






-
摘要:建模用户的长期兴趣和短期兴趣对精准推荐非常关键,但是,由于没有针对用户兴趣的手工注释标签,现有方法总是遵循将这两种方面纠缠在一起的范式,这可能导致推荐准确性和可解释性较差。在本文中,为了解决这个问题,我们提出了一个对比学习框架,用自监督将用于推荐的长期兴趣和短期兴趣解耦。具体来说,首先提出两个独立的编码器来独立捕获不同时间尺度的用户兴趣;然后从交互序列中提取长期和短期兴趣代理,作为用户兴趣的伪标签;然后设计成对对比任务来监督兴趣表示与其相应的兴趣代理之间的相似性;最后,由于长期和短期兴趣的重要性是动态变化的,我们提出通过基于注意力的网络自适应聚合它们进行预测。
-
背景及动机:建模用户的长期兴趣和短期兴趣对精准推荐非常关键,但由没有用于标识用户兴趣的手工注释标签,使得这两方面纠缠在一起用于推荐,这可能导致推荐准确性和可解释性较差
-
应对策略:通过对比学习,构建自监督学习任务来解耦用户的长短期兴趣,在推荐时给予这两个方面不同的注意力/权重。
-
一些观点:
-
用户的兴趣难以追踪,因为他们往往既有稳定的长期兴趣,又有动态的短期兴趣。例如,精通技术的用户可能总是愿意浏览电子产品(长期兴趣),而他也可能在短时间内表现出对服装的兴趣(短期兴趣)。因此,准确地建模和区分用户的长期和短期兴趣至关重要。
-
解耦长短期兴趣面临一些挑战:①长短期兴趣反应了用户偏好的不同方面(长期兴趣可以视为用户长期保持稳定的整体偏好,而短期兴趣则表示用户根据最近的交互而快速演变的动态偏好),因此学习长短期兴趣的统一表示不足以捕获这种差异,相反将两个方面分开建模更为合适。②缺乏学习相应兴趣表示的label。③最后预测用户可能的交互的时候,两种兴趣都应该考虑在内,但是两种兴趣的重要性因不同的用户-项目交互而异。
