







再返过来思考 MQ 的所有应用场景,就不难理解 MQ 为什么适用了?因为这些应用场景无外乎都利用了上面两个特性。
举一个实际例子,比如说电商业务中最常见的「订单支付」场景:在订单支付成功后,需要更新订单状态、更新用户积分、通知商家有新订单、更新推荐系统中的用户画像等等。
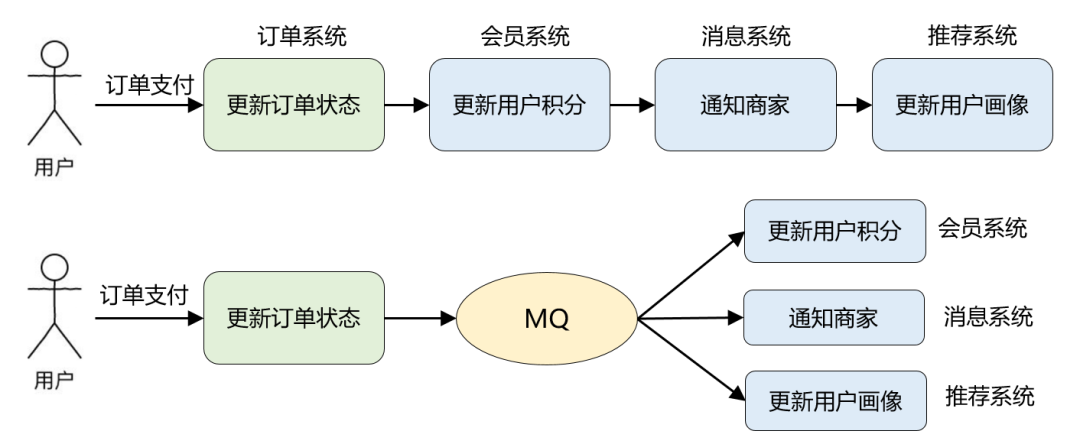
引入 MQ 后,订单支付现在只需要关注它最重要的流程:更新订单状态即可。其他不重要的事情全部交给 MQ 来通知。这便是 MQ 解决的最核心的问题:系统解耦。
改造前订单系统依赖 3 个外部系统,改造后仅仅依赖 MQ,而且后续业务再扩展(比如:营销系统打算针对支付用户奖励优惠券),也不涉及订单系统的修改,从而保证了核心流程的稳定性,降低了维护成本。
这个改造还带来了另外一个好处:因为 MQ 的引入,更新用户积分、通知商家、更新用户画像这些步骤全部变成了异步执行,能减少订单支付的整体耗时,提升订单系统的吞吐量。这便是 MQ 的另一个典型应用场景:异步通信。
除此以外,由于队列能转储消息,对于超出系统承载能力的场景,可以用 MQ 作为 “漏斗” 进行限流保护,即所谓的流量削峰。我们还可以利用队列本身的顺序性,来满足消息必须按顺序投递的场景;利用队列 + 定时任务来实现消息的延时消费 ……
MQ 其他的应用场景基本类似,都能回归到消息模型的特性上,找到它适用的原因,这里就不一一分析了。总之,就是建议大家多从复杂多变的实践场景再回归到理论层面进行思考和抽象,这样能吃得更透。
04 如何设计一个 MQ?
了解了上面这些理论知识以及应用场景后,下面我们再一起看下:到底如何设计一个 MQ?
4.1 MQ 的雏形
我们还是先从简单版的 MQ 入手,如果只是实现一个很粗糙的 MQ,完全不考虑生产环境的要求,该如何设计呢?
