







🎉个人主页:这个昵称我想了20分钟
✨往期专栏:【速成之路】jQuery
🎖️专栏:【速成之路】SQL server
🔓往期回顾:
【SQL server速成之路】数据库基础
【SQL server速成之路】数据库和表(一)
【SQL server速成之路】数据库和表(二)
数据库的查询

🎆单表查询
当用户登录到SQL Server后,即被指定一个缺省数据库,通常是master数据库。使用USE语句可以选择当前要操作的数据库。
语法格式:
USE <数据库名称>
例如,要选择xsbook为当前数据库,使用语句:
USE xsbook
一旦选择了当前数据库后,若对操作的数据库对象加以限定,则其后的命令均是针对当前数据库中的表或视图等进行的。
下面介绍SELECT语句,SELECT语句很复杂,其基本的语法如下:
SELECT select_list /*指定要选择的列或行及其限定*/
[ INTO new_table ] /*INTO子句,指定结果存入新表*/
FROM table_source /*FROM子句,指定表或视图*/
[ WHERE search_condition ] /*WHERE子句,指定查询条件*/
[ GROUP BY group_by_expression ] /*GROUP BY子句,指定分组表达式*/
[ HAVING search_condition ] /*HAVING子句,指定分组统计条件*/
[ ORDER BY order_expression [ ASC | DESC ]] /*ORDER子句,指定排序表达式和顺序*/
1.选择列
选择表中的部分或全部列组成结果表,通过SELECT语句的SELECT子句来表示。SELECT子句的格式为:
SELECT [ ALL | DISTINCT ] [ TOP n [ PERCENT ] [ WITH TIES ] ] <select_list>
其中select_list指出了结果的形式,select_list的格式为:
{ * /*选择当前表或视图的所有列*/
| { <表名> | <视图名> | <表的别名> } . * /*选择指定的表或视图的所有列*/
| { <列名> | <表达式> | $IDENTITY }
[ [ AS ] <列的别名> ] /*选择指定的列*/
| column_alias = expression /*选择指定列并更改列标题*/
} [ , … n ]
(1)选择一个表中指定的列
使用SELECT语句选择一个表中的某些列,各列名之间要以逗号分隔,格式如下:
SELECT <列名1> [ , <列名2>…]
FROM <表名>
WHERE search_condition
其功能是在FROM子句指定的表中检索符合search_condition条件的列。
【例】 查询xsbook数据库的xs表中各个同学的姓名、专业和借书量。
USE xsbook
SELECT 姓名,专业, 借书量
FROM xs
执行结果如图所示。

(2)查询全部列
当在SELECT语句指定列的位置上使用*号时,表示查询表的所有列。
【例】 查询xs表中的所有列。
SELECT *
FROM xs
该语句等价于语句:
SELECT 借书证号, 姓名,性别, 出生时间, 专业,借书量, 照片
FROM xs
其执行后将列出xs表中的所有数据,如图所示。

(3)修改查询结果中的列标题
当希望查询结果中的某些列或所有列显示时使用自己选择的列标题时,可以在列名之后使用AS子句来更改查询结果的列标题名。AS子句的格式为:
AS column_alias
其中column_alias是指定的列标题。
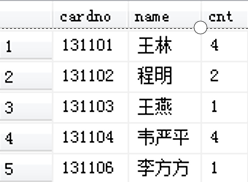
【例】 查询xs表中计算机系同学的借书证号、姓名和借书量,结果中各列的标题分别指定为cardno、name和cnt。
SELECT 借书证号 AS cardno, 姓名 AS name, 借书量 AS cnt
FROM xs
WHERE 专业= '计算机'
该语句的执行结果如图所示。
更改查询结果中的列标题也可以使用column_alias=expression的形式。例如:
SELECT cardno =借书证号, name = 姓名, cnt =借书量
FROM xs
WHERE 专业= '计算机'
该语句的执行结果与上例的结果完全相同。
注意,当自定义的列标题中含有空格时,必须使用引号将标题括起来。例如:
SELECT 'Card no' = 借书证号, 姓名 AS 'Student name', cnt = 借书量
FROM xs
WHERE 专业= '计算机'
(4)替换查询结果中的数据
在对表进行查询时,有时对所查询的某些列希望得到的是一种概念而不是具体的数据。例如查询xs表的借书量,所希望知道的是借书量多还是少的情况,这时,就可以用等级来替换借书量的具体数字。
要替换查询结果中的数据,则要使用查询中的CASE表达式,格式为:
CASE
WHEN 条件1 THEN 表达式1
WHEN 条件2 THEN 表达式2
……
ELSE 表达式
END
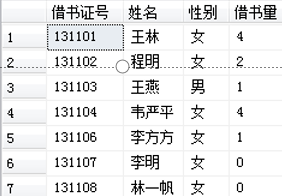
【例】 查询xs表中各同学的借书证号、姓名、性别和借书量,对其性别按以下规则替换:若性别为0,替换为“男”;为1,替换为“女”。所用的SELECT语句为:
SELECT 借书证号, 姓名, 性别=
CASE
WHEN 性别= '0' THEN '男'
WHEN 性别= '1' THEN '女'
END, 借书量
FROM xs
执行结果如图所示:
(5)查询经过计算的值
使用SELECT对列进行查询时,不仅可以直接以列的原始值作为结果,而且还可以将对列值进行计算后所得的值作为查询结果,即SELECT子句可使用表达式作为结果。
要查询经过计算的值,在SELECT之后的目标列的格式为表达式:
SELECT <表达式> [ , <表达式> ]
【例】 查询图书表中库存图书的价值。
SELECT 书名, 库存图书价值=库存量*价格
FROM book
该语句的执行结果如图所示:

2. 选择行
选择表中的部分或全部行作为查询的结果。
(1)消除结果集中的重复行
对于关系数据库来说,表中的每一行都必须是不相同的。但当我们对表只选择其中的某些列时,就可能会出现重复行。例如,若对xsbook数据库的jy表只选择借书证号和ISBN时,就出现多行重复的情况。
在SELECT语句中使用DISTINCT关键字可以消除结果集中的重复行,其格式是:
SELECT DISTINCT <列名> [ , <列名>…]
其中关键字DISTINCT的含义是对结果集中的重复行只选择一个,保证行的惟一性。
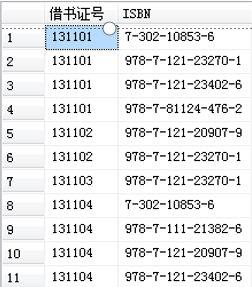
【例】 对xsbook数据库的jy表只选择借书证号和ISBN列,消除结果集中的重复行。
SELECT DISTINCT 借书证号, ISBN
FROM jy
该语句的执行结果如图所示。
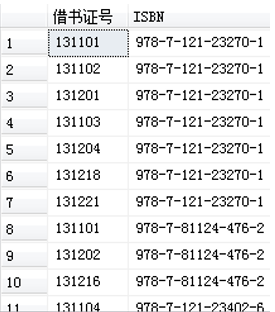
以下的SELECT语句对xsbook数据库的jy表只选择借书证号和ISBN列,不消除结果集中的重复行。(没有给出DISTINCT 或ALL时,默认为ALL)
SELECT ALL 借书证号, ISBN
FROM jy
该语句执行结果如图所示。
(2)限制结果集的返回行数
可以使用TOP选项限制查询结果集返回的行数。TOP选项的基本格式为:
TOP n [ PERCENT ]
其中n是一个正整数,表示返回查询结果集的前n行。若带PERCENT关键字,则表示返回结果集的前n%行。例如下列语句将返回jy表的前10行:
SELECT TOP 10 *
FROM jy
该语句执行后结果结果如图所示。

(3)查询满足条件的行
查询满足条件的行可以通过WHERE子句实现。WHERE子句给出查询条件,该子句必须紧跟FROM子句之后,其基本格式为:
WHERE <search_condition>
其中search_condition为查询条件,格式为:
{ [ NOT ] <precdicate> | (<search_condition> ) }
[ { AND | OR } [ NOT ] { <predicate> | (<search_condition>) } ]
} [ ,…n ]
其中predicate为判定运算,结果为TRUE、FALSE或UNKNOWN,NOT表示对判定的结果取反,AND用于组合两个条件,两个条件都为TRUE时值才为TRUE。OR也用于组合两个条件,两个条件有一个条件为TRUE时值就为TRUE。
<predicate>格式为:
{ expression { = | < | <= | > | >= | <> | != | !< | !> } expression /*比较运算*/
| string_expression [ NOT ] LIKE string_expression [ ESCAPE ‘escape_character’ ] /*字符串模式匹配*/
| expression [ NOT ] BETWEEN expression AND expression /*指定范围*/
| expression IS [ NOT ] NULL /*是否空值判断*/
| expression [ NOT ] IN ( subquery | expression [,…n] ) /*IN子句*/
| expression { = | < | <= | > | >= | <> | != | !< | !> } { ALL | SOME | ANY } ( subquery )
/*比较子查询*/
| EXIST ( subquery ) /*EXIST子查询*/
}
从查询条件的构成可以看出,可以将多个判定运算的结果通过逻辑运算符再组成更为复杂的查询条件。判定运算包括比较运算、模式匹配、范围比较、空值比较和子查询。其中的IN关键字既可以指定范围,也可以表示子查询。为使读者更清楚地了解查询条件,将WHERE子句的查询条件列于下表中。