-
当用户持续浏览相似的项目时,短期兴趣更为重要,而当用户切换到截然不同的项目时,其行为很大程度上受长期兴趣所驱动。因此自适应地融合这两个方面来预测未来的相互作用是至关重要的但具有挑战性。
-
解耦是有益的,有助于实现可解释和可控的推荐,因为可以通过调整融合权重来跟踪和调整每个方面的重要性。以线性为例:假设长短期兴趣纠缠在一起

最后的融合权重0.56、0.44和期望的融合权重0.8、0.2有很大差异。
-
-
目标任务:
个用户,
个项目
所有用户的交互序列
- 特定用户 $u$ 的交互序列由一系列交互过的项目按时间先后排列:
表示用户
的交互历史的长度
- 每个项目
都在 [1, N] 中
-
方法概述及框架:对比学习+注意力机制+CLSR框架
解耦用户长短期兴趣
用户兴趣建模
将用户兴趣建模为一下三个独立的机制:
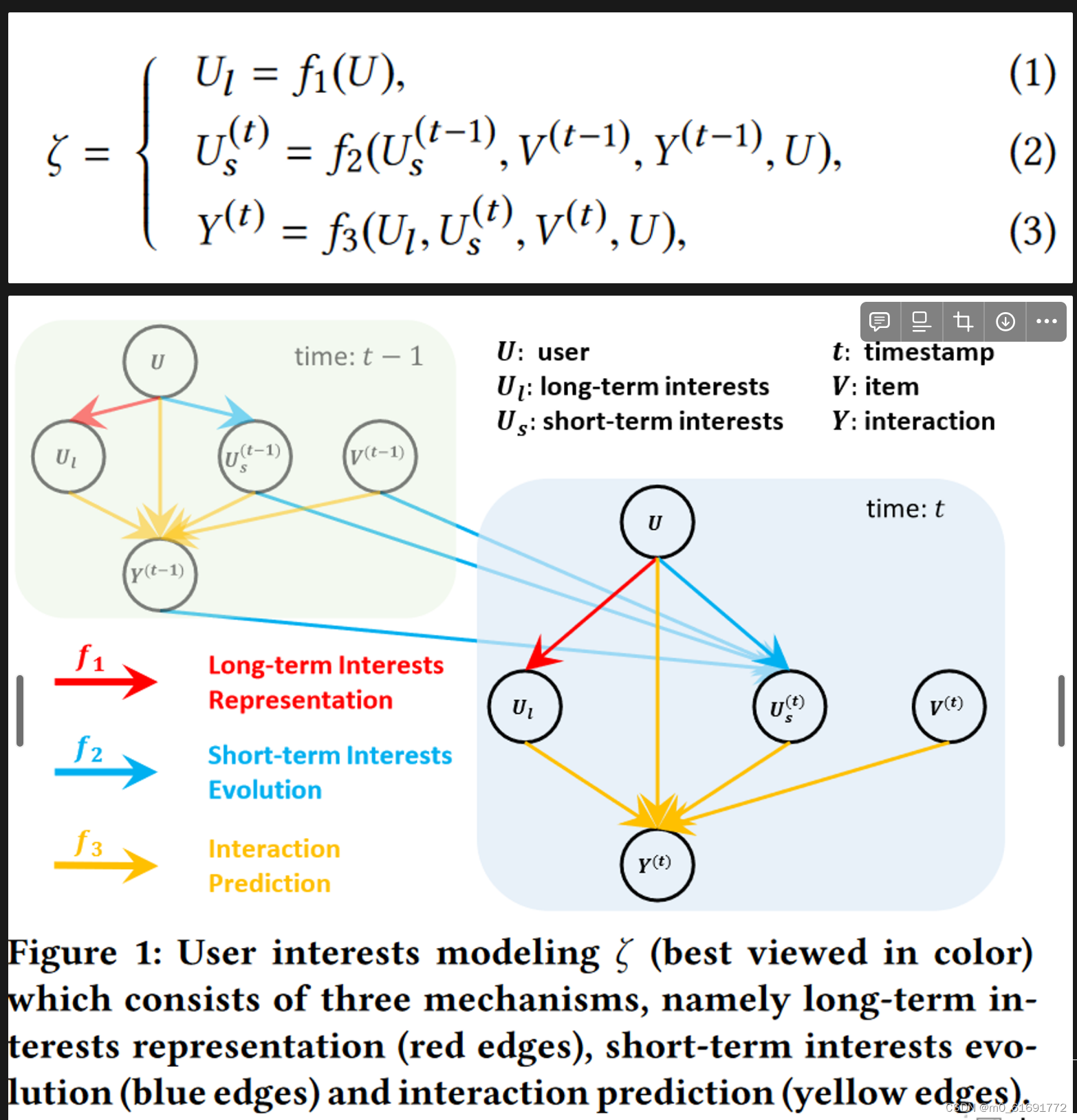
其中表示用户画像,包括用户ID和交互历史
. 用户兴趣建模
将每个交互分解为三个方面:长期兴趣表征、短期兴趣演变和交互预测。
1. 长期兴趣表征
长期兴趣反映了对用户偏好的整体看法,因此是稳定的并且受近期的交互的影响较小。换句话说,可以从整个历史交互序列中推断出长期兴趣,因此将 作为
的输入,其中包含交互历史
.
2. 短期兴趣演变
短期兴趣随着用户不断与推荐项目交互而变化。例如,用户在点击某个项目后可能会建立新的兴趣,同时也可能失去某些兴趣。即短期兴趣是时间相关的变量,因此在 中时间戳
处的短期兴趣是从
处的短期兴趣递归演变而来,受到最后一次交互和项目的影响。
3. 交互预测
在预测未来交互时,长期兴趣还是短期兴趣发挥更重要的作用取决于多个方面。因此采用注意力机制融合长短期兴趣来实现 .
