







tar -xzvf standalone_fate_master_1.6.0.tar.gz
cd standalone_fate_master_1.6.0
source bin/init_env.sh
bash init.sh init
问题:service.sh: [[ not found
解决:修改init.sh文件中的sh命令为bash

测试:
cd standalone_fate_master_1.6.0
source bin/init_env.sh
bash ./python/federatedml/test/run_test.sh
会输出一系列的测试输出,最终:

toy测试
python ./examples/toy_example/run_toy_example.py 10000 10000 0
运行起来之后可以看到:


控制台(IP:8080):

安装FATE-Client和FATE-Test
为方便使用FATE,我们提供了便捷的交互工具FATE-Client以及测试工具FATE-Test.
请在环境内使用以下指令安装:
python -m pip install fate-client
python -m pip install fate-test
二、切分数据集
数据集:威斯康星州临床科学中心开源的乳腺癌肿瘤数据集
from sklearn.datasets import load_breast_cancer
为了模拟横向联邦建模的场景,我们首先在本地将乳腺癌数据集切分为特征相同的横向联邦形式,当前的breast数据集有569条样本,我们将前面的469条作为训练样本,后面的100条作为评估测试样本。
从469条训练样本中,选取前200条作为公司A的本地数据,保存为breast_1_train.csv,将剩余的269条数据作为公司B的本地数据,保存为breast_2_train.csv。
测试数据集可以不需要切分,两个参与方使用相同的一份测试数据即可,文件命名为breast_eval.csv。
splitDataset.py
from sklearn.datasets import load_breast_cancer
import pandas as pd
breast_dataset = load_breast_cancer()
breast = pd.DataFrame(breast_dataset.data, columns=breast_dataset.feature_names)
breast = (breast-breast.mean())/(breast.std())
col_names = breast.columns.values.tolist()
columns = {}
for idx, n in enumerate(col_names):
columns[n] = “x%d”%idx
breast = breast.rename(columns=columns)
breast[‘y’] = breast_dataset.target
breast[‘idx’] = range(breast.shape[0])
idx = breast[‘idx’]
breast.drop(labels=[‘idx’], axis=1, inplace = True)
breast.insert(0, ‘idx’, idx)
breast = breast.sample(frac=1)
train = breast.iloc[:469]
eval = breast.iloc[469:]
breast_1_train = train.iloc[:200]
breast_1_train.to_csv(‘breast_1_train.csv’, index=False, header=True)
breast_2_train = train.iloc[200:]
breast_2_train.to_csv(‘breast_2_train.csv’, index=False, header=True)
eval.to_csv(‘breast_eval.csv’, index=False, header=True)
注意:官方地址中的csv文件是有问题的,要运行这个切割数据集自己生成新的数据集文件
===================================================================================
用FATE构建横向联邦学习Pipeline,涉及到三个方面的工作:
- 数据转换输入
将数据文件(csv、txt)等转换成为FATE独有的基础数据结构DTable,从而方便进一步的操作

