







如何设计高效的数据库索引策略?
数据库索引是提升查询性能的核心工具,但不当使用会导致存储开销增加、写入性能下降等问题。以下从多个维度详细解析高效索引设计策略:
一、索引类型选择与适用场景
- B树/B+树索引
- 适用场景:范围查询(如
BETWEEN、>)、等值查询(WHERE id=38)、排序(ORDER BY)和分组(GROUP BY)。 - 优势:平衡树结构减少磁盘I/O,支持高基数列(唯一值多)的高效检索。
- 数据库差异:
- 适用场景:范围查询(如
- MySQL InnoDB默认使用B+树,主键即聚簇索引,决定数据物理存储顺序。
- PostgreSQL的B树索引支持多列复合索引和覆盖查询。
-
哈希索引
- 适用场景:仅精确等值查询(如
WHERE user_id=123)。 - 限制:不支持范围查询、排序,内存数据库(如Redis)性能更优。
- 适用场景:仅精确等值查询(如
-
位图索引
- 适用场景:低基数列(如性别、状态字段),数据仓库中的OLAP场景。
- 优势:通过位图压缩减少存储,适合多条件组合查询。
-
全文索引
- 适用场景:文本模糊匹配(如
LIKE "%keyword%")、搜索引擎。 - 实现差异:MySQL使用倒排索引,PostgreSQL支持GIN/GiST索引。
- 适用场景:文本模糊匹配(如
-
复合索引
- 设计原则:遵循最左前缀原则(如索引
(a,b,c)仅支持a、a+b、a+b+c查询)。 - 优化技巧:将高选择性列放在左侧,范围查询列置于末尾。
- 设计原则:遵循最左前缀原则(如索引
二、影响索引效率的关键因素
-
查询模式
- 高频查询字段:优先为
WHERE、JOIN、ORDER BY涉及的列建索引。 - 覆盖索引:索引包含查询所需全部字段,避免回表(如
SELECT a,b FROM table WHERE a=1,索引(a,b))。
- 高频查询字段:优先为
-
数据分布
- 高选择性原则:唯一值比例高的列(如用户ID)更适合索引。
- 低基数列优化:使用位图索引或结合高基数列创建复合索引。
-
更新频率
- 写入开销:频繁更新的表需谨慎添加索引,避免锁冲突和碎片化。
- 维护策略:定期重建碎片化索引(如MySQL的
OPTIMIZE TABLE)。
三、索引设计最佳实践
-
索引列选择
- 必选场景:主键、唯一约束、外键。
- 避免冗余:删除未使用的索引,减少存储和写入开销。
-
复合索引设计
- 顺序优化:按查询条件频率和选择性排序(如
(user_id, create_time))。 - 覆盖查询:包含
SELECT子句中的字段,减少回表次数。
- 顺序优化:按查询条件频率和选择性排序(如
-
特殊场景处理
- 函数/表达式:使用函数索引(如Oracle的