自监督实现
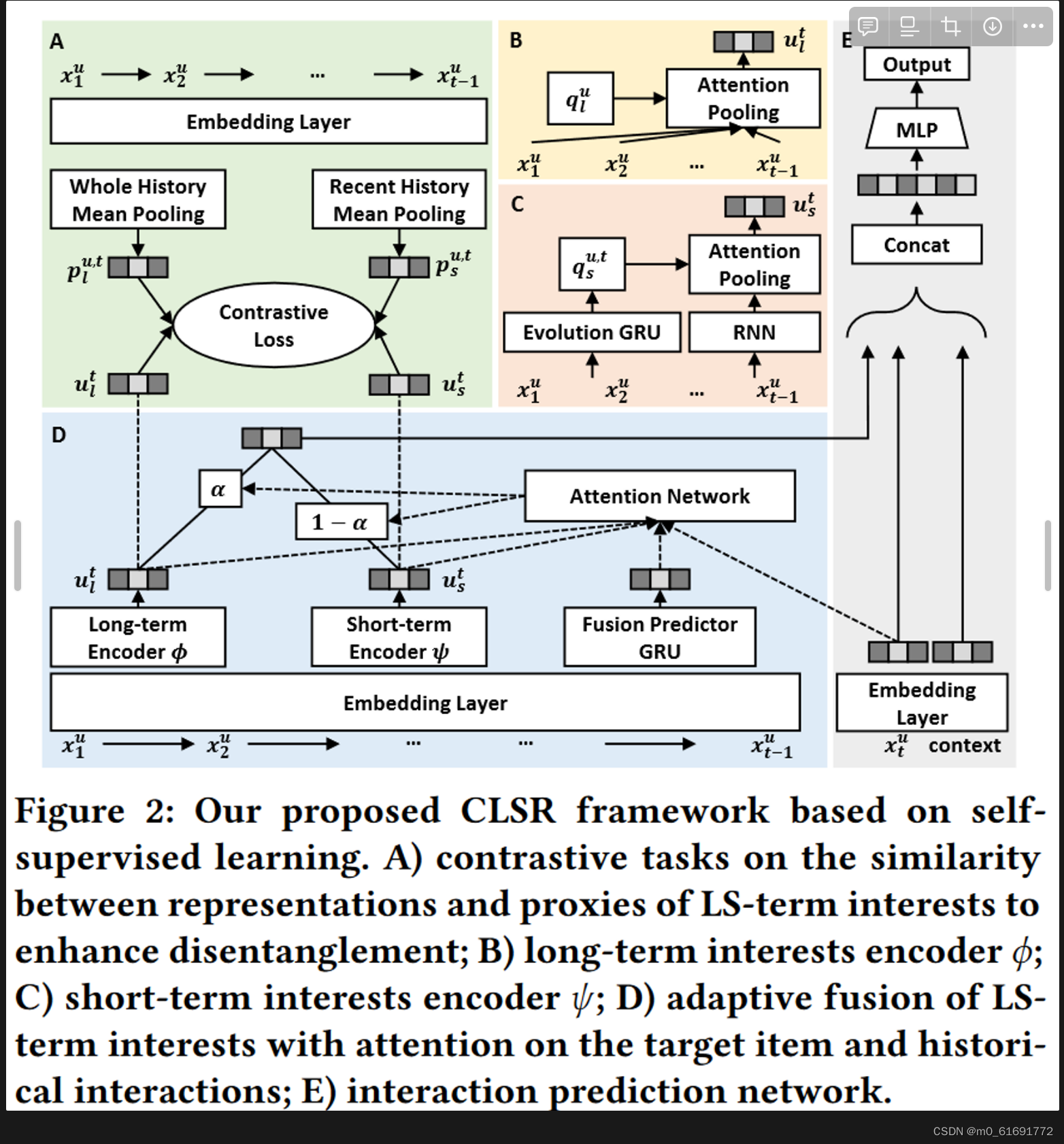
1. 为长短期兴趣生成查询向量
设计两个独立的注意力编码器 $φ$ 和 $ψ$ 分别捕获这两个方面。首先生成查询向量:
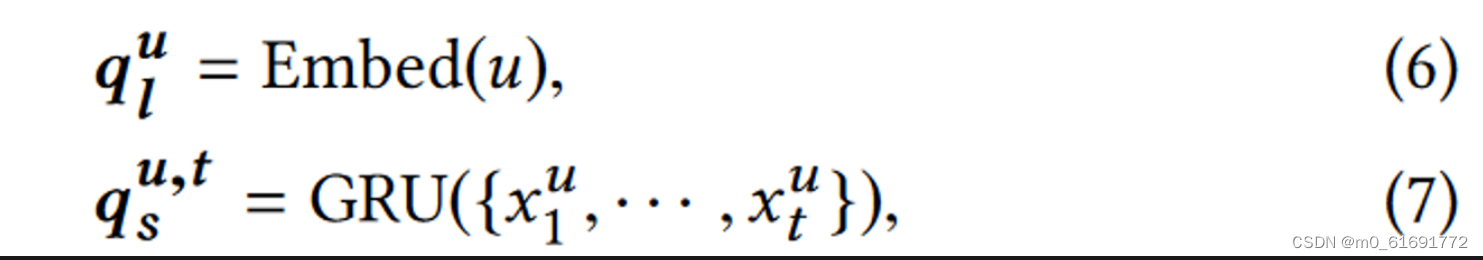
分别使用查找嵌入表和门控循环单元(GRU)来捕获随时间变化的不同动态。为了对嵌入相似性施加额外的自我监督,所有嵌入需要位于相同的语义空间中。因此使用项目的历史序列作为注意力编码的键,因此获得的长短期兴趣表示在相同的项目表示空间中:
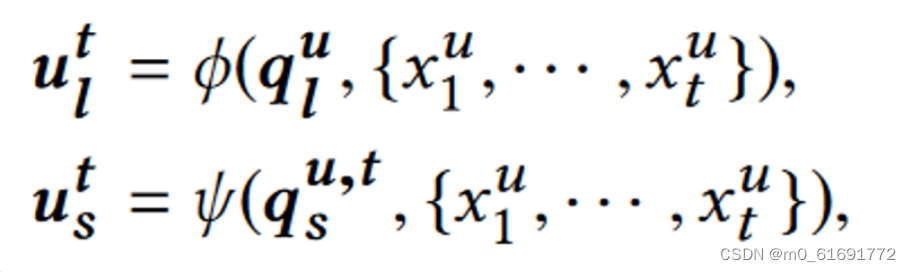
一个是查询向量,一个是由历史交互构成的键
一个是查询向量,一个是由历史交互构成的键
2. 长期兴趣编码器 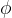

3. 短期兴趣编码器 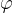

