






目录
53. 寻宝
- 题目链接:卡码网:53. 寻宝
文章讲解:代码随想录
在世界的某个区域,有一些分散的神秘岛屿,每个岛屿上都有一种珍稀的资源或者宝藏。国王打算在这些岛屿上建公路,方便运输。
不同岛屿之间,路途距离不同,国王希望你可以规划建公路的方案,如何可以以最短的总公路距离将 所有岛屿联通起来。
给定一张地图,其中包括了所有的岛屿,以及它们之间的距离。以最小化公路建设长度,确保可以链接到所有岛屿。
输入描述:
第一行包含两个整数V 和 E,V代表顶点数,E代表边数 。顶点编号是从1到V。例如:V=2,一个有两个顶点,分别是1和2。
接下来共有 E 行,每行三个整数 v1,v2 和 val,v1 和 v2 为边的起点和终点,val代表边的权值。
输出描述:
输出联通所有岛屿的最小路径总距离
输入示例:
7 11 1 2 1 1 3 1 1 5 2 2 6 1 2 4 2 2 3 2 3 4 1 4 5 1 5 6 2 5 7 1 6 7 1输出示例:
6
思路
本篇我们来讲解另一个算法:Kruskal,同样可以求最小生成树。
prim 算法是维护节点的集合,而 Kruskal 是维护边的集合。
上来就这么说,大家应该看不太懂,这里是先让大家有这么个印象,带着这个印象在看下文,理解的会更到位一些。
kruscal的思路:
- 边的权值排序,因为要优先选最小的边加入到生成树里
- 遍历排序后的边
- 如果边首尾的两个节点在同一个集合,说明如果连上这条边图中会出现环
- 如果边首尾的两个节点不在同一个集合,加入到最小生成树,并把两个节点加入同一个集合
下面我们画图举例说明kruscal的工作过程。
依然以示例中,如下这个图来举例。
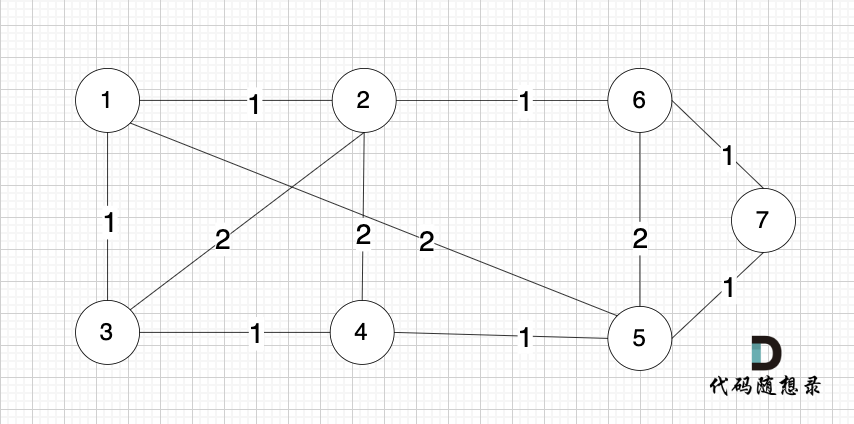
将图中的边按照权值有小到大排序,这样从贪心的角度来说,优先选 权值小的边加入到 最小生成树中。
排序后的边顺序为[(1,2) (4,5) (1,3) (2,6) (3,4) (6,7) (5,7) (1,5) (3,2) (2,4) (5,6)]
(1,2) 表示节点1 与 节点2 之间的边。权值相同的边,先后顺序无所谓。
开始从头遍历排序后的边。
选边(1,2),节点1 和 节点2 不在同一个集合,所以生成树可以添加边(1,2),并将 节点1,节点2 放在同一个集合。
