







 本文介绍了机器学习的基础概念,包括与人工智能的关系、基本术语、算法分类和通用步骤。接着讨论了模型评估中的过拟合、欠拟合和交叉验证法,并深入讲解了线性模型、神经网络的激活函数、损失函数和SVM。此外,还涵盖了聚类算法如K-means和DBSCAN。
本文介绍了机器学习的基础概念,包括与人工智能的关系、基本术语、算法分类和通用步骤。接着讨论了模型评估中的过拟合、欠拟合和交叉验证法,并深入讲解了线性模型、神经网络的激活函数、损失函数和SVM。此外,还涵盖了聚类算法如K-means和DBSCAN。
目录
一.机器学习概念
1.机器学习与人工智能关系
机器学习的核心是:使用算法解析数据,从中学习,然后对世界上的某件事情做出决定或预测。这意味着机器学习是非显著式编程。机器学习重在发现数据之间内在关系,并做出预测。
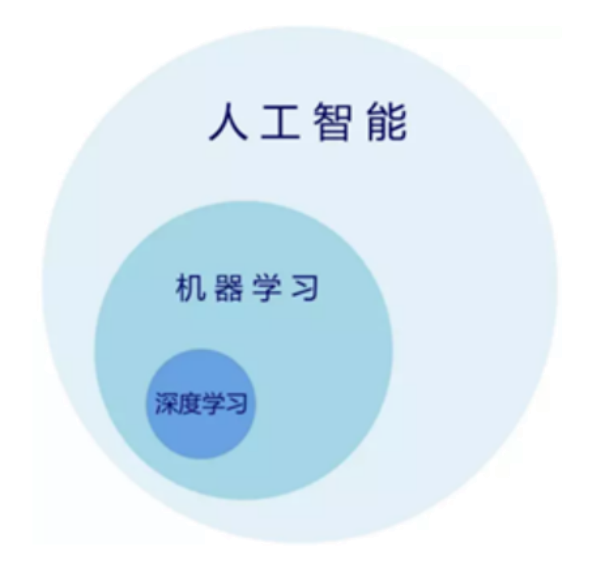
机器学习是人工智能的一个分支,使用特定的算法和编程方法来实现人工智能。人工智能致力于创造出比人类更能完成复杂任务的机器。深度学习是机器学习的一个子集,专注于模仿人类大脑的生物学和过程。
2.基本术语

1. 数据集:一组样本的集合。
2. 样本:数据的特定实例,每条记录是关于一个对象的描述。
3. 属性:反映对象在某方面的表现或性质的事项。
4. 属性空间:属性张成的空间。
5. 维数:每个示例由d个属性描述,d称为样本的"维数"。
6. 训练数据:训练过程中使用的数据称为"训练数据"
9. 标记:关于示例结果的信息,例如"好瓜"。
10.测试:学得模型后,使用模型进行预测得过程。
3.算法分类
监督学习:分类、回归
样本带有标签值,称为监督信号,有学习过程,根据数据学习,得到模型,