虽然分别采用了不同的编码器,但是仍然不能保证长短期兴趣之间的解耦,因为他们是通过无监督方式获得的。而且也没有 label 来监督其学习——因此设计对比任务来克服这一挑战
4. 长短期兴趣的自监督解耦
- 从交互序列本身获得长短期兴趣的代理来监督两个兴趣编码器。具体来说,我们计算整个交互历史的平均表示作为长期兴趣的代理,并使用最近 k 个交互的平均表示作为短期兴趣的代理。形式上,给定用户 u 在时间戳 t 的长短期兴趣代理可以计算如下:
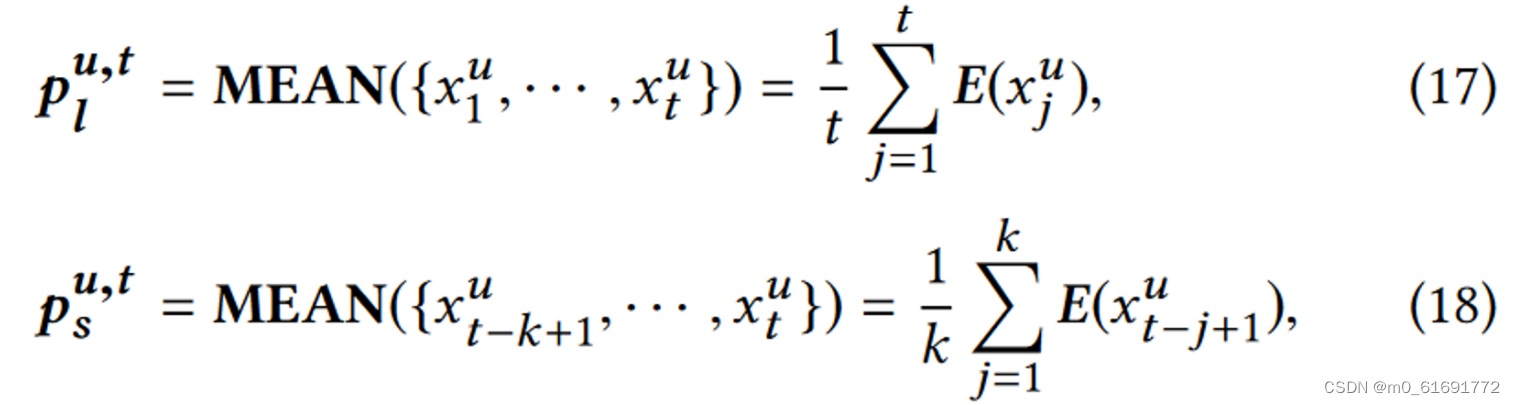
其中 表示项目
的嵌入。仅在序列长度长于阈值
时才计算代理,因为如果整个序列仅包含少数项目,则无需区分长短期. 阈值
和表征用户短期兴趣的交互长度
均为超参数,使用平均池化是因为简单且性能足够好,不会引入额外的超参数。更复杂的代理设计可以留给未来的工作。
- 有了代理作为标签,我们就可以利用它来监督长短期兴趣的解耦。具体来说,在编码器输出和代理之间进行对比学习,要求学习到的长短期兴趣的表示与其相应的代理比相反的代理更相似:
