改浏览器窗口大小](#font_color33CCCCfont_219)
- [浏览器前进&后退](#font_color33CCCCfont_240)
- [浏览器刷新](#font_color33CCCCfont_272)
- [浏览器窗口切换](#font_color33CCCCfont_279)
- [常见操作](#font_color33CCCCfont_288)
+ [鼠标控制](#font_colororangefont_342)
+ - [单击左键](#font_color33CCCCfont_353)
- [单击右键](#font_color33CCCCfont_362)
- [双击](#font_color33CCCCfont_373)
- [拖动](#font_color33CCCCfont_382)
- [鼠标悬停](#font_color33CCCCfont_395)
+ [键盘控制](#font_colororangefont_409)
❤ 系列内容 ❤
爬虫+自动化利器 selenium 之自学成才篇(一)
主要内容:selenium 简介、selenium 安装、安装浏览器驱动、8 种方式定位页面元素、浏览器控制、鼠标控制、键盘控制
爬虫+自动化利器 selenium 之自学成才篇(二)
主要内容:三种等待方式(显式等待、隐式等待、强制等待)、一组元素的定位方式、切换操作(窗口切换、表单切换)、弹窗处理等。
爬虫+自动化利器 selenium 之自学成才篇(三)
主要内容:文件上传 & 下载、cookie 操作、调用 JavaScript(滑动滚动条)、关闭操作、页面截图等。

selenium 简介
