






第一章
定义:网络爬虫是一种按照一定规则,自动抓取互联网信息的程序或者是脚本。
本质上是模拟浏览器打开网页,获取网页数据
1发送请求 2获取响应 3解析数据 4保存数据

万事开头难,第一步安装。
略(网上太多了,有错的话把错误粘到百度)
1发送请求
浏览器发送消息给网址所在的服务器(http请求)
包括
请求URL,请求方法,请求头,请求体
2获取响应
响应状态:状态代码
响应头部:内容长度/类型等
响应体:内容
3解析数据

4保存数据
提取数据-----.csv/json/db
Requests库
1安装
Cmd中打入
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple/
使用一下
import requests
res =requests.get("https://movie.douban.com/")#豆瓣
print(res.status_code)#状态码
成功截图:

代表安装成功,开始下一步!
分割-----------------
浏览下requests库方法:

- requests.request()
创建请求的通用方法
requests.request(method, url,**kwargs)

**kwargs一些参数
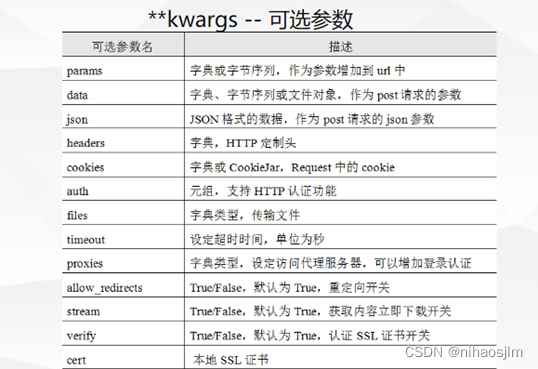
表中headers参数可设置为浏览器信息User Agent来模拟浏览器发送请求,User Agent(用户代理,简称UA)
服务器通过查看headers中的UA来判断是谁在访问。某些网站如豆瓣网必须设置UA信息才能进行访问。
UA可以进行伪装,Python允许用户修改User Agent来模拟浏览器访问,即伪装成浏览器,从而隐藏自己是爬虫程序的身份。
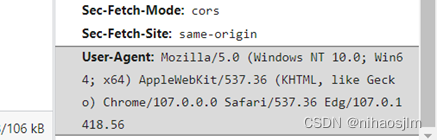
可选参数headers-UA获取
F12:进入开发者模式 /右键找到检查

单击网络->单击XHR ->选中get.ashx ->标头 ->User-Agent
点击Network或网络
切换完毕后,按F5刷新,重新加载资源。(之前没刷新也是什么也没有)
重新加载后选择筛选XHR资源(注意看这个Fetch/HXR)
!没有找到xhr,搜索得知
为什么天猫,京东等,网站控制台network中看不到xhr请求?
都走jsonp因为接口调用五花八门 都走cors的话 配allow origin都配不完
 headers-UA获取
headers-UA获取
1通过requests.request()方法,伪装浏览器且以get方式访问百度首页数据的代码如下:
import requests
#导包
header = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 "
"Safari/537.36 Edg/107.0.1418.56"}
#上面获取得的User-Agent
url = "https://www.baidu.com/"
#url地址
res = requests.request('get', url, headers=header)
#get方法请求,请求头的ua信息
print(res.text)
#以text打印
运行截图:
2使用requests库中的get方法
requests.get()方法 获取网页最常用的方式,该方法的语法格式如下:
requests.get(url,params=None,**kwargs)

import requests
params = {'spam': 1, 'eggs': 2, 'bacon': 0}
res = requests.get('http://www.musi-cal.com/cgi-bin/query',params)
res.text[:10]
练习一下
import requests
url = 'https://www.baidu.com/'
res = ----------
print(res.text)
答案requests.get(url)
增加**kwargs中的headers参数,示例如下:
import requests
params = {'spam': 1, 'eggs': 2, 'bacon': 0}
header={'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"}
res = requests.get('http://www.musi-cal.com/cgi-bin/query',params,headers=header)
print(res.text)
调用get()方法后,返回的网页内容保存为一个Response对象:
import requests
res = requests.get("https://www.baidu.com/") #获取
print(type(res))
# 返回Response类型的对象
图:

