







文章目录
论文名称:Pick and Choose: A GNN-based Imbalanced Learning Approach for Fraud Detection
论文下载地址:https://dl.acm.org/doi/pdf/10.1145/3442381.3449989
数据集、源码和其他附件下载地址:https://github.com/PonderLY/PC-GNN
这是WWW’21: Proceedings of the Web Conference论文
旨在通过利用标签信息设计独特的采样方法来解决利用图神经网络做欺诈检测task中的类不平衡问题
摘要翻译
Graph-based fraud detection approaches have escalated lots of attention recently due to the abundant relational information of graph-structured data, which may be beneficial for the detection of fraudsters. However, the GNN-based algorithms could fare poorly when the label distribution of nodes is heavily skewed, and it is common in sensitive areas such as financial fraud, etc. To remedy the class imbalance problem of graph-based fraud detection, we propose a Pick and C hoose Graph Neural Network (PC-GNN for short) for imbalanced supervised learning on graphs. First, nodes and edges are picked with a devised label-balanced sampler to construct sub-graphs for mini-batch training. Next, for each node in the sub-graph, the neighbor candidates are chosen by a proposed neighborhood sampler. Finally, information from the selected neighbors and different relations are aggregated to obtain the final representation of a target node. Experiments on both benchmark and real-world graph-based fraud detection tasks demonstrate that PCGNN apparently outperforms state-of-the-art baselines.
由于图数据可以很好地表达实体之间的关系,因而基于图的欺诈检测往往能取得不错的效果。但目前面临的问题是在欺诈检测这样的任务中往往存在着节点标签分布严重偏斜的问题,这会严重影响欺诈检测算法的性能。
于是作者提出了一种新的图神经网络模型PC-GNN,这个模型可以被解耦成三个部分Pick、Choose、Aggregate。
Pick部分使用了一个标签平衡采样器从原始数据中采样得到标签分布更加均衡的子图数据用作小批量训练(mini-batch training)的input
Choose部分使用一个考虑节点标签的邻域采样器对节点邻域内的节点和边进行采样用于当前节点表示
Aggregate部分将从不同关系下(本文考虑的图是多关系不平衡图 Multi-Relation Imbalanced Graph)节点邻域信息采样得到的结果聚合成最终的节点特征表示
实验结果证明PC-GNN模型在图欺诈检测的benchmark数据集(YelpChi和Amazon)以及现实中金融数据集上都取得了好于sota的结果
回答十问
Q1论文试图解决什么问题?
作者将其形式化地定义为了一个图上的不平衡节点的分类问题
作者还从application和algorithm两个方面深入分析了fraud detection问题面临的三个挑战
application方面是由fraudsters进行伪装而在数据集上制造的噪音,体现为redundant link information和lack of necessary link information for fraudsters。解释一下就是欺诈节点往往倾向于与好的节点建立联系,并且减少自己与其他节点的联系来进行自我伪装
algorithm方面由于数据集的标签分布极度不平衡,一个fraud节点的周围绝大多数都是正常节点,则在对这个中心fraud节点进行embedding时,与之相连的fraud节点的信息将被忽略。
Q2这是否是一个新的问题?
原有方案的解决思路
Re-sampling methods balance the number of examples by over-sampling the minority class, or under-sampling the majority class. Re-weighting methods assign different weights to different classes or even different samples by cost-sensitive adjustments or meta-learning based methods.
已经有了不少相关研究。在解决类不平衡问题上,传统特征空间中的监督学习已经取得了不错的结果。
使用的是传统的基于特征的监督学习设置(conventional feature-based supervised learning settings) ,而他们在解决类不平衡问题常用办法是两种重采样和重加权。重采样的思路是过采样小样本类数据和降采样大样本数据。重加权可以通过引入loss函数给不同类别样本以不同权重或使用元学习来实现。
这两种办法都是为了提高分类器对小类别数据的敏感程度
图上类不平衡问题的探索:DR-GCN使用双正则化图卷积:类条件对抗正则化器和潜在分布对齐正则化器
Q3这篇文章要验证一个什么科学假设?