Selenium 是最广泛使用的开源 Web UI(用户界面)自动化测试套件之一。Selenium 支持的语言包括C#,Java,Perl,PHP,Python 和 Ruby。目前,Selenium Web 驱动程序最受 Python 和 C#欢迎。 Selenium 测试脚本可以使用任何支持的编程语言进行编码,并且可以直接在大多数现代 Web 浏览器中运行。在爬虫领域 selenium 同样是一把利器,能够解决大部分的网页的反爬问题,但也不是万能的,它最明显的缺点就是速度慢。下面就进入正式的 study 阶段。
selenium安装
打开 cmd,输入下面命令进行安装。
pip install -i https://pypi.douban.com/simple selenium
执行后,使用 pip show selenium 查看是否安装成功。
安装浏览器驱动
针对不同的浏览器,需要安装不同的驱动。下面列举了常见的浏览器与对应的驱动程序下载链接,部分网址需要 “科学上网” 才能打开哦(dddd)。
- Firefox 浏览器驱动:Firefox
- Chrome 浏览器驱动:Chrome
- IE 浏览器驱动:IE
- Edge 浏览器驱动:Edge
- PhantomJS 浏览器驱动:PhantomJS
- Opera 浏览器驱动:Opera
这里以安装 Chrome 驱动作为演示。但 Chrome 在用 selenium 进行自动化测试时还是有部分 bug ,常规使用没什么问题,但如果出现一些很少见的报错,可以使用 Firefox 进行尝试,毕竟是 selenium 官方推荐使用的。
确定浏览器版本
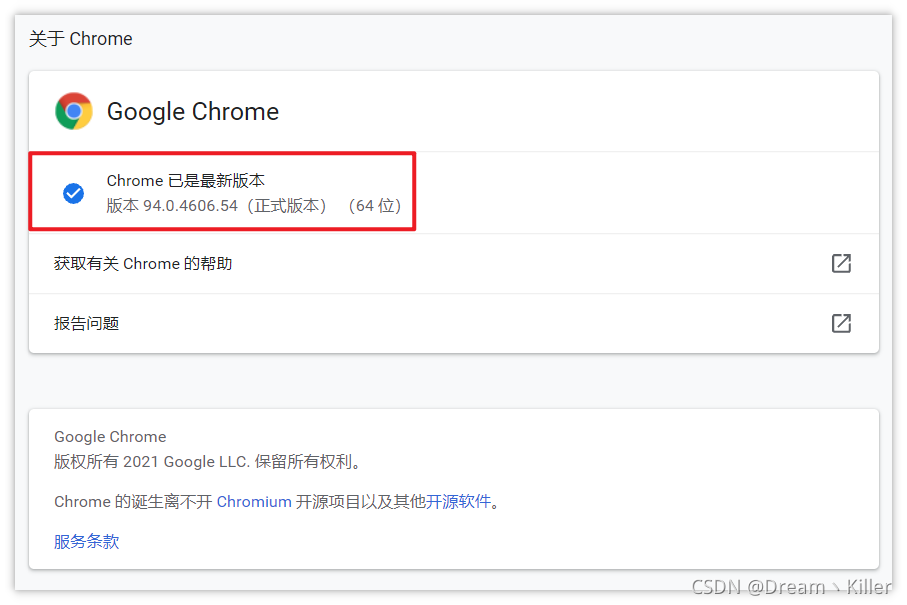
在新标签页输入 chrome://settings/ 进入设置界面,然后选择 【关于 Chrome】
查看自己的版本信息。这里我的版本是94,这样在下载对应版本的 Chrome 驱动即可。
下载驱动
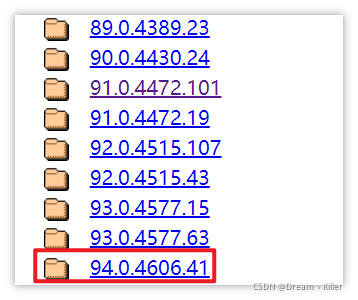
打开 Chrome驱动 。单击对应的版本。
根据自己的操作系统,选择下载。
下载完成后,压缩包内只有一个 exe 文件。