① 表达式比较
比较运算符用于比较两个表达式值,共有9个,分别是:=(等于)、<(小于)、<=(小于等于)、>(大于)、>=(大于等于)、<>(不等于)、!=(不等于)、!<(不小于)、!>(不大于)。比较运算的格式为:
expression { = | < | <= | > | >= | <> | != | !< | !> } expression
其中expression是除text、ntext和image之外类型的表达式。
【例】 查询xsbook数据库xs表中借书量不小于3本以上的学生情况。
SELECT *
FROM xs
WHERE 借书量 !< 3
执行结果如图所示。

② 指定范围
用于范围比较的关键字有两个:BETWEEN和NOT BETWEEN,用于查找字段值在(或不在)指定范围的行。BETWEEN(NOT BETWEEN)关键字格式为:
expression [ NOT ] BETWEEN expression1 AND expression2
其中BETWEEN关键字之后是范围的下限(即低值),AND关键字之后是范围的上限(即高值)。
【例】 查询xs表中出生时间在“1995-1-1”与“1996-12-31”之间的学生情况。
SELECT *
FROM xs
WHERE 出生时间 BETWEEN '1995-1-1' AND '1996-12-31'
③ 确定集合
使用IN关键字可以指定一个值表集合,值表中列出所有可能的值,当表达式与值表中的任一个匹配时,即返回TRUE,否则返回FALSE。使用IN关键字指定值表集合的格式为:
expression IN ( expression [,…n])
【例】 查询xs表中专业为“计算机”、“信息工程”、“英语”或“自动化”的学生的情况。
SELECT *
FROM xs
WHERE 专业 IN ('计算机','信息工程','英语','自动化')
与IN相对的是NOT IN,用于查找列值不属于指定集合的行。例如,以下语句查找既不是“计算机”、“信息工程”、“英语”,也不是“自动化”专业的学生的情况:
SELECT *
FROM xs
WHERE 专业 NOT IN ('计算机','信息工程','英语','自动化')
④ 字符匹配
LIKE谓词用于进行字符串的匹配,其运算对象可以是char、varchar、text、ntext、datetime和smalldatetime类型的数据,返回逻辑值TRUE或FALSE。LIKE谓词表达式的格式为:
string_expression [ NOT ] LIKE string_expression [ ESCAPE ‘%’ | ‘_’ ]
其含义是查找指定列值与匹配串相匹配的行。
【例】 查询xs表中计算机系的学生情况。
SELECT *
FROM xs
WHERE 专业 LIKE '计算机'
下面的SELECT语句与上面的语句等价:
SELECT *
FROM xs
WHERE 专业 = '计算机'
⑤ 空值比较
当需要判定一个表达式的值是否为空值时,使用IS NULL关键字,格式为:
expression IS [ NOT ] NULL
当不使用NOT时,若表达式expression的值为空值,返回TRUE,否则返回FALSE;当使用NOT时,结果刚好相反。
【例】 查询学生借书数据库xs表中专业尚不定的学生情况。
SELECT *
FROM xs
WHERE 专业 IS NULL
⑥ 多重条件查询
逻辑运算符AND和OR可用来联结多个查询条件。AND的优先级高于OR,但使用括号可以改变优先级。
【例】 查询计算机专业、借书量在3本以下的学生姓名和借书证号。
SELECT 借书证号,姓名
FROM xs
WHERE 专业='计算机' AND 借书量<3
(4)对查询结果排序
在应用中经常要对查询的结果排序输出,例如按借书的数量对学生排序、按价格对书进行排序等等。SELECT语句的ORDER BY子句可用于对查询结果按照一个或多个字段的值进行升序(ASC)或降序(DESC)排列,默认值为升序。ORDER BY子句的格式为:
[ ORDER BY { order_by_expression [ ASC | DESC ] } [ ,…n ]
其中,order_by_expression是排序表达式,可以是列名、表达式或一个正整数,当expression是一个正整数时,表示按表中该位置上的列排序。
(5)使用聚合函数(用于统计)
对表数据进行检索时,经常需要对结果进行计算或统计,例如在图书管理数据库中求学生借书的总数、统计各书的价值等。T-SQL提供了一些聚合函数(也称集函数)用来增强检索功能。聚合函数用于计算表中的数据,返回单个计算结果。SQL Server 2012所提供常用的聚合函数列于下表中。