想要验证图神经网络算法解决类不平衡问题
Q4有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
在文章的relative works中,作者对当前基于图的异常检测task的works进行了分类。
他将这些works按照问题分为financial fraud detection和opinion fraud detection
在financial fraud detection的task中,现有方法尝试了不同方法在node representation过程中解决问题,比如使用discriminative embedding、引入attention mechanism、应用meta-path的方法
在opinion fraud detection的task中,不同的模型都在尝试不同的方法在node embedding中考虑更多信息
这些都在使用过采样的方法来对抗图上节点数据类不平衡的问题
Q5论文中提到的解决方案之关键是什么?
三个部分 将标签信息纳入节点的特征表示中,让采样更加均衡,让minority class的信息也能纳入考虑,使得feature embedding时,对其是敏感的
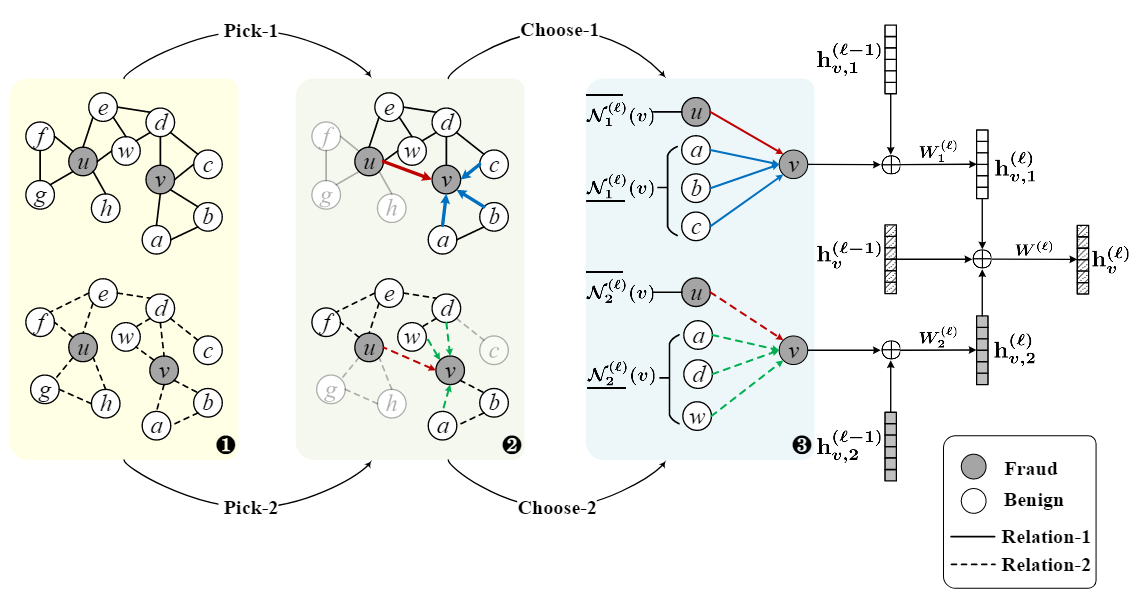
三个part pick choose aggregate
为了解决Q1中提出的两个方面的三个挑战,作者使用了独特的采样结构以获得能够充分捕捉数据集中少类别节点信息的节点向量编码
pick阶段:
目的:为了解决algorithm方面的挑战
方法:使用了一个标签平衡采样器(label-balanced graph sampler)采样节点和边构成子图用于后续的fraud detection
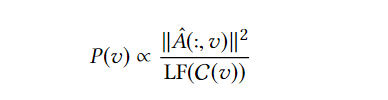
这是pick阶段使用的采样分布,分子对应的是数据集中多关系不平衡图的经标准化的邻接矩阵中节点对应向量,分母衡量了该节点所属类别在数据集中的频度
结果:得到一个标签分布平衡的子图
choose阶段:
目的:解决application方面的挑战
方法:设计了一个特别的邻域采样器(neighborhood sampler),在pick step得到的子图上实现正常节点邻域降采样和fraud节点邻域过采样以破除fraud节点的伪装。在这个步骤中作者引入了一个独特的距离函数(衡量待嵌入节点和待采样点之间的距离)用于过采样和降采样
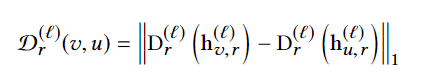
降采样处理:
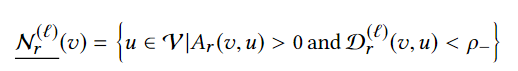
过采样处理
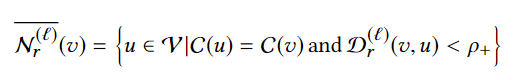
aggregate阶段
分为两个step来完成,先计算出每一个relation下当前节点的特征表示,然后再对每个relation下节点的特征表示进行聚合
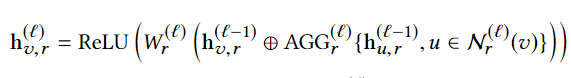
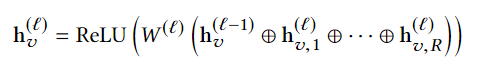
Q6论文中的实验是如何设计的?