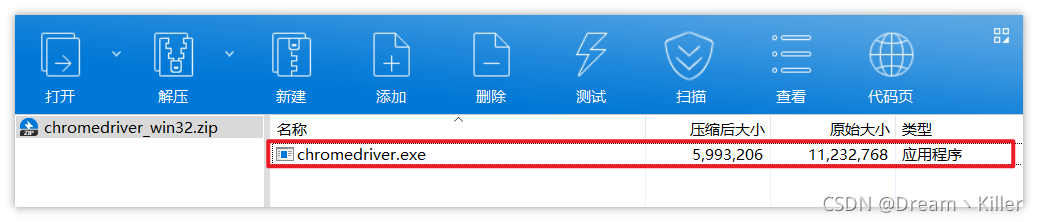
将 chromedriver.exe 保存到任意位置,并把当前路径保存到环境变量中(我的电脑>>右键属性>>高级系统设置>>高级>>环境变量>>系统变量>>Path),添加的时候要注意不要把 path 变量给覆盖了,如果覆盖了千万别关机,然后百度。添加成功后使用下面代码进行测试。
from selenium import webdriver
# Chrome浏览器
driver = webdriver.Chrome()
定位页面元素
打开指定页面
使用 selenium 定位页面元素的前提是你已经了解基本的页面布局及各种标签含义,当然如果之前没有接触过,现在我也可以带你简单的了解一下。
以我们熟知的 CSDN 为例,我们进入首页,按 【F12】 进入开发者工具。红框中显示的就是页面的代码,我们要做的就是从代码中定位获取我们需要的元素。
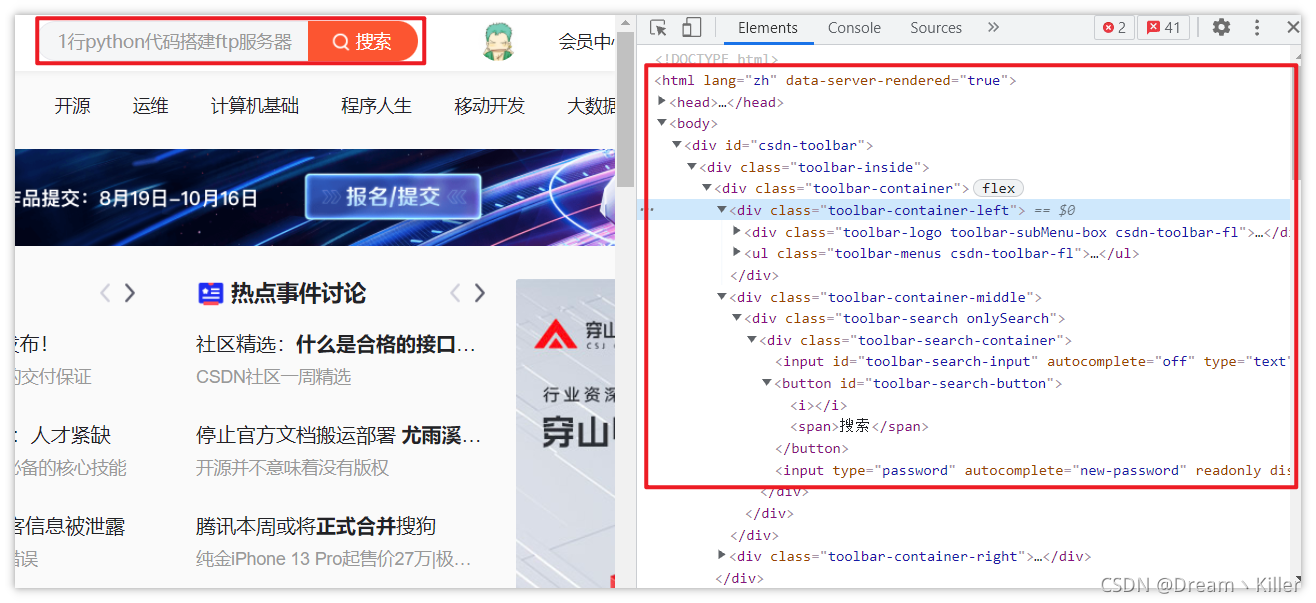
想要定位并获取页面中的信息,首先要使用 webdriver 打开指定页面,再去定位。
from selenium import webdriver
# Chrome浏览器
driver = webdriver.Chrome()
driver.get('https://www.csdn.net/')
执行上面语句后会发现,浏览器打开 CSDN 主页后会马上关闭,想要防止浏览器自动关闭,可以添加下面代码。
# 不自动关闭浏览器
option = webdriver.ChromeOptions()
option.add_experimental_option("detach", True)
# 将option作为参数添加到Chrome中
driver = webdriver.Chrome(chrome_options=option)
这样将上面的代码组合再打开浏览器就不会自动关闭了。
from selenium import webdriver
