






目录
使用daemonset方式安装ingress时,master节点没有ingress-controller运行。
master节点的ingress-controller状态陷入CrashLoopBackOff
前言
本文是基于网络社区较为流行的k8s高可用部署文档的踩坑排错记录。作为一个k8s新手,在使用该文档的教程方法执行k8s部署时遇到诸多问题,而网络社区中的问题记录和博客教程都不是很能解决自己在部署时遇到的问题。在此对这些踩坑做一个记录。
由于本人能力有限,第一次发文,相关问题的解决方法和文章内容难免出错。欢迎评论纠错,互相讨论。
基于部署文档网址:32 张配图详解 K8S 1.24 高可用部署,保姆级详细版! (qq.com)
实验环境
虚拟机相关信息:
| 虚拟机操作系统 | 主机名 | ip 地址 | 内存 | CPU核数 | 角色 | VIP |
| CentOS 8.5 | k8s-master -168-209-11 | 192.168.209.11 | 2GB | 2 | master | 192.168.209.120 |
| CentOS 8.5 | k8s-master2 -168-209-14 | 192.168.209.14 | 2GB | 2 | master | 192.168.209.120 |
| CentOS 8.5 | k8s-node1 -168-209-12 | 192.168.209.12 | 2GB | 2 | worker | |
| CentOS 8.5 | k8s-node1 -168-209-13 | 192.168.209.13 | 2GB | 2 | worker |
相关配置项信息:
| K8s | 1.24.1 |
| Docker-ce | 26.0.2 |
| Ingress | 1.2 |
| Nginx | 1.14.1 |
| Keepalived | 2.1.5 |
| Dashboard Web | 2.6 |
| Harbor | 2.10.2 |
| Xshell | 7 |
k8s初始化失败相关问题
我的kubeadm init语句如下所示,错误是基于这些选项发生的。列出以供参考。
kubeadm init \
