






1-1
若用平方探测法解决冲突,则插入新元素时,若散列表容量为质数,插入就一定可以成功。
F
可能会超出表容量,插入失败。
平方探测法是一种较好的处理冲突的方法,可以避免出现“堆积”问题,它的缺点是不能探测到散列表上的所有单元,但至少能探测到一半单元
在散列中,函数“插入”和“查找”具有同样的时间复杂度。
T
插入和查找具有同样的时间复杂度O(1)。
即使把2个元素散列到有100个单元的表中,仍然有可能发生冲突。
T
将 10 个元素散列到 100 000 个单元的哈希表中,一定不会产生冲突。
F
哈希表装填因子定义为:α= 填入表中的元素个数/哈希表的长度。
采用平方探测冲突解决策略(hi(k)=(H(k)+i2)%11, 注意:不是±i2),将一批散列值均等于2的对象连续插入一个大小为11的散列表中,那么第4个对象一定位于下标为0的位置。
T
解析:第一个地址为2,第二个为2+1,第三个为2+4,第四个为2+9,即下标为0。
2-1
在下列查找的方法中,平均查找长度与结点个数无关的查找方法是:
A.顺序查找
B.二分法
C.利用哈希(散列)表
D.利用二叉搜索树
分数 4
作者 DS课程组
单位 浙江大学
散列冲突可以被描述为:
A.两个元素除了有不同键值,其它都相同
B.两个有不同数据的元素具有相同的键值
C.两个有不同键值的元素具有相同的散列地址
D.两个有相同键值的元素具有不同的散列地址
分数 4
作者 DS课程组
单位 浙江大学
假定有K个关键字互为同义词,若用线性探测法把这K个关键字存入散列表中,至少要进行多少次探测?
A.K−1
B.K
C.K+1
D.K(K+1)/2
第一个关键字需要探测一次,以后的关键字均比前一个关键字要多探查一次,则共需探测K(K+1)/2次。
至少需要 1 + 2 + ...+ k-1 = k(k-1)/2 次探测.
解析:在Hash表中存入第一个同义关键字后,后面至少连续有k-1个单元为空,则按线性探测再散列法可依次存入剩余的k-1个关键字,这样探测次数最少.
k(k-1)/2
散列表的查找过程和建表过程类似。假设给定的值为K,根据建表时设定的散列函数H,计算出散列地址H(K),若表中该地址对应的空间未被占用,则查找失败,否则将该地址中的值与K比较,若相等则查找成功,否则按建表时设定的处理冲突方法找下一个地址,如此反复下去,直到某个地址空间未被占用(查找失败)或者关键字比较相等(查找成功)为止。
此处的查找就可以看成探测,固由以上结论得
分数 4
作者 DS课程组
单位 浙江大学
采用线性探测法解决冲突时所产生的一系列后继散列地址:
A.必须大于等于原散列地址
B.必须小于等于原散列地址
C.可以大于或小于但不等于原散列地址
D.对地址在何处没有限制
分数 4
作者 DS课程组
单位 浙江大学
从一个具有N个结点的单链表中查找其值等于X的结点时,在查找成功的情况下,需平均比较多少个结点?
A.N/2
B.N
C.(N−1)/2
D.(N+1)/2
分数 4
作者 DS课程组
单位 浙江大学
若用平方探测法解决冲突,则插入新元素时,以下陈述正确的是:
A.插入一定可以成功
B.插入不一定能成功
C.插入一定不能成功
D.若散列表容量为质数,插入就一定可以成功
分数 4
作者 冯雁
单位 浙江大学
给定散列表大小为17,散列函数为H(Key)=Key%17。采用平方探测法处理冲突:hi(k)=(H(k)±i2)%17将关键字序列{ 23, 22, 7, 26, 9, 6 }依次插入到散列表中。那么元素6存放在散列表中的位置是:
A.15
B.10
C.6
D.2
分数 4
作者 冯雁
单位 浙江大学
给定散列表大小为11,散列函数为H(Key)=Key%11。按照线性探测冲突解决策略连续插入散列值相同的5个元素。问:此时该散列表的平均不成功查找次数是多少?