① SUM和AVG
SUM和AVG分别用于求表达式中所有值项的总和与平均值,语法格式为:
SUM / AVG ( [ ALL | DISTINCT ] expression )
其中,expression是常量、列、函数或表达式,其数据类型只能是以下类型:int、smallint、tinyint、bigint、decimal、numeric、float、real、money和smallmoney。
② MAX和MIN
MAX和MIN分别用于求表达式中所有值项的最大值与最小值,语法格式为:
MAX / MIN ( [ ALL | DISTINCT ] expression )
其中expression是常量、列、函数或表达式,其数据类型可以是数字、字符和时间日期类型。
③ COUNT
COUNT用于统计组中满足条件的行数或总行数,格式为:
COUNT ( { [ ALL | DISTINCT ] expression } | * )
其中,expression是一个表达式,其数据类型是除uniqueidentifier、text、image或ntext之外的任何类型。COUNT(*)统计总行数。 COUNT忽略空值。
④ GROUPING
GROUPING函数为输出的结果表产生一个附加列,该列的值为1或0,格式为:
GROUPING ( column_name )
当用CUBE或ROLLUP运算符添加行时,附加的列输出值为1,当所添加的行不是由CUBE或ROLLUP产生时,附加列值为0。
(6)对查询结果分组(用于分组统计)
SELECT语句的GROUP BY子句用于将查询结果按某一列或多列值进行分组,值相等的为一组。对查询结果分组的主要目的是为了细化聚合函数的作用对象。
GROUP BY子句的格式为:
[ GROUP BY [ ALL ] group_by_expression [,…n]
[ WITH { CUBE | ROLLUP } ] ]
其中,group_by_expression是用于分组的表达式,其中通常包含字段名。指定ALL将显示所有组。
(7) HAVING子句
如果分组后还需要按一定的条件对这些组进行筛选,最终只输出满足指定条件对组,那么使用having子句指定筛选条件。
HAVING子句的格式为:
[ HAVING <search_condition> ]
其中,search_condition为查询条件,与WHERE子句的查询条件类似,并且可以使用聚合函数。
🎆连接查询
若一个查询同时涉及两个或多个表,则称为连接查询。查询结果通常是含有参加连接运算的两个表或多个表的指定列的表。
1.连接谓词
可以在SELECT语句的WHERE子句中使用比较运算符给出连接条件对表进行连接,将这种表示形式称为连接谓词表示形式。连接谓词又称为连接条件,其一般格式为:
[<表名1.>] <列名1> <比较运算符> [<表名2.>] <列名2>
其中,比较运算符主要有:<、<=、=、>、>=、!=、<>、!<和!>,当比较符为“=”时,就是等值连接。若在目标列中去除相同的字段名,则为自然连接。此外,连接谓词还可以采用以下形式:
[<表名1.>] <列名1> BETWEEN [<表名2.>] <列名2>AND[<表名2.>] <列名3>
连接谓词中的列名称为连接字段。
2.以JOIN关键字指定的连接
T-SQL扩展了以JOIN关键字指定连接的表示方式,使表的连接运算能力有了增强。JOIN连接在FROM子句的< joined_table >中指定,格式如下:
<joined_table> ::=
{
<table_source> <join_type> <table_source> ON <search_condition>
| <table_source> CROSS JOIN <table_source>
| <joined_table>
}
说明:<join_type>表示连接类型,ON用于指定连接条件。<join_type>的格式为:
[ INNER | { LEFT | RIGHT | FULL } [ OUTER ] [ <join_hint> ] JOIN

