






 文章讲述了如何使用Prolog编写旅行路径查询(travel/2,travel/3)以及处理列表组合(combine1,combine2,combine3)的逻辑,包括子集和超集检查(mysubset,mysuperset),以及元素频率统计(frequencies)。
文章讲述了如何使用Prolog编写旅行路径查询(travel/2,travel/3)以及处理列表组合(combine1,combine2,combine3)的逻辑,包括子集和超集检查(mysubset,mysuperset),以及元素频率统计(frequencies)。
We are given the following knowledge base of travel information:
byCar(auckland,hamilton).
byCar(hamilton,raglan).
byCar(valmont,saarbruecken).
byCar(valmont,metz).
byTrain(metz,frankfurt).
byTrain(saarbruecken,frankfurt).
byTrain(metz,paris).
byTrain(saarbruecken,paris).
byPlane(frankfurt,bangkok).
byPlane(frankfurt,singapore).
byPlane(paris,losAngeles).
byPlane(bangkok,auckland).
byPlane(losAngeles,auckland).
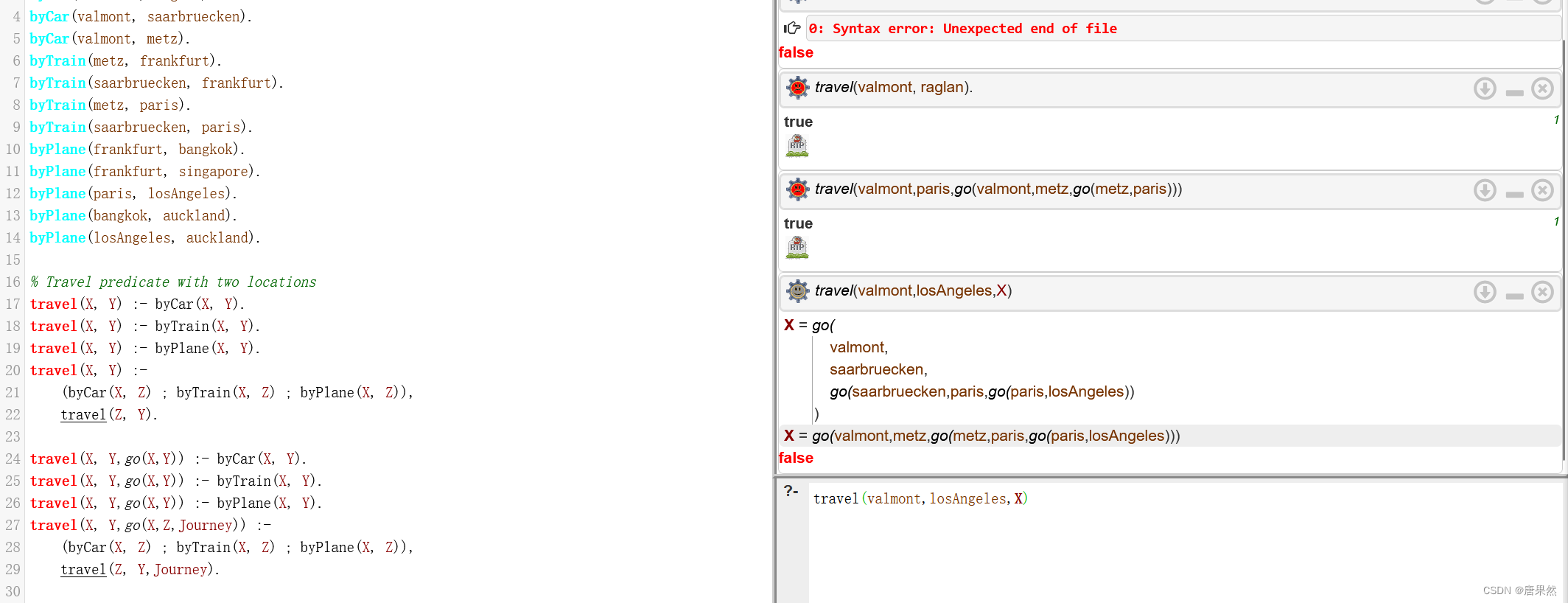
Write a predicate travel/2 which determines whether it is possible to travel from one place to another by ‘chaining together’ car, train, and plane journeys. For example, your program should answer ‘yes’ to the query travel(valmont,raglan).
% Travel predicate with two locations
travel(X, Y) :- byCar(X, Y).
travel(X, Y) :- byTrain(X, Y).
travel(X, Y) :- byPlane(X, Y).
travel(X, Y) :-
(byCar(X, Z) ; byTrain(X, Z) ; byPlane(X, Z)),
travel(Z, Y). 三个交通方式直接取并,然后再取交
So, by using travel/2 to query the above database, you can find out that it is possible to go from Vamont to Raglan. In case you are planning a travel, that’s already very good information, but what you would then really want to know is how exactly to get from Valmont to Raglan.
Write a predicate travel/3 which tells you how to travel from one place to another.
The program should, e.g., answer ‘yes’ to the query travel(valmont,paris,go(valmont,metz,go(metz,paris)))
and X = go(valmont,metz,go(metz,paris,go(paris,losAngeles))) to the query travel(valmont,losAngeles,X).
travel(X, Y,go(X,Y)) :- byCar(X, Y).
travel(X, Y,go(X,Y)) :- byTrain(X, Y).
travel(X, Y,go(X,Y)) :- byPlane(X, Y).
