






火山模型
火山模型是一种流行的查询执行模型,它在数据库管理系统中被广泛采用来执行SQL查询。模型通过结构化且模块化的方式来处理查询,该计算模型将关系代数中每一种操作抽象为一个 Operator,将整个 SQL 构建成一个 Operator 树,从根节点到叶子结点自上而下地递归调用 next() 函数。。火山模型的核心在于它的“迭代器接口”,每个操作符(如选择、投影、连接等)都是一个迭代器,可以产生(或使用)一行数据然后传递到下一个操作符。火山模型中,每个操作符实现四个基本函数:open()、next()、close()以及init()。open()用于初始化操作,例如为表扫描打开文件或为排序操作构建内存中的数据结构。next()函数被反复调用以产生新的输出行,直至没有更多数据可供处理。close()函数则负责清理操作,如关闭文件句柄或释放内存。
火山模型的优点在于:简单,每个 Operator 可以单独抽象实现、不需要关心其他 Operator 的逻辑。缺点是每次都是计算一个 tuple,这样会造成多次调用 next ,也就是造成大量的虚函数调用,这样会造成 CPU 的利用率不高。
总体架构
如下图所示,indexscan位于下图的行执行算子模块。执行器通过判断sql语句是非DDL语句进入executor模块,查看查询描述符的planstate判断是否是向量化算子。如果不是,使用行执行算子方法初始化。
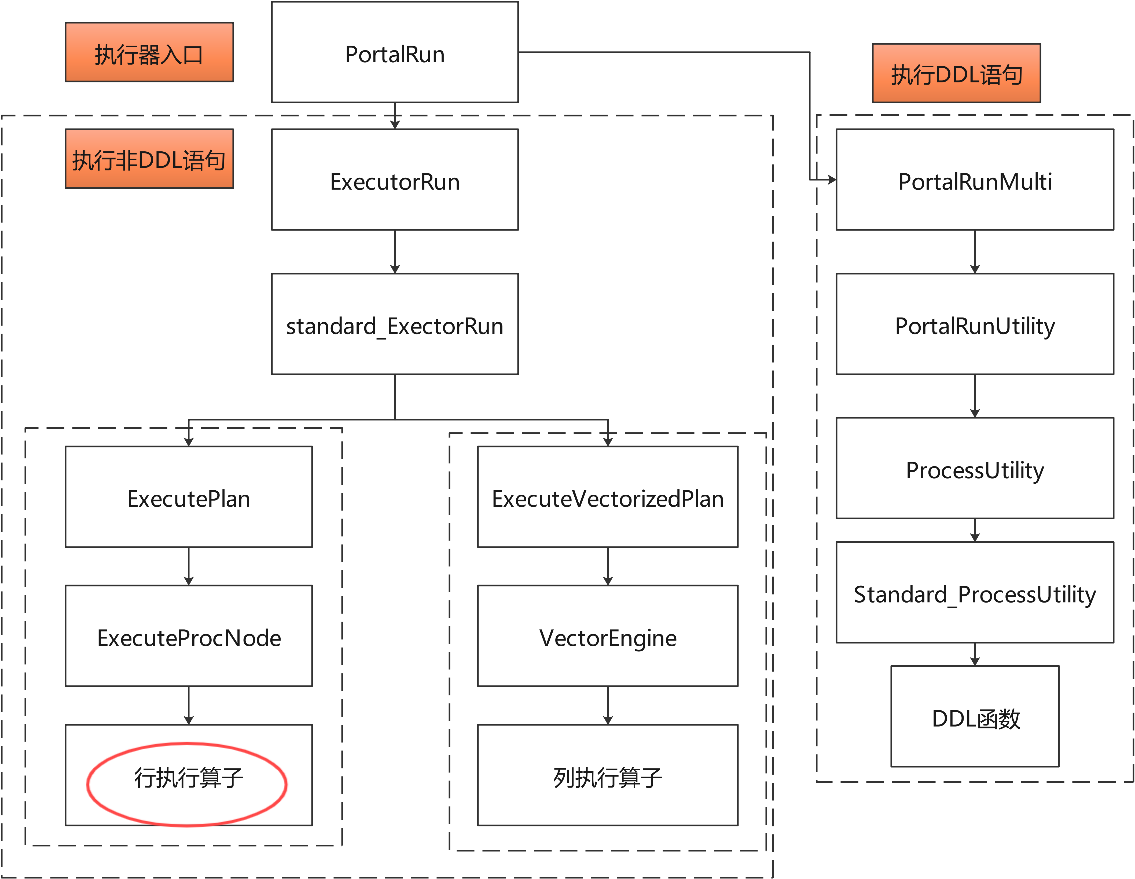
执行了行执行算子之后,就进入了存储引擎。indexsan最后返回了元组槽数据,再通过下图的行存表接口进行页面存储访问。

南北向接口
整个执行器模块的总函数是ExecutorRun方法,接收了queryDesc查询描述符。这个描述符里面存储了执行器的执行计划planstate。
在opengauss的执行计划中,ExecInitNode 和 ExecProcNode 是两个非常关键的函数,它们负责初始化和执行执行计划中的各个节点。
ExecProcNode 是一个函数指针,指向的函数用于执行一个计划节点并获取其输出元组。例如index scan的对应函数就是ExecIndexScan,index only scan对应ExecIndexOnlyScan。对于 ExecProcNode,其北向接口是上层节点如何获取当前节点的输出元组描述符。调用 ExecProcNode 时,上层节点会期望获取一个输出元组或指示处理结束。在执行过程中,ExecProcNode 会调用子节点的 ExecProcNode 来获取输入元组。
ExecInitNode 函数用于初始化一个计划节点。这个函数会根据节点的类型调用相应的初始化函数。初始化的主要任务包括:
- 分配和初始化节点的状态结构。
- 初始化表达式和子节点。
- 分配必要的内存资源。
对于 ExecInitNode 来说,其北向接口主要是调用此节点的初始化函数,并获取节点状态结构以备后续执行使用。ExecInitNode 在初始化时会递归地初始化其子节点。例如,对于一个联合节点(Join Node),它会初始化左子节点和右子节点。南向接口就是table access method方法,位于storage模块中,根据元组访问表内存。最终,处理后的元组将被返回给客户端,作为查询结果的一部分。