然后用于预测。按照标签值的类型可以进一步分为两类:
分类问题:标签值为离散值。
回归问题:标签值为实数。
无监督学习:聚类、降维
样本没有标签值,没有训练过程,机器学习算法直接对样本进行处理,得到某
种结果。
半监督学习:两者结合
有些训练样本有标签值,有些没有标签值,用这些样本进行训练得到模型,然
后用于预测,介于有监督学习与无监督学习之间。
4.机器学习通用步骤
1. 选择数据:划分训练数据、测试数据、验证数据。
2. 数据建模: 使用训练数据来构建模型。
3. 训练模型:数据接入模型,确定模型的类型,参数等。
4. 测试模型:使用测试数据检查被训练模型的表现(精确率、召回率)。
5. 验证模型: 使用完全训练好的模型在新数据上做预测。
6. 调优模型:使用更多数据、不同的特征或调整过的参数来提升算法的性能。
二.模型评估与选择
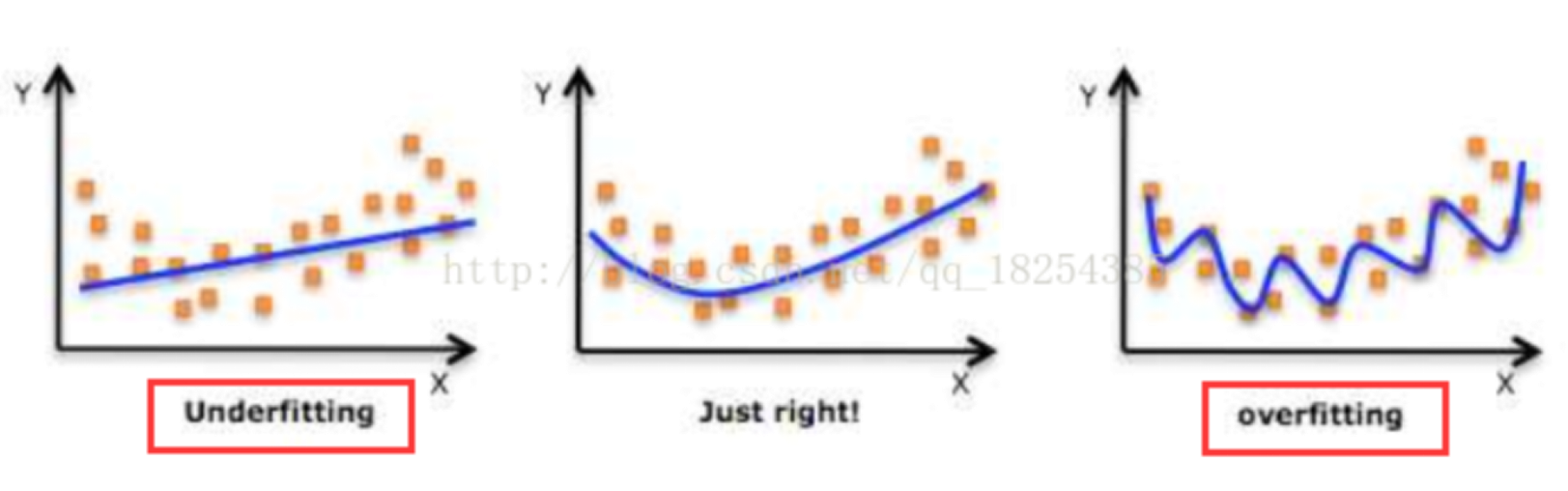
1.过拟合和欠拟合
过拟合:
学习器将训练样本本身的特点当做所有样本的一般性质,学习器把训练样本学习的“太好”,学到了很多没必要的特征,导致泛化性能下降。
欠拟合:
训练样本的一般性质尚未被学习器学好。
防止过拟合的方法:
1. 数据集扩增:获得更多符合要求的数据。
2. 改进模型,通过控制模型的复杂度来防止过拟合:
a. 优化目标加正则项, 通过L1和L2正则项。
b. 深度网络的常见方法:early stop(当loss不再减小时,提前结束训练)/Dropout(在每个训练批次中,随即丢掉一定数量的神经元)策略。
防止欠拟合的方法:
1.增加新特征,可以考虑加入组合特征、高次特征,来增大假设空间。
