






 文章分析了一家电商公司在1月8日至10日的促销活动中,各项关键指标的增长情况,如GMV、净销售额、订单数、用户数,以及性别、年龄分布对营收的影响。同时,通过ARPU和ARPPU计算了收入与活跃用户和付费用户的比例,发现活动效果显著,提出针对女性用户和青年客群的优化策略。
文章分析了一家电商公司在1月8日至10日的促销活动中,各项关键指标的增长情况,如GMV、净销售额、订单数、用户数,以及性别、年龄分布对营收的影响。同时,通过ARPU和ARPPU计算了收入与活跃用户和付费用户的比例,发现活动效果显著,提出针对女性用户和青年客群的优化策略。
项目背景
为了更好的回馈新⽼⽤户,提⾼平台整体销售额,某公司决定1月8号到1月10号时间段全平台开展为期三天的“满减”促销活动,为了评估此次活动的整体效果同时为后续的促销活动提供相应的数据⽀持,根据相关活动数据,通过活动效果分析对此次活动进⾏了相应的分析。
数据来源
订单明细数据和用户数据
分析目的
1. 对活动期间前后营收(GMV、净销售额等)对比作总结
2. 对活动期间前后产品销售情况(订单数、付费用户数等)和拒退情况比较作总结
3. 对活动期间前后渠道拉新、营收、转化、客群贡献对比作总结
4. 分析哪些客群对营收贡献更大作总结
结论与意见
1.活动期间GMV上升了137.69%,净销售额上升了72.73%订单数上升了146.17%、付费用户数上升了91.07%,可见活动达到了很好的效果,后期可以多尝试此类活动。
2.男性的GMV为7913545.0,女性的GMV为16168496.0,可见平台可以针对⼥性⽤户进⾏适当的优化,⼀⽅⾯营造购物氛围,⼀⽅⾯减少犹豫时间。
3.主要消费的年龄阶段为青年占比0.577224,其次为中年占比0.385380,可见平台多对青年客群进行相对的优惠对策
分析过程及代码
指标指示
| 指标 | 解释 |
| GMV | GMV(总交易额、成交总额) |
| ARPU | 指总收入与活跃用户数量的比率。具体计算公式为:ARPU = 总收入 / 活跃用户数量 |
| ARPPU | 是指总收入与付费用户数量的比率。具体计算公式为:ARPPU = 总收入 / 付费用户数量 |
| 拒退率 | 拒绝收货退款率 |
数据理解
| 列名 | 解释 |
| discount | 折扣 |
| orderID | 订单ID |
| userID | 用户ID |
| num | 数量 |
导包:
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'].insert(0, 'SimHei') # 设置字体样式
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
get_ipython().run_line_magic('config', "InlineBackend.figure_format = 'svg'") # 设置图形输出格式为SVG
加载数据
加载订单明细数据
orders_df = pd.read_excel('电商运营数据/order2023.xlsx', true_values=['是'], false_values=['否'])
orders_df
加载用户数据
users_df = pd.read_excel('电商运营数据/user2023.xlsx', usecols=['userID', 'age', 'sex', 'date', 'channelID'])
users_df.rename(columns={'chanelID': 'channelID'}, inplace=True)
users_df
数据处理
查看时间区间
活动时间:1月8日到1月10日进行了为期三天的活动
数据来源:1月5日到1月13日的订单明细数据和用户数据
- 宣传期:1月5日 ~ 1月7日
- 活动期:1月8日 ~ 1月10日
- 返场期:1月11日 ~ 1月13日
orders_df.orderTime.describe() #统计指标并返回它们的值

可见最大小的时间(即最早最晚的时间)为2023-01-05 00:01:11和2023-01-13 23:59:45,时间对得上的
查看空值
users_df.isna().sum()

orders_df.isna().sum()

可见订单明细数据表有空值,
空值处理:
orders_df.discount.fillna('', inplace=True)
orders_df.discount.replace(r'\s', '', regex=True, inplace=True)orders_df.isna().sum()