当用户发出 CREATE INDEX 命令时,opengauss首先解析该命令,生成相应的查询树。解析后的查询树经过查询重写和规划阶段,生成一个创建索引的计划。这个计划由 PlanState 和相关的数据结构管理。
在创建索引的过程中,以下是一些主要的数据结构和组件:
RelationData:表示要创建索引的表的元数据,包括表的描述符、锁信息等。
IndexInfo:存储索引的关键信息,包括索引键、表达式和谓词等。
IndexBuildResult:存储索引构建的结果,包括索引中的元组数量等信息。
Opengauss 在创建索引时,会扫描表中的所有数据,并使用特定的buildState结构体将数据插入到索引中。不同类型的索引(如 B-Tree、Hash、GIN、GiST)有不同的实现方式和相关数据结构。
执行算子
执行算子模块包含多种计划执行算子,算子类型如表所示,是计划执行的独立单元,用于实现具体的计划动作。执行计划包含4类算子,分别是控制算子、扫描算子、物化算子和连接算子。这些算子统一使用节点(node)表示,具有统一的接口,执行流程采用递归模式。整体执行流程是:首先根据计划节点的类型初始化状态节点(函数名为“ExecInit+算子名”),然后再回调执行函数(函数名为“Exec+算子名”),最后是清理状态节点(函数名为“ExecEnd+算子名”)。
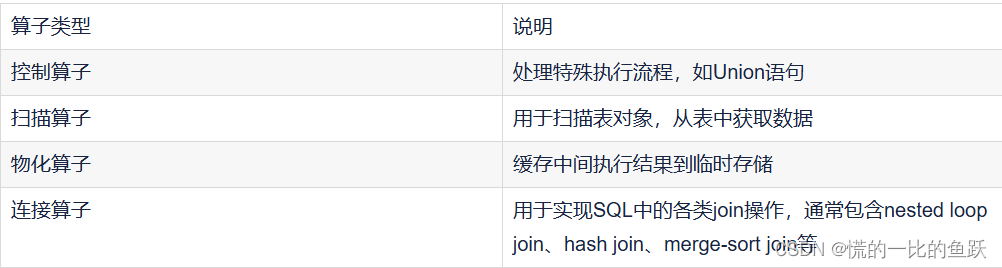
IndexScan 算子是扫描算子,是ExecInitNode的组成部分。如果过滤条件涉及索引,则查询计划对表的扫描使用 IndexScan 算子,利用索引加速元组获取。
IndexScan 算子执行索引扫描操作,它是通过遍历数据库表的索引来查找符合查询条件的数据行,而不是全表扫描。这可以大大加速查询操作,尤其是在大型表上。此外,IndexScan 算子接收一个或多个查询条件,通常是等值条件(例如,WHERE column = value),用于定位匹配条件的行。IndexScan 算子通常作为查询计划中的一部分出现,由查询优化器决定是否使用索引扫描来执行查询。优化器会考虑查询条件、索引类型、表大小等因素来选择最佳的执行计划。
扫描计划
opengauss在查询中对表的扫描计划大概有如下几种:
Seq Scan:按照表的记录的排列顺序从头到尾依次检索扫描,每次扫描要取到所有的记录。这也是最简单最基础的扫表方式。
Index Scan:先扫描一遍索引,从索引中找到符合要求的记录的位置(指针),再定位到表中具体的Page去取。
Bitmap Heap Scan: 一次性将满足条件的索引项全部取出,并在内存中进行排序, 然后根据取出的索引项访问表数据。
Index Only Scan:建立 index时,所包含的字段集合,囊括了我们查询语句中的字段,这样,提取出相应的index ,就不必再次提取数据块。
除此之外,openGauss实现了向量化执行引擎,达到算子级别的并行。也就是说在执行器火山模型基础上,一次处理一批数据,而不是一次一个元组。这样可以充分利用SIMD指令进行优化,达到指令级别并行。具体实现是CStoreIndexScan,用来扫描列存储数据。cstore表支持psort和cbtree两种索引。psort索引是一种局部排序聚簇索引。psort索引表的组织形式也是cstore表,该cstore表的字段包括索引键中的各个字段,再加上对应的TID字段。cbtree索引和行存储表的B-Tree索引在结构和使用方式上几乎完全一致。