数据集
对比实验
实验设置
评价指标
使用了F1-macro、AUC、GMean三个指标
实验结果性能对比
分组对比
GraphConsis和CARE-GNN是当前的fraud detection的sota模型
GraphSAGE和GraphSAINT是具有代表性的采样方法
GCN、GAT是传统gnn方法,DR-GCN是使用双正则化方法来处理多关系不平衡类图的GCN方法
消融实验
在financial fraud检测中,PC-GNN取得了最好的效果,证明了其两个关键步骤pick和choose的有效性
而在opinion fraud检测中,PC-GNN在F1-macro上结果不理想,于是作者研究了具体的各个类别上的F1 score,结果发现是PC-GNN的两个variants在F1-benign上有更好的结果。另外,在Amazon数据集上发现PC-GNN/p出现了两个类别的F1-score都高于PC-GNN,于是作者猜测PC-GNN适合更加大的数据集,当PC-GNN去除其pick部分时,使用全部的节点数据会得到一个更好的F1-score表现
参数设置分析
作者进行了training ratio的分析,分析的是数据集划分对模型性能的影响
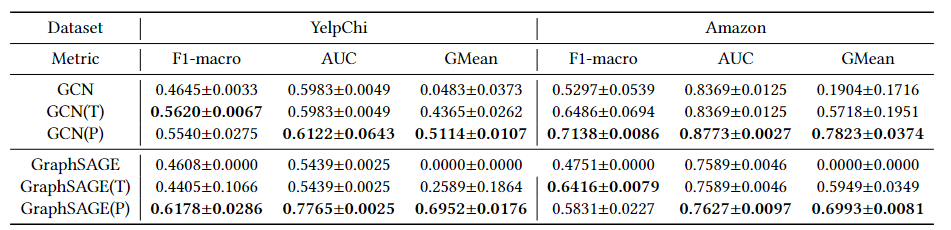
将当前PC结构移植到其他的GNN模型上的效果?
作者尝试将pick结构移植到其他gnn模型中,文中使用的是GCN和GraphSAGE,并同时对比了加入threshold-moing策略的gnn模型,在review spammer数据集上进行实验。结果证明使用pick结构利用子图进行训练的模型比使用阈值移动的模型有更好的效果
Q7用于定量评估的数据集是什么?代码有没有开源?
YelpChi数据集 和 Amazon数据集 是检测spam review的
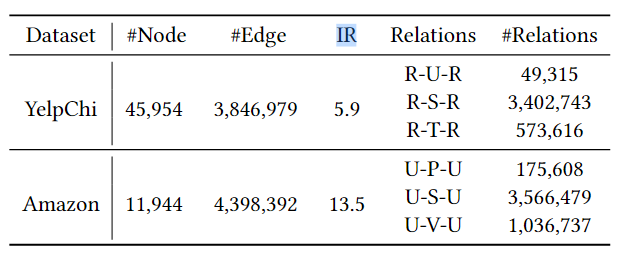
(IR: 数据集的不平衡程度,
I
R
=
∣
C
1
∣
∣
C
2
∣
IR = \frac{|C_1|}{|C_2|}
IR=∣C2∣∣C1∣, 其中
C
1
C_1
C1为多类样本)
这两个数据集中节点都是100维的向量,并且都包含三种关系(即多关系类不平衡图)
另外有从Alibaba拿到的现实世界的检测financial fraud的数据集M7和M9
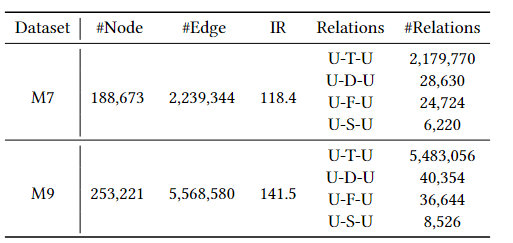
这两个数据集中的节点是908维,包含四种关系
代码开源
Q8论文中的实验及结果有没有很好地支持需要验证的科学假设?