空值处理完成
查看折扣类型
orders_df.discount.unique()

注意第一个空的并不是空值而是该商品没有折扣的
# 给订单数据打标记(宣传期、活动期、返场期)
def make_tag(day):
if day < 8:
return '宣传期'
elif day < 11:
return '活动期'
else:
return '返场期'
orders_df['seg'] = orders_df.orderTime.dt.day.map(make_tag)
orders_df['seg'] = orders_df.seg.astype('category').cat.reorder_categories(['宣传期', '活动期', '返场期'])
orders_df
对活动期间前后营收(GMV、净销售额等)分析
# 统计三个阶段的GMV、销售数量、订单数量和用户数量
temp1 = pd.pivot_table(
orders_df,
index='seg',
values=['orderAmount', 'num', 'orderID', 'userID'],
aggfunc={
'orderAmount': 'sum',
'num': 'sum',
'orderID': 'nunique',
'userID': 'nunique'
}
).rename(
columns={
'orderAmount': 'GMV',
'num': '销售数量',
'orderID': '订单数量',
'userID': '用户数量'
}
)
temp1

# 统计三个阶段的净销售额、净销售数量、成交订单数、成交用户数
temp2 = pd.pivot_table(
orders_df.query('not chargeback'),
index='seg',
values=['payment', 'num', 'orderID', 'userID'],
aggfunc={
'payment': 'sum',
'num': 'sum',
'orderID': 'nunique',
'userID': 'nunique'
}
).rename(
columns={
'payment': '净销售额',
'num': '净销售数量',
'orderID': '成交订单数量',
'userID': '成交用户数量'
}
)
temp2

# 拼接两张表的数据
metrics = pd.concat((temp1, temp2), axis=1).reindex(
columns=['GMV', '净销售额', '销售数量', '净销售数量', '订单数量', '成交订单数量', '用户数量', '成交用户数量']
)
metrics

可见活动期的数据有明显的上升
数据不太直观,咱们来做可视化图
x = metrics.index.values.tolist()
y1 = metrics.GMV.values.tolist()
y2 = metrics.净销售额.values.tolist()from pyecharts.globals import CurrentConfig, NotebookType
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_LAB
from pyecharts.charts import Bar
from pyecharts import options as optsbar = Bar(init_opts=opts.InitOpts(width='720px', height='360px'))
bar.add_xaxis(x)
bar.add_yaxis('GMV', y1)
bar.add_yaxis('净销售额', y2)
bar.load_javascript()bar.render_notebook()
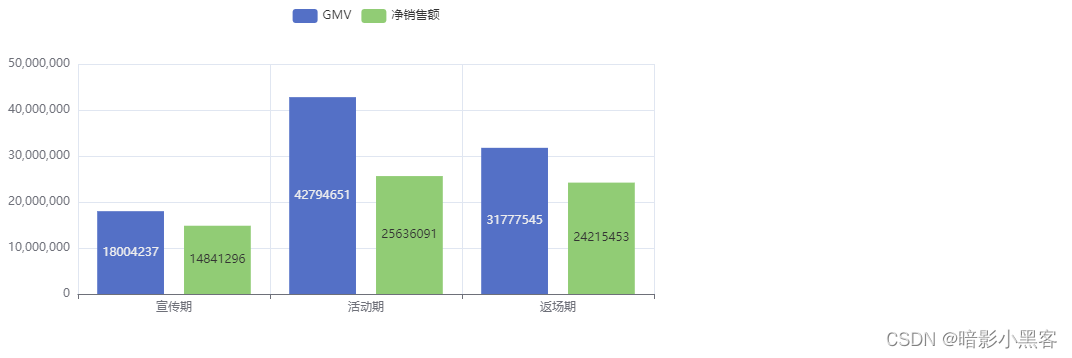
这样就很明显的看出活动期的数据是最高的
添加客单价和拒退率
metrics['客单价'] = (metrics.净销售额 / metrics.用户数量).round(2)
metrics['拒退率'] = ((metrics.订单数量 - metrics.成交订单数量) / metrics.订单数量).round(4)
metrics.style.format(formatter={'拒退率': '{:.2%}', '客单价': '{:.2f}'})

