







设计一个高可用的分布式系统需要从架构设计、容错机制、数据一致性、监控恢复等多个维度进行综合规划。以下是基于现有理论、技术实践和行业经验的系统性解决方案:
一、核心原则与目标
-
可用性指标
高可用性通常以“N个9”(如99.99%,年停机≤8.76小时)为目标。核心原则包括:- 冗余设计:避免单点故障,通过多副本、多节点、多区域部署实现容灾。
- 自动故障转移:减少人工干预,通过心跳检测、健康检查等机制快速切换流量。
- 分层架构:从客户端到数据库逐层冗余,确保每一层的独立可用性。
-
分层架构的高可用实现
- 反向代理层:使用Nginx+Keepalived实现负载均衡和虚拟IP自动切换。
- 服务层:通过服务连接池和集群部署,动态分配请求至健康节点。
- 数据层:读库冗余(如主从复制)、写库冗余(如主备切换+虚拟IP)。
- 缓存层:双读双写或主从同步,避免单点故障导致缓存雪崩。
二、容错机制设计
-
冗余策略
- 数据冗余:分布式存储(如HDFS、Cassandra)通过多副本保障数据安全。
- 服务冗余:无状态服务集群化,有状态服务通过主备或分片实现高可用。
- 网络冗余:多运营商链路、BGP多线接入,避免单线路故障。
-
故障检测与恢复
- 心跳机制:定期检测节点状态,超时未响应则标记为故障。
- 自动恢复:Kubernetes的Pod自动重启、数据库主从切换。
- 降级策略:在过载或故障时,优先保障核心功能(如限流、熔断)。
-
容灾方案
- 同城双活:主备数据中心实时同步,故障时DNS/GSLB切换流量。
- 异地多活:多地数据中心同时服务,异步复制数据并自动冲突解决。
- 跨云部署:利用多云平台避免单一云服务商故障。
三、负载均衡与流量管理
-
负载均衡算法
- 静态策略:轮询、加权轮询、哈希(如源IP哈希)。
- 动态策略:最少连接数、响应时间加权,适应实时负载变化。
-
高可用负载均衡器
- 硬件+软件结合:F5硬件负载均衡器与Nginx/LVS互补,避免单点故障。
- 双机热备:主备负载均衡器通过VRRP协议实现自动切换。
-
全局流量调度(GSLB)
根据地理位置、网络延迟和节点健康状态,动态分配用户请求至最优数据中心。
四、数据一致性与分区容错性
-
CAP理论权衡
- CP模式:强一致性优先(如金融系统),适用Redis、HBase。
- AP模式:高可用优先(如电商),适用Cassandra、CouchDB。
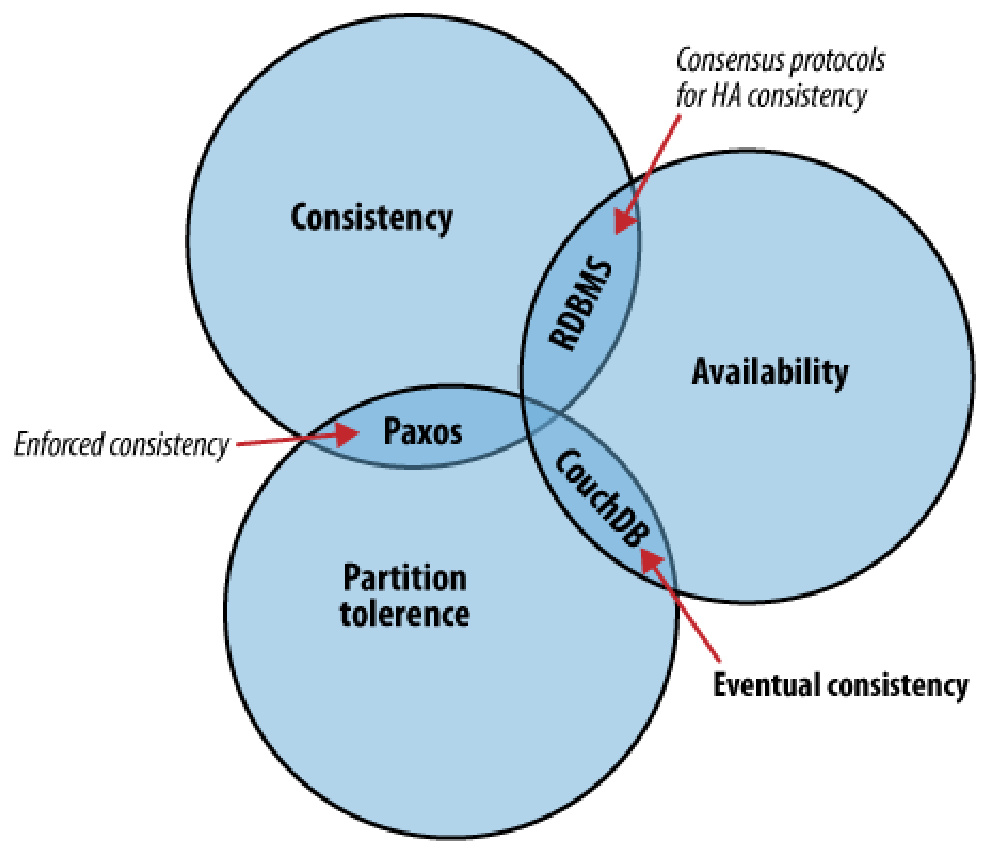
- 最终一致性:通过版本号、向量时钟解决冲突(如Dynamo)。
-
分区容忍性设计
- Quorum机制:读写多数节点成功(如Raft算法)。
- 异步复制:容忍网络分区,通过日志回放恢复一致性。
五、监控与自动化运维
-
全链路监控
- 工具集成:Prometheus+Grafana监控指标,ELK分析日志,分布式追踪(如Jaeger)。
- 健康检查:多层次检测(硬件、网络、服务、应用)。
-
混沌工程
- 故障模拟:使用Chaos Monkey、Gremlin注入网络延迟、节点宕机等故障,验证系统韧性。
- 自动化演练:定期测试容灾切换流程,确保恢复预案有效性。
-
自愈机制
- 自动扩缩容:根据负载动态调整节点数量(如Kubernetes HPA)。
- 数据修复:通过校验和、副本同步修复损坏数据。
六、跨地域与多活架构
-
跨地域部署
- 数据同步:利用云服务商工具(如阿里云CEN、AWS Global Accelerator)实现低延迟复制。
- 流量调度:智能DNS解析用户至最近可用区域,减少延迟。
-
两地三中心
- 同城双活+异地灾备:同城保障低延迟,异地应对大规模灾难。
- 数据分级:核心数据强同步,非核心数据异步备份。
七、最佳实践与挑战
-
实施建议
- 渐进式优化:从单机房冗余起步,逐步扩展至异地多活。
- 成本平衡:根据业务需求选择冗余级别(如冷备 vs 热备)。
-
常见挑战
- 脑裂问题:通过仲裁服务(如ZooKeeper)避免双主冲突。
- 数据冲突:采用时间戳或业务规则解决异步复制冲突。
结论
高可用分布式系统的设计需围绕冗余、自动化、分层容错展开,结合CAP权衡与业务场景选择合适策略。通过全链路监控、混沌工程和跨地域部署,可构建出弹性强、自愈能力高的系统。实际落地中需持续优化,平衡性能、成本与复杂度,最终实现“故障无感知”的用户体验。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











