






这周主要工作在于大模型微调的实现,利用第四周提取的规范jsonl数据作为微调数据集
微调环境准备

在 InternStudio 平台,为了节省时间可以从本地 clone 一个已有 pytorch 2.0.1 的环境:
/root/share/install_conda_env_internlm_base.sh xtuner0.1.9激活环境后新建微调目录,从github上拉取xtuner源码:
进入源码目录,安装Xtuner

发现安装错误,取github的issue中看到是开发版本的固有问题,故选择更换更新版本的xtuner0.1.17

发现还是不行,调试之后发现是其中的deepspeed的问题。去Xtuner官网InternLM/xtuner: An efficient, flexible and full-featured toolkit for fine-tuning large models (InternLM2, Llama3, Phi3, Qwen, Mistral, ...) (github.com)
直接下载xtuner0.1.9,成功安装
配置准备
在assistant/data目录下传入之前处理好的jsonl数据集formatted_data2.jsonl,新建model/Shanghai_AI_Laboratory/目录存放InternLM的模型文件
copy Xtuner自带的oasst1数据集配置文件到config目录,修改配置文件,修改的地方有
pretrained_model_name_or_path ,data_path,evaluation_inputs,dataset,
dataset_map_fn等等,具体配置文件见repository的assistant/config/assistant_internlm_chat_7b_qlora_oasst1_e3.py
开始微调
微调耗时比较久,为避免因终端关闭或 SSH 连接断开导致任务终止, 我使用 screen 命令将实验进程与终端窗口分离
screen -S train分离会话按Ctrl-A然后按D,然后就可以睡觉去了,服务器挂着训练
微调结束后,要结束并释放会话时可以:
screen -X -S train quit可以看到,eta(Estimated Time of Arrival)字段显示的估算时间,训练时间三个多小时就可以了: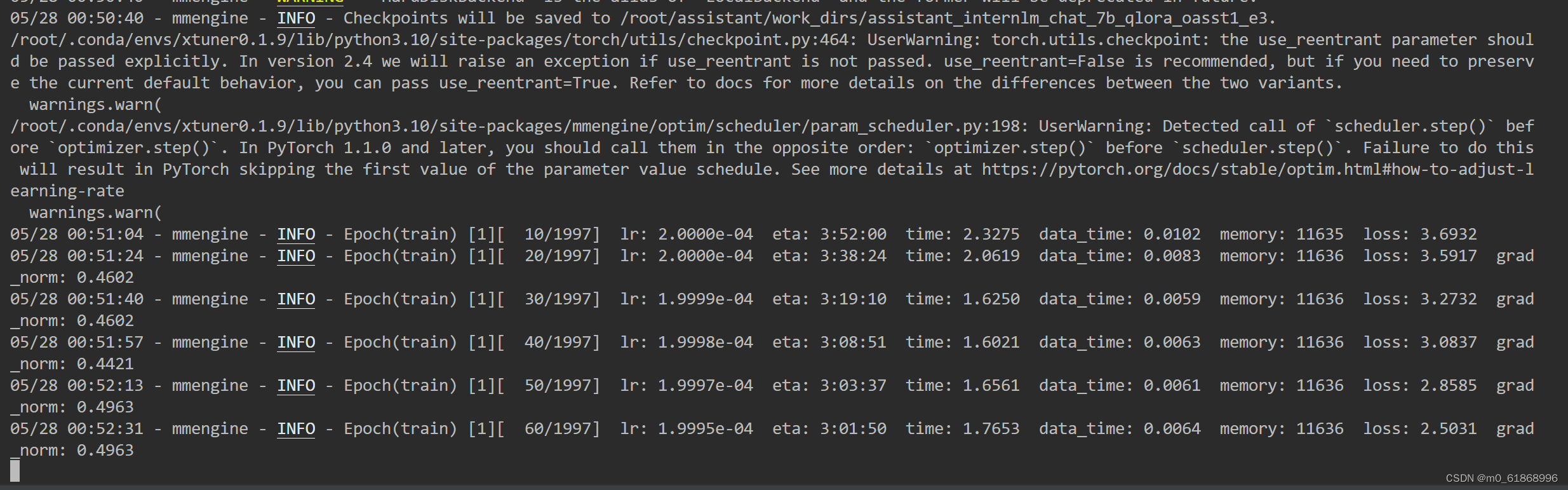
如果还想更快的话可以开启deepspeed加速整体的训练过程
DeepSpeed是一个深度学习优化库,由微软开发,旨在提高大规模模型训练的效率和速度。它通过几种关键技术来优化训练过程,包括模型分割、梯度累积、以及内存和带宽优化等。DeepSpeed特别适用于需要巨大计算资源的大型模型和数据集。
在DeepSpeed中,zero 代表“ZeRO”(Zero Redundancy Optimizer),是一种旨在降低训练大型模型所需内存占用的优化器。ZeRO 通过优化数据并行训练过程中的内存使用,允许更大的模型和更快的训练速度。ZeRO 分为几个不同的级别,主要包括:
-
deepspeed_zero1:这是ZeRO的基本版本,它优化了模型参数的存储,使得每个GPU只存储一部分参数,从而减少内存的使用。
-
deepspeed_zero2:在deepspeed_zero1的基础上,deepspeed_zero2进一步优化了梯度和优化器状态的存储。它将这些信息也分散到不同的GPU上,进一步降低了单个GPU的内存需求。
-
deepspeed_zero3:这是目前最高级的优化等级,它不仅包括了deepspeed_zero1和deepspeed_zero2的优化,还进一步减少了激活函数的内存占用。这通过在需要时重新计算激活(而不是存储它们)来实现,从而实现了对大型模型极其内存效率的训练
考虑到模型较小,训练时间也不算久,可以接受,我选择采用deepspeed_zero2来进行加速,可以看到,加速后,eta只有两个多小时了:

查看显存占用,显存占用为13G:
















 172
172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









