







CAP定理及其对数据库选型的影响解析
一、CAP定理的核心内涵与历史背景
CAP定理是分布式系统设计的核心理论,由Eric Brewer在2000年提出,后由Seth Gilbert和Nancy Lynch于2002年通过数学证明正式确立。其核心观点为:在分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition Tolerance)三者不可兼得,必须进行权衡。这一理论为理解分布式系统的设计限制提供了基础框架。
二、CAP三要素的详细定义
-
一致性(Consistency)
所有节点在同一时刻对数据的访问结果完全一致,即任何读操作都能获取最新写入的数据。例如,银行转账操作需确保所有节点同时更新余额,避免数据冲突。 -
可用性(Availability)
系统需在合理时间内响应所有请求(无论成功或失败),即使部分节点故障也不影响整体服务。例如,电商平台需保证用户在高并发场景下仍能正常浏览商品。 -
分区容错性(Partition Tolerance)
系统在网络分区(节点间通信中断)时仍能继续运行,不因部分节点失联而崩溃。例如,跨国分布式数据库需容忍不同地区间的网络延迟或中断。
三、CAP定理的权衡机制与系统分类
根据CAP定理,分布式系统需在三者中选择两项,形成以下三种模式:
-
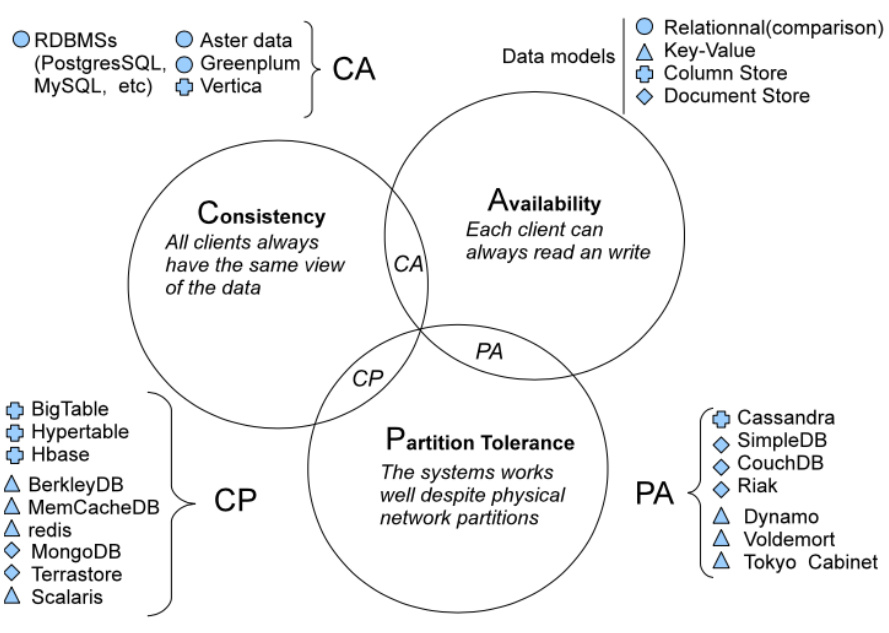
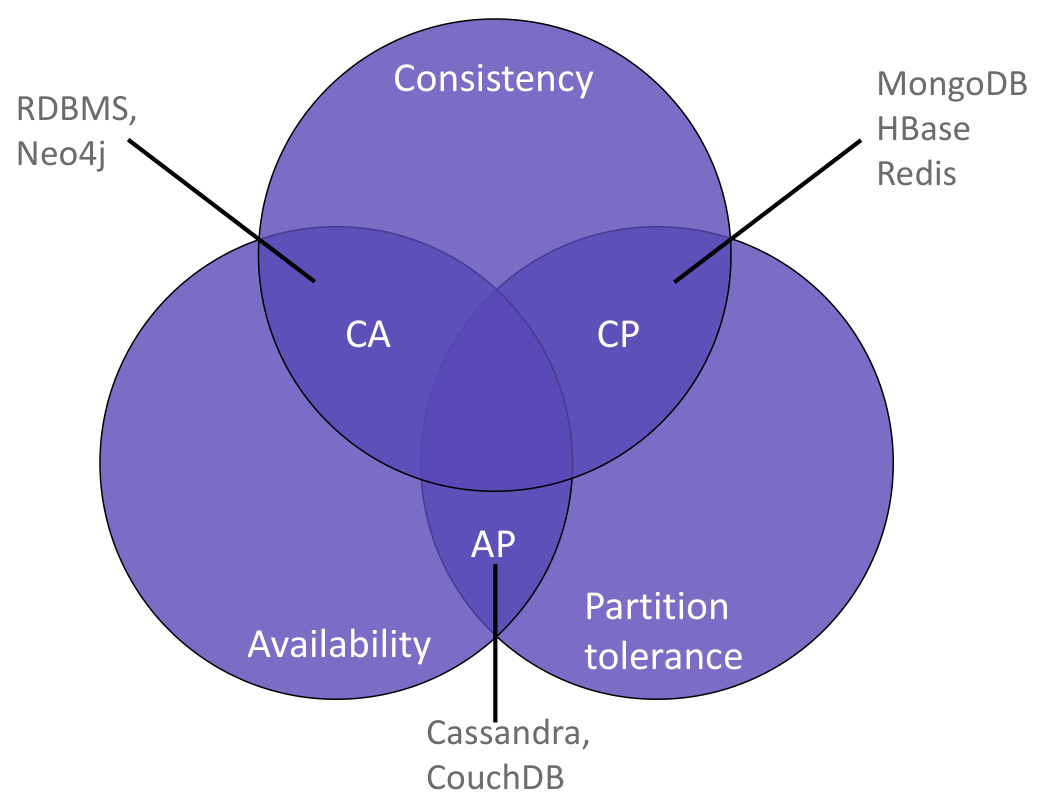
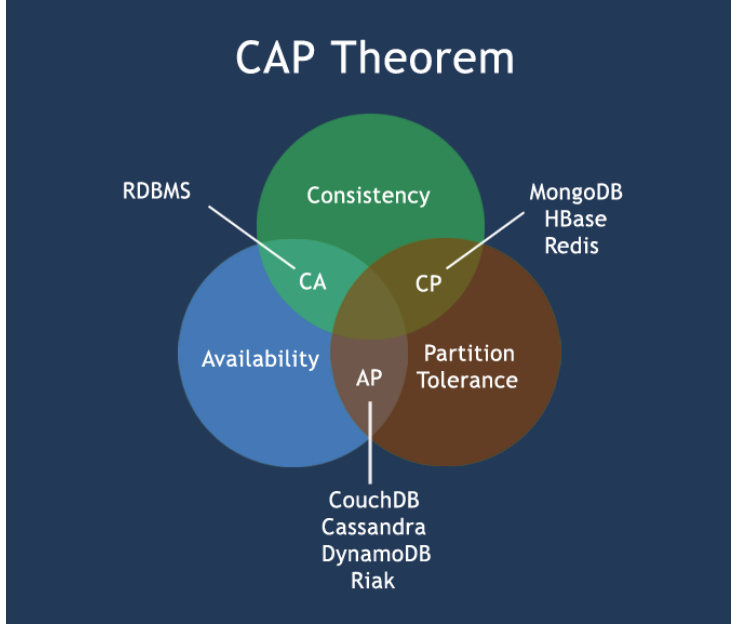
CA模式(Consistency + Availability)
- 特点:牺牲分区容错性,适用于单数据中心或网络稳定的场景。
- 典型系统:传统关系型数据库(如MySQL、PostgreSQL)。
- 局限:扩展性差,无法应对网络分区。
2.CP模式(Consistency + Partition Tolerance)
- 特点:在网络分区时牺牲可用性以保持强一致性。
- 典型系统:MongoDB(通过Write Concern配置)、HBase、Redis。
- 适用场景:金融交易、库存管理等对数据一致性要求极高的领域。
3.AP模式(Availability + Partition Tolerance)
- 特点:在网络分区时允许短暂的数据不一致,通过最终一致性实现高可用。
- 典型系统:Cassandra、CouchDB、DynamoDB。
- 适用场景:社交媒体、物联网等需要高吞吐和容错的场景。
四、CAP定理对数据库选型的影响
-