--apiserver-advertise-address=192.168.209.11 \
--image-repository registry.aliyuncs.com/google_containers \
--control-plane-endpoint=cluster-endpoint \
--kubernetes-version v1.24.1 \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16 \
--v=5机器配置不满足k8s最低配置要求
k8s1.24.1初始最低要求需要两个CPU和1700MB内存。若出现这样的错误,为虚拟机增加相关配置信息即可。

tc not found
执行kubeadm init初始化时,可能遇到报错tc not found。这个错误对于初始化虽然没有什么影响,但是如果不放心的话可以把tc这个工具下好就不会报错了。

yum install iproute-tc -ykubeadm init等待控制平面超时
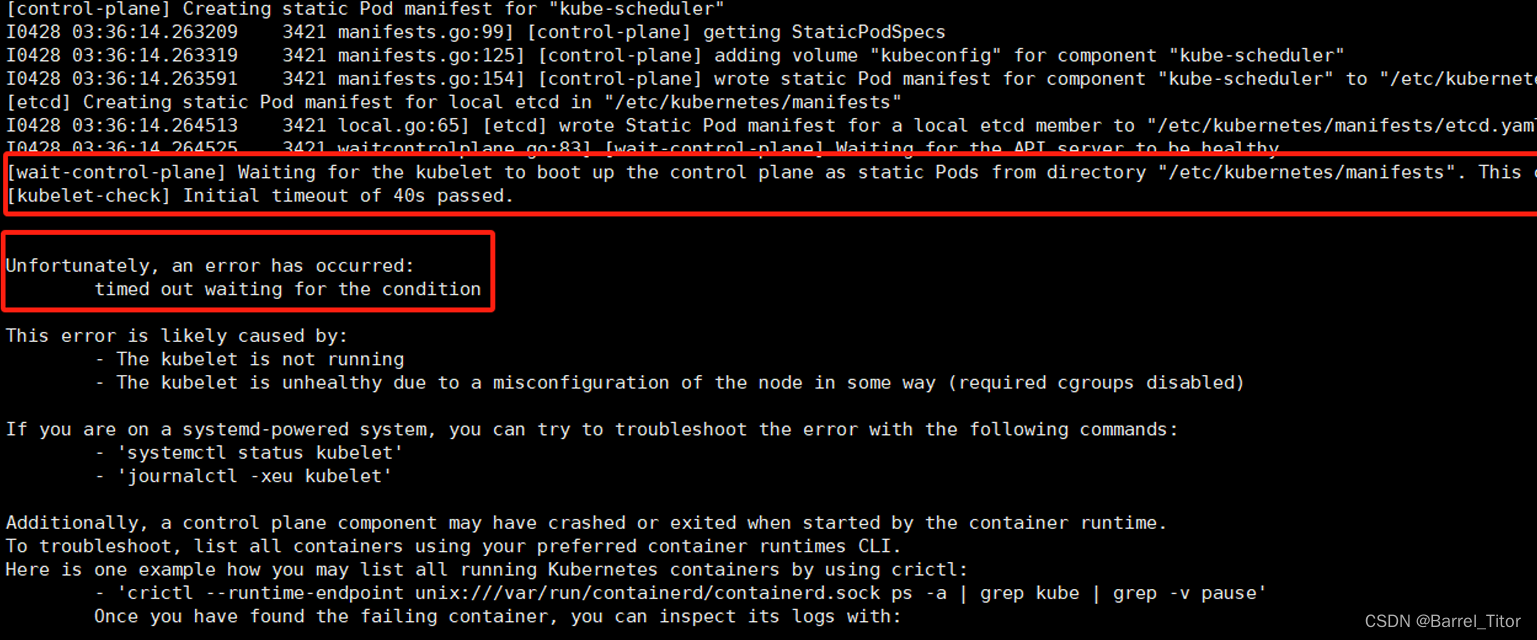
如果出现等待超时这样的错误需要排查多处地方,在下边列出几项可能出错的地方。
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory “/etc/kubernetes/manifests”. This can take up to 4m0s
[kubelet-check] Initial timeout of 40s passed.
1、导出默认配置的config.toml配置有误
确定sandbox_image的镜像源是阿里云的镜像源而不是k8s官方的。
grep sandbox_image /etc/containerd/config.toml 
2、control-plane的输入有误
control-plane的合法输入应是一个ipv4的地址,但是做应用时不可能记住ip做管理,肯定是配置成有意义的字符串帮助记忆。在这里,我的control-plane输入是cluster-endpoint。