索引扫描
在索引扫描中,索引访问方法(am:access method)负责恢复其已知匹配扫描键的所有元组的TID(元组ID)。访问方法不从索引的父表中实际获取这些元组,也不去确定它们是否通过扫描的可见性测试或其他条件。
扫描键是WHERE子句的内部表示形式,形式为index_key operator constant,其中index_key是索引的列之一,operator是与该索引列相关联的操作符。一个索引扫描有零个或多个扫描键,这些键被隐式地AND连接——返回的元组应满足所有指示的条件。
访问方法可以报告索引是有损的或者某个特定查询需要重新检查。这意味着索引扫描将返回所有通过扫描键的条目,可能还包括不通过的额外条目。然后,核心系统的索引扫描机制将再次应用索引条件到堆元组上,以验证它是否真的应该被选择。如果没有指定重新检查选项,则索引扫描必须准确返回匹配的条目集。
数据库由访问方法来找到并通过所有给定扫描键的条目。此外,系统将交接所有匹配索引键和操作符的WHERE子句,而不进行任何语义分析以确定它们是否冗余或矛盾。例如,在WHERE x > 4 AND x > 14中,x是一个b树索引列,b树amrescan函数必须意识到第一个扫描键是多余的,可以丢弃。
索引扫描操作步骤:
查找起点:根据查询条件,索引扫描首先在索引中找到满足条件的第一个条目。
遍历索引:从起点开始,索引扫描遍历索引中的条目,直到找到不满足条件的条目为止。
数据抓取:对于索引中每一个指向表中满足条件的行的引用,数据库系统会从表中抓取相应的行数据。
IndexScan算子是索引扫描算子,对应IndexScan计划节点,相关的代码源文件是nodeIndexScan.cpp文件。如果过滤条件涉及索引,查询计划对表的扫描使用IndexScan算子,利用索引加速元组获取。算子对应的主要函数如下图所示。
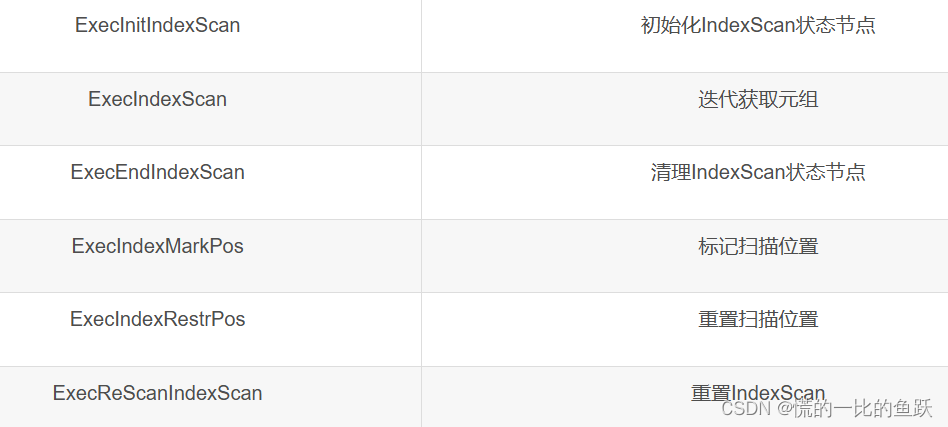
ExecInitIndexScan函数负责初始化IndexScan状态节点。主要执行流程如下。
1 创建IndexScanState节点。初始化子节点,初始化目标列表、索引过滤条件、原始过滤条件。
2 打开对应表、索引,构建索引扫描Key。
3.处理ORDER BY对应的Key。
4.启动索引扫描(返回索引扫描描述符IndexScanDesc)。
5. 把过滤Key传递给索引器。
ExecIndexScan函数负责迭代获取元组,通过回调函数的形式调用IndexNext函数获取元组。IndexNext函数首先按照扫描Key获取元组,然后再执行表达式indexqualorig判断元组是否满足过滤条件,如果不满足则需要继续获取。
ExecEndIndexScan函数负责清理IndexScanState节点。主要执行流程如下。
1.清理元组占用的槽位,关闭索引扫描描述子。
2.关闭索引(如果是分区表则需要关闭分区索引及分区映射)和表。
详细阅读,见https://github.com/yhyhdyb/opengaussIndexScan
数据结构
- IndexScan node
存储了索引信息,索引谓词,扫描方向,索引扫描时通过node节点和执行状态信息就能得到查询的元组信息。
IndexScan结构体的第一个字段是Scan结构体,这使得可以将它们的指针直接强制转换为Scan类型。