(1)内连接
内连接按照ON所指定的连接条件合并两个表,返回满足条件的行。
【例】 查找xsbook数据库每个学生的情况以及借阅的图书情况。
SELECT *
FROM xs INNER JOIN jy ON xs.借书证号 = jy.借书证号
结果表将包含xs表和jy表的所有字段(不去除重复字段—借书证号)。Inner可以省略。
(2)外连接
外连接包括3种:
- 左外连接(LEFT OUTER JOIN):结果表中除了包括满足连接条件的行外,还包括左表的所有行;
- 右外连接(RIGHT OUTER JOIN):结果表中除了包括满足连接条件的行外,还包括右表的所有行;
- 完全外连接(FULL OUTER JOIN):结果表中除了包括满足连接条件的行外,还包括两个表的所有行。
outer关键字可以省略;外连接只能对两个表进行。
【例】 查找所有学生情况,及他们借阅图书的索书号,若学生未借阅任何图书,也要包括其情况。
SELECT xs.* , 索书号
FROM xs LEFT OUTER JOIN jy ON xs.借书证号 = jy.借书证号
本例执行时,若有学生未选任何课程,则结果表中相应行的课程号字段值为NULL。执行结果如图所示。

(3)交叉连接
交叉连接实际上是将两个表进行拼接,结果表是由第一个表的每行与第二个表的每一行拼接后形成的表,因此结果表的行数等于两个表行数之积。
【例】 列出学生所有可能的借书情况。
SELECT 借书证号,姓名,ISBN,书名
FROM xs CROSS JOIN book
🎆嵌套查询
在SQL语言中,一个SELECT-FROM-WHERE语句称为一个查询块。在WHERE子句或HAVING子句所表示的条件中,可以使用另一个查询的结果(即一个查询块)作为条件的一部分,例如判定列值是否与某个查询的结果集中的值相等,这种将一个查询块嵌套在另一个查询块的WHERE子句或HAVING子句的条件中的查询称为嵌套查询。例如:
SELECT 姓名
FROM xs
WHERE 借书证号 IN
( SELECT 借书证号
FROM jy
WHERE ISBN='978-7-111-21382-6'
)
1.IN子查询
在嵌套查询中,子查询的结果往往是一个集合,所以IN是嵌套查询中最常使用的谓词。IN子查询用于进行一个给定值是否在子查询结果集中的判断,格式为:
expression [ NOT ] IN ( subquery )
其中,subquery是子查询。当表达式expression与子查询subquery的结果表中的某个值相等时,IN谓词返回TRUE,否则返回FALSE;若使用了NOT,则返回的值刚好相反。
2.比较子查询
比较子查询是指父查询与子查询之间用比较运算符进行关联。如果我们能够确切地知道子查询返回的是单个值时,就可以使用比较子查询。这种子查询可以认为是IN子查询的扩展,它使表达式的值与子查询的结果进行比较运算,格式为:
expression { < | <= | = | > | >= | != | <> | !< | !> } { ALL | SOME | ANY } ( subquery )
其中,expression为要进行比较的表达式,subquery是子查询。ALL、SOME和ANY说明对比较运算的限制。
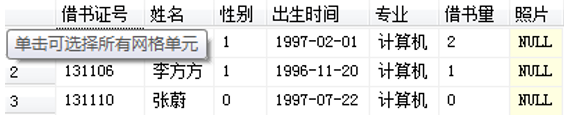
【例】 查找其他专业比所有通信工程专业的学生年龄都小的学生。
SELECT *
FROM xs
WHERE 专业<>'通信工程' AND 出生时间 > ALL
( SELECT 出生时间
FROM xs
WHERE 专业 = '通信工程'
)
该语句的执行结果如图所示:
3.EXISTS子查询
EXISTS谓词用于测试子查询的结果是否为空表,若子查询的结果集不为空,则EXISTS返回TRUE,否则返回FALSE。EXISTS还可与NOT结合使用,即NOT EXISTS,其返回值与EXIST刚好相反。格式为:
[ NOT ] EXISTS ( subquery )
【例】 查找借阅了ISBN为978-7-111-21382-6图书的学生姓名。
分析:本查询涉及xs和jy表,我们可以在xs表中依次取每一行的“借书证号”值,用此值去检查jy表。若jy表中存在“借书证号”值等于xs.借书证号的值,并且其ISBN等于“978-7-111-21382-6”,那么就取该行的xs.姓名值送入结果表。将此思路表述为SQL语句:
SELECT 姓名
FROM xs
WHERE EXISTS
( SELECT *
FROM jy
WHERE 借书证号 = xs.借书证号 AND ISBN = '978-7-111-21382-6'
)
🎆SELECT查询的其他子句
1.FROM子句
FROM子句指定用于SELECT的查询对象,其格式为:
[ FROM {<table_source>} [,…n] ]
其中<table_source>指出了要查询的表或视图。