cluster-endpoint 是映射到该 IP 的自定义 DNS 名称,这里配置hosts映射:192.168.209.11 cluster-endpoint。 这将使 --control-plane-endpoint=cluster-endpoint 传递给 kubeadm init,并将相同的 DNS 名称传递给 kubeadm join。
确保/etc/hosts文件有相应的映射。否则会一直等待控制平面超时。道理也很简单,操作系统根本不知道这个自定义DNS字符串是什么东西,找不到对应的ip映射关系,自然找不到对应的主机,自然就导致了超时。

3、master节点状态处于NotReady
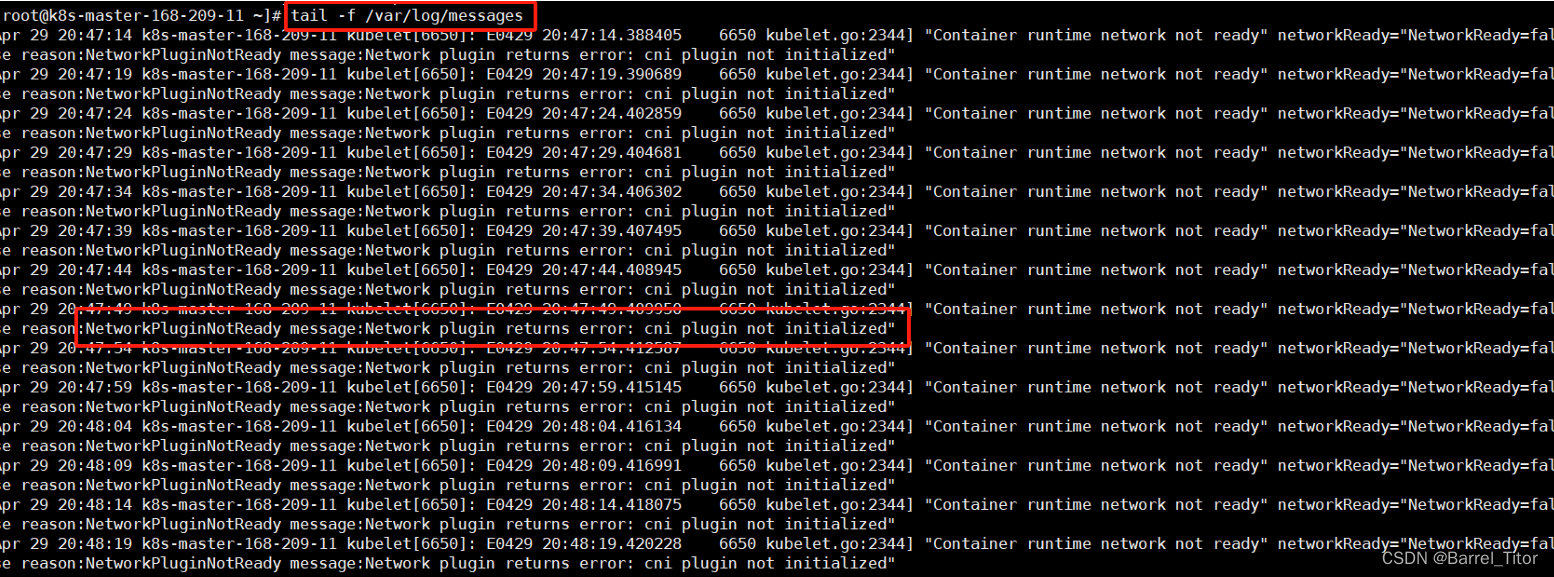
初始化后,master节点状态可能NotReady,相应的问题可以通过查看日志得知。
执行命令以下命令查看日志。
tail -f /var/log/message可以看到日志错误提醒cni plugin not initialized,所以问题是cni插件没装。
初始化时用的是flannel方案,执行以下命令安装cni插件。
docker pull quay.io/coreos/flannel:v0.14.0
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.ymlingress相关问题
使用daemonset方式安装ingress时,master节点没有ingress-controller运行。
这是因为master节点可能设置了不可调度,若想master节点也运行ingress-controller将master的taints去掉即可,即将master设置成可调度。
#node的名字可以用kubectl get nodes知道
kubectl describe node k8s-master-168-209-11
#只看Taints的话可以直接grep 执行以下命令即可
kubectl describe node k8s-master-168-209-11 | grep Taint
#确定状态后,若有Taints则将其设置为none以将master节点设置成可调度
kubectl taint nodes k8s-master-168-209-11 node-role.kubernetes.io/master-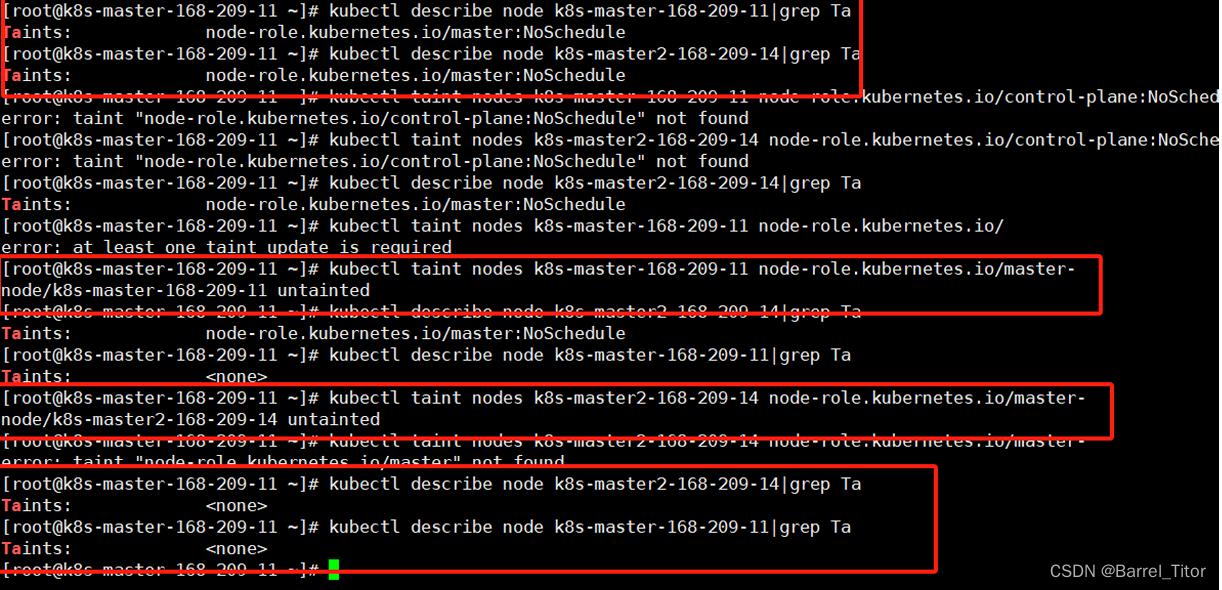