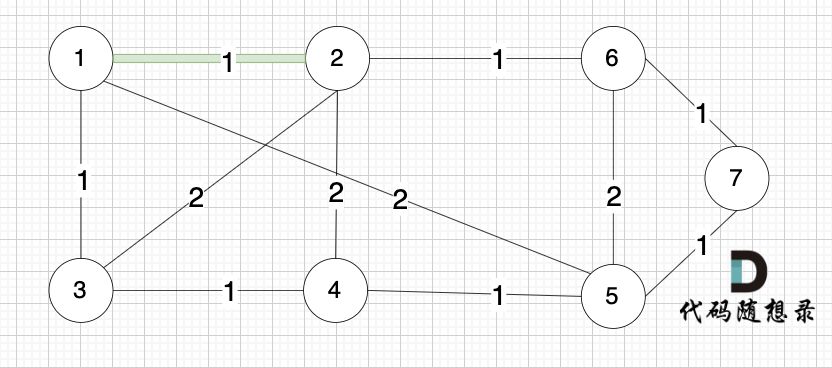
选边(4,5),节点4 和 节点 5 不在同一个集合,生成树可以添加边(4,5) ,并将节点4,节点5 放到同一个集合。
大家判断两个节点是否在同一个集合,就看图中两个节点是否有绿色的粗线连着就行
(这里在强调一下,以下选边是按照上面排序好的边的数组来选择的)
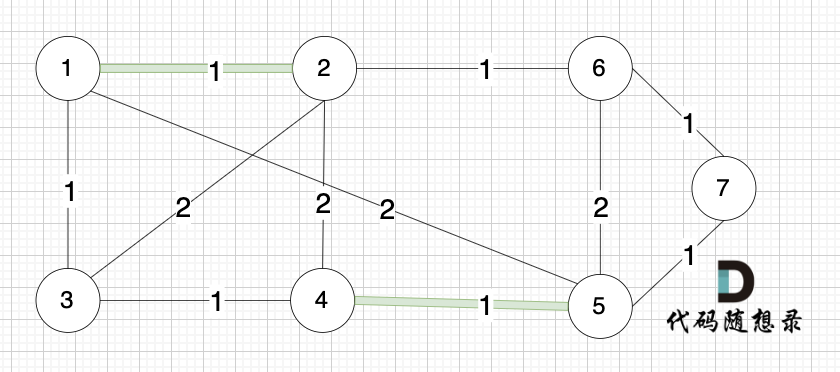
选边(1,3),节点1 和 节点3 不在同一个集合,生成树添加边(1,3),并将节点1,节点3 放到同一个集合。
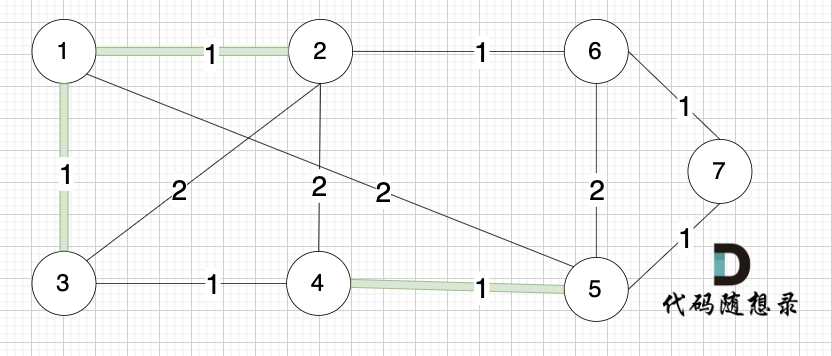
选边(2,6),节点2 和 节点6 不在同一个集合,生成树添加边(2,6),并将节点2,节点6 放到同一个集合。
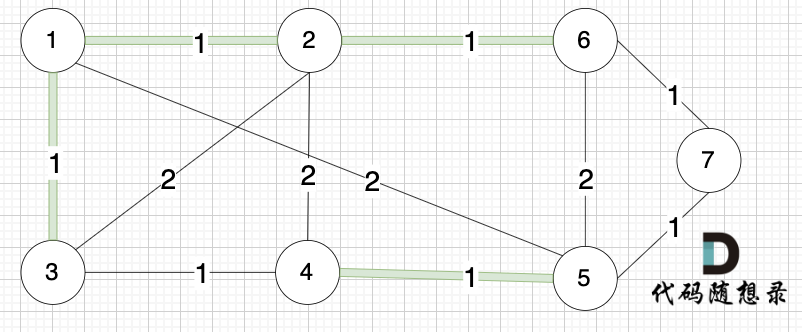
选边(3,4),节点3 和 节点4 不在同一个集合,生成树添加边(3,4),并将节点3,节点4 放到同一个集合。
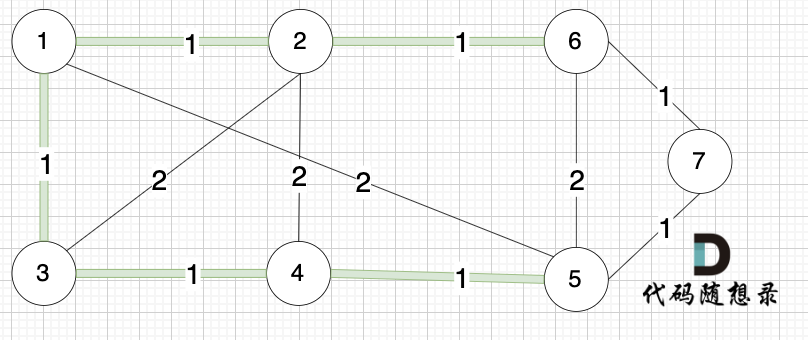
选边(6,7),节点6 和 节点7 不在同一个集合,生成树添加边(6,7),并将 节点6,节点7 放到同一个集合。
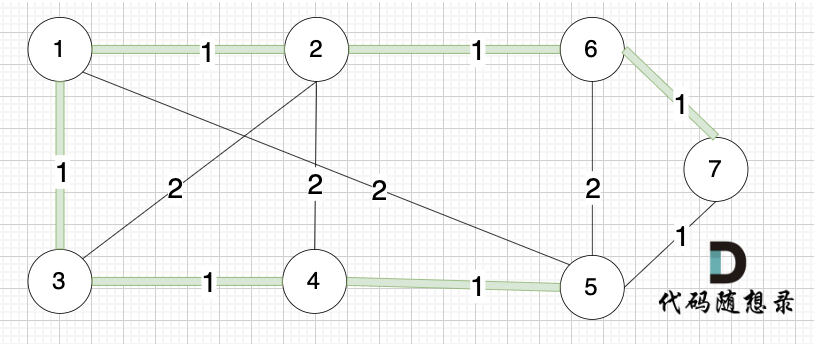
选边(5,7),节点5 和 节点7 在同一个集合,不做计算。
选边(1,5),两个节点在同一个集合,不做计算。
后面遍历 边(3,2),(2,4),(5,6) 同理,都因两个节点已经在同一集合,不做计算。
此时 我们就已经生成了一个最小生成树,即:
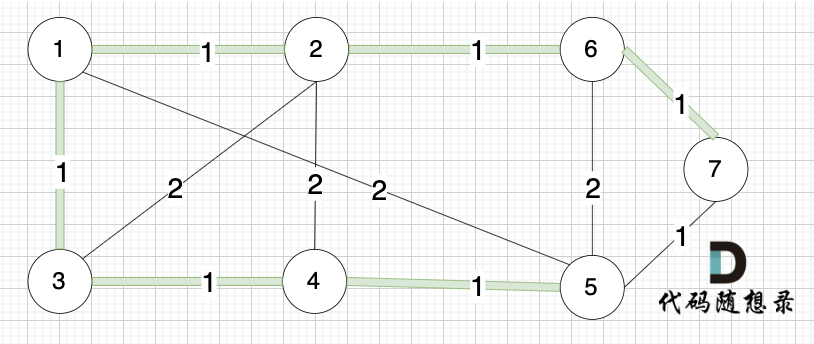
在上面的讲解中,看图的话 大家知道如何判断 两个节点 是否在同一个集合(是否有绿色的线连在一起),以及如何把两个节点加入集合(就在图中把两个节点连上)
但在代码中,如果将两个节点加入同一个集合,又如何判断两个节点是否在同一个集合呢?
这里就涉及到我们之前讲解的并查集。
我们在并查集开篇的时候就讲了,并查集主要就两个功能:
- 将两个元素添加到一个集合中
- 判断两个元素在不在同一个集合
方法一: kruskal