<table_source> ::=
{
<表名或视图名> [ [ AS ] <表别名> ] /*查询表或视图,可指定别名*/
| derived_table [ AS ] table_alias [ ( column_alias [ ,...n ] ) ] /*子查询*/
| <joined_table> /*连接表*/
| <pivoted_table> /*将行转换为列*/
| <unpivoted_table> /*将列转换为行*/
}
说明:
(1)AS:AS选项为表指定别名,可以省略。表别名主要用于相关子查询及连接查询中。
(2)derived_table:derived_table是由SELECT查询语句的执行而返回的表,必须使用为其指定一个别名,也可以为列指定别名。
(3)joined_table
joined_table为连接表。
(4)pivoted_table和unpivoted_table
<pivoted_table>的格式如下:
<pivoted_table> ::=
table_source PIVOT <pivot_clause> [AS] <表别名>
其中:
<pivot_clause> ::=
( <聚合函数名> (<列名> ) FOR pivot_column IN (<column_list>) )
2.INTO子句
使用INTO子句可以将SELECT查询所得的结果保存到一个新建的表中。INTO子句的格式为:
[ INTO <表名> ]
包含INTO子句的SELECT语句执行后所创建的表的结构由SELECT所选择的列决定,新创建的表中的记录由SELECT的查询结果决定,若SELECT的查询结果为空,则创建一个只有结构而没有记录的空表。
【例】 由xs表创建“计算机系学生借书证”表,包括借书证号和姓名。
SELECT 借书证号,姓名
INTO 计算机系学生借书证
FROM xs
WHERE 专业= '计算机'
3.UNION子句
使用UNION子句可以将两个或多个SELECT查询的结果合并成一个结果集,其格式为:
{ <query specification> | (<query expression> ) }
UNION [ A LL ] <query specification> | (<query expression> )
[ UNION [ A LL ] <query specification> | (<query expression> ) […n] ]
其中,query specification和query expression都是SELECT查询语句。
使用UNION组合两个查询的结果集的基本规则是:
① 所有查询中的列数和列的顺序必须相同。
② 数据类型必须兼容。
4.EXCEPT 和 INTERSECT
EXCEPT和INTERSECT用于比较两个查询的结果,返回非重复值。语法格式如下:
{ <query_specification> | ( <query_expression> ) }
{ EXCEPT | INTERSECT }
{ <query_specification> | ( <query_expression> ) }
其中和都是SELECT查询语句。
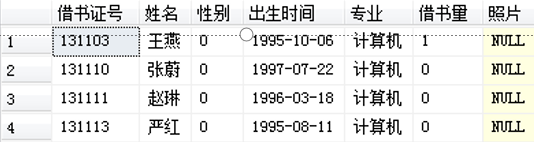
【例】 查找专业为计算机但性别不为男的学生信息。
SELECT * FROM xs WHERE 专业= '计算机'
EXCEPT
SELECT * FROM xs WHERE 性别=1
执行结果如图所示。
5.CTE
在SELECT语句的最前面可以使用一条WITH子句来指定临时结果集,语法格式如下:
[ WITH <common_table_expression> [ ,...n ] ]
其中:
<common_table_expression>::=
expression_name [ ( column_name [ ,...n ] ) ]
AS ( CTE_query_definition )
说明:临时命名的结果集也称为公用表值表达式(Common Table Expression,简称CTE),CTE用于存储一个临时的结果集,在SELECT、INSERT、DELETE、UPDATE或CTEATE VIEW语句中都可以建立一个CTE。
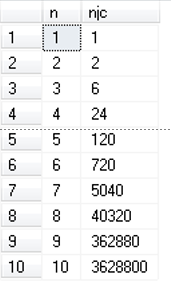
【例】 计算数字1-10的阶乘。
WITH MyCTE(n,njc)
AS (
SELECT n=1, njc=1
UNION ALL
SELECT n=n+1, njc=njc*(n+1)
FROM MyCTE
WHERE n<10
)
SELECT n, njc FROM MyCTE
执行结果如图所示。

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