# 不自动关闭浏览器
option = webdriver.ChromeOptions()
option.add_experimental_option("detach", True)
# 注意此处添加了chrome\_options参数
driver = webdriver.Chrome(chrome_options=option)
driver.get('https://www.csdn.net/')
下面我们再来看看几种常见的页面元素定位方式。
id 定位
标签的 id 具有唯一性,就像人的身份证,假设有个 input 标签如下。
<input id="toolbar-search-input" autocomplete="off" type="text" value="" placeholder="C++难在哪里?">
我们可以通过 id 定位到它,由于 id 的唯一性,我们可以不用管其他的标签的内容。
driver.find_element_by_id("toolbar-search-input")
name 定位
name 指定标签的名称,在页面中可以不唯一。假设有个 meta 标签如下
<meta name="keywords" content="CSDN博客,CSDN学院,CSDN论坛,CSDN直播">
我们可以使用 find_element_by_name 定位到 meta 标签。
driver.find_element_by_name("keywords")
class 定位
class 指定标签的类名,在页面中可以不唯一。假设有个 div 标签如下
<div class="toolbar-search-container">
我们可以使用 find_element_by_class_name 定位到 div 标签。
driver.find_element_by_class_name("toolbar-search-container")
tag 定位
每个 tag 往往用来定义一类功能,所以通过 tag 来识别某个元素的成功率很低,每个页面一般都用很多相同的 tag ,比如:\<div\>、\<input\> 等。这里还是用上面的 div 作为例子。
<div class="toolbar-search-container">
我们可以使用 find_element_by_class_name 定位到 div 标签。
driver.find_element_by_tag_name("div")
xpath 定位
xpath 是一种在 XML 文档中定位元素的语言,它拥有多种定位方式,下面通过实例我们看一下它的几种使用方式。
<html>
<head>...<head/>
<body>
<div id="csdn-toolbar">
<div class="toolbar-inside">
<div class="toolbar-container">
<div class="toolbar-container-left">...</div>
<div class="toolbar-container-middle">
<div class="toolbar-search onlySearch">
<div class="toolbar-search-container">
<input id="toolbar-search-input" autocomplete="off" type="text" value="" placeholder="C++难在哪里?">
根据上面的标签需要定位 最后一行 input 标签,以下列出了四种方式,xpath 定位的方式多样并不唯一,使用时根据情况进行解析即可。
# 绝对路径(层级关系)定位
driver.find_element_by_xpath(
"/html/body/div/div/div/div[2]/div/div/input[1]")
