







前言
这些是我练习后觉得应该记录下来的,当然那些方法很多,这里展示的只是我想到的,其他我想不到的我就没写出来,欢迎大家补充
1.将字符串变为列表
原字符串:"1,2,3,4,5"
法1:
代码
string="1,2,3,4,5"
l=list(string)
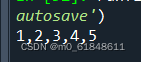
print(l)输出结果

注意,不能直接写成list(string)就完了,因为字符串是不可变对象,需要重新赋值才可,否则这样子输出的是原来的字符串,后面很多的练习也是这种情况,要重新赋值才可以
string="1,2,3,4,5"
list(string)
print(string)输出结果
法2:
代码
string="1,2,3,4,5"
l=string.split(',')
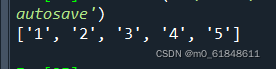
print(l)输出结果,可以看到字符串变为了列表,但是输出结果中已经没有逗号了,因为split时将逗号作为分隔符将字符串分开
2.查找目标字符串中某个字符的位置
目标字符串:"I am the one"
目标字符:"m"
法1:
使用find()函数,目标字符串.find(目标字符),返回的是目标字符所在的下标,如果字符串中含有多个该目标字符,则会返回第一个下标
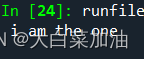
string="I am the one"
target='m'
print(string.find(target))输出结果
![]()
法2:
设置一个循环,将列表元素与目标字符比较,若是一样,则输出其坐标
string="I am the one"
target='m'
for i in string:
if i==target:
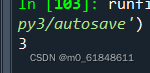
print(string.index(i))输出结果
法3
但是按上面的写法,当有多个目标字符在目标字符串中时,它匹配到后面的目标字符,输出的下标仍然还是第一个匹配到目标字符的坐标位置
所以可以写成这样,我把字符串先转为列表,然后再去匹配,如果这个数字的下标对应列表元素与目标字符相同那么就就输出该位置,也就是输出该目标字符串中目标字符出现的下标了
string="I am the onem"
target='m'
l=list(string)
for i in range(0,len(l)):
if l[i]==target:
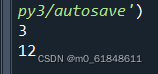
print((i))输出结果
3.提取字符串中的特定内容
目标字符串:"I am the one , you love"
要求提取:单个字母:”m“
一个单词:”am“
一句话:”I am the one“
法1:
如果目标字符串中有多个该字母,它会全部输出,但这种方法只适合提取单个字母,但是实际上,这里的i不是列表中的元素,只是等于列表元素的元素
string="I am the one , you love"
target='m'
for i in string:
if target in i:
print(i)只适合提取单个字母的也可以这样写
string="I am the one , you love"
target='m'
for i in string:
if i==target:
print(i)法2:
将字符串转为列表,然后循环比对,匹配了就输出
单一字母的,就直接用list()转换字符串就可以
string="I am the one , you love"
target='m'
l=list(string)
for i in l:
if target in i:
print(i)如果要真正提取列表中元素可以通过将i作为下标,然后提取列表中元素
string="I am the one , you love"
target='m'
l=list(string)
for i in range(0,len(l)):
if l[i]==target :
print(l[i])单词的,用split()处理字符串
string="I am the one , you love"
target='am'
l=string.split(" ")
for i in l:
if target in i:
print(i)这种方法不适合提取一段话
法3:
说到提取内容,关键就是在于匹配,我们可以使用正则表达式匹配
一个字母一个单词都可以这样写,这样有字符串中有多少个目标都会输出
import re
string="I am the one , you love am"
target='am'
result=re.findall('(am)',string)
print(result)输出结果
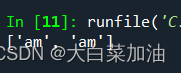
提取一句话
import re
string="I am the one , you love "
target='I am the one'
result=re.findall('^(.*ne)',string)
print(result)输出结果

我觉得正则表达式用起来很灵活,像从字符串类型的数据中提取内容的,我感觉在爬虫解析网页时用得比较多,用正则表达式就是一个很好的选择,但是呢也很容易出错,有好有坏
4.替换字符串的内容
法1:
用replace函数
string="I am the one , you love "
target='were'
new=string.replace('am','were')
print(new)输出结果
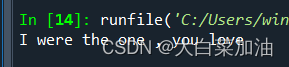
法2:
先把字符串变为列表,然后替换内容,再用join函数把列表变为字符串
string="I am the one , you love "
target='were'
new=string.split(' ')
new[1]=target
new=' '.join(new)
print(new)输出结果

5.去掉字符串内容
法1:
字符串变列表,再用remove函数,可以移去指定单词,但是只能移走最前面的那个如果有多个在字符串中,如果想去掉多个的可以设置while循环
string="I am the one , you love "
target='am'
new=string.split(' ')
new.remove(target)
string=" ".join(new)
print(string)输出结果
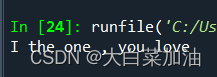
法2:
用replace函数去掉空字符,也可以去掉指定的字符
string="I am the one , you love "
string=string.replace(" ","")
print(string)输出结果
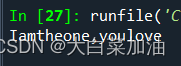
法3:
用strip()去掉首尾空字符,也可以用来去除首尾指定字符
string=" I am the one , you love "
print(string)
string=string.strip()
print(string)输出结果
lstrip()去掉左边空字符/左指定字符,rstrip()去掉右边空字符/右指定字符
6.向字符串里添加内容
法1:
使用+,然后重新赋值
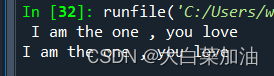
string=" I am the one "
target='I am the best '
new=string+','+target
print(new)输出结果
法2:
将字符串变为列表后使用insert插入,后变回字符串
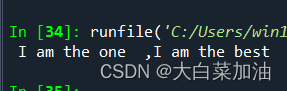
string=" I am the one "
target='I am the best '
l=list(string)
l.insert(len(l)-1,target)
new=''.join(l)
print(new)
输出结果:

法3:
使用join向字符串里面添加空格
string=" I am the one "
l=list(string)
l=' '.join(l)
print(l)
输出结果:

7.改变字符串中的大小写
变大写:
法1:
所有首字母变大写
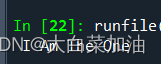
string=" I am the one "
string=string.title()
print(string)输出结果:
法2:
所有字母变大写
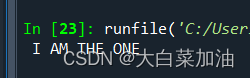
string=" I am the one "
string=string.upper()
print(string)输出结果:
变小写:
法1:
所有字母变小写
string=" I am the one "
string=string.lower()
print(string)输出结果:















 176
176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