A.26/11
B.5/11
C.1
D.不确定
给定散列表大小为11,散列函数为H(Key)=Key%11。按照线性探测冲突解决策略连续插入散列值相同的4个元素。问:此时该散列表的平均不成功查找次数是多少?
A.1
B.4/11
C.21/11
D.不确定
答案:C
分析:
区别概念平均成功查找次数和平均不成功查找次数。
平均成功查找次数=每个关键词比较次数之和÷关键词的个数
平均不成功查找次数=每个位置不成功时的比较次数之和÷表长(所谓每个位置不成功时的比较次数就是在除余位置内,每个位置到第一个为空的比较次数,比如此题表长为11,散列函数为Key%11,除余的是11,那么除余位置就是0—10;如果表长为15,但散列函数为Key%13,那么除余位置就是0—12)
明确概念后做题:
连续插入散列值相同的4个元素,我们就假设它的散列值都为0,那么插入后的位置:
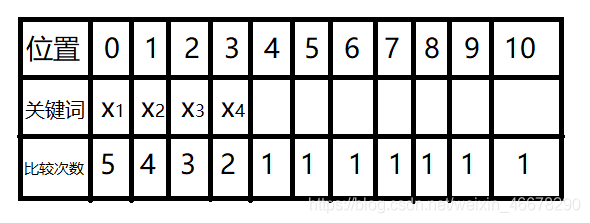
其中位置0到第一个为空的位置4的比较次数为5,其余的位置以此类推。
平均不成功查找次数=(5+4+3+2+1+1+1+1+1+1+1)÷ 11 = 21/11
故选C
分数 4
作者 DS课程组
单位 浙江大学
在有n(n>1000)个元素的升序数组A中查找关键字x。查找算法的伪代码如下所示:
k = 0;
while ( k<n 且 A[k]<x ) k = k+3;
if ( k<n 且 A[k]==x ) 查找成功;
else if ( k-1<n 且 A[k-1]==x ) 查找成功;
else if ( k-2<n 且 A[k-2]==x ) 查找成功;
else 查找失败;
本算法与二分查找(折半查找)算法相比,有可能具有更少比较次数的情形是:
A.当x不在数组中
B.当x接近数组开头处
C.当x接近数组结尾处
D.当x位于数组中间位置
类似于顺序查找,显然第二个是对的。