master节点的ingress-controller状态陷入CrashLoopBackOff
错误如下图所示。
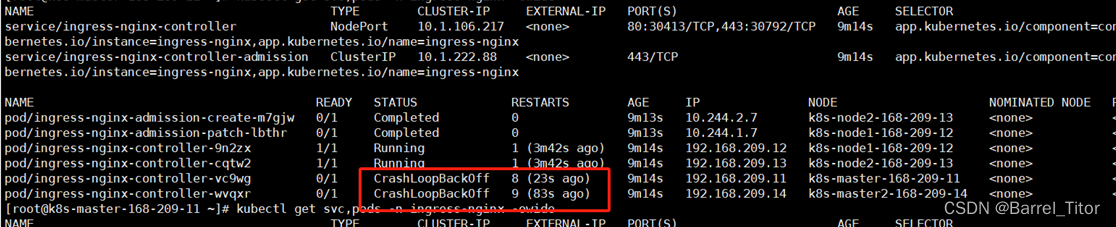
CrashLoopBackOff就是因为某些原因使pod不断重启从而无法成功运行,这里出现这个错误是因为我按照参考的文档网址部署了Nginx+Keepalived的高可用负载均衡器。而Nginx在配置时用了80端口作为监听端口,导致与master节点ingress-controller端口冲突。
执行以下命令查看pod日志
#pod_name是实际的pod名 namespace是容器所在的名空间
kubectl logs pod_name -n namespace
#以我的集群为例 执行下边的命令查询日志
kubectl logs ingress-nginx-controller-sxv22 -n ingress-nginx
可以看到日志提示80端口以及被占用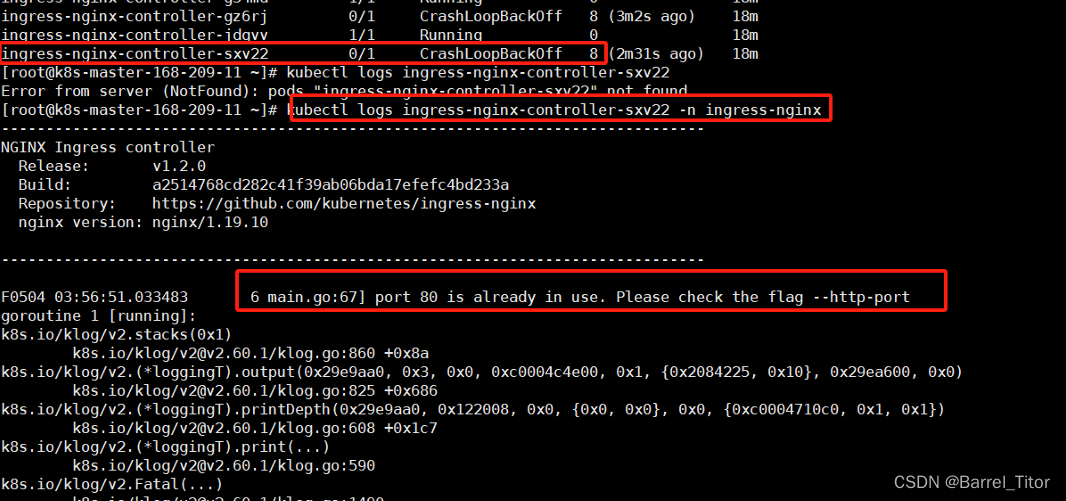
可以使用lsof看哪些进程在用80端口。执行以下命令排错。
lsof -i :80可以看到nginx进程正在使用80端口

这里是因为我在配置nginx.conf时使用了80端口作为监听端口,因此解决办法要么是把nginx的80端口改了,要么把ingress-controller的默认端口改了。只要他们俩之间的端口不冲突就行。在这里我把nginx的监听端口改成了81,然后重启nginx,删除原来的ingress再重新安装。master节点的ingress-controller的运行状态就行running了。
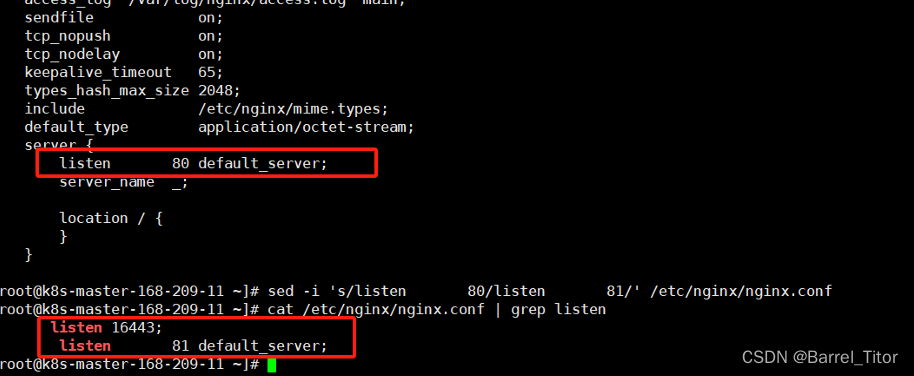
#可以执行get命令查看pod状态
kubectl get svc,pods -n ingress-nginx -owide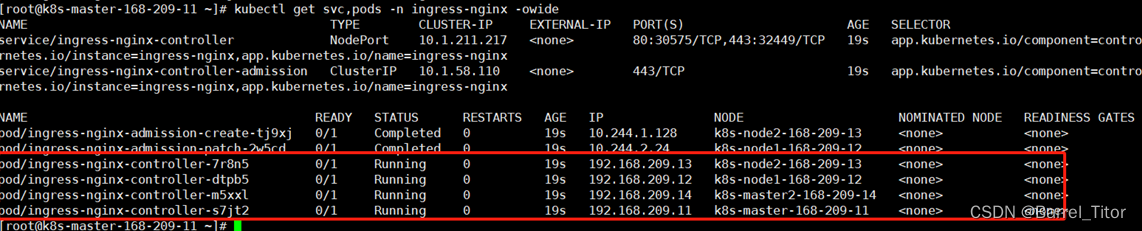
Harbor相关问题
Harbor安装失败
