




经过之前SadTalker源码解读,并且经过实验发现,数字人三个阶段preprocess,audio_to_coeff,animate_from_coeff中,第一阶段preprocess花了近一半时间,故考虑优化这部分。
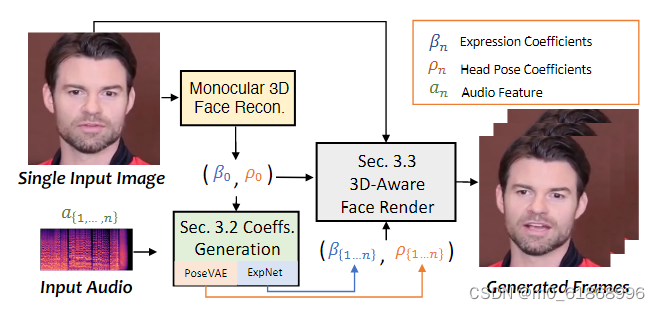
之前的源码分析可以发现,preprocess主要是进行图片的裁剪,标准化,然后进行3DMM特征的提取,其中特征提取部分使用的是resnet50,如果是视频输入则每一帧都要过resnet50,图片的话只要一次就行。该模块就是总体模块中的monocular3D face recon部分:
英语口语训练助手实际上不需要每次自己传图片,而是可以让用户选则特定的角色来进行对话,对于特定的角色,实际上可以用固定的图片和音频,音频的实现再之后讨论。
由于我们各个阶段的函数和模块都封装的很好了,只需要将第一阶段的模块单独拿出来,图片路径设置为我们提供的角色图片,预先提取出preprocess产生的参数,即存到mat文件中,下次使用直接访存就行了:
from src.utils.init_path import init_path
from src.utils.preprocess import CropAndExtract
import os
config_path='/root/avatar/src/config'
checkpoint_path='/root/avatar/checkpoints'
devi 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