模型训练
FATE以模型训练构建流水线pipeline
模型评估:(可选)
评估模型性能的手段
如果只使用框架自带的模型,那么其实我们需要修改的就是配置文件即可
新建一个项目目录chapter05(我这里创建的叫chapter05因为对应书第五章内容,可自行修改)
将数据集放到该目录下的data目录中:
完成数据转换,需要一个配置文件和一个启动程序:
配置文件
upload_data.json文件编写配置,内容为:
{
“file”: “data/breast_1_train.csv”,
“head”: 1,
“partition”: 16,
“work_mode”: 0,
“table_name”: “homo_breast_1_train”,
“namespace”: “homo_host_breast_train”
}
字段说明:
-
file: 数据文件路径,相对于当前所在路径
-
head: 指定数据文件是否包含表头
-
partition: 指定用于存储数据的分区数
-
work_mode: 指定工作模式,0代表单机版,1代表集群版
-
table_name:转换为DTable格式的表名
-
namespace: DTable格式的表名对应的命名空间
-
backend: 指定后端,0代表EGGROLL, 1代表SPARK加RabbitMQ, 2代表SPARK加Pulsar (暂时未用到)
fate-flow上传数据
使用fate-flow上传数据。从FATE-1.5开始,推荐使用 FATE-Flow Client Command Line 执行FATE-Flow任务。
提示:
{
“retcode”: 100,
“retmsg”: “Fate flow CLI has not been initialized yet or configured incorrectly. Please initialize it before using CLI at the first time. And make sure the address of fate flow server is configured correctly. The configuration file path is: /ai/xwj/federate_learning/fate_dir/standalone_fate_master_1.6.0/venv/lib/python3.6/site-packages/flow_client/settings.yaml.”
}
解决:先初始化flow
使用flow首先要初始化一下:
Fate Flow 命令行初始化命令。用户可选择提供fate服务器配置文件路径或指定fate服务器ip地址及端口进行初始化。注意:若用户同时使用上述两种方式进行初始化,CLI将优先读取配置文件内容,而用户所配置的服务器ip地址及端口信息将被忽略。
因为之前init命令直接已经启动了flow,所以直接初始化即可
flow init --ip 127.0.0.1 --port 9380
{
“retcode”: 0,
“retmsg”: “Fate Flow CLI has been initialized successfully.”
}
因为之前上传命令会自动将原始的本地文件转为DTable格式
flow data upload -c upload_data.json
注意,我使用的是新版本,新版本支持命令行直接使用
如果提示没有flow命令,那么可能没有使用提供的conda环境,解决如下:
source bin/init_env.sh
{
“data”: {
“board_url”: “http://127.0.0.1:8080/index.html#/dashboard?job_id=202108151639113656812&role=local&party_id=0”,
“job_dsl_path”: “/home/jiangbo/FATE/standalone_fate_master_1.6.0/jobs/202108151639113656812/job_dsl.json”,
“job_id”: “202108151639113656812”,
“job_runtime_conf_on_party_path”: “/home/jiangbo/FATE/standalone_fate_master_1.6.0/jobs/202108151639113656812/local/job_runtime_on_party_conf.json”,
“job_runtime_conf_path”: “/home/jiangbo/FATE/standalone_fate_master_1.6.0/jobs/202108151639113656812/job_runtime_conf.json”,
“logs_directory”: “/home/jiangbo/FATE/standalone_fate_master_1.6.0/logs/202108151639113656812”,
“model_info”: {
“model_id”: “local-0#model”,
“model_version”: “202108151639113656812”
},
“namespace”: “homo_host_breast_train”,
“pipeline_dsl_path”: “/home/jiangbo/FATE/standalone_fate_master_1.6.0/jobs/202108151639113656812/pipeline_dsl.json”,