如果Harbor出现下边的这个错误,那可能是helm版本过低了。在使用helm安装harbor版本>=1.14.0的时候,helm版本需要>=3.10.0。如果不满足,则会报错。我在安装harbor时,远程最新的harbor已经是2.10.2了,而我的helm版本是3.9.0。因此出现了这样的错误。
Error: INSTALLATION FAILED: template: harbor/templates/registry/registry-secret.yaml:11:62: executing "harbor/templates/registry/registry-secret.yaml" at <include "harbor.secretKeyHelper" (dict "key" "REGISTRY_HTTP_SECRET" "data" $existingSecret.data)>: error calling include: template: harbor/templates/_helpers.tpl:44:41: executing "harbor.secretKeyHelper" at <.data>: wrong type for value; expected map[string]interface {}; got interface {}
我的安装命令:
helm install myharbor --namespace harbor harbor/harbor \
--set expose.ingress.hosts.core=myharbor.com \
--set expose.ingress.hosts.notary=notary.myharbor.com \
--set-string expose.ingress.annotations.'nginx\.org/client-max-body-size'="1024m" \
--set expose.tls.secretName=myharbor.com \
--set persistence.persistentVolumeClaim.registry.storageClass=nfs-client \
--set persistence.persistentVolumeClaim.jobservice.storageClass=nfs-client \