可见活动期的拒退率也上升了
把数据跟上一个对比

可见从宣传期到活动期间GMV上升了137.69%,净销售额上升了72.73%订单数上升了146.17%、付费用户数上升了91.07%,可见活动达到了很好的效果,
数据重塑
为什么要数据重塑?
因为订单明细数据里有点
# 统计每个用户的购买数量、订单数量、消费金额
temp3 = pd.pivot_table(
orders_df,
index='userID',
values=['orderID', 'num', 'payment'],
aggfunc={
'orderID': 'nunique',
'num': 'sum',
'payment': 'sum'
}
)
temp3['buy'] = True # 是否购买
temp3
# 连表(用户表和上面的表进行左外连接,引入维度数据)
merged_df = pd.merge(users_df, temp3, how='left', on='userID')
merged_df
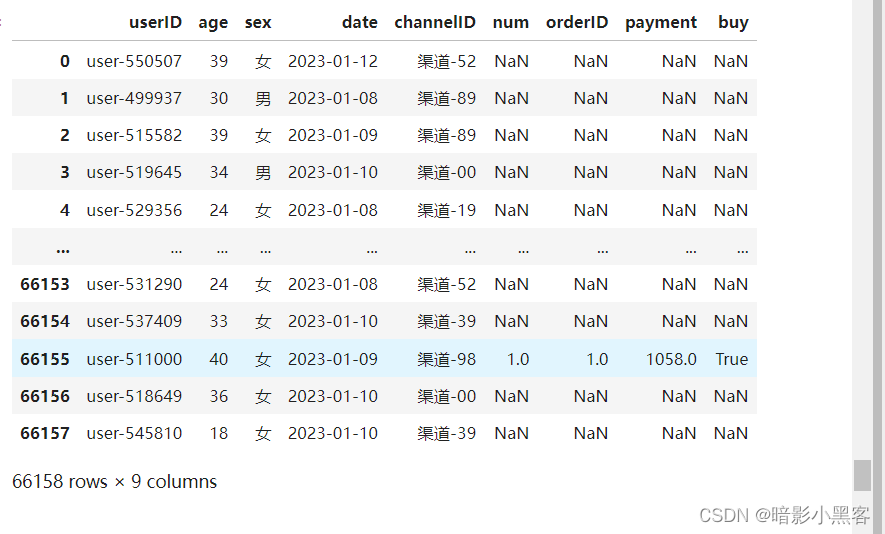
这些nan就是没有下单的客户
渠道分析
# 统计每个渠道的销售额、销售数量、订单数量、活跃人数、购买用户数量
temp4 = pd.pivot_table(
merged_df,
index='channelID',
values=['payment', 'num', 'orderID', 'userID', 'buy'],
aggfunc={
'payment': 'sum',
'num': 'sum',
'orderID': 'sum',
'userID': 'count',
'buy': 'count',
}
).rename(
columns={'payment': '销售额', 'num': '销售数量', 'orderID': '订单数量', 'userID': '活跃人数', 'buy': '购买用户数'}