class Edge:
def __init__(self, l, r, val):
self.l = l
self.r = r
self.val = val
n = 10001
father = list(range(n))
def init():
global father
father = list(range(n))
def find(u):
if u != father[u]:
father[u] = find(father[u])
return father[u]
def join(u, v):
u = find(u)
v = find(v)
if u != v:
father[v] = u
def kruskal(v, edges):
edges.sort(key=lambda edge: edge.val)
init()
result_val = 0
for edge in edges:
x = find(edge.l)
y = find(edge.r)
if x != y:
result_val += edge.val
join(x, y)
return result_val
if __name__ == "__main__":
import sys
input = sys.stdin.read
data = input().split()
v = int(data[0])
e = int(data[1])
edges = []
index = 2
for _ in range(e):
v1 = int(data[index])
v2 = int(data[index + 1])
val = int(data[index + 2])
edges.append(Edge(v1, v2, val))
index += 3
result_val = kruskal(v, edges)
print(result_val)心得收获
此时我们已经讲完了 Kruskal 和 prim 两个解法来求最小生成树。
什么情况用哪个算法更合适呢。
Kruskal 与 prim 的关键区别在于,prim维护的是节点的集合,而 Kruskal 维护的是边的集合。 如果 一个图中,节点多,但边相对较少,那么使用Kruskal 更优。
有录友可能疑惑,一个图里怎么可能节点多,边却少呢?