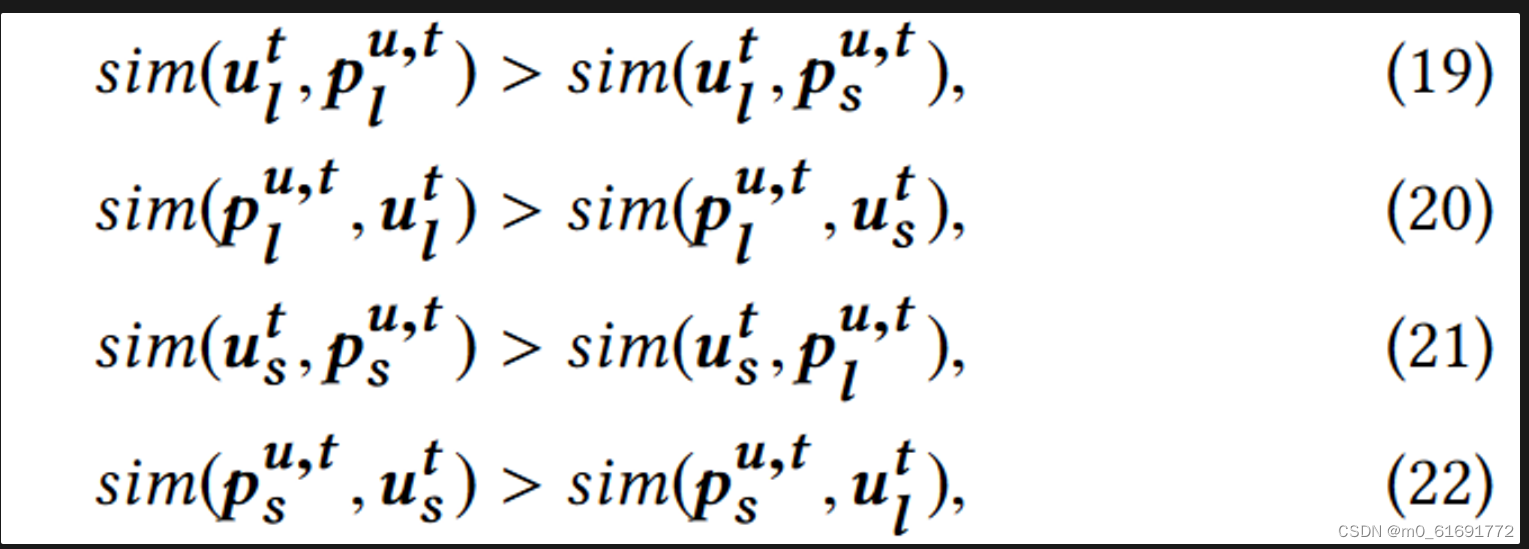
四个对比学习任务:Eqn(19)要求 跟短期兴趣相比,要跟长期兴趣代理更相似。Eqn(20)要求
跟短期兴趣相表征相比,长期兴趣代理更相似。
- 基于贝叶斯个性化排名(BPR)和三元组损失实现两个成对损失函数,以完成对比学习任务。
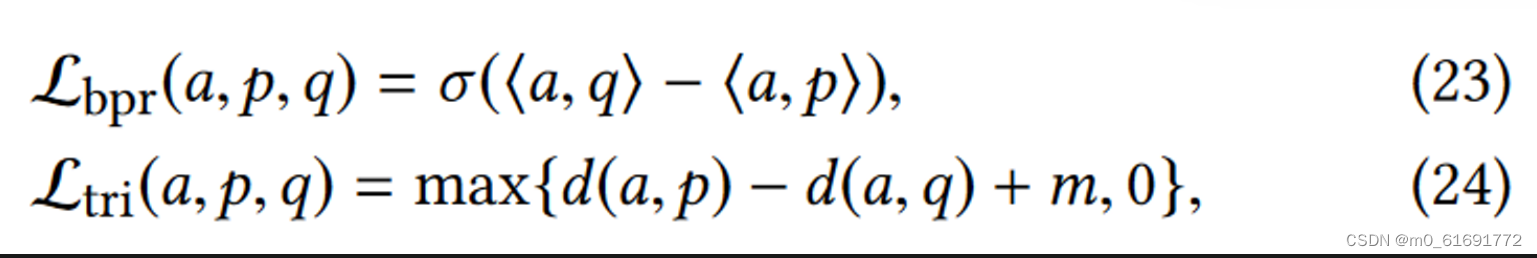
表示softplus激活函数,<·,·>表示两个嵌入的内积,d表示欧式距离。
和
都是为了让anchor
与正样本p比与负样本q更相似而设计的. d(a, p) − d(a, q)一定是个负数,损失函数最小化要求其负的愈多,即两者之间的距离差异越大,是hinge损失函数的变体,使二者距离之差最多为m就足够了
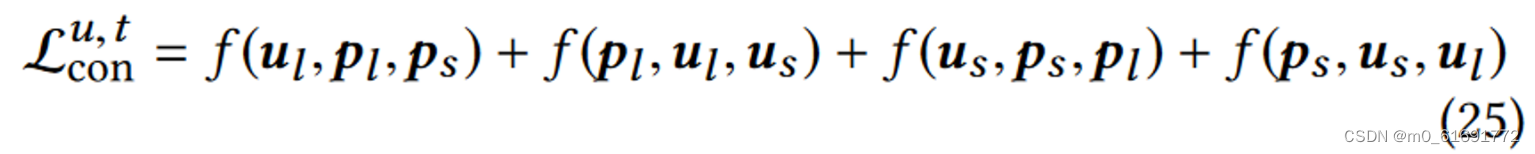
自监督解耦的对比损失,可以是
或
。这里并没有添加独立性约束的正则项去迫使学习到解耦方面互不相同,因为长短期兴趣可以在一定程度上相互重叠,比如仅在电商平台购买衣服的用户往往具有一致的长短期兴趣。