“table_name”: “homo_breast_1_train”,
“train_runtime_conf_path”: “/home/jiangbo/FATE/standalone_fate_master_1.6.0/jobs/202108151639113656812/train_runtime_conf.json”
},
“jobId”: “202108151639113656812”,
“retcode”: 0,
“retmsg”: “success”
}
访问board_url可以在浏览器中看到对应的详情:
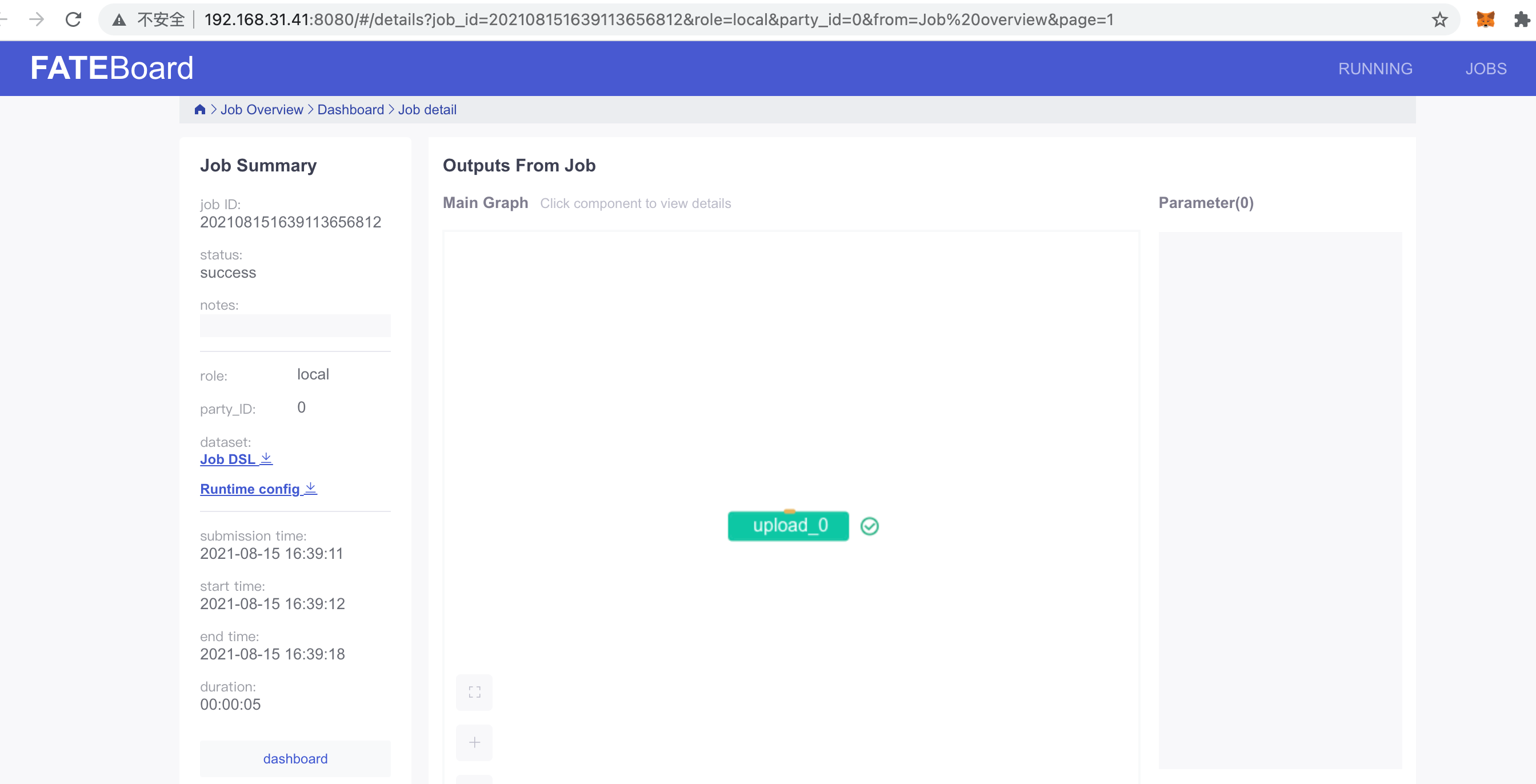
对于breast_2_train.csv以及测试集合同样的过程:
测试集上传到两个参与方,并各自转换为DTable格式
{
“file”: “data/breast_2_train.csv”,
“head”: 1,
“partition”: 16,
“work_mode”: 0,
“table_name”: “homo_breast_2_train”,
“namespace”: “homo_guest_breast_train”
}
// host
{
“file”: “data/breast_eval.csv”,
“head”: 1,
“partition”: 16,
“work_mode”: 0,
“table_name”: “homo_breast_1_eval”,
“namespace”: “homo_host_breast_eval”
}
// guest
{
“file”: “data/breast_eval.csv”,
“head”: 1,
“partition”: 16,
“work_mode”: 0,
“table_name”: “homo_breast_2_eval”,
“namespace”: “homo_guest_breast_eval”
}
借助FATE,我们可以使用组件的方式来构建联邦学习,而不需要用户从新开始编码,FATE构建联邦学习Pipeline是通过自定义dsl和conf两个配置文件来实现:
dsl文件:用来描述任务模块,将任务模块以有向无环图(DAG)的形式组合在一起。
conf文件:设置各个组件的参数,比如输入模块的数据表名;算法模块的学习率、batch大小、迭代次数等。
我们本实验使用的是模型:逻辑回归
进入examples/dsl/v1/homo_logistic_regression文件夹中:
使用test_homolr_train_job_dsl.json、test_homolr_train_job_conf.json两个文件来辅助构建横向联邦学习模型
3.2.1 DSL配置文件
为了让任务模型的构建更加灵活,目前 FATE 使用了一套自定的领域特定语言 (DSL) 来描述任务。在 DSL 中,各种任务模块(例如数据读写 data_io,特征工程 feature-engineering, 回归 regression,分类 classification)可以通向一个有向无环图 (DAG) 组织起来。通过各种方式,用户可以根据自身的需要,灵活地组合各种算法模块。
DSL 的配置文件采用 json 格式,实际上,整个配置文件就是一个 json 对象 (dict)。在这个 dict 的第一级是 “components”,用来表示这个任务将会使用到的各个模块。用户需要使用模块名加数字 _num 作为对应模块的 key,例如 dataio_0,并且数字应从 0 开始计数。
具体的参数见官方文档连接(上面)
test_homolr_train_job_dsl.json:
定义了四个模块已经构成了基本的联邦学习流水线(feature_scale_0为1.6.0新增),可直接使用(复制一份)
{
“components” : {
// 数据IO组件,用于将本地数据转为DTable
“dataio_0”: {
“module”: “DataIO”,
“input”: {
“data”: {
“data”: [
“args.train_data”
]
}
},
“output”: {
“data”: [“train”],
“model”: [“dataio”]
}
},
// 特征工程模块
“feature_scale_0”: {
“module”: “FeatureScale”,
“input”: {
“data”: {
“data”: [
“dataio_0.train”
]
}
},
“output”: {
“data”: [“train”],
“model”: [“feature_scale”]
}
},
// 横向逻辑回归组件
“homo_lr_0”: {
“module”: “HomoLR”,
“input”: {
“data”: {
“train_data”: [
“feature_scale_0.train”
]
}
},
“output”: {
“data”: [“train”],
“model”: [“homolr”]
}
},
// 模型评估组件,如果未提供测试数据集则自动使用训练集
“evaluation_0”: {
“module”: “Evaluation”,
“input”: {
“data”: {
“data”: [
“homo_lr_0.train”
]
}
}
}
}
}
这里的args.train_data是根据下面的运行配置conf来的
其次配置文件之间的指定关系如下:

3.2.2 运行配置 Submit Runtime Conf
每个模块都有不同的参数需要配置,不同的 party 对于同一个模块的参数也可能有所区别。为了简化这种情况,对于每一个模块,FATE 会将所有 party 的不同参数保存到同一个运行配置文件(Submit Runtime Conf)中,并且所有的 party 都将共用这个配置文件。
除了 DSL 的配置文件之外,用户还需要准备一份运行配置(Submit Runtime Conf)用于设置各个组件的参数。
test_homolr_train_job_conf.json 修改如下:
{
// 创始人
“initiator”: {
“role”: “guest”,
“party_id”: 10000
},
“job_parameters”: {
“work_mode”: 0 // 0代表单机版,1代表集群版
},
// 所有参与此任务的角色
// 每一个元素代表一种角色以及承担这个角色的party_id,是一个列表表示同一角色可能有多个实体ID
“role”: {
“guest”: [
10000
],
“host”: [
10000
],
// 仲裁者
“arbiter”: [
10000
]
},
// 对于权限角色的进一步参数配置
“role_parameters”: {
“guest”: {
“args”: {
“data”: {
“train_data”: [
{
“name”: “homo_breast_2_train”, // 修改DTable的表名
“namespace”: “homo_guest_breast_train” // 修改命名空间
}
]
}
},
“dataio_0”: {
“label_name”: [“y”] // 添加标签对应的列属性名称
}
},
“host”: {
“args”: {
“data”: {
“train_data”: [
{
“name”: “homo_breast_1_train”, // 同理修改
“namespace”: “homo_host_breast_train”
}
]
}
},
“dataio_0”: {
“label_name”: [“y”] // 添加标签对应的列属性名称
},
“evaluation_0”: {
“need_run”: [
false
]
}
}
},
// 设置模型训练的超参数信息
“algorithm_parameters”: {
“dataio_0”: {
“with_label”: true,
“label_name”: “y”,
“label_type”: “int”,
“output_format”: “dense”
},
“homo_lr_0”: {
“penalty”: “L2”,
“optimizer”: “sgd”,
“tol”: 1e-05,
“alpha”: 0.01,
“max_iter”: 10,
“early_stop”: “diff”,
“batch_size”: 500,
“learning_rate”: 0.15,
“decay”: 1,
“decay_sqrt”: true,
“init_param”: {
“init_method”: “zeros”
},
“encrypt_param”: {
“method”: null
},
“cv_param”: {
“n_splits”: 4,
“shuffle”: true,
“random_seed”: 33,
“need_cv”: false
}
}
}
}
关于角色,解释如下:
-
arbiter是用来辅助多方完成联合建模的,它的主要作用是聚合梯度或者模型。比如纵向lr里面,各方将自己一半的梯度发送给arbiter,然后arbiter再联合优化等等。
-
guest代表数据应用方。
-
host是数据提供方。
-
local是指本地任务, 该角色仅用于upload和download阶段中。
3.2.3 提交参数,训练模型
Job submit
-
介绍: 提交执行pipeline任务。
-
参数:
| 编号 | 参数 | Flag_1 | Flag_2 | 必要参数 | 参数介绍 |
| :-: | — | — | — | — | — |
| 1 | conf_path | -c | –conf-path | 是 | 任务配置文件路径 |
| 2 | dsl_path | -d | –dsl-path | 否 | DSL文件路径. 如果任务为预测任务,该字段可以不输入。另外,用户可以提供可用的自定义DSL文件用于执行预测任务。 |
执行:
flow job submit -c test_homolr_train_job_conf.json -d test_homolr_train_job_dsl.json
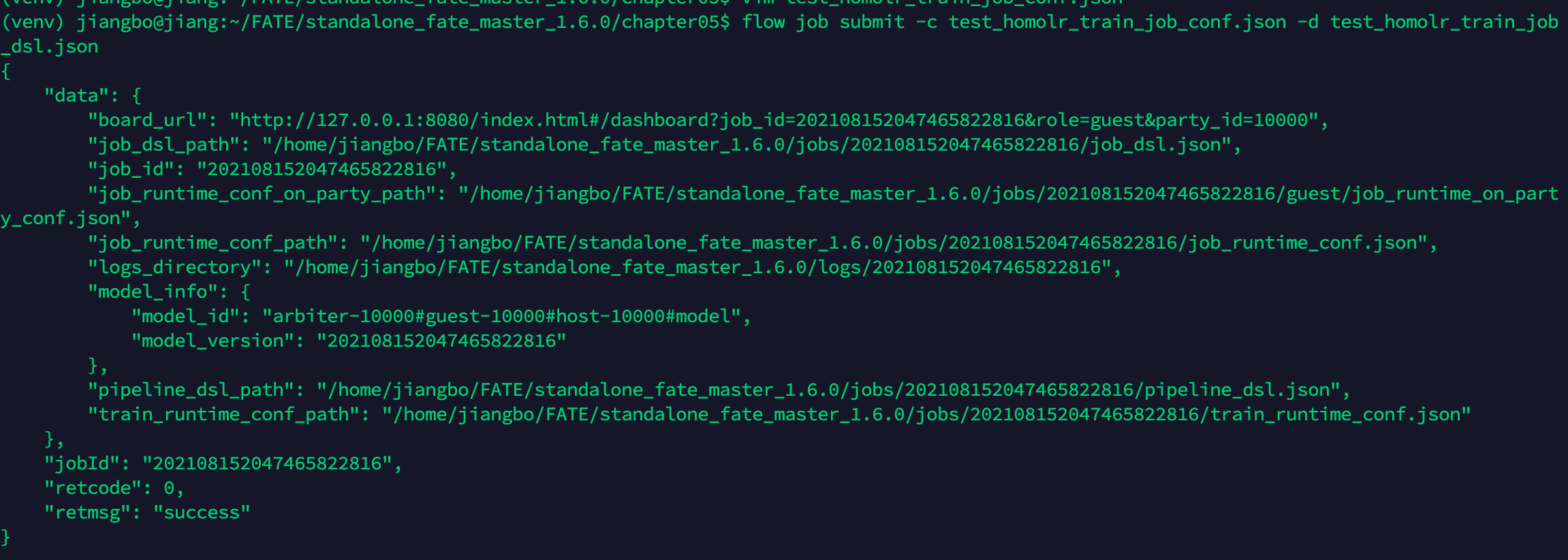