对一个长度为 10 的排好序的表用二分法查找,若查找不成功,至少需要比较的次数是()。
A.4
B.3
C.5
D.6
若采用二分查找法查找一个长度为n的顺序表L中不存在的元素,则关键字的比较次数最多是 ⌊log2n⌋+1,最少是⌊log2n⌋。这道题问的是最少的情况。
分数 4
作者 考研真题
单位 浙江大学
现有长度为 11 且初始为空的散列表 HT,散列函数是 H(key)=key%7,采用线性探查(线性探测再散列)法解决冲突。将关键字序列 87,40,30,6,11,22,98,20 依次插入到 HT 后,HT 查找失败的平均查找长度是:
A.4
B.5.25
C.6
D.6.29
1. 构造散列表
根据散列函数 H(key) = key %7 以及线性再探测,我们可以构造出散列表,如下图
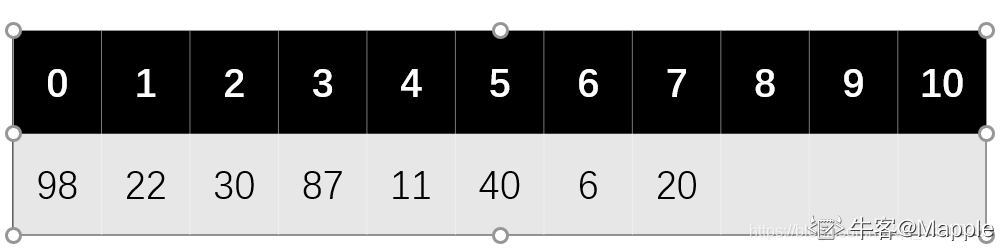
2. 计算失败的平均查找长度
计算失败,可以转换理解,就是在已经构造好的散列表上,我们再去插入一个新的值需要比较多少次。
比如,现在我再插入一个数 21,那么理论上应该存放在地址 0 的位置,但是地址 0 有 98 了,则我们线性再探测(就是依次增加一个地址,看是否为空,空则可以插入),同理地址 1 也存在元素。以此类推,我们一共要比较地址 0~7,发现都有值,直到比较地址 8 才为空。所以一共比较了 9 次。
对其他地址(0~6)用同样的方式去理解,则一共比较的次数是 9+8+7+6+5+4+3 = 42
这里要注意,因为我们的模是 7,所以计算的地址只可能在(0~6)这个范围,所以最后的结果是 42/7 =6
3.计算成功的平均查找长度
计算成功的长度,就是记录下每个数值比较了几次找到可存储的空间。
比如,本题每个数值比较(并存入)对应地址的次数如下图。
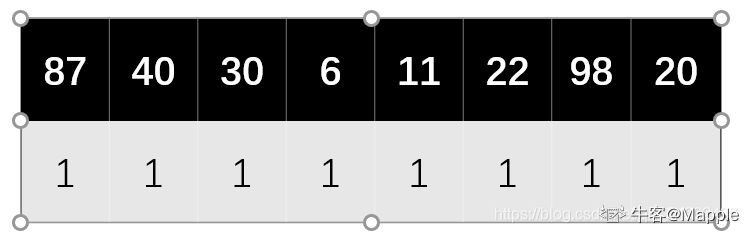