--set persistence.persistentVolumeClaim.database.storageClass=nfs-client \
--set persistence.persistentVolumeClaim.redis.storageClass=nfs-client \
--set persistence.persistentVolumeClaim.trivy.storageClass=nfs-client \
--set persistence.persistentVolumeClaim.chartmuseum.storageClass=nfs-client \
--set persistence.enabled=true \
--set externalURL=https://myharbor.com \
--set harborAdminPassword=Harbor12345 错误如图: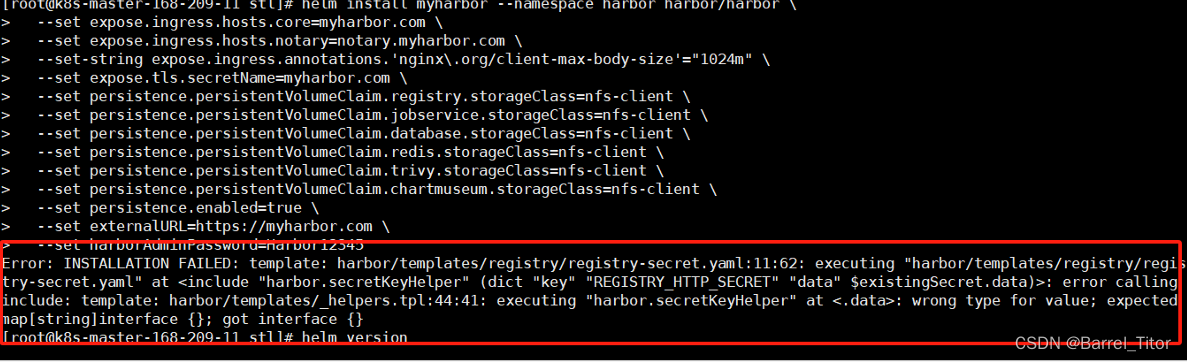
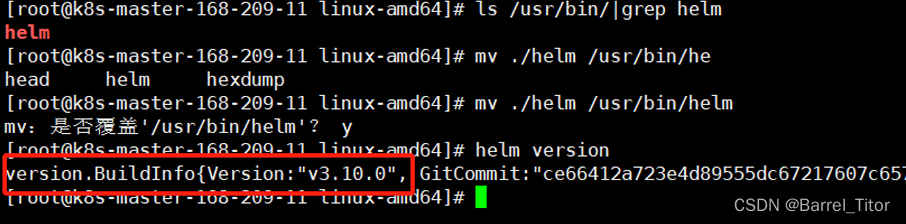
即如此,更新helm到3.10.0及以上即可,我在这将helm更新到了helm3.10.0。
#获取想要的helm版本包 我这里下的3.10
wget https://get.helm.sh/helm-v3.10.0-rc.1-linux-amd64.tar.gz
#随后解压该包获得里边的二进制文件helm
tar -zxvf helm-v3.10.0-rc.1-linux-amd64.tar.gz
cd linux-amd64/
#然后将新的helm二进制文件替换掉用户的二进制目录下的helm即可,这里我helm做过链接,所以替换的
#是/usr/bin/helm
mv ./helm /usr/bin/helm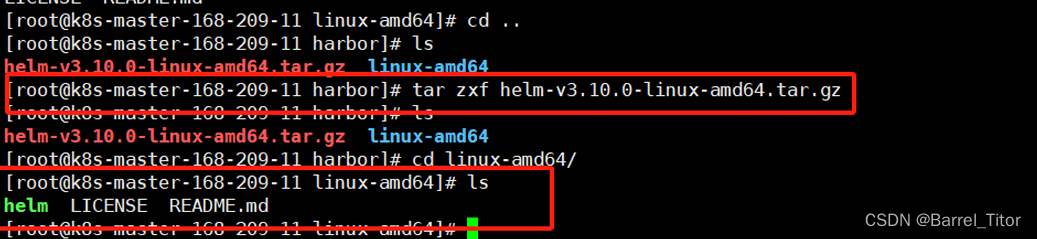
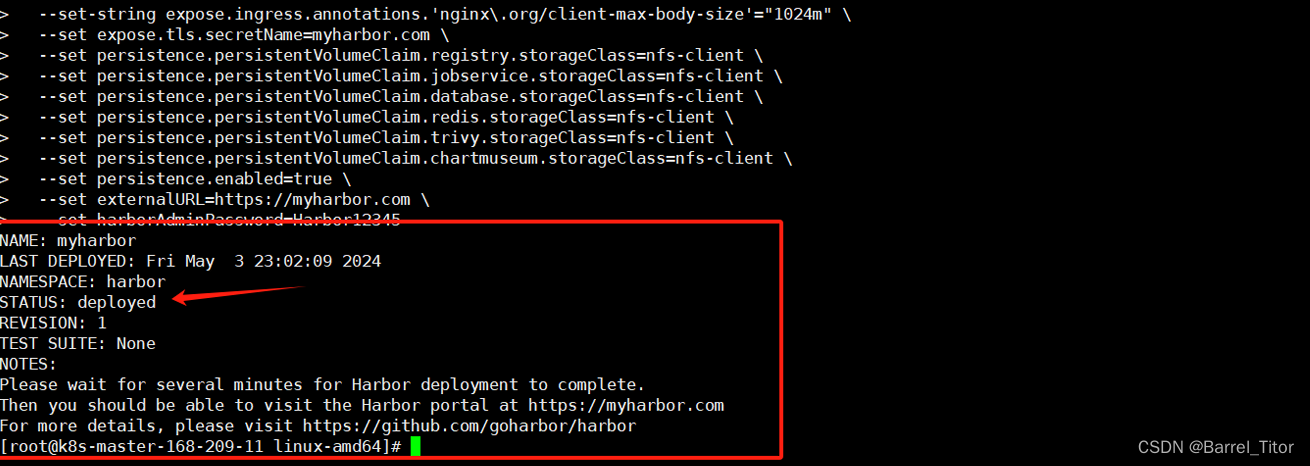
再次安装Harbor就可以看到部署成功了















 2178
2178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