注意:需要全部为勾号才说明运行成功
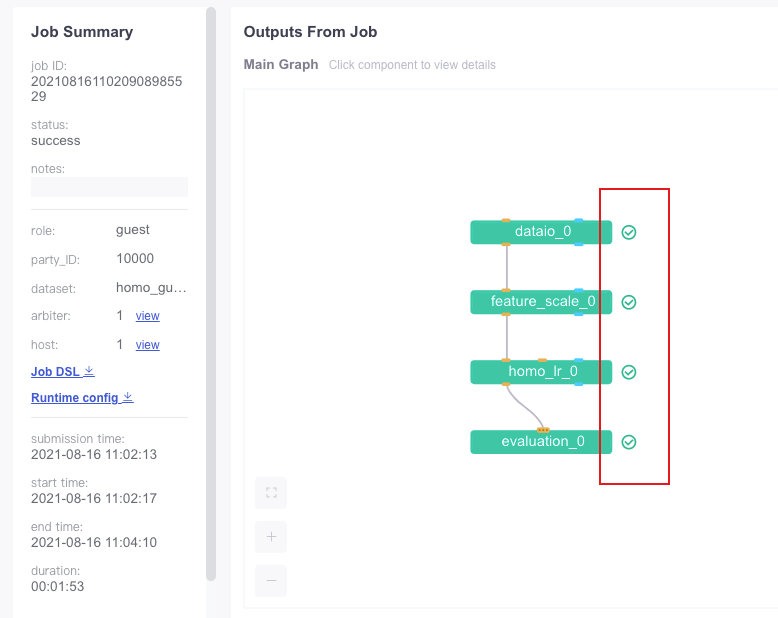
可以看到运行的结果: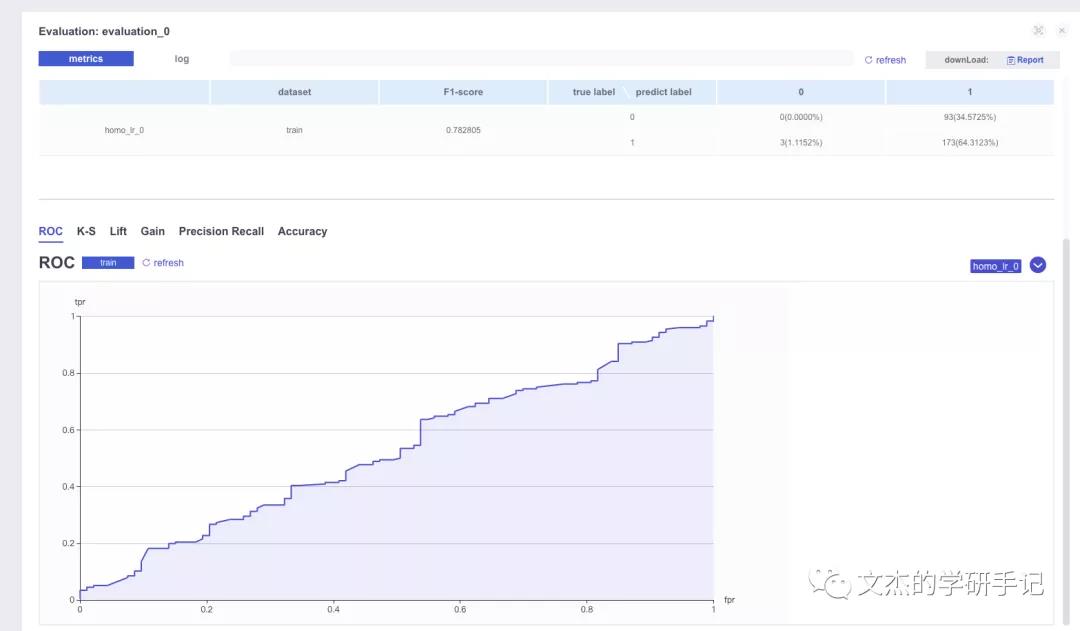
为了评估模型的效果,我们重新修改配置以检查效果:
在上传数据时,我们已经将两个评估模型的数据上传,并且转换为DTable格式
现在我们修改dsl配置文件:
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。