文章开头说过,任何 MQ 无外乎:一发一存一消费,这是 MQ 最核心的功能需求。另外,从技术维度来看 MQ 的通信模型,可以理解成:两次 RPC + 消息转储。
有了这些理解,我相信只要有一定的编程基础,不用 1 个小时就能写出一个 MQ 雏形:
1、直接利用成熟的 RPC 框架(Dubbo 或者 Thrift),实现两个接口:发消息和读消息。
2、消息放在本地内存中即可,数据结构可以用 JDK 自带的 ArrayBlockingQueue 。
4.2 写一个适用于生产环境的 MQ
当然,我们的目标绝不止于一个 MQ 雏形,而是希望实现一个可用于生产环境的消息中间件,那难度肯定就不是一个量级了,具体我们该如何下手呢?
1、先把握这个问题的关键点
假如我们还是只考虑最基础的功能:发消息、存消息、消费消息(支持发布-订阅模式)。
那在生产环境中,这些基础功能将面临哪些挑战呢?我们能很快想到下面这些:
1、高并发场景下,如何保证收发消息的性能?
2、如何保证消息服务的高可用和高可靠?
3、如何保证服务是可以水平任意扩展的?
4、如何保证消息存储也是水平可扩展的?
5、各种元数据(比如集群中的各个节点、主题、消费关系等)如何管理,需不需要考虑数据的一致性?
可见,高并发场景下的三高问题在你设计一个 MQ 时都会遇到,「如何满足高性能、高可靠等非功能性需求」才是这个问题的关键所在。
2、整体设计思路
先来看下整体架构,会涉及三类角色:

另外,将「一发一存一消费」这个核心流程进一步细化后,比较完整的数据流如下:
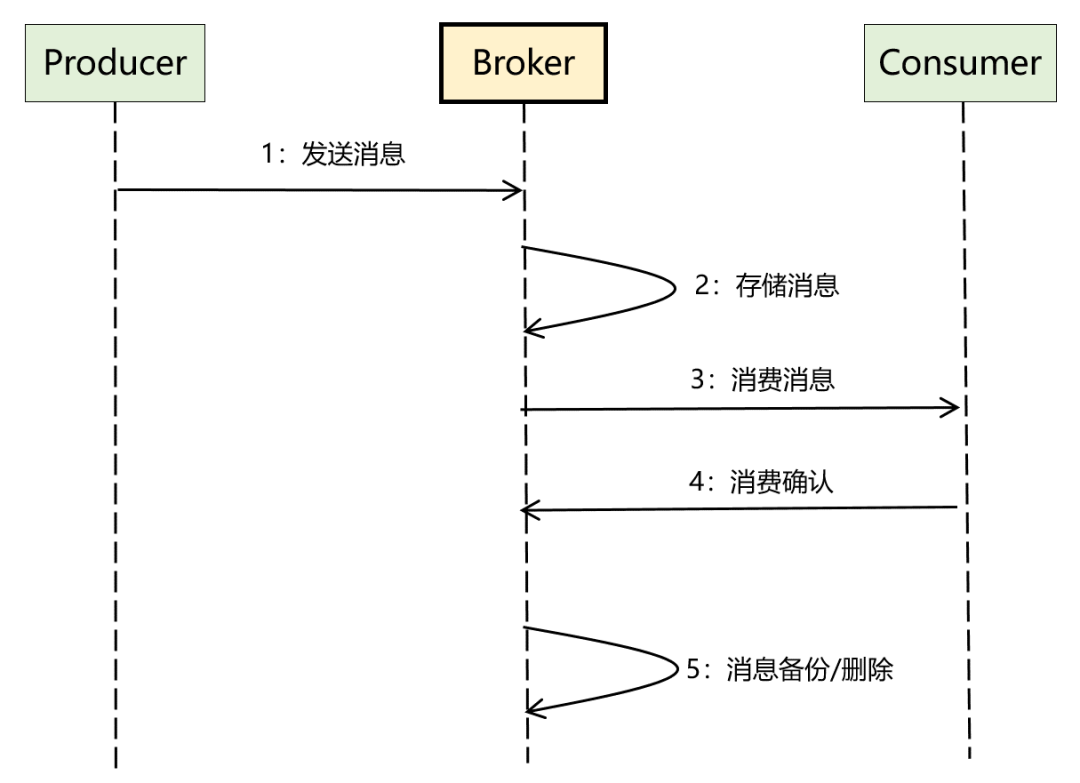
基于上面两个图,我们可以很快明确出 3 类角色的作用,分别如下:
1、Broker(服务端):MQ 中最核心的部分,是 MQ 的服务端,核心逻辑几乎全在这里,它为生产者和消费者提供 RPC 接口,负责消息的存储、备份和删除,以及消费关系的维护等。
2、Producer(生产者):MQ 的客户端之一,调用 Broker 提供的 RPC 接口发送消息。
3、Consumer(消费者):MQ 的另外一个客户端,调用 Broker 提供的 RPC 接口接收消息,同时完成消费确认。
3、详细设计
下面,再展开讨论下一些具体的技术难点和可行的解决方案。
难点1:RPC 通信
解决的是 Broker 与 Producer 以及 Consumer 之间的通信问题。如果不重复造轮子,直接利用成熟的 RPC 框架 Dubbo 或者 Thrift 实现即可,这样不需要考虑服务注册与发现、负载均衡、通信协议、序列化方式等一系列问题了。