yes
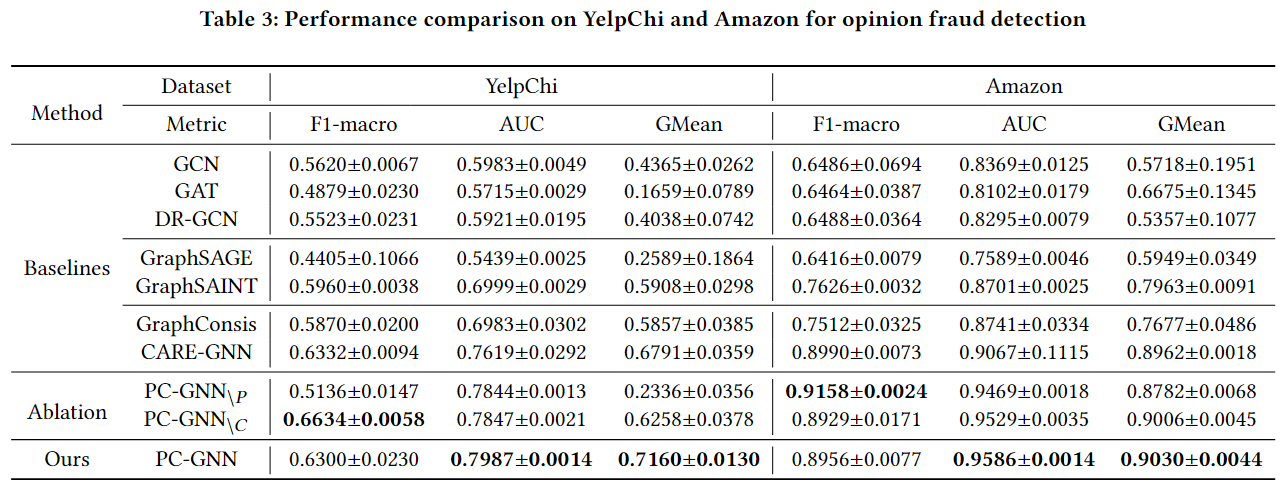
为了探究Pick和Choose两个模块各自的作用,作者做了消融实验来探究。其中PC-GNN/p是不含label-balanced sampler的网络而使用原始的标签分布以构建采样子图的策略
而PC-GNN/c是不含领域采样器的网络而采取直接聚合各个邻域内结构信息的策略
作者将当前的一些sota方法及其增强版本作为baseline进行对比实验。值得一提的是,作者在增强baseline方法时使用了threshold-moving strategy 即改变分类阈值,使得baseline能够达到最好的G1-score和GMean指标
Q9这篇论文到底有什么贡献?
对图上节点异常检测任务提出了两个创新方法
首先通过使用标签平衡采样器得到一个类分布更加平衡的子图样本以解决在使用GNN进行特征嵌入时小样本类被忽视的问题
其次通过邻域采样器在节点特征表示采样时加入距离限制以去除冗余的连接以解决欺诈节点伪装的问题,与此同时小样本节点还通过过采样来增加连接。
文章提出的PC-GNN在现有的图异常节点检测的数据集上验证了其有效性
Q10下一步呢?有什么工作可以继续深入?