- 交互预测的自适应融合
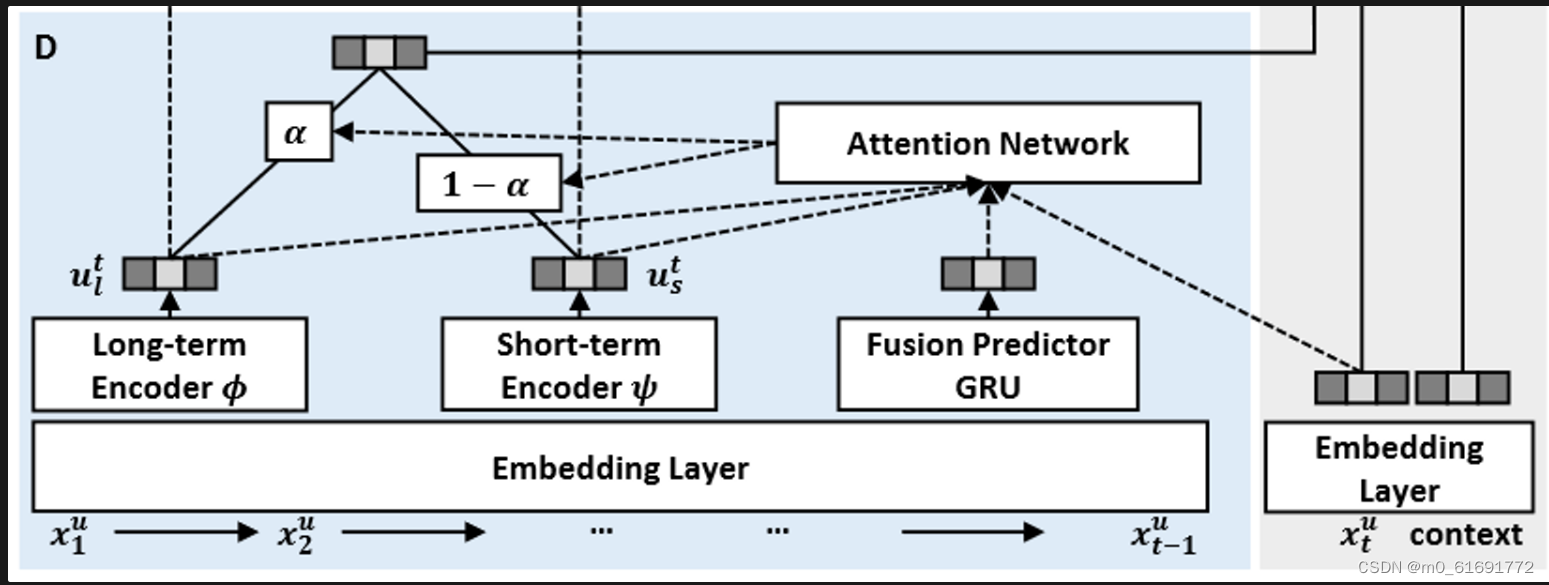
通过自监督学习到解耦的长短期兴趣表征之后,要对其进行融合。简单的相加或拼接假设两者的贡献固定,这在很多情况下是无效的。**事实上,长期重要还是短期重要,取决于历史序列(比如当用户持续浏览同一类别的商品时,主要受短期兴趣驱动),**同时也依赖于目标项目(例如,运动爱好者即使浏览了几本书,仍然可能出于长期兴趣而点击推荐的自行车)。因此将历史交互序列和目标项目作为aggregator的输入,其中历史序列使用GRU进行压缩,最后的隐藏状态输出作为MLP注意力网络的输入。
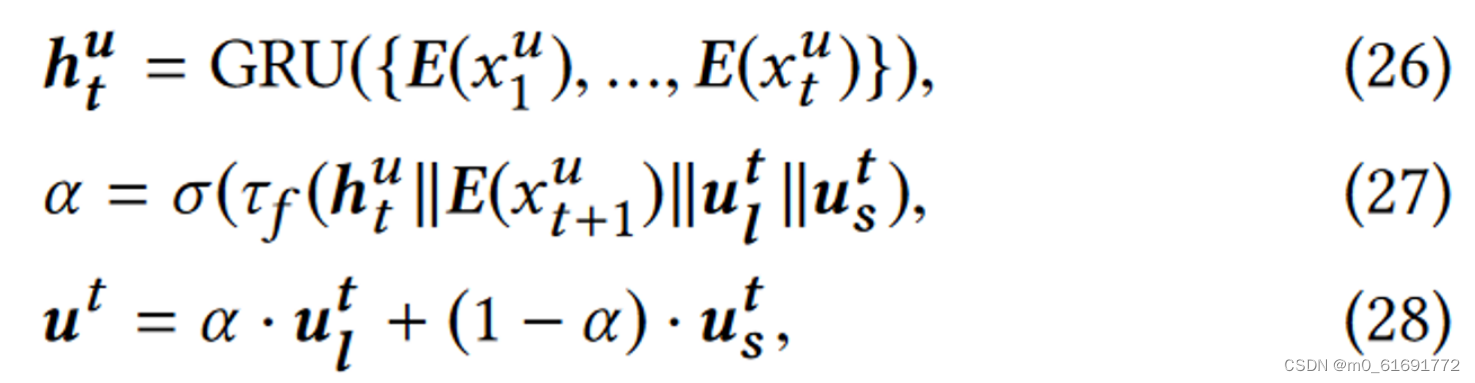
这里的是sigmoid函数
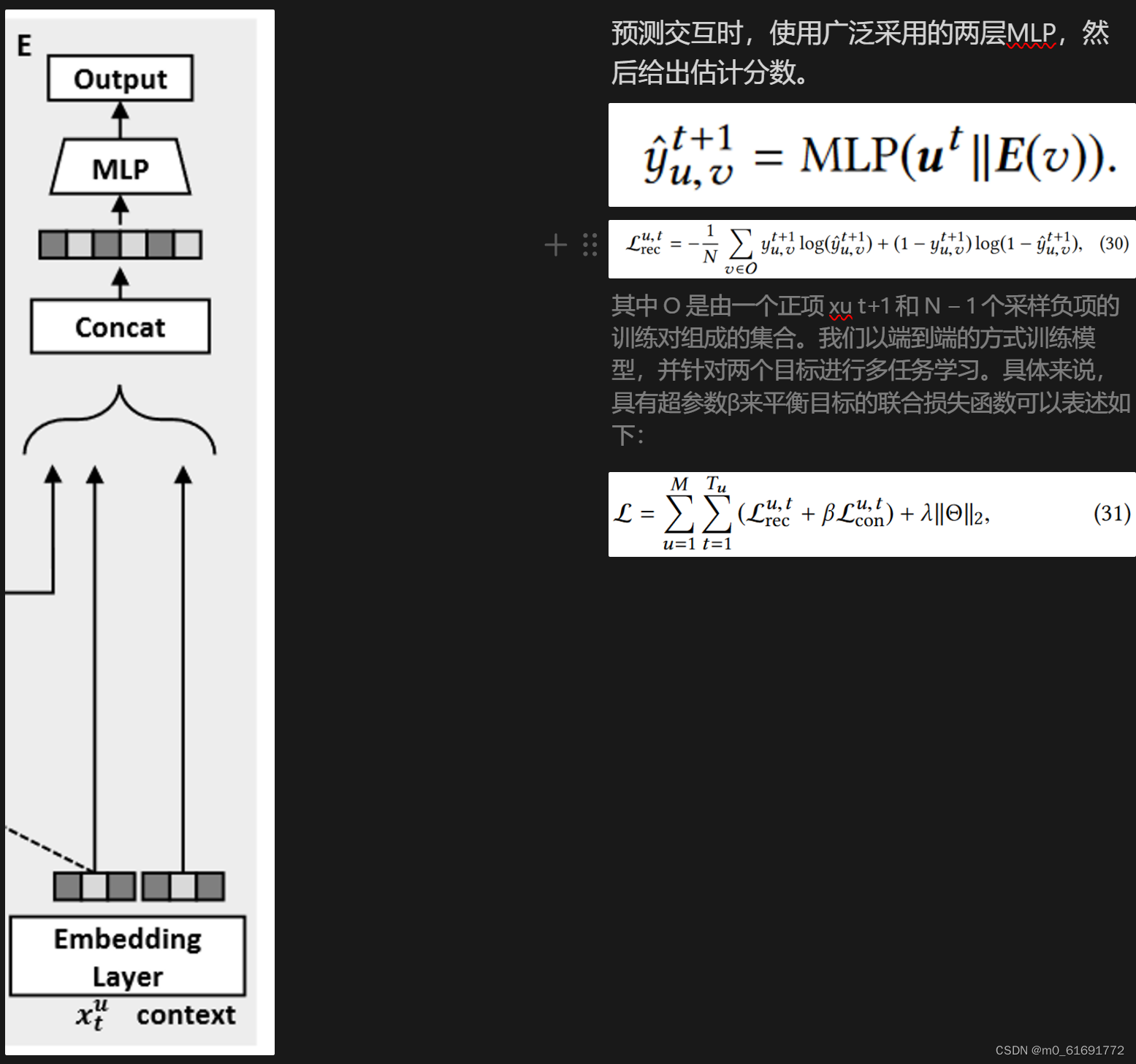
预测交互时,使用广泛采用的两层MLP,然后给出估计分数。