# 利用元素属性定位
driver.find_element_by_xpath(
"//\*[@id='toolbar-search-input']"))
# 层级+元素属性定位
driver.find_element_by_xpath(
"//div[@id='csdn-toolbar']/div/div/div[2]/div/div/input[1]")
# 逻辑运算符定位
driver.find_element_by_xpath(
"//\*[@id='toolbar-search-input' and @autocomplete='off']")
css 定位
CSS 使用选择器来为页面元素绑定属性,它可以较为灵活的选择控件的任意属性,一般定位速度比 xpath 要快,但使用起来略有难度。
CSS 选择器常见语法:
| 方法 | 例子 | 描述 |
|---|---|---|
| .class | .toolbar-search-container | 选择 class = 'toolbar-search-container' 的所有元素 |
| #id | #toolbar-search-input | 选择 id = 'toolbar-search-input' 的元素 |
| * | * | 选择所有元素 |
| element | input | 选择所有 <input\> 元素 |
| element>element | div>input | 选择父元素为 <div\> 的所有 <input\> 元素 |
| element+element | div+input | 选择同一级中在 <div\> 之后的所有 <input\> 元素 |
| [attribute=value] | type='text' | 选择 type = 'text' 的所有元素 |
举个简单的例子,同样定位上面实例中的 input 标签。
driver.find_element_by_css_selector('#toolbar-search-input')