).reindex(
columns=['销售额', '销售数量', '订单数量', '活跃人数', '购买用户数']
)
temp4.sort_values(by='活跃人数', ascending=False)
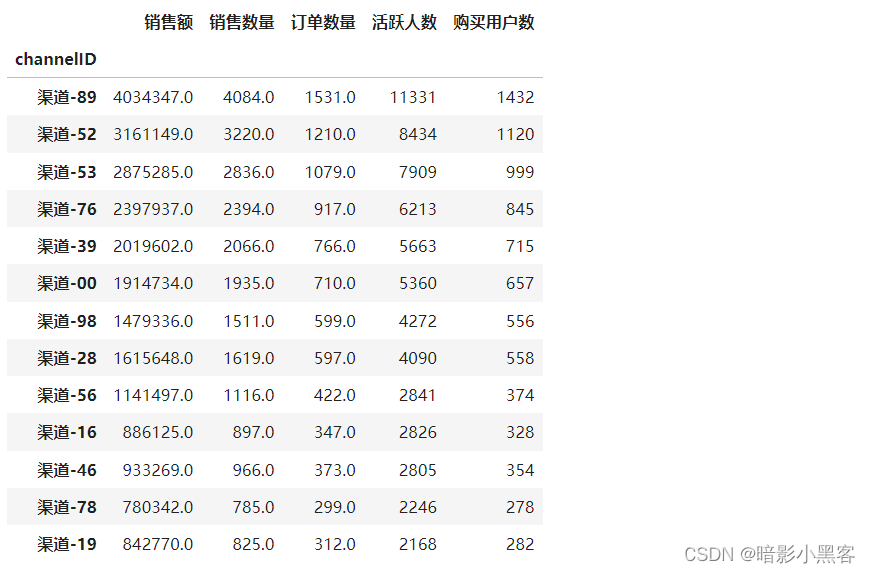
# 统计不同渠道的转化率和客单价
temp4['转化率'] = temp4.购买用户数 / temp4.活跃人数
temp4['ARPU'] = temp4.销售额 / temp4.活跃人数# 输出格式设置
temp4.style.format({
'销售数量': '{:.0f}',
'订单数量': '{:.0f}',
'转化率': '{:.2%}',
'ARPU': '{:.2f}',
'ARPPU': '{:.2f}'
})
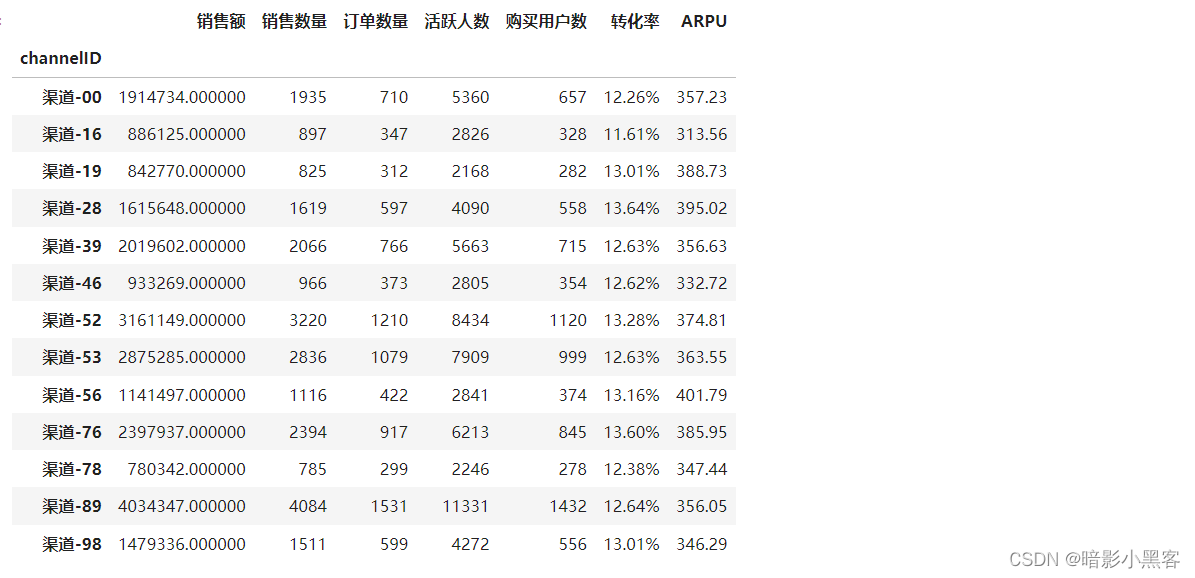
对客群的性别价值分析
# 统计不同性别的销售额、销售数量、订单数量、拉新用户数量、购买用户数量
temp4 = pd.pivot_table(
merged_df,
index='sex',
values=['payment', 'num', 'orderID', 'userID', 'buy'],
aggfunc={
'payment': 'sum',
'num': 'sum',
'orderID': 'sum',
'userID': 'count',
'buy': 'count',
}
).rename(
columns={'payment': 'GMV', 'num': '销售数量', 'orderID': '订单数量', 'userID': '拉新用户数', 'buy': '购买用户数'}
).reindex(
columns=['GMV', '销售数量', '订单数量', '拉新用户数', '购买用户数']
)
temp4

