






今天给大家分享在面试中经常被问到的 MySQL 题目,一共160道高频面试题,文章有限不能在此一一展示,(文末有完整版PDF!)
1、关系型和非关系型数据库的区别?
关系型数据库的优点
● 容易理解,因为它采⽤了关系模型来组织数据。
● 可以保持数据的⼀致性。
● 数据更新的开销⽐较⼩。
● ⽀持复杂查询(带 where ⼦句的查询)
⾮关系型数据库(NOSQL)的优点
● ⽆需经过 SQL 层的解析,读写效率⾼。
● 基于键值对,读写性能很⾼,易于扩展
● 可以⽀持多种类型数据的存储,如图⽚,⽂档等等。
● 扩展(可分为内存性数据库以及⽂档型数据库,⽐如 Redis,MongoDB,HBase 等,适合场景:数据量⼤⾼可⽤的⽇志系统/地理位置存储系统)。
2、MySQL 使用索引的原因?
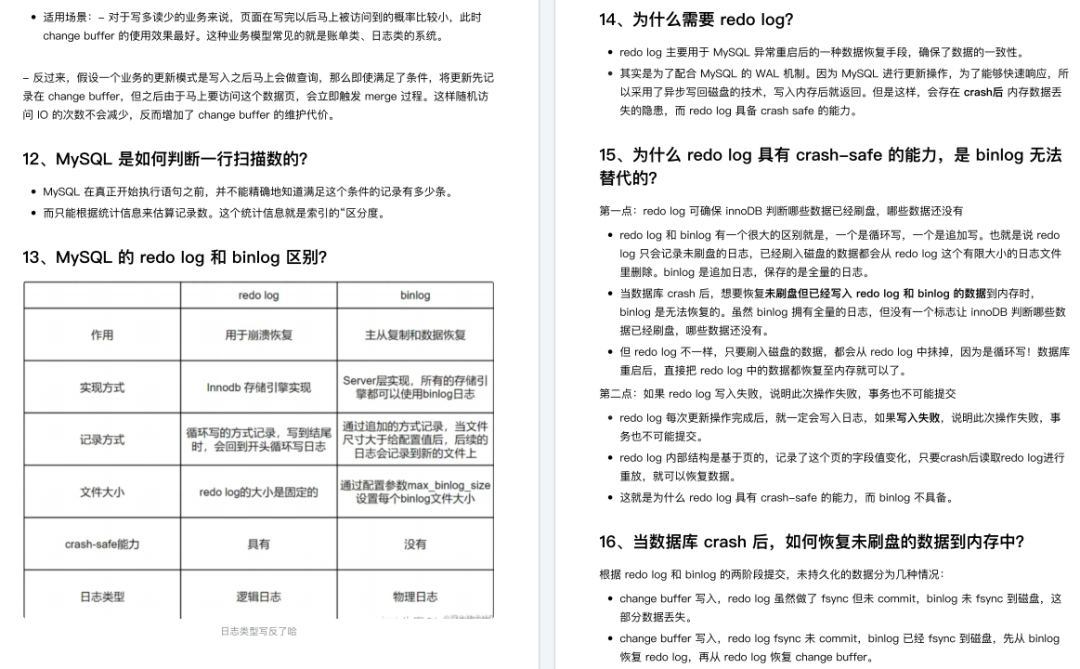
根本原因
● 索引的出现,就是为了提⾼数据查询的效率,就像书的⽬录⼀样。
● 对于数据库的表⽽⾔,索引其实就是它的“⽬录”。
扩展
● 创建唯⼀性索引,可以保证数据库表中每⼀⾏数据的唯⼀性。
● 帮助引擎层避免排序和临时表
● 将随机 IO 变为顺序 IO,加速表和表之间的连接。
3、MySQL 的大表查询为什么不会爆内存?