travel(X, Y,go(X,Z,Journey)) :-
(byCar(X, Z) ; byTrain(X, Z) ; byPlane(X, Z)),
travel(Z, Y,Journey).
*************找清楚递归规则很重要,同时注意,分号表示并,逗号表示交。
第二题:
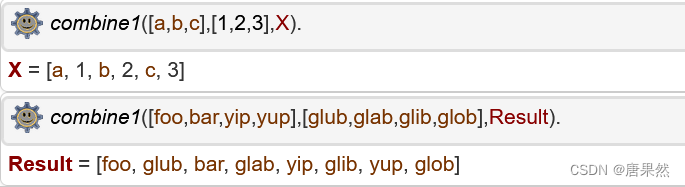
1. Write a 3-place predicate combine1 which takes three lists as arguments and
combines the elements of the first two lists into the third as follows:
?- combine1([a,b,c],[1,2,3],X).
X = [a,1,b,2,c,3]
?- combine1([foo,bar,yip,yup],[glub,glab,glib,glob],Result).
Result = [foo,glub,bar,glab,yip,glib,yup,glob]
combine1([], [], []).
combine1([X|Xs], [Y|Ys], [X,Y|Zs]) :-
combine1(Xs, Ys, Zs).
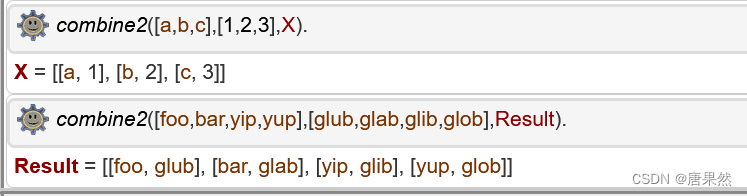
2. Now write a 3-place predicate combine2 which takes three lists as arguments
and combines the elements of the first two lists into the third as follows:
?- combine2([a,b,c],[1,2,3],X).
X = [[a,1],[b,2],[c,3]]
?- combine2([foo,bar,yip,yup],[glub,glab,glib,glob],Result).
Result = [[foo,glub],[bar,glab],[yip,glib],[yup,glob]]
combine2([], [], []).
combine2([X|Xs], [Y|Ys], [[X,Y]|Zs]) :-
combine2(Xs, Ys, Zs).
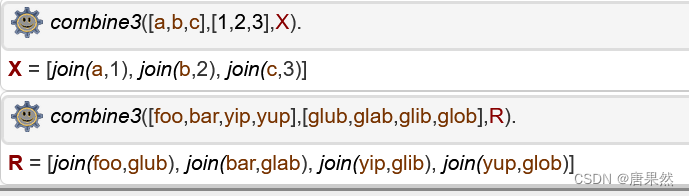
3. Finally, write a 3-place predicate combine3 which takes three lists as arguments
and combines the elements of the first two lists into the third as follows:
?- combine3([a,b,c],[1,2,3],X).
X = [join(a,1),join(b,2),join(c,3)]
?- combine3([foo,bar,yip,yup],[glub,glab,glib,glob],R).
R = [join(foo,glub),join(bar,glab),join(yip,glib),join(yup,glob)]
combine3([], [], []).
combine3([X|Xs], [Y|Ys], [join(X,Y)|Zs]) :-
combine3(Xs, Ys, Zs).
第三题:
1. Write a predicate mysubset/2 that takes two lists (of constants) as arguments and
checks, whether the first list is a subset of the second.
% Base case: an empty list is a subset of any list
mysubset([], _).
% Check if the first element of the first list is in the second list
mysubset([X|Xs], Y) :-
member(X, Y), 内置函数
mysubset(Xs, Y).
?-mysubset([a,b],[a,b,c]).
?-mysubset([d,e],[a,b,c]).