关系型数据库(SQL)与NoSQL的定位差异
- SQL数据库:通常属于CA模式,通过ACID事务保证强一致性,但扩展性受限。例如,MySQL在单机环境下性能优异,但分布式部署困难。
- NoSQL数据库:根据CAP设计倾向分为CP或AP类型,通过牺牲部分特性实现高扩展性。例如,Cassandra(AP)通过无主复制机制支持跨区域部署,而HBase(CP)通过强一致性协议保障数据准确。
-
实际选型中的权衡维度
- 业务需求:金融系统需优先选择CP模式,而实时性要求不高的场景可选AP模式。
- 网络环境:跨地域部署需优先分区容错性(P),本地集群可侧重CA。
- 一致性模型:最终一致性(BASE理论)可弥补AP系统的不足,例如Cassandra通过反熵机制逐步同步数据。
-
典型案例分析
- 金融交易系统:选择CP型数据库(如HBase),在网络分区时拒绝写入以保证账务一致性,避免资金错误。
- 社交平台:选择AP型数据库(如Cassandra),允许用户点赞/评论数据短暂不一致,优先保障服务可用性。
- 物联网数据采集:采用AP型时序数据库(如InfluxDB),容忍设备断网时的数据延迟,通过批量同步恢复一致性。
五、CAP定理的争议与演进
-
理论局限性
- CAP定理被批评为过度简化,实际系统中三者并非完全互斥。例如,现代数据库(如Google Spanner)通过原子钟和TrueTime API实现“外部一致性”,在无分区时同时满足CA。
-
动态权衡的可能性
- 部分系统允许运行时动态调整CAP属性。例如,MongoDB可配置为强一致性(CP)或最终一致性(AP)。
- 多模型数据库(如Azure Cosmos DB)支持按需选择一致性级别,从强一致到最终一致共5种模式。
-
与其他理论的结合
- BASE理论:通过“基本可用、软状态、最终一致”弥补AP系统的不足,广泛应用于NoSQL设计。
- PACELC扩展:在分区(P)和正常(E)场景下分别权衡一致性(C)与延迟(L),提供更细粒度的设计指导。
六、总结与选型建议
CAP定理揭示了分布式系统的本质矛盾,但实际选型需结合具体场景动态权衡:
- 强一致性优先:选择CP模式(如金融、政务系统)。
- 高可用优先:选择AP模式(如互联网应用、实时分析)。
- 传统事务需求:使用关系型数据库,但需接受扩展性限制。
- 灵活性与扩展性:采用NoSQL并结合BASE理论优化最终一致性。
最终,数据库选型需综合考虑业务目标、数据规模、运维成本等多重因素,而非机械遵循CAP分类。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