既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)

最后
不知道你们用的什么环境,我一般都是用的Python3.6环境和pycharm解释器,没有软件,或者没有资料,没人解答问题,都可以免费领取(包括今天的代码),过几天我还会做个视频教程出来,有需要也可以领取~
给大家准备的学习资料包括但不限于:
Python 环境、pycharm编辑器/永久激活/翻译插件
python 零基础视频教程
Python 界面开发实战教程
Python 爬虫实战教程
Python 数据分析实战教程
python 游戏开发实战教程
Python 电子书100本
Python 学习路线规划

一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

g_convert/252731a671c1fb70aad5355a2c5eeff0.png)
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)
[外链图片转存中…(img-qJOvvD8n-1712961438400)]
最后
不知道你们用的什么环境,我一般都是用的Python3.6环境和pycharm解释器,没有软件,或者没有资料,没人解答问题,都可以免费领取(包括今天的代码),过几天我还会做个视频教程出来,有需要也可以领取~
给大家准备的学习资料包括但不限于:
Python 环境、pycharm编辑器/永久激活/翻译插件
python 零基础视频教程
Python 界面开发实战教程
Python 爬虫实战教程
Python 数据分析实战教程
python 游戏开发实战教程
Python 电子书100本
Python 学习路线规划
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
[外链图片转存中…(img-tl3GqEsV-1712961438401)]















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