2. Write a predicate mysuperset/2 that takes two lists as arguments and checks,
whether the first list is a superset of the second.
% Base case: an empty list is a superset of any list
mysuperset(_, []).
% Check if the first element of the second list is in the first list
mysuperset(X, [Y|Ys]) :-
member(Y, X),
mysuperset(X, Ys).
?-mysuperset([a,b,c],[a,b]).
?-mysuperset([a,b,c],[d,e]).

第四题:
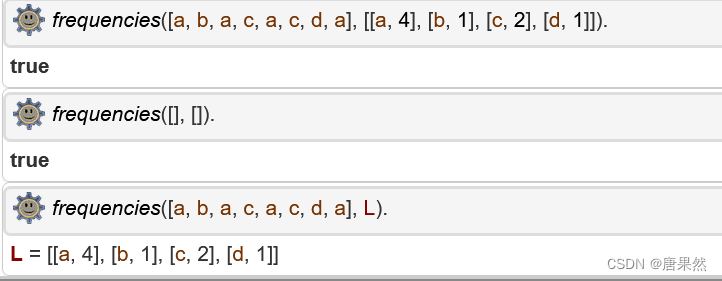
Write a Prolog program to implement the predicate frequencies(L,M), which takes as input a list L and returns a list of pairs [x,n], where x is an element of L and n is the number of times x appears in L. Here are some sample runs in SWI Prolog:
?- frequencies([a,b,a,c,a,c,d,a],L).
L = [[a, 4], [b, 1], [c, 2], [d, 1]]
Yes
?- frequencies([],L).
L = []
Yes
frequencies([],[]).
frequencies([H|Y],L) :-
frequencies(Y,L1),
check(H,L1,L).
check(H,[],[H,1]).
check(H,[[Y,K]|L],[[Y,K1]|L]):-
H = Y,
K1 is K +1.
check(H,[[Y,K]|L],[[Y,K]|M]) :-
H \== Y,
check(H,L,M).
check(H,[H,K],[H,K1]):- K1 is K +1.
check(H,[Y,K],[[Y,K]|[H,1]]) :-
H \== Y.
-
基本情况:
frequencies([], []).- 如果输入列表为空,频率列表也为空。
-
递归情况:
frequencies([H | Y], L) :- frequencies(Y, L1), check(H, L1, L).- 递归处理列表的尾部 (
Y) 并获取频率列表 (L1)。 - 调用
check/3谓词根据列表的头 (H) 更新频率列表 (L)。
-
check/3谓词:check(H, [], [H, 1]).- 如果列表为空,创建一个新列表
[H, 1],表示H的频率为 1。
- 如果列表为空,创建一个新列表
check(H, [[Y, K] | L], [[Y, K1] | L]) :- H = Y, K1 is K + 1.- 如果
H等于频率列表的头部,通过将K增加 1 来更新频率为K1。
- 如果
check(H, [[Y, K] | L], [[Y, K] | M]) :- H \== Y, check(H, L, M).- 如果
H与频率列表的头不同,保留当前头部并递归检查列表的其余部分 (L)。
- 如果
check(H, [H, K], [H, K1]) :- K1 is K + 1.- 如果频率列表只有一个元素
[H, K],通过将K增加 1 来更新频率为K1。
- 如果频率列表只有一个元素
check(H, [Y, K], [[Y, K] | [H, 1]]) :- H \== Y.- 如果元素
H与频率列表的头不同,创建一个新条目[H, 1]。
- 如果元素
总体而言,这个 Prolog 程序计算列表中每个元素的频率,并返回一个包含对 [元素, 频率] 的列表。check/3 谓词负责根据当前正在处理的元素更新频率列表。
第五题:
Assume that a binary tree is represented in Prolog using the function term
tree(X,LeftSubTree,RightSubTree)
where X is the element at any node and LeftSubTree and RightSubTree are the left sub-tree and the right sub-tree for the node respectively. The term nil is used when there is no left sub-tree or right-tree. For example, the following function term:
tree(20,tree(10,nil,nil),tree(40,tree(30,nil,nil),nil))
would represent the following binary (search) tree:
20
/ \
10 40
/
30
Recall that a binary search tree is a binary tree in which all the elements in the left sub-tree of a node are less than the element at the node and all the elements in the right sub-tree of a node are greater than the element at the node. Assume that the binary search tree is being used to represent a set of numbers with no duplicates. Write Prolog programs for the following predicates:
- smallest(X,T) is true if X is the smallest element in the binary search tree T.
- member(X,T) is true if X is an element in the binary search tree T.
- height(T,H) is true if H is the height of the binary search tree T where height is defined as the length of the longest path from root to leaf node.
Smallest/2:
排序树:
smallest([],[]).
smallest(X, tree(X, nil, nil)).
smallest(X, tree(_, Left, _)) :-
smallest(X, Left).
排序树只需要沿着左边找就是最小值。

Member/2:
member(X, tree(X, _, _)).
member(X, tree(Root, Left, _)) :-
X < Root,
member(X, Left).
member(X, tree(Root, _, Right)) :-
X > Root,
member(X, Right).

Height/2:
height(nil, 0).
height(tree(_, Left, Right), H1) :-
height(Left, LH),
height(Right, RH),
height(LeftSubTree,HL),
height(RightSubTree,HR),
max(HL,HR,H),
H1 is H +1.
max(HL,HR,HL):- HL >= HR.
max(HL,HR,HR):- HL < HR.




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