所以其 ASL = 1+1+1+1+1+1+1+1/8=1
note
1.注意失败与成功的查找长度的分母意义是不同的,失败时,分母是模的值;成功时,分母是元素个数。
分数 4
作者 徐镜春
单位 浙江大学
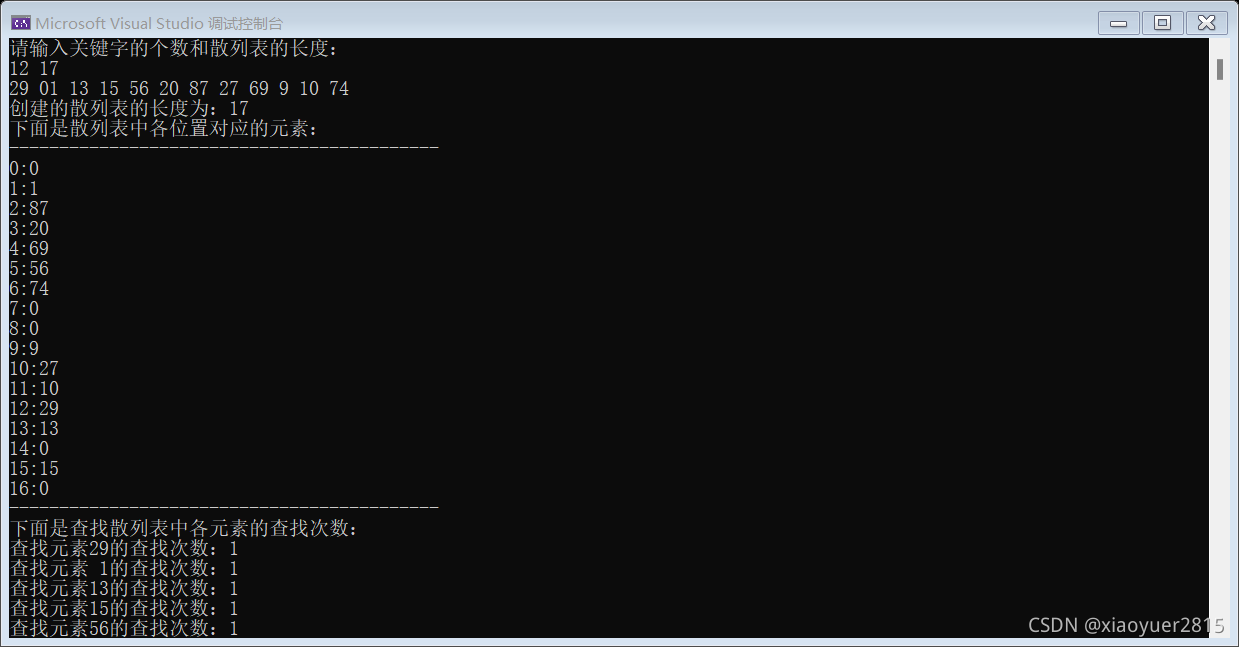
设有一组关键字 { 29,01, 13,15,56,20,87,27,69,9,10,74 },散列函数为 H(key)=key%17,采用线性探测方法解决冲突。试在 0 到 18 的散列地址空间中对该关键字序列构造散列表,则成功查找的平均查找长度为 __
A.0.33
B.1.17
C.1.25
D.1.33
1+1+1+1+1+1+1+1+4+1+2+1/12 = 1.33
线性探测 所以创建的散列表长度17 小于18的最大素数
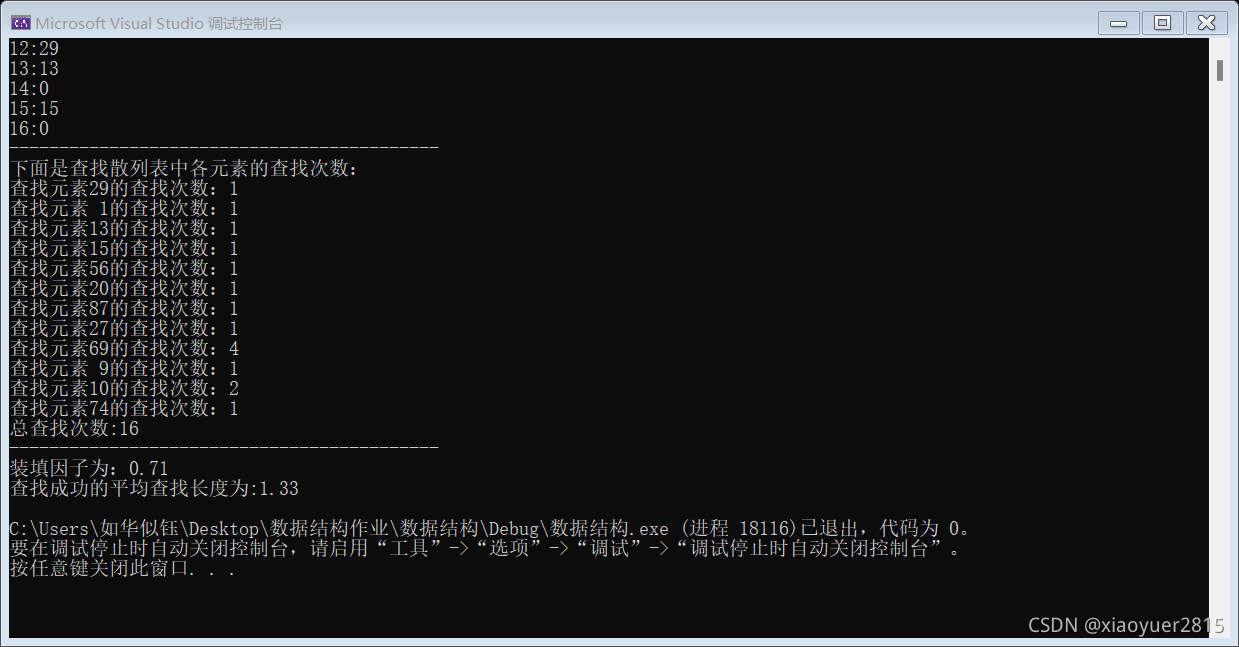
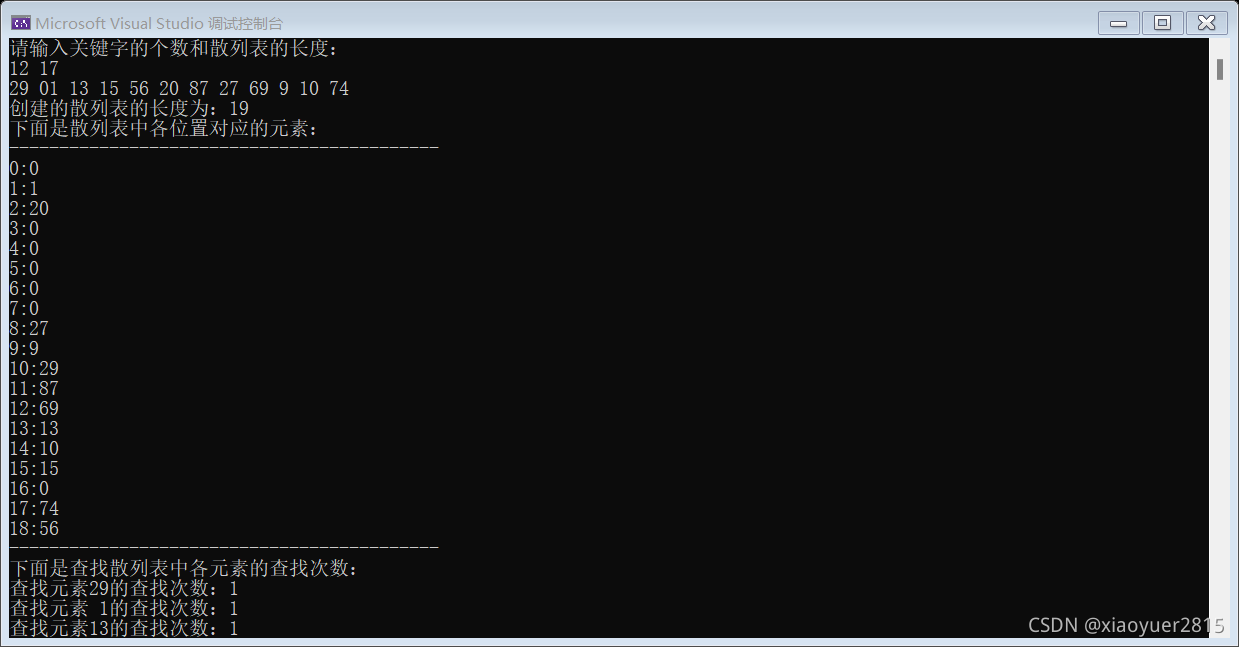
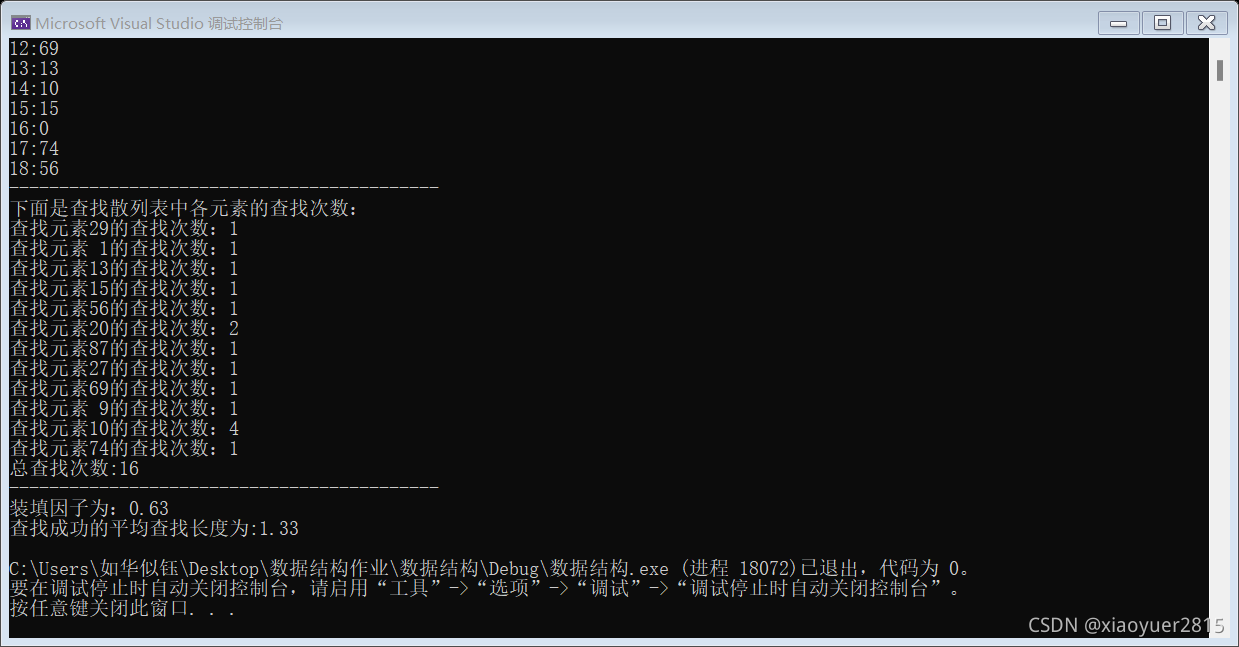
设有一组关键字 { 29,01, 13,15,56,20,87,27,69,9,10,74 },散列函数为 H(key)=key%17,采用平方探测方法解决冲突。试在 0 到 18 的散列地址空间中对该关键字序列构造散列表,则成功查找的平均查找长度为 __
A.0.33
B.1.17
C.1.25
D.1.33
平方探测 所以创建的散列表长度19 大于18的最小素数
15/12 = 1.25
设有一组关键字 { 92,81, 58,21,57,45,161,38,117 },散列函数为 h(key)=key%13,采用下列双散列探测方法解决第 i 次冲突:h(key)=(h(key)+i×h2(key))%13,其中 h2(key)=(key%11)+1。试在 0 到 12 的散列地址空间中对该关键字序列构造散列表,则成功查找的平均查找长度为 __