其中 O 是由一个正项 xu t+1 和 N − 1 个采样负项的训练对组成的集合。我们以端到端的方式训练模型,并针对两个目标进行多任务学习。
实验
- 数据集:电子商务数据集(https://tianchi.aliyun.com/dataset/dataDetail?dataId=649)、短视频推荐数据集
- baseline:
- NCF、DIN、Light GCN——长期兴趣建模
- Caser、GRU4REC、DIEN、SASRec、SURGE——短期兴趣建模
- SLi-Rec——长短期兴趣建模
- 评估指标:准确性指标AUC、GAUC,排名指标MRR、NDCG@K
- 代码及数据链接:GitHub - tsinghua-fib-lab/CLSR: The official implementation of "Disentangling Long and Short-Term Interests for Recommendation" (WWW '22)
- 一些结论:
- 通过比较不同的用于捕获短期兴趣的序列模型变体 RNN、LSTM、GRU、Time4LSTM,发现Time4LSTM对于提升推荐效果更有效,表明时间间隔特征有助于LSterm兴趣建模。仅使用最后交互的项目(k=1)作为短期兴趣的代理并不是一个好的选择,因为一次交互可能是具有很大可能性的噪音,k=2时最好。
- 在点击(低成本行为)预测时,短期兴趣占主导地位;在收藏/购买(高成本行为)预测时,长期兴趣的地位上升,但不足以成为主导地位。
- 使用Hinge损失函数或其变体可以使最后的推荐性能有上升的可能性
- 我的评述:创新在于提出了新的知识体系,对用户兴趣进行解耦,进一步执行更细粒度建模带来了推荐性能的提升。
原文:Disentangling Long and Short-Term Interests for Recommendation | Proceedings of the ACM Web Conference 2022















 874
874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









