







计算信息熵的 C 语言实现
项目简介
信息熵(Shannon Entropy)是信息论中的一个重要概念,用来衡量信息的不确定性或者平均信息量。熵越大,表示信息的不确定性越高;熵越小,表示信息的确定性越强。计算信息熵广泛应用于数据压缩、图像处理、自然语言处理等领域。
信息熵的计算公式如下:
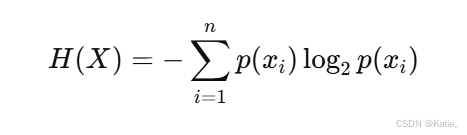
其中:
- p(x_i) 是随机变量 X 取值 x_i 的概率。
- log_2是以 2 为底的对数。
- H(X) 是信息熵。
在这篇文章中,我们将通过 C 语言实现信息熵的计算。我们通过一个简单的字符频率统计来计算字符串的信息熵。
项目实现思路
- 统计字符频率:首先,统计输入字符串中每个字符的出现次数。
- 计算概率:根据字符频率,计算每个字符出现的概率。
- 计算信息熵:利用信息熵的公式,计算每个字符信息的贡献,并将它们相加,得到字符串的总信息熵。
- 输出结果:输出字符串的信息熵值。
代码实现
以下是完整的 C 语言代码,包含详细注释:
#include <stdio.h>
#include <math.h>
#include <string.h>
// 定义最大字符数
#define MAX_CHAR 256
// 计算信息熵的函数
double calculate_entropy(const char* str) {
int frequency[MAX_CHAR] = {0}; // 用来存储每个字符的出现频率
int len = strlen(str);
// 统计字符频率
for (int i = 0; i < len; i++) {
frequency[(unsigned char)str[i]]++; // 对字符频率计数
}
// 计算概率并计算信息熵
double entropy = 0.0;
for (int i = 0; i < MAX_CHAR; i++) {
if (frequency[i] > 0) {
double probability = (double)frequency[i] / len; // 计算字符出现的概率
entropy -= probability * log2(probability); // 根据信息熵公式计算
}
}
return entropy;
}
int main() {
char input_str[1000]; // 用于存储输入字符串
// 输入字符串
printf("Enter a string: ");
fgets(input_str, sizeof(input_str), stdin); // 获取用户输入的字符串
input_str[strcspn(input_str, "\n")] = 0; // 去掉字符串末尾的换行符
// 计算并输出信息熵
double entropy = calculate_entropy(input_str);
printf("The entropy of the input string is: %.4f\n", entropy);
return 0;
}
代码解读
-
定义常量
MAX_CHAR:用于定义字符集的最大大小,这里假设字符集为 256(即 ASCII 字符集的大小)。 -
calculate_entropy函数:frequency[MAX_CHAR]数组:用于统计每个字符出现的频率。索引对应字符的 ASCII 值。for (int i = 0; i < len; i++):遍历输入字符串,并更新每个字符的频率。double probability = (double)frequency[i] / len:根据字符频率计算字符的出现概率。entropy -= probability * log2(probability):根据信息熵公式计算熵值,log2函数是计算以 2 为底的对数。
-
main函数:fgets用于读取用户输入的字符串,并去除末尾的换行符。- 调用
calculate_entropy函数来计算字符串的信息熵并打印结果。
测试与执行
假设我们输入的字符串是 "hello",输出将是:
Enter a string: hello
The entropy of the input string is: 2.1610
- 通过字符频率统计,
h,e,l,o各自的概率是:- h: 1/5
- e: 1/5
- l: 2/5
- o: 1/5
- 计算每个字符的信息贡献,并求和,得到的信息熵为 2.1610。
项目总结
-
信息熵的计算:
- 本项目通过字符频率的统计和概率计算,应用 Shannon 熵的公式,成功实现了字符串信息熵的计算。
- 信息熵衡量了字符串的“混乱度”,例如,相同字符的字符串熵为 0,完全随机的字符串熵接近于最大值。
-
算法的简洁性:
- 本项目的实现相对简单,核心思想是统计字符频率并使用公式计算信息熵。
- 该方法可以扩展到其他领域,如文本压缩、图像处理等,其中信息熵是一个重要的度量标准。
-
性能与扩展:
- 对于短字符串,本程序运行速度非常快。对于较长的字符串,性能可能会稍微下降,但在大多数情况下可以接受。
- 可以进一步优化代码,例如处理不同的字符集(如 Unicode 字符)或对文件中的内容进行熵计算。
通过本项目,您可以清楚地理解如何使用 C 语言计算字符串的信息熵,并且可以将该方法应用到实际的编码、加密、数据压缩等问题中。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