A.1.67
B.1.56
C.1.44
D.1.33
1+1+1+1+1+2+3+3+2/9=1.67
下列因素中, 影响散列(哈希)方法平均查找长度的是
I. 装填因子
II.散列函数
III. 冲突解决策略
A.仅 I、II
B.仅 I、III
C.仅 II、III
D.I、II、III
7-1 字符串关键字的散列映射
给定一系列由大写英文字母组成的字符串关键字和素数P,用移位法定义的散列函数H(Key)将关键字Key中的最后3个字符映射为整数,每个字符占5位;再用除留余数法将整数映射到长度为P的散列表中。例如将字符串AZDEG插入长度为1009的散列表中,我们首先将26个大写英文字母顺序映射到整数0~25;再通过移位将其映射为3×322+4×32+6=3206;然后根据表长得到3206%1009=179,即是该字符串的散列映射位置。
发生冲突时请用平方探测法解决。
输入格式:
输入第一行首先给出两个正整数N(≤500)和P(≥2N的最小素数),分别为待插入的关键字总数、以及散列表的长度。第二行给出N个字符串关键字,每个长度不超过8位,其间以空格分隔。
输出格式:
在一行内输出每个字符串关键字在散列表中的位置。数字间以空格分隔,但行末尾不得有多余空格。
输入样例1:
4 11
HELLO ANNK ZOE LOLI
输出样例1:
3 10 4 0
输入样例2:
6 11
LLO ANNA NNK ZOJ INNK AAA
输出样例2:
3 0 10 9 6 1
#include<bits/stdc++.h>
#define maxn 20003
using namespace std;
map<string,int> Hash;
string s;
int n, p, vis[maxn];
int insert(int x)
{
x %= p;
if(Hash.find(s) != Hash.end())
return x;
if(Hash[s] == 0 && vis[x]) //冲突
{
int ans = x,i = 1;
while(vis[x])
{
x = (ans + i*i) % p;
if(vis[x] == 0)
break;
else
x = (ans - i*i + p) % p;
i++;
}
vis[x] = 1;
Hash[s] = x;
return x;
}
else if(Hash[s] == 0 && !vis[x])
{
vis[x] = 1;
Hash[s] = x;
return x;
}
return x;
}
int main()
{
memset(vis, 0, sizeof(vis));
cin>>n>>p;
for(int i = 0;i < n;i++)
{
cin>>s;
int sum = 0, len = s.length();
if(s.length() > 3)
{
for(int j = s.length()-3;j < s.length();j++)
sum = sum*32 + s[j] - 'A';
}
else
{
for(int j = 0; j < s.length();j++)
sum = sum*32 + s[j] - 'A';
}
int index = insert(sum % p);
if(i == 0)
cout<<index;
else cout<<" "<<index;
}
cout<<endl;
}
















 6736
6736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