driver.find_element_by_css_selector('html>body>div>div>div>div>div>div>input')
link 定位
link 专门用来定位文本链接,假如要定位下面这一标签。
<div class="practice-box" data-v-04f46969="">加入!每日一练</div>
我们使用 find_element_by_link_text 并指明标签内全部文本即可定位。
driver.find_element_by_link_text("加入!每日一练")
partial_link 定位
partial_link 翻译过来就是“部分链接”,对于有些文本很长,这时候就可以只指定部分文本即可定位,同样使用刚才的例子。
<div class="practice-box" data-v-04f46969="">加入!每日一练</div>
我们使用 find_element_by_partial_link_text 并指明标签内部分文本进行定位。
driver.find_element_by_partial_link_text("加入")
浏览器控制
修改浏览器窗口大小
from selenium import webdriver
# Chrome浏览器
driver = webdriver.Chrome()
driver.get('https://www.csdn.net/')
# 设置浏览器浏览器的宽高为:600x800
driver.set_window_size(600, 800)
使用 maximize_window() 方法可以实现浏览器全屏显示。
from selenium import webdriver
# Chrome浏览器
driver = webdriver.Chrome()
driver.get('https://www.csdn.net/')
# 设置浏览器浏览器的宽高为:600x800
driver.maximize_window()
浏览器前进&后退
webdriver 提供 back 和 forward 方法来实现页面的后退与前进。下面我们 ①进入CSDN首页,②打开CSDN个人主页,③back 返回到CSDN首页,④ forward 前进到个人主页。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
# 访问CSDN首页
driver.get('https://www.csdn.net/')
sleep(2)
#访问CSDN个人主页
driver.get('https://blog.csdn.net/qq\_43965708')
sleep(2)
#返回(后退)到CSDN首页
driver.back()
sleep(2)
#前进到个人主页
driver.forward()
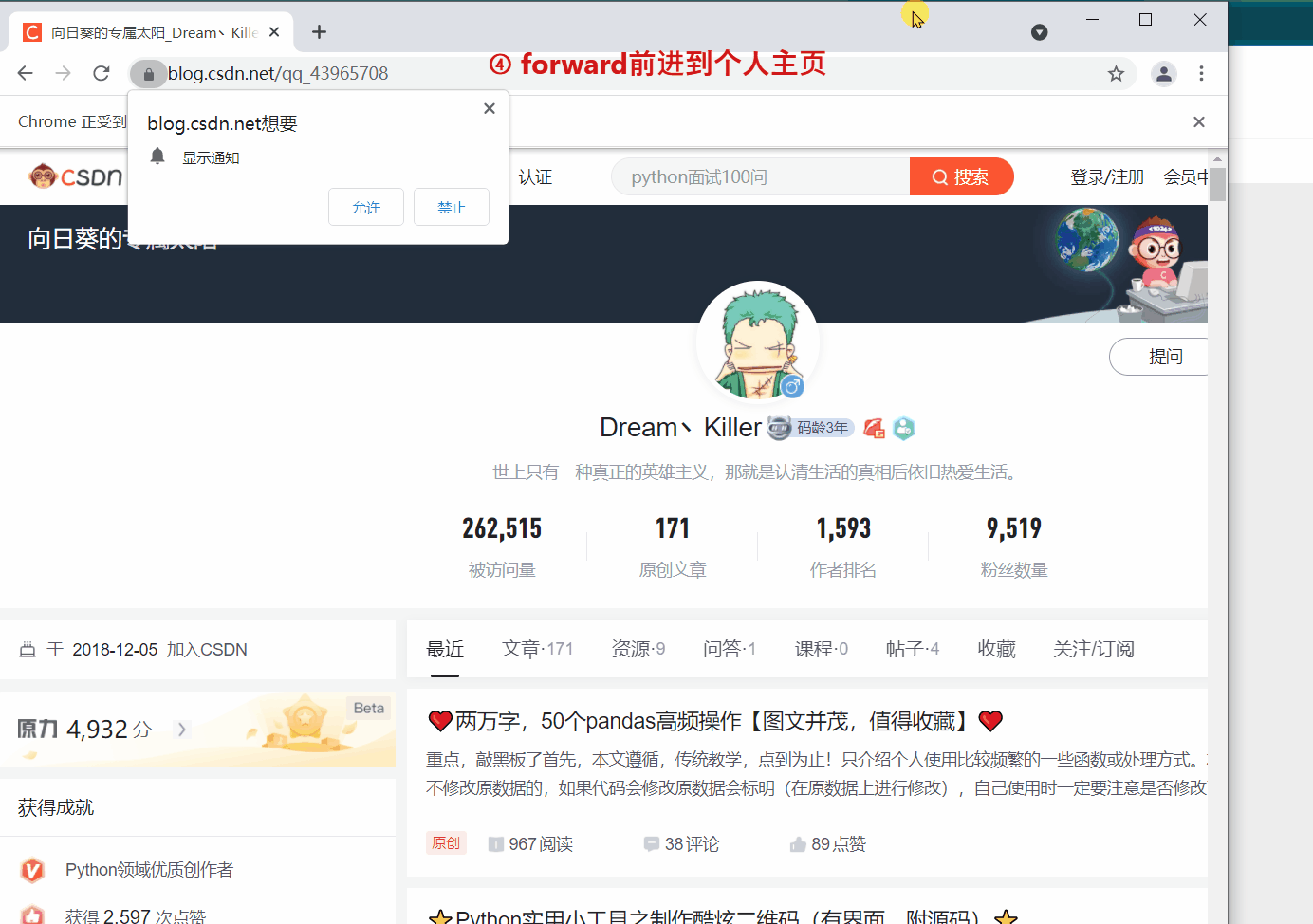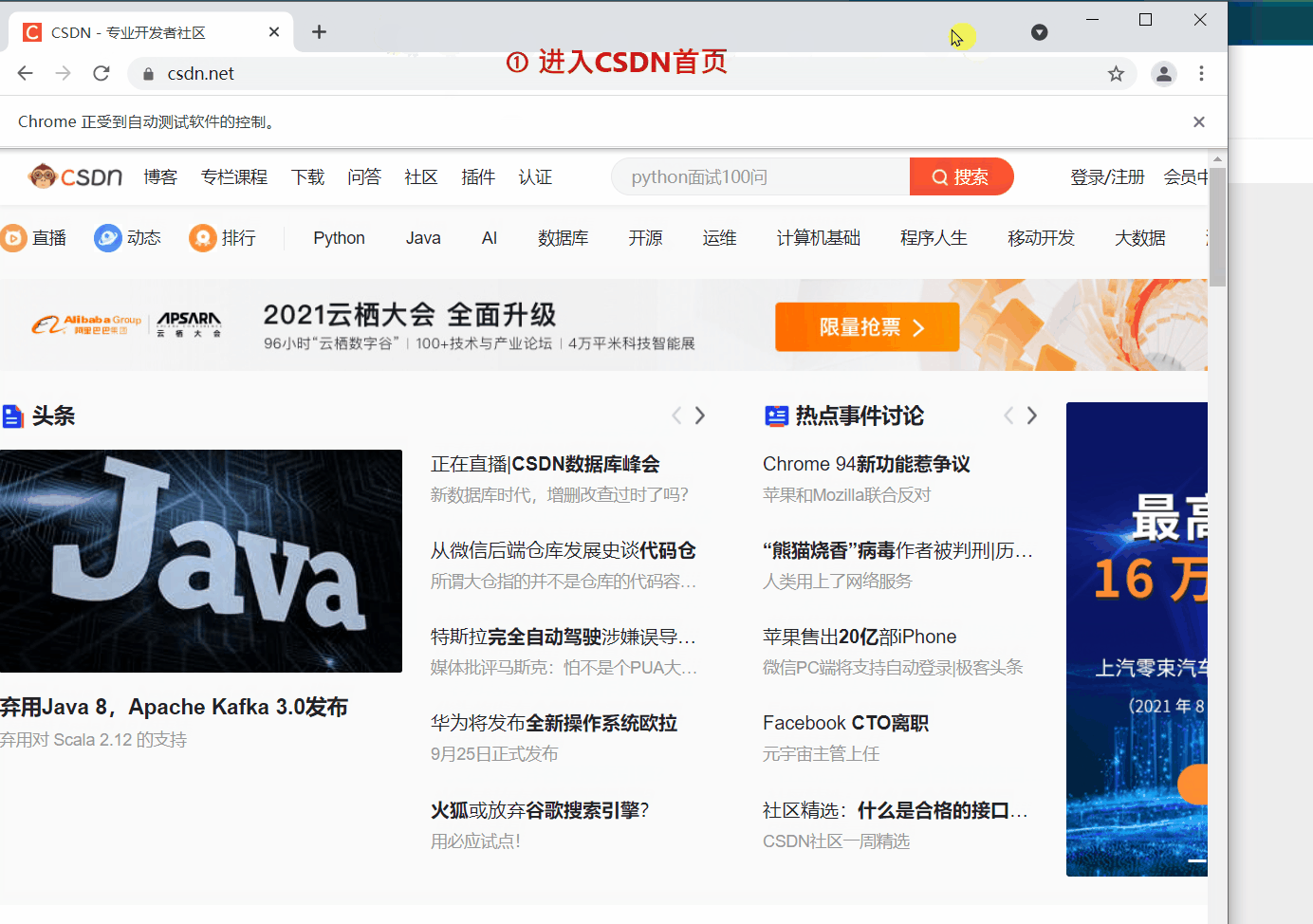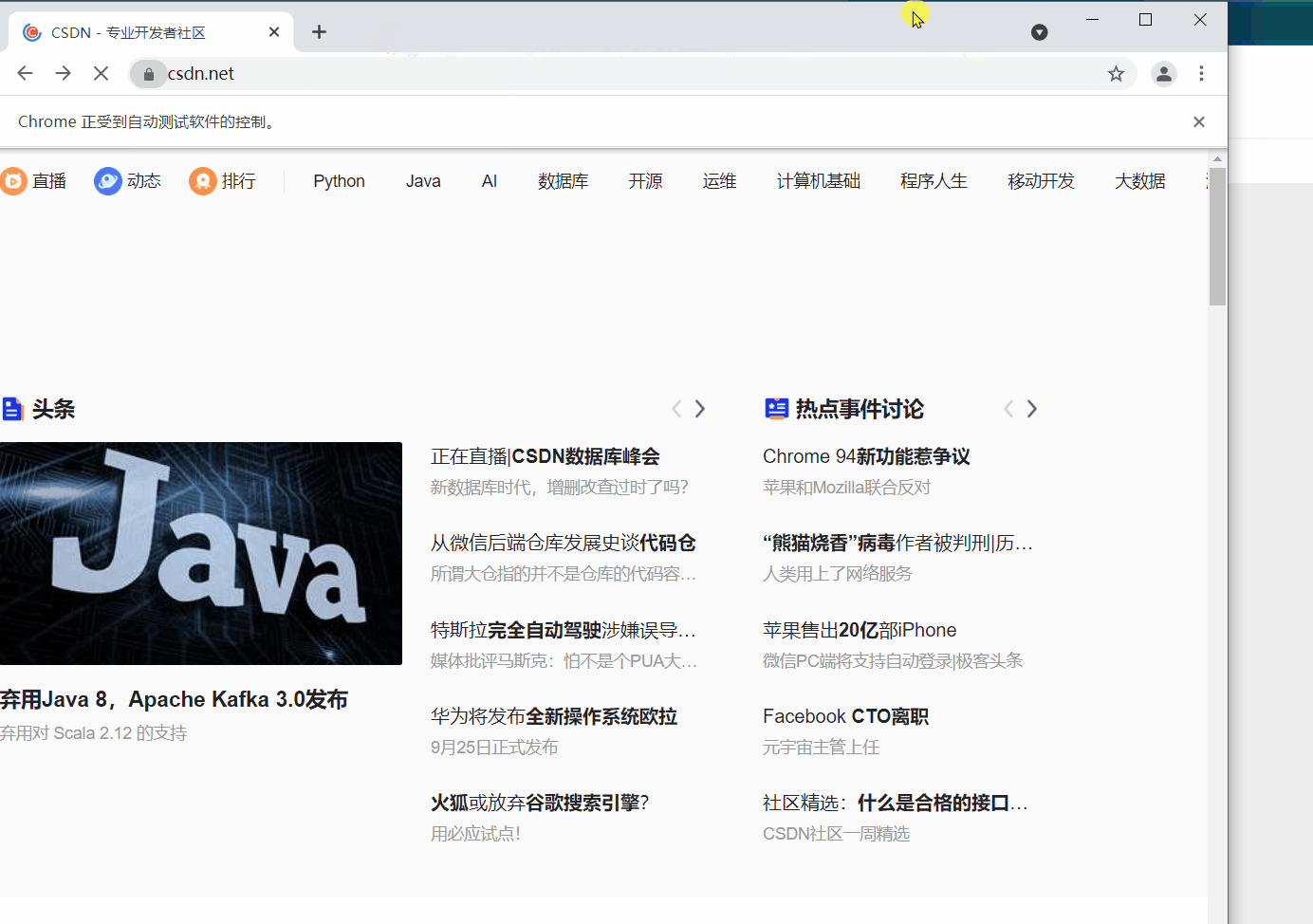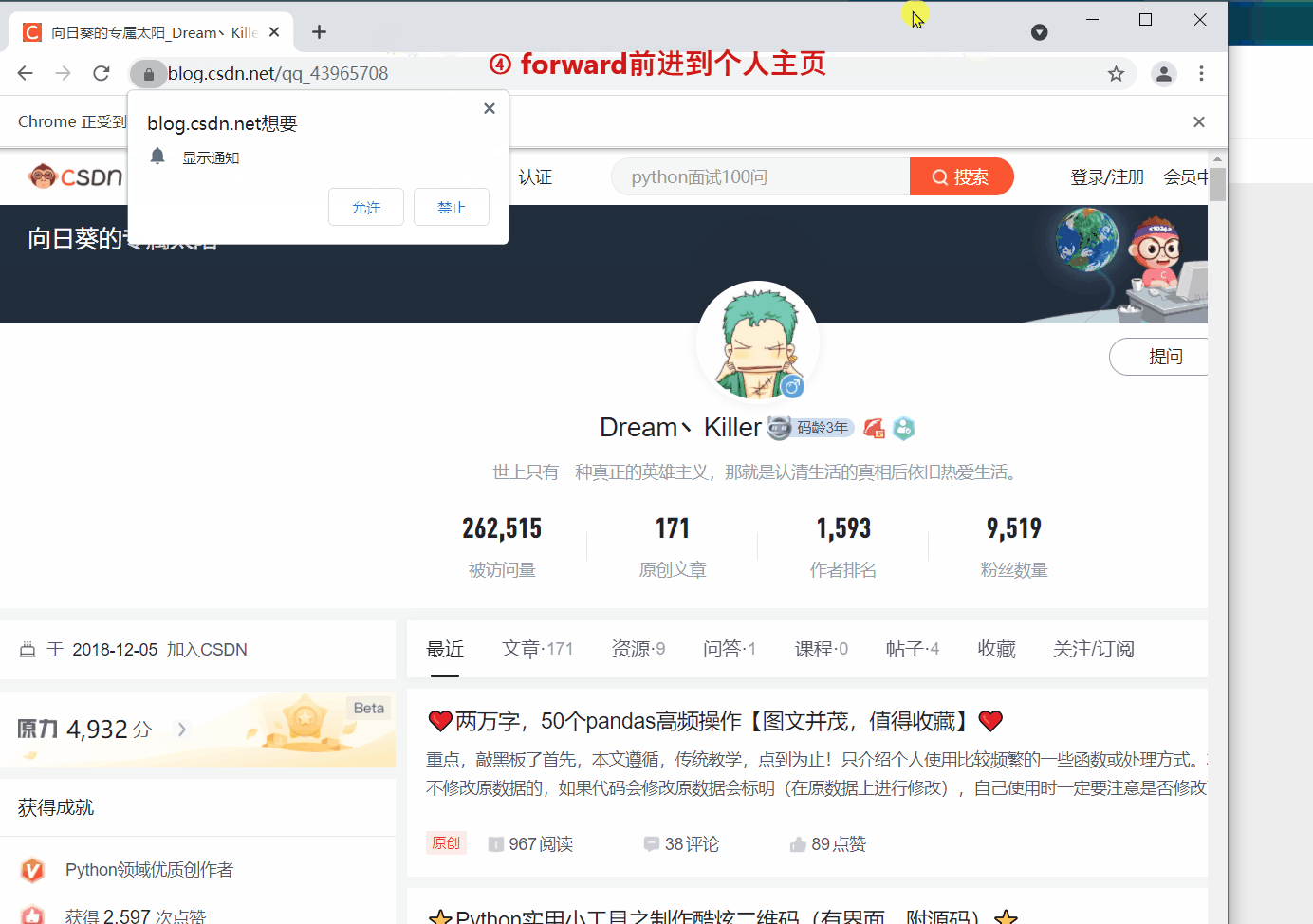
细心的读者会发现第二次 get() 打开新页面时,会在原来的页面打开,而不是在新标签中打开。如果想的话也可以在新的标签页中打开新的链接,但需要更改一下代码,执行 js 语句来打开新的标签。
# 在原页面打开
driver.get('https://blog.csdn.net/qq\_43965708')
# 新标签中打开
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化学习资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