# 统计不同性别的销售额、销售数量、订单数量、活跃人数、购买用户数量
temp5 = pd.pivot_table(
merged_df,
index='sex',
values=['payment', 'num', 'orderID', 'userID', 'buy'],
aggfunc={
'payment': 'sum',
'num': 'sum',
'orderID': 'sum',
'userID': 'count',
'buy': 'count',
}
).rename(
columns={'payment': 'GMV', 'num': '销售数量', 'orderID': '订单数量', 'userID': '活跃人数', 'buy': '购买用户数'}
).reindex(
columns=['GMV', '销售数量', '订单数量', '活跃人数', '购买用户数']
)
temp5

可见,男性的GMV为7913545.0,女性的GMV为16168496.0,可见平台可以针对⼥性⽤户进⾏适当的优化,
对客群的年龄价值分析
# 对比年龄段的状况
def make_age(age):
if age < 18:
return '青少年'
elif age < 40:
return '青年'
elif age < 60:
return '中年'
else:
return '老年'users_df['age_group'] = orders_df.orderTime.dt.day.map(make_age)
users_df['age_group'] = pd.cut(users_df['age'], bins=[0, 18, 40, 60, float('inf')], labels=['青少年', '青年', '中年', '老年']).astype('category')# 显示更新后的users_df
users_df
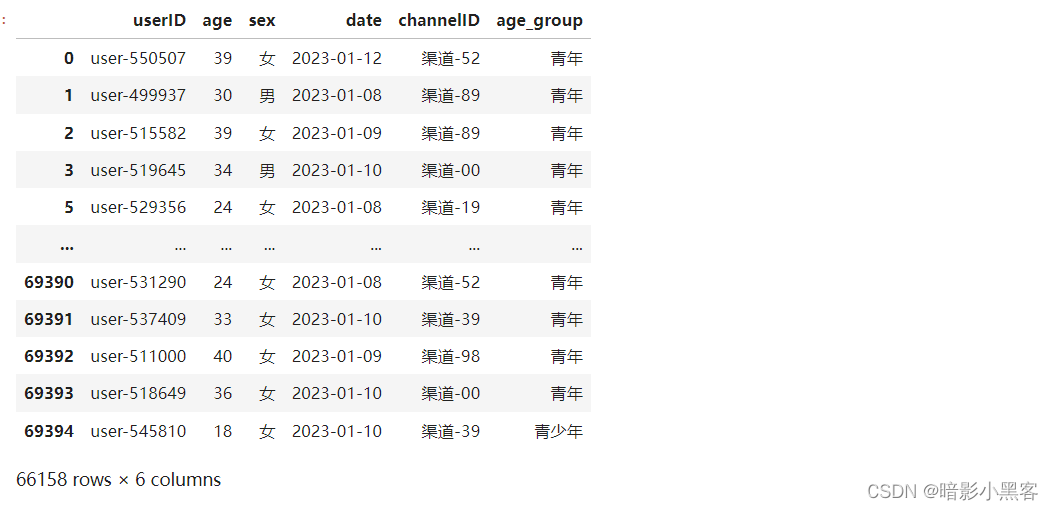
unique_count = users_df['userID'].nunique()
# 总人数
print(unique_count)
![]()
# 每个年龄段的人数占比
age_groups = users_df.groupby(pd.cut(users_df['age'], bins=[0, 18,40, 60, float('inf')], labels=['青少年', '青年', '中年','老年'])).size()
print(age_groups /unique_count)

可见,主要消费的年龄阶段为青年占比0.577224,其次为中年占比0.385380,可见平台多对青年客群进行相对的优惠对策



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