节点未必一定要连着边那, 例如 这个图,大家能明显感受到边没有那么多对吧,但节点数量 和 上述我们讲的例子是一样的。
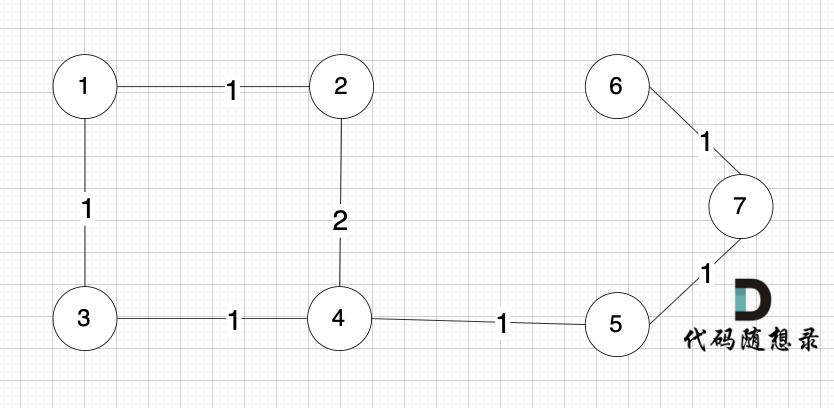
为什么边少的话,使用 Kruskal 更优呢?
因为 Kruskal 是对边进行排序的后 进行操作是否加入到最小生成树。
边如果少,那么遍历操作的次数就少。
在节点数量固定的情况下,图中的边越少,Kruskal 需要遍历的边也就越少。
而 prim 算法是对节点进行操作的,节点数量越少,prim算法效率就越优。
所以在 稀疏图中,用Kruskal更优。 在稠密图中,用prim算法更优。
边数量较少为稀疏图,接近或等于完全图(所有节点皆相连)为稠密图
Prim 算法 时间复杂度为 O(n^2),其中 n 为节点数量,它的运行效率和图中边树无关,适用稠密图。
Kruskal算法 时间复杂度 为 nlogn,其中n 为边的数量,适用稀疏图。
Prim和Kruskal的区别
Prim算法和Kruskal算法都是用于求解 最小生成树(MST) 的经典贪心算法。尽管它们的目标相同,但它们的实现方式和使用的数据结构有所不同。
- 思路与操作对象的区别
Prim算法:
节点为中心:Prim算法从一个起始节点开始,不断向已连接的生成树中添加最小边。它通过逐步扩展树的节点来构建最小生成树。
局部贪心策略:每次选择的都是与已构建的生成树相连的最小边。
Kruskal算法:
边为中心:Kruskal算法从所有边中选择权值最小的边开始,逐步将未连通的部分通过边连接起来。
全局贪心策略:Kruskal算法直接对所有边进行排序,然后逐步选择不会形成环的最小边。 - 使用的数据结构
Prim算法:
邻接矩阵或邻接表:通常使用邻接矩阵或邻接表来表示图,逐步更新已连接节点与其他未连接节点之间的最小权值。
优先队列(可选):使用优先队列(堆)优化查找最小边的操作,复杂度可以优化为 O(E log V)。
Kruskal算法:
边列表:Kruskal算法将所有边按权值排序,然后依次选择边,因此直接使用边的列表。
并查集(Union-Find):Kruskal算法需要并查集来判断两个节点是否已经在同一集合中,用于检测是否形成环路。 - 适用的图类型
Prim算法:
适用于稠密图:由于 Prim算法逐步扩展已连接的节点集合,因此在边数较多的稠密图中表现较好。
时间复杂度为 O(V^2)(邻接矩阵)或 O(E log V)(使用优先队列的邻接表)。
Kruskal算法:
适用于稀疏图:Kruskal算法对边进行排序并依次选择最小边,在边数较少的稀疏图中表现较好。
时间复杂度为 O(E log E),其中 E 是边数。 - 执行流程
Prim算法:
从任意起始节点开始,将该节点标记为已访问。
每次选择已访问节点集合中与未访问节点集合之间的最小边,将新节点加入最小生成树。
重复该过程,直到所有节点都被访问。
Kruskal算法:
将所有边按权值从小到大排序。
依次选择最小的边,如果该边连接的两个节点不在同一集合中,则将它们加入最小生成树,并使用并查集进行合并。
重复该过程,直到树中包含 n-1 条边。 - 结束条件
Prim算法:
当所有节点都已加入生成树时,算法结束。
Kruskal算法:
当选中的边数达到 n-1 条时,算法结束(其中 n 是节点数)。
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qq_42952637/article/details/142101328















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