2. 尝试非线性模型,比如核SVM 、决策树、DNN等模型。
3. 增加网络的复杂度。
4. 减少使用正则化数量。
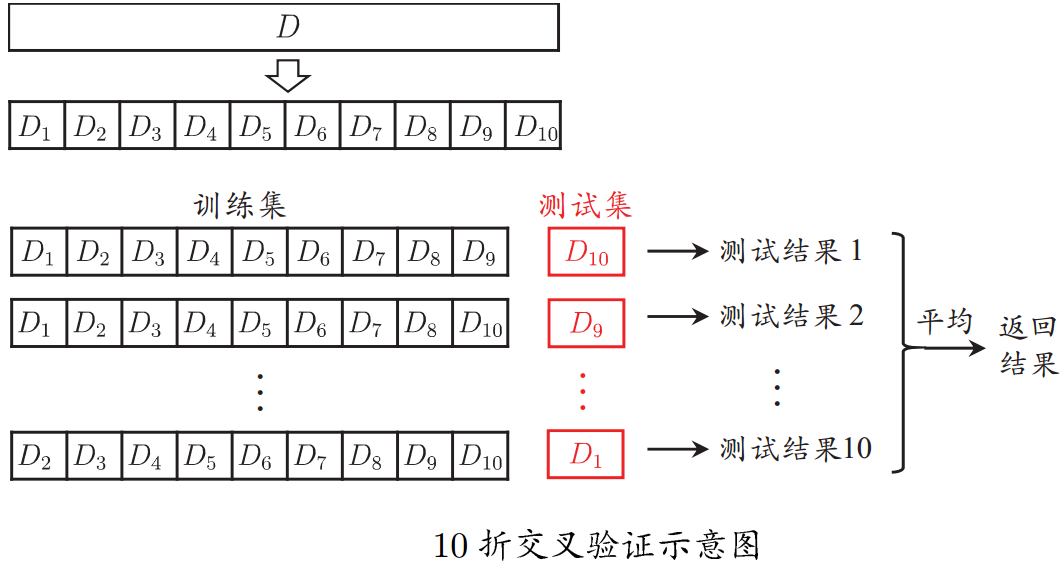
2.交叉验证法
将数据集分层采样划分为k个大小相似的互斥子集,每次用k-1个子集的并集作为训练集,余下的子
集作为测试集,最终返回k个测试结果的均值,k最常用的取值是10。
交叉验证法优点:可以有效地利用有限的数据进行模型的训练和验证,提高模型的泛化性能;由于每个样本都被用于验证一次,因此对模型的评估更加稳定和准确。
交叉验证法缺点:计算成本高,因为需要进行K次训练和验证,尤其是当数据集很大时,这可能会非常耗时。K值的选择会影响到交叉验证的效果。如果K值选得太小,例如K=2,那么训练集和验证集的划分可能过于随机,模型的评估结果可能波动较大;如果K值选得太大,例如K等于样本总数,那么虽然评估结果较为稳定,但是计算成本会非常高。
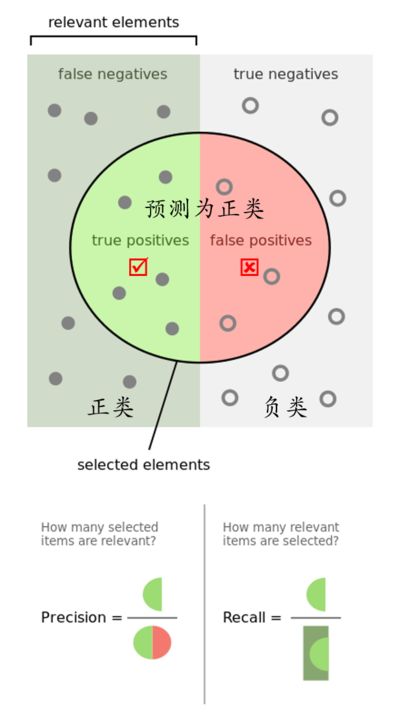
3.性能度量
对于分类任务,错误率和精度是最常用的两种性能度量。
错误率:分错样本占样本总数的比例。
![]()
精度:分对样本占样本总数的比率。
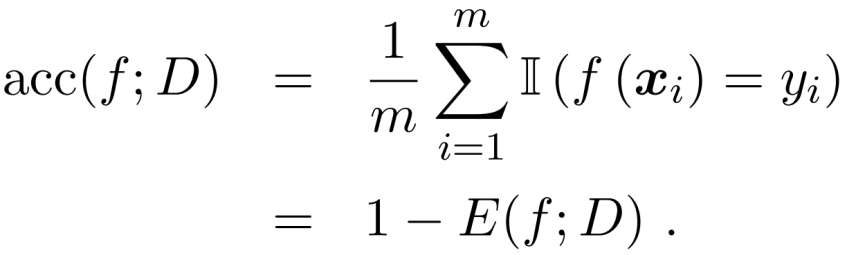

正样本精确率为:Precision=TP/(TP+FP),表示的是 正样本识别正确总数 / 所有预测为正样本的样本总数。
正样本召回率为:Recall=TP/(TP+FN),表示的是 正样本识别正确总数 / 实际正样本总数。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