当然,你也可以基于 Netty 来做底层通信,用 Zookeeper、Euraka 等来做注册中心,然后自定义一套新的通信协议(类似 Kafka),也可以基于 AMQP 这种标准化的 MQ 协议来做实现(类似 RabbitMQ)。对比直接用 RPC 框架,这种方案的定制化能力和优化空间更大。
难点2:高可用设计
高可用主要涉及两方面:Broker 服务的高可用、存储方案的高可用。可以拆开讨论。
Broker 服务的高可用,只需要保证 Broker 可水平扩展进行集群部署即可,进一步通过服务自动注册与发现、负载均衡、超时重试机制、发送和消费消息时的 ack 机制来保证。
存储方案的高可用有两个思路:1)参考 Kafka 的分区 + 多副本模式,但是需要考虑分布式场景下数据复制和一致性方案(类似 Zab、Raft等协议),并实现自动故障转移;2)还可以用主流的 DB、分布式文件系统、带持久化能力的 KV 系统,它们都有自己的高可用方案。
难点3:存储设计
消息的存储方案是 MQ 的核心部分,可靠性保证已经在高可用设计中谈过了,可靠性要求不高的话直接用内存或者分布式缓存也可以。这里重点说一下存储的高性能如何保证?这个问题的决定因素在于存储结构的设计。
目前主流的方案是:追加写日志文件(数据部分) + 索引文件的方式(很多主流的开源 MQ 都是这种方式),索引设计上可以考虑稠密索引或者稀疏索引,查找消息可以利用跳转表、二份查找等,还可以通过操作系统的页缓存、零拷贝等技术来提升磁盘文件的读写性能。
如果不追求很高的性能,也可以考虑现成的分布式文件系统、KV 存储或者数据库方案。
难点4:消费关系管理
为了支持发布-订阅的广播模式,Broker 需要知道每个主题都有哪些 Consumer 订阅了,基于这个关系进行消息投递。由于 Broker 是集群部署的,所以消费关系通常维护在公共存储上,可以基于 Zookeeper、Apollo 等配置中心来管理以及进行变更通知。
总结
在这里,由于面试中MySQL问的比较多,因此也就在此以MySQL为例为大家总结分享。但是你要学习的往往不止这一点,还有一些主流框架的使用,Spring源码的学习,Mybatis源码的学习等等都是需要掌握的,我也把这些知识点都整理起来了
**[CodeChina开源项目:【一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频】](
)**
点都整理起来了
**[CodeChina开源项目:【一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频】](
)**
[外链图片转存中…(img-rzjRqF39-1631189344816)]
















 428
428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