● 由于 MySQL 是边读变发,因此对于数据量很⼤的查询结果来说,不会再 server 端保存完整的结果集,所以,如果客户端读结果不及时,会堵住 MySQL 的查询过程,但是不会把内存打爆。
● InnoDB 引擎内部,由于有淘汰策略,InnoDB 管理 Buffer_Pool 使⽤的是改进的 LRU 算法,使⽤链表实现,实现上,按照 5:3 的⽐例把整个 LRU 链表分成了 young 区域和 old 区域。对冷数据的全扫描,影响也能做到可控制。
4、MySQL 存储引擎介绍(InnoDB、MyISAM、MEMORY)
● InnoDB 是事务型数据库的⾸选引擎,⽀持事务安全表 (ACID),⽀持⾏锁定和外键。MySQL5.5.5 之后,InnoDB 作为默认存储引擎
● MyISAM 基于 ISAM 的存储引擎,并对其进⾏扩展。它是在 Web、数据存储和其他应⽤环境18下最常⽤的存储引擎之⼀。MyISAM 拥有较⾼的插⼊、查询速度,但不⽀持事务。在MySQL5.5.5 之前的版本中,MyISAM 是默认存储引擎
● MEMORY 存储引擎将表中的数据存储到内存中,为查询和引⽤其他表数据提供快速访问。
5、MySQL 的并行策略有哪些?
● 按表分发策略:如果两个事务更新不同的表,它们就可以并⾏。因为数据是存储在表⾥的,所以按表分发,可以保证两个 worker 不会更新同⼀⾏。
缺点:如果碰到热点表,⽐如所有的更新事务都会涉及到某⼀个表的时候,所有事务都会被分配到同⼀个 worker 中,就变成单线程复制了。
● 按⾏分发策略:如果两个事务没有更新相同的⾏,它们在备库上可以并⾏。如果两个事务没有更新相同的⾏,它们在备库上可以并⾏执⾏。显然,这个模式要求 binlog 格式必须是 row。
缺点:相⽐于按表并⾏分发策略,按⾏并⾏策略在决定线程分发的时候,需要消耗更多的计算资源。
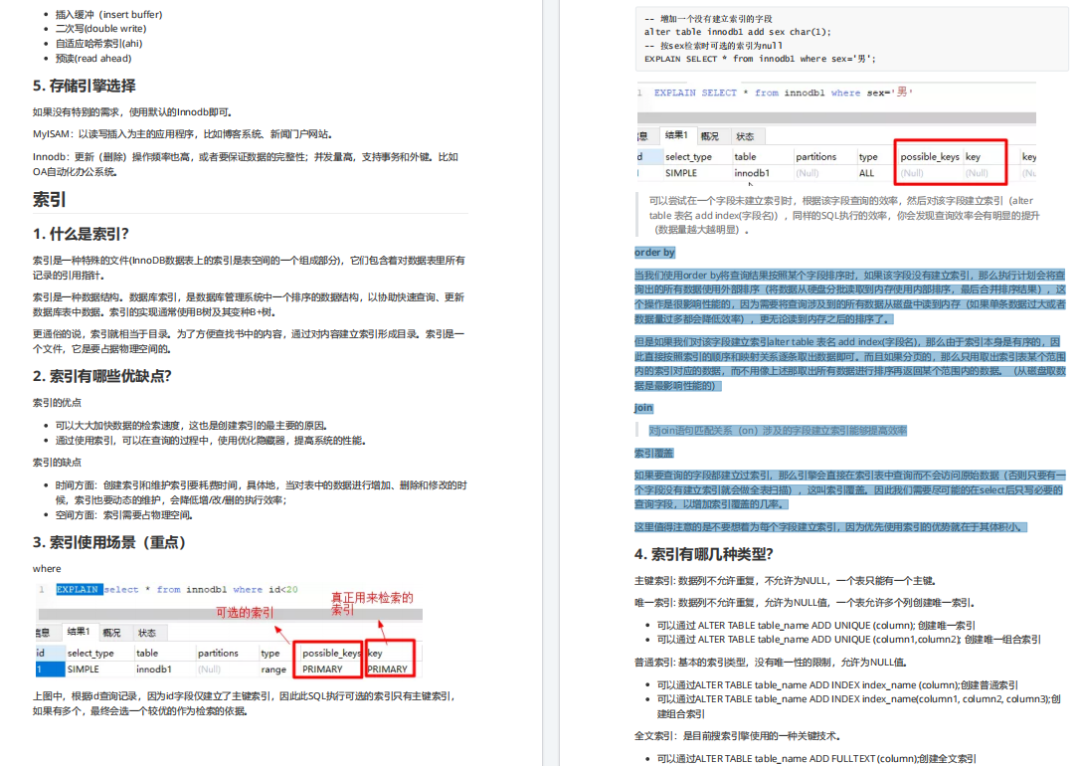
6、索引使用场景
where
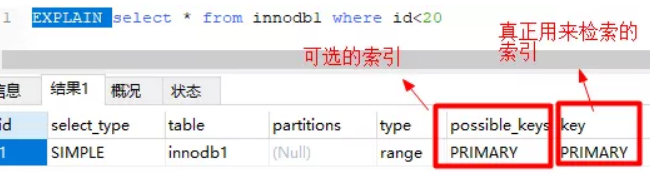
上图中,根据id查询记录,因为id字段仅建立了主键索引,因此此SQL执行可选的索引只有主键索引,
如果有多个,最终会选一个较优的作为检索的依据。