Scan结构体是所有扫描节点的“父类”,存储了是否是分区表,分区剪枝信息,哈希表桶信息。Scan结构体的第一个字段是Plan结构体,这使得可以将它们的指针直接强制转换为Plan类型。
Plan结构体是所有执行计划节点的“父类”,存储了id、父节点id、子节点、谓词列表、分区信息、布隆过滤器,甚至还有用于机器学习预测的时间状态信息。
2.PlanState
执行器状态节点,indexscan会继承这个结构体为IndexScanState。
PlanState存储了执行计划和状态,它还有左子树和右子树。
在索引扫描过程中,PlanState 负责管理相关资源和上下文,包括:
内存管理:管理和分配执行过程中需要的内存上下文,确保索引扫描过程中的内存使用是受控的。
缓存管理:管理和使用缓存来优化索引扫描的性能,减少重复的磁盘访问。
在索引扫描结束时,ExecEndIndexScan函数会被调用来清理和释放资源。这包括:
释放索引扫描过程中使用的内存上下文IndexScanState。
关闭索引扫描描述符(IndexScanDesc)。
3.RelationData
OID(对象标识符)是用于唯一标识数据库对象(如表、索引、视图等)的标识符。每个对象在创建时都会被分配一个唯一的 OID。
在opengauss中,表的主要数据结构是RelationData
RelationData封装了表的元数据,如物理存储信息、元数据信息、索引信息。
同时也存储了table访问方法接口am,进行内存的访问。
4.TupleTableSlot
TupleTableSlot是opengauss内部用于查询执行过程中的一种数据结构。它是用来暂存元组(tuple)的一个容器或缓冲区。TupleTableSlot的主要作用是在查询计划的执行过程中,在各个执行节点之间传递元组。
在索引扫描过程中,迭代函数遍历元组的时候传递的就是该结构体。
5.scan keys
scan key 主要用于在扫描表或索引时过滤符合条件的元组。scan key 指定了在扫描过程中需要应用的条件,用于优化和加速查询。
Scan key由ScanKeyData结构体封装,里面有涉及列编号,涉及操作符,比较内容数据。
Scan key会被存储在IndexScanStae里面。
6.Tuple
Tuple是数据库表中的记录。不同类型的表和索引使用不同的元组表示方式。
1.Heap tuple 是最基本的元组类型,用于存储在堆表(heap table)中的记录。每个堆元组包含实际的数据行以及一些管理信息。
结构:
HeapTupleHeaderData:包含元组的元数据,如事务ID(Transaction ID),元组的状态(如插入、删除、更新)等。
数据列:存储实际的数据值。
2. Index Tuple
Index tuple 是用于存储在索引中的记录。索引元组的结构与堆元组不同,因为它们主要用于加速数据检索,而不是存储完整的数据行。
结构:
IndexTupleData:包含元组的元数据。
索引键:存储用于索引的键值。
TID:指向对应的堆元组的位置。
管理信息:
t_tid:指向包含该索引元组的堆元组的位置,形式为 (block number, tuple offset)。















 402
402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