CREATE INDEX idx ON table (UPPER(name)))。 - 隐式类型转换:确保查询条件与索引列类型一致(如字符串字段避免用数字查询)。
- 函数/表达式:使用函数索引(如Oracle的
四、常见设计错误与解决方案
| 错误类型 | 示例 | 解决方案 |
|---|---|---|
| 对索引列运算 | WHERE id+1=10 | 改写为WHERE id=9 |
前导通配符LIKE | WHERE name LIKE '%John' | 改用后缀匹配或全文索引 |
| 复合索引未遵循最左前缀 | 索引(a,b,c),查询WHERE b=1 | 调整索引顺序或添加a列条件 |
| 数据分布不均 | 性别字段(男/女)建单列索引 | 改用位图索引或与高基数列组合 |
| 范围查询后索引失效 | 索引(a,b),查询WHERE a>1 AND b=2 | 拆分查询或调整索引顺序为(b,a) |
五、数据库系统差异与优化
-
MySQL
- 聚簇索引:主键决定数据物理存储,建议使用自增主键减少页分裂。
- 全文检索:使用
FULLTEXT索引,结合MATCH AGAINST语法。
-
PostgreSQL
- 多索引支持:GIN索引适合JSONB字段,BRIN索引优化时间范围查询。
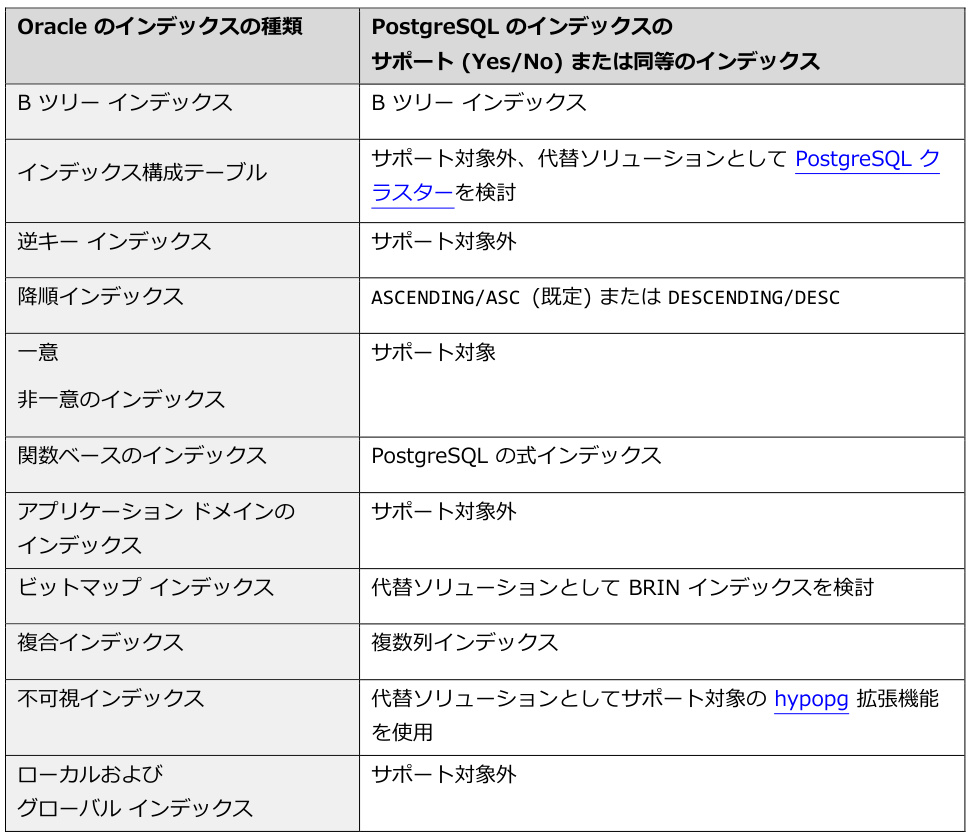
- 部分索引:仅索引满足条件的行(如
CREATE INDEX ON orders (status) WHERE status='pending')。
- 多索引支持:GIN索引适合JSONB字段,BRIN索引优化时间范围查询。
-
Oracle
- 位图索引:数据仓库中低基数列首选。
- 反向索引:优化并行插入场景(如
CREATE INDEX idx ON table (id) REVERSE)。
六、维护与监控策略
-
定期维护
- 重建碎片化索引(如MySQL的
ALTER TABLE REBUILD)。 - 更新统计信息(如PostgreSQL的
ANALYZE)。
- 重建碎片化索引(如MySQL的
-
性能监控
- 使用
EXPLAIN分析执行计划,确认索引使用情况。 - 监控慢查询日志,识别未走索引的SQL。
- 使用
结论
高效索引设计需综合业务需求、数据特性和数据库类型:
- 选择性原则:优先为高基数列建索引。
- 覆盖与复合:通过复合索引减少回表,覆盖高频查询。
- 权衡读写:避免过度索引导致写入性能下降。
- 动态调整:根据数据分布变化定期优化索引结构。
通过科学设计和持续优化,索引可使查询性能提升数倍至数十倍(如某案例从850ms优化至35ms),成为数据库高效运行的核心保障。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











