







RabbitMQ学习笔记
1. 消息中间件的对比
-
kafka:基于Pull 的模式处理消息消费,适合大量数据的互联网服务,适用于大型公司
-
RocketMQ:可靠性很高,基本可以做到消息0丢失,天生为金融互联网而生
-
RabbitMQ:中小型公司首选,性能好,吞吐量到万级,社区活跃度比较高
2. RabbitMQ四大核心概念
- 生产者、交换机、队列、消费者
3. 消息应答机制
为了保证消息在发送过程中不丢失,rabbitmq引入了消息应答机制::消费者在接收到消息并且处理该消息之后,告诉 rabbitmq 它已经处理了,rabbitmq 可以把该消息删除了。
- 消息应答机制就是channel.basicAck () 方法,当消费者收到消息,在回调函数中调用这个方法告诉生产者收到了消息,替换原来的自动应答(autoAck = true)
4. RabbitMQ持久化
如果RabbitMQ 服务突然停掉,为了保证生产者发送的消息不丢失,需要将队列和消息都标记为持久化
-
队列初始化:在声明队列的时候,把第二个参数:durable置为true即可

-
消息持久化:(持久性保证并不强,更强的需要用到发布确认)
生产者发送消息时,添加MessageProperties.PERSISTENT_TEXT_PLAIN属性实现

5. 消息分发:
轮训分发转变成不公平发,设置参数 channel.basicQos(1);
转变成预取值:定义通道上允许的未确认消息的最大数量
6. 发布确认
-
原理:生产者将信道设置成confirm模式(异步),所有在该信道发布的消息都会有一个唯一的ID,消息到达匹配的队列之后,会发送确认信息返回生产者
-
开启发布确认:

- 单个确认发布(同步方案):每个消息都要返回确认信息后,才发送后续消息,否则阻塞直到超出指定时间抛出异常,所以速度最慢
- 批量确认发布(同步方案):跟单个不一样的是,发送一部分消息,才批量确认发布是否成功,也是同步确认,会阻塞,速度稍快一点,但是无法定位到错误的位置
- 异步确认发布:实现比较复杂,是最好的方案,效率也最高,就是把未确认的消息放入一个集合中,返回给发布者,这样就可以查看到出错的位置
7. 交换机
-
Exchange类型:直接(direct),主题(topic),标题(header),扇出(fanout)
-
FanoutExchange:就是广播,将接收到的消息广播到所有队列,使用这个类型的交换机也就不需要Routingkey,实践如下
/** * 在消费者代码中--- * 生成一个临时的队列 队列的名称是随机的 * 当消费者断开和该队列的连接时 队列自动删除 */ channel.exchangeDeclare(EXCHANGE_NAME, "fanout");//声明交换机+类型 String queueName = channel.queueDeclare().getQueue(); //把该临时队列绑定我们的 exchange 其中 routingkey(也称之为 binding key)为空字符串 channel.queueBind(queueName, EXCHANGE_NAME, ""); -
DirectExchange:消息只去到它绑定的 routingKey 队列中去。
–主要就是比扇出类型多填入Routingkey用于绑定队列
-
TopicExchange:Routingkey需要满足一定的要求,是一个 单词列表,用 . 分来
规则:

-
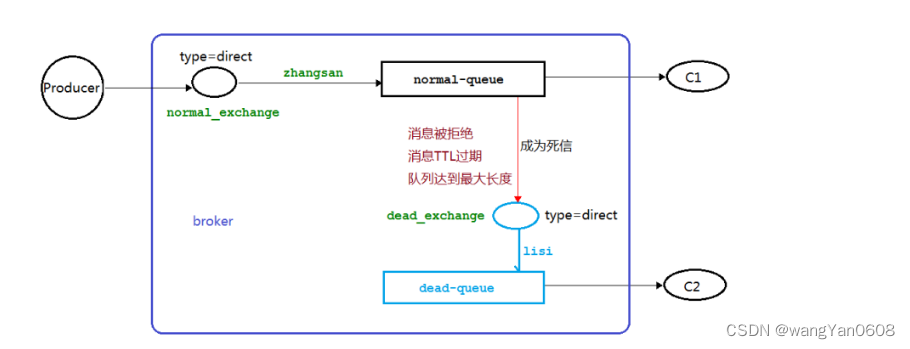
8. 死信队列
解释:由于特定的原因导致 queue 中的某些消息无法被消费,例如下单成功后在指定时间未支付,将进入死信队列
1. 死信的来源
- 消息TTL过期
- 队列达到最大长度(满了)
- 消息被拒绝
2. 死信的框架图
8. 延迟队列
-
概念
简单来说,延时队列就是用来存放需要在指定时间被处理的 元素的队列
-
普通的延迟队列会出现这样的问题:RabbitMQ只会检测队列中的第一个消息是否过期,如果过期丢入死信队列,但如果第一个消息延迟时间很长,而第二个短的也只能等第一个执行完成之后才被执行,不合理,解决:
- 企业中一般用Rabbitmq 插件实现延迟队列,解决延迟消息在队列中堆积(原理:不会将楚然如的消息直接放入队列中排队,而是放入一个表中,到达投递时间在执行)
9. 发布确认高级
1.确认机制方案
(交换机收到消息后,直接返回确认消息,如果不可路由,会被丢弃,生产者不知道)
-
配置文件中添加配置,发布消息成功到交换器后会触发回调方法
spring.rabbitmq.publisher-confirm-type=correlated
-
创建回调接口类,用于回调
-
生产者注入这个接口类
-
这样当交换机成功转发给队列后会给生产者发送确认信息,失败的则会被丢弃,
2. 回退消息方案
(当消息无法路由的时候的回调方法*,告诉生产者原因)
- 在回调接口实现类中增加对应的方法,在生产者代码中配置
3. 备份交换机
(前面两种方案的进化,出问题的消息不返回生产者,而是进入备份交换机)
当交换机接收到一条不可路由消息时,将会把这条消息转发到备份交换机中,由备份交换机来进行转发和处理,这样就能把所有消息都投递到与其绑定的队列中,然后我们在备份交换机下绑定一个队列,这样所有那些原交换机无法被路由的消息,就会都 进入这个队列了。
10.幂等性
1. 概念:
用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用。就是由于一些故障的发生,消费者方可能会出现重复消费情况
2. 最佳解决:
问题最佳解决方案是用redis的原子性,setnx,天然具有原子性,从而实现不重复消费
11.优先级队列
1. 概念:
例如同时向队列中发送订单请求,大客户的订单设置较高的优先级,先处理优先级高的消息
2.队列的两种模式
- 惰性队列:惰性队列会尽可能的将消息存入磁盘中,而在消费者消费到相应的消息时才会被加载到内存中
- 默认队列:当生产者将消息发送到 RabbitMQ 的时候,队列中的消息会尽可能的存储在内存之中,这样可以更加快速的将消息发送给消费者
12.RabbitMQ集群
操作顺序:
-
搭建、配置RabbitMQ集群
-
利用镜像机制:可以将队列镜像到集群中的其他 Broker 节点之上,如果集群中
的一个节点失效了,队列能自动地切换到镜像中的另一个节点上以保证服务的可用性
原来是单机rabbitmq主要是将队列+消息持久化,来保证消息不丢失,但是还是存在问题,搭建集群+镜像机制可以将队列和消息存放在集群中,当一个单机出现问题,可以偏移到备份机来获取数据,从而保证消息不丢失
13.Haproxy+Keepalive 实现高可用负载均衡
14.Federation Exchange+Federation Queue
(联邦交换机+联邦队列)
就是使用上下游配置,从上游获取消息以满足下游的需求















 353
353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