作者指出除了本文使用的基于标签的采样方法在数据上进行改进,还可以尝试在不平衡类图上使用一个全新的图神经网络的结构
知识点查询
关于评价指标
F1-macro、AUC、GMean
首先,对于分类问题,我们要了解混淆矩阵
这里以二分类问题中的混淆矩阵为例
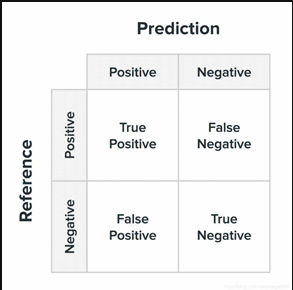
每一列代表预测类别,每一行代表实际类别
在混淆矩阵中样本被分为了四个类别
True Positive(TP): 真正类,样本的实际类别和预测类别都是正类
False Positive(FP): 假正类, 样本的预测类别是正类 实际类别是负类
True Nagative(TN): 真负类, 样本的实际类别和预测类别都是负类
False Nagative(FN): 假负类,样本的预测类别是负类,实际类别是正类
将混淆矩阵应用到多分类问题上
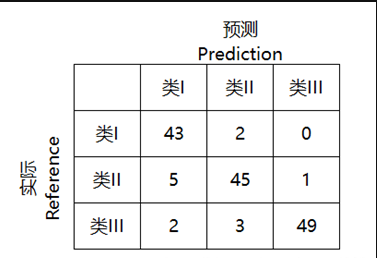
混淆矩阵的作用
对分类问题的预测结果的总结 展示了当前分类模型在预测时会对哪一部分产生混淆,了解到分类模型所犯错误,实现了结果的分解
从混淆矩阵中获得分类指标
精确率(Accuracy)
A
c
c
u
r
a
c
y
=
T
P
+
T
N
T
P
+
T
N
+
F
N
+
F
P
Accuracy = \frac{TP+TN}{TP+TN+FN+FP}
Accuracy=TP+TN+FN+FPTP+TN
表示模型的精度,即模型识别正确样本数/样本总数
准确率(Precision)
P
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
Precision = \frac{TP}{TP+FP}
Precision=TP+FPTP
也称查准率,即在模型识别为正类的样本中有真正为正类的样本占比
召回率(Recall)
R
e
c
a
l
l
=
T
P
T
P
+
F
N
Recall = \frac{TP}{TP+FN}
Recall=TP+FNTP
也称查全率,即模型能识别出来的正类样本在所有正类中的占比
区分精确率和准确率
Accuracy是对全部数据的判断,其假设数据类别分布是均衡的
Precision是对某一个类别的判断
F
β
s
c
o
r
e
F\beta score
Fβscore
F
β
F\beta
Fβ是将正确率和召回率的加权平均,
β
\beta
β代表的是二者合并时的权重分配,即Recall是Precision的
β
\beta
β倍
F1_score:将Recll和Precision视为同等重要。计算的是Recall和Precision的调和平均数
ROC曲线和AUC指标
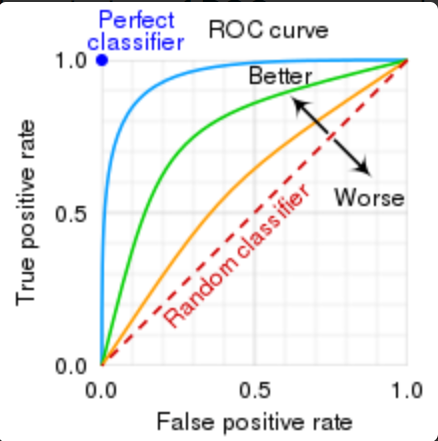
横坐标:伪正率FPR,预测类别为正但实际类别为负的样本占所有负类样本的比例
纵坐标:真正率TPR,预测类别和实际类别均为正的样本占所有正类样本的比例
ROC曲线上变化的是分类阈值,分类阈值针对的是样本被预测为正类的概率,当分类阈值最小为0时,所有样本均被预测为正类,对应坐标(1,1);当分类阈值开始增大时,FPR和TPR均减小,如果模型的预测效果足够好,在分类阈值上升时,FPR的减小程度应该是大于TPR的减小程度的,而理想状态下,随着分类阈值的增大,TPR应当不会减小的。一般情况下,对于分类阈值为1的情况,ROC曲线对应的是(0,0)坐标点。
为了衡量我们的分类器的性能,引入了AUC(Area Under Curve)指标,它被定义为ROC曲线下的面积,取值范围为0.5~1,AUC为1的是完美分类器,AUC为0.5的是随机猜测没有预测价值的分类器。
AUC的意义:随机一个正样本和一个负样本,根据当前分类模型计算得到的score将此正类样本排在负类样本前面的概率
为什么实验ROC曲线
当测试集中正负样本分布变化时,ROC曲线能保持不变。这是实际数据集上常常出现的类不平衡问题的分类task的首选指标
GMean
Precision和Recall的几何平均
可视为模型在正类别上的平衡性能指标
F1_macro
各个类别F1值的平均数
F1_micro
直接计算总体的F1值
参考资料
- 混淆矩阵简介https://blog.csdn.net/qq_38436431/article/details/120538673?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522169467178916800226555309%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=169467178916800226555309&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-1-120538673-null-null.142v94chatsearchT3_1&utm_term=%E6%B7%B7%E6%B7%86%E7%9F%A9%E9%98%B5&spm=1018.2226.3001.4187

















 5050
5050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