-- 增加一个没有建立索引的字段alter table innodb1 add sex char(1);-- 按sex检索时可选的索引为nullEXPLAIN SELECT * from innodb1 where sex='男';
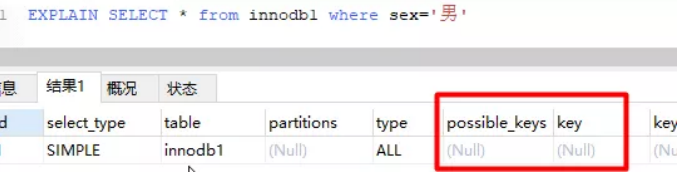
可以尝试在一个字段未建立索引时,根据该字段查询的效率,然后对该字段建立索引(alter table 表名 add index(字段名)),同样的SQL执行的效率,你会发现查询效率会有明显的提升 (数据量越大越明显)。
order by
当我们使用order by将查询结果按照某个字段排序时,如果该字段没有建立索引,那么执行计划会将查询出的所有数据使用外部排序(将数据从硬盘分批读取到内存使用内部排序,最后合并排序结果),这个操作是很影响性能的,因为需要将查询涉及到的所有数据从磁盘中读到内存(如果单条数据过大或者数据量过多都会降低效率),更无论读到内存之后的排序了。
但是如果我们对该字段建立索引alter table 表名 add index(字段名),那么由于索引本身是有序的,因此直接按照索引的顺序和映射关系逐条取出数据即可。而且如果分页的,那么只用取出索引表某个范围内的索引对应的数据,而不用像上述那取出所有数据进行排序再返回某个范围内的数据。(从磁盘取数据是最影响性能的)
join
对join语句匹配关系(on)涉及的字段建立索引能够提高效率
索引覆盖
如果要查询的字段都建立过索引,那么引擎会直接在索引表中查询而不会访问原始数据(否则只要有一个字段没有建立索引就会做全表扫描),这叫索引覆盖。因此我们需要尽可能的在select后只写必要的查询字段,以增加索引覆盖的几率。
这里值得注意的是不要想着为每个字段建立索引,因为优先使用索引的优势就在于其体积小。
更多内容展示


*题目整合自网络,由「程序员贺同学」及「ThinkWon」的整理,仅用于学习交流分享,版权归原作者所有,如有侵权请联系删除
完整资料领取看这
扫码备注:160道MySQL面试题
即可100%免费领取
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