和浏览器的交互过程一样,requests.get()代表请求过程,返回的Response对象代表响应,返回的内容作为一个对象便于操作,Response对象的主要属性如下表:

例子res.status_code # 返回状态
200
除了属性,response对象还提供一些方法,如下表:

其中json()方法能够在HTTP响应内容中解析存在的json数据,如下代码所示:
import requests
url = 'https://touch.dujia.qunar.com/depCities.qunar'
strhtml = requests.get(url) # 获取出发地站点信息
print(strhtml.text) #返回json数据
dep_dict = strhtml.json()#解析json数据,返回字典格式
print(dep_dict)
for dep_item in dep_dict['data']: #dep_item即是a/b/c等
for dep in dep_dict['data'][dep_item]:
print(dep)#打印出发地
运行截图

raise_for_status()方法能在非成功响应后产生异常,这时可引入异常处理机制try...except.

通过requests库获取一个网页的通用代码框架如下:
import requests
def getHTMLText(url):
try:
r = requests.get(url,timeout = 30) # 设置超时时长为30秒
r.raise_for_status() # 如果HTTP响应状态码不是200,则产生异常
r.encoding = r. apparent_encoding #设置编码方式,避免乱码
return r.text # 返回响应内容字符串
except:
return "产生异常"
#测试
url="https://www.baiu.com/" #https://www.baidu.com/
print(getHTMLText(url))
运行截图
3、requests.post()方法 用于向指定url提交表单数据,该方法的语法格式如下:

import requests
params = {'spam': 1, 'eggs': 2, 'bacon': 0}
res = requests.post("http://www.musi-cal.com/cgi-bin/query", data=params)# 上传的数据,字典形式
print(res.text)
res= requests.post("http://httpbin.org/post",data = "helloWorld")#上传的数据,字符串形式
print(res.text)
练习
>>>import requests
>>>import json
>>>url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' >>>form_data = {'i':’我爱中国’, ...} #form_data为请求表单数据
>>>response =______________(____________,data= ____________)
>>>res = json.loads(response.text) >>>print(res)
答案:requests.post url form_data
实现任务:获取豆瓣网电影板块 (1.0版)https://movie.douban.com/cinema/nowplaying/whan 武汉正热映的页面数据。
import requests
def getMoviesHtmlTextRequests(url):
header={'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"}
try:
res = requests.get(url,headers=header)
res.raise_for_status()
res.encoding = res.apparent_encoding
text= res.text
return text
except:
return "获取电影数据失败"
url = 'https://movie.douban.com/cinema/nowplaying/wuhan/'
print(getMoviesHtmlTextRequests(url))
豆瓣网电影板块https://movie.douban.com/cinema/nowplaying/wuhan/主要展示了武汉市正在上映的电影,如何获取该网页数据呢?
除了上述第三方库requests可以获取网页数据, 还可以使用Python内置的urllib库来实现。
requests库是基于urllib封装而成的第三方库,十分便捷而受到青睐,但是urllib是内置库,对远程网页的操作更像操作本地文件一样,易于理解。
下一day通过urllib库获取网页数据
1day的总结
首先是在f12查看那个开发者工具时找不到XHR资源
我是没有注意到Fetch/HXR还有有的网站可能木有
还要f5刷新下才出来
然后是requests的get/post方法,在复现代码时候倒是没有什么错误,无非是库的导入什么的,不过这个过程,这个还是需要进一步练习才熟悉的。
还有一些细节的东西 例如抛出异常的结构 等等,也需要自己琢磨
计划在近几天完成day2和day1的复习
还有对于安卓开发项目启动准备,
回想一下大学前两年,学习的东西忘掉的差不多,
。。。无了,等待更新和修改















 3704
3704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









