







文章目录
前言
之前介绍了顺序表,这种线性的数据结构。本文将介绍另一种线性结构链表。链表有8种结构,本文主要介绍最简单的一种无头单向非循环链表,为以后学习其它链表结构做铺垫。
1.链表的相关介绍
1.什么是节点
早在结构体的博客中就提到了链表。链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
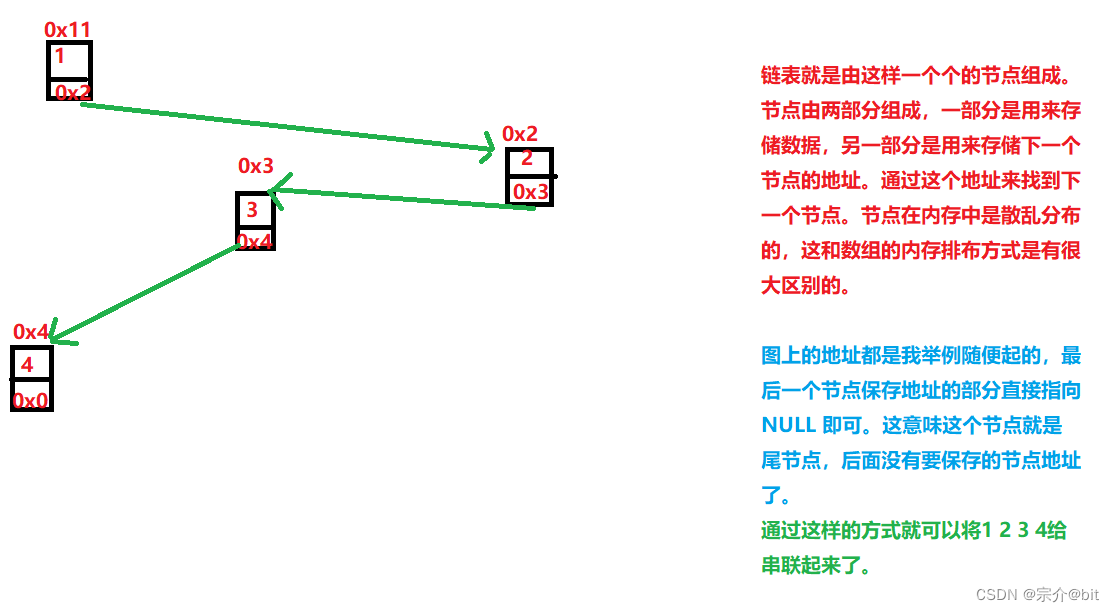
我们可以类比一下数组,我们知道数组在内存中的排布是一片连续的空间。数组名是首元素地址,通过数组名加上偏移量即可访问相应的内存空间。链表也是通过链表头节点去访问每个节点。但是节点在内存中是散乱排布的,所以当前的节点都要保存下一个节点的·地址,通过这个地址找到依次找到每个节点,最后的一个节点保存地址的部分直接保存空指针即可,因为后续已经没有节点了。
2.链表和顺序表的对比
顺序表和链表都可以用来存储数据,这两者有何区别呢?我们知道如果是静态的顺序表,顺序表存储数据的最大个数是被限定了的,如果数据过多顺序表的容量就可能会不够,如果数据过少顺序表的部分空间就会被浪费。就算是使用动态的顺序表也会有这样的问题。同时动态顺序表的扩容是需要申请新空间,拷贝数据,释放旧空间。会有不小的消耗。在插入和删除数据时,都需要频繁的的挪动数据。反观链表,链表是需要插入一个数据就申请一个节点,随用随取,也不用挪动数据,只需要将原来两个节点断开,插入数据后在将相应的节点连起来。删除数据也只用找到对应的节点释放其空间,之后再将原来相应节点连接起来即可。当然顺序表也有优点,不然顺序表早就淘汰了,就不用再去学了。以后会详细介绍的,本文主要介绍链表。
链表节点都是malloc申请的,最大的原因是:如果使用局部变量表示节点出了相应的作用域就会被销毁,如果采用全局变量和静态变量表示节点,当要销毁节点的时候,无法操作。使用malloc函数,在堆区开辟相应的空间存储节点,就可以解决上述的问题。当然使用malloc函数来申请节点空间还有方便操作节点访问节点等诸多好处,这里就不在深究了。
3.链表的种类
实际中链表的结构非常多样,以下情况组合起来就有8种链表结构:
1. 单向或者双向
2. 带头或者不带头
3. 循环或者非循环
以上种类各自两两组合就是2 * 2 * 2=8种。
虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构。
分别是:无头单向非循环链表, 带头双向循环链表。
无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了,这个后续会介绍。
本文介绍的就是无头单向非循环链表
2.链表的实现
1.节点的定义和创建
链表是由一个个节点构成的,在创建链表之前的首先需要声明定义节点。
代码示例
#define SLTDataType int
typedef struct SListNode
{
SLTDataType data;//数据域
struct SListNode* next;//地址域
}SListNode;
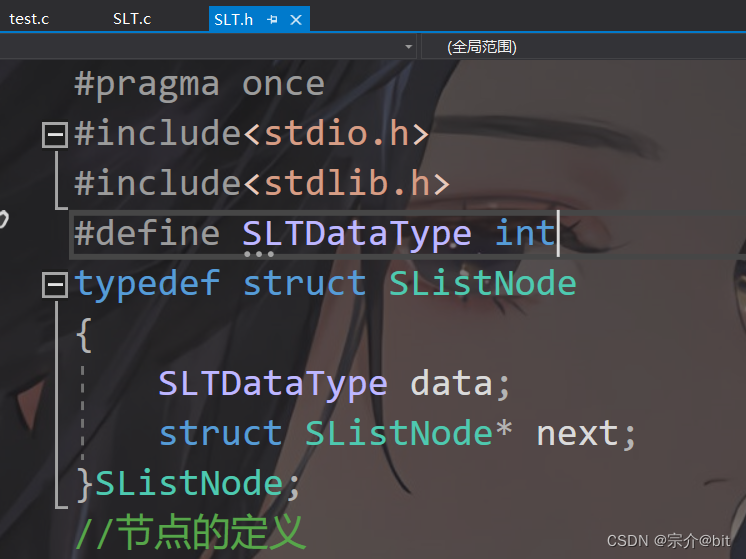
节点由两部分组成,一部分是用来保存数据的就是数据域,另一部分是指针域,指针域是用来保存下一个节点的地址的。#deifne预处理指令将int重新命名成SLTDataType,这样做的好处是存储其他类型数据时,只需要改动预处理指令即可,代码的复用性比较好。
我在写单链表的时候是建了3个文件的,两个.c文件一个.h文件这样更加规范一点。在给变量或者函数命名的时候不要随便起名尽量要规范一点养成良好的编程习惯。
节点的创建
当要插入数据或者链表初始化的时候,肯定会新增节点,所以我们直接将创建节点这个过程封装成函数来实现。
代码示例
SListNode* BuySListNode(SLTDataType x)//申请一个节点
{
SListNode* new_node = (SListNode*)malloc(sizeof(SListNode));
if (new_node != NULL)//判断是否申请成功
{
new_node->data = x;//插入数据
new_node->next = NULL;//地址域指向空
return new_node;
}
else
{
perror("malloc fail\n");//申请失败打印信息
exit(-1);//直接退出
}
}
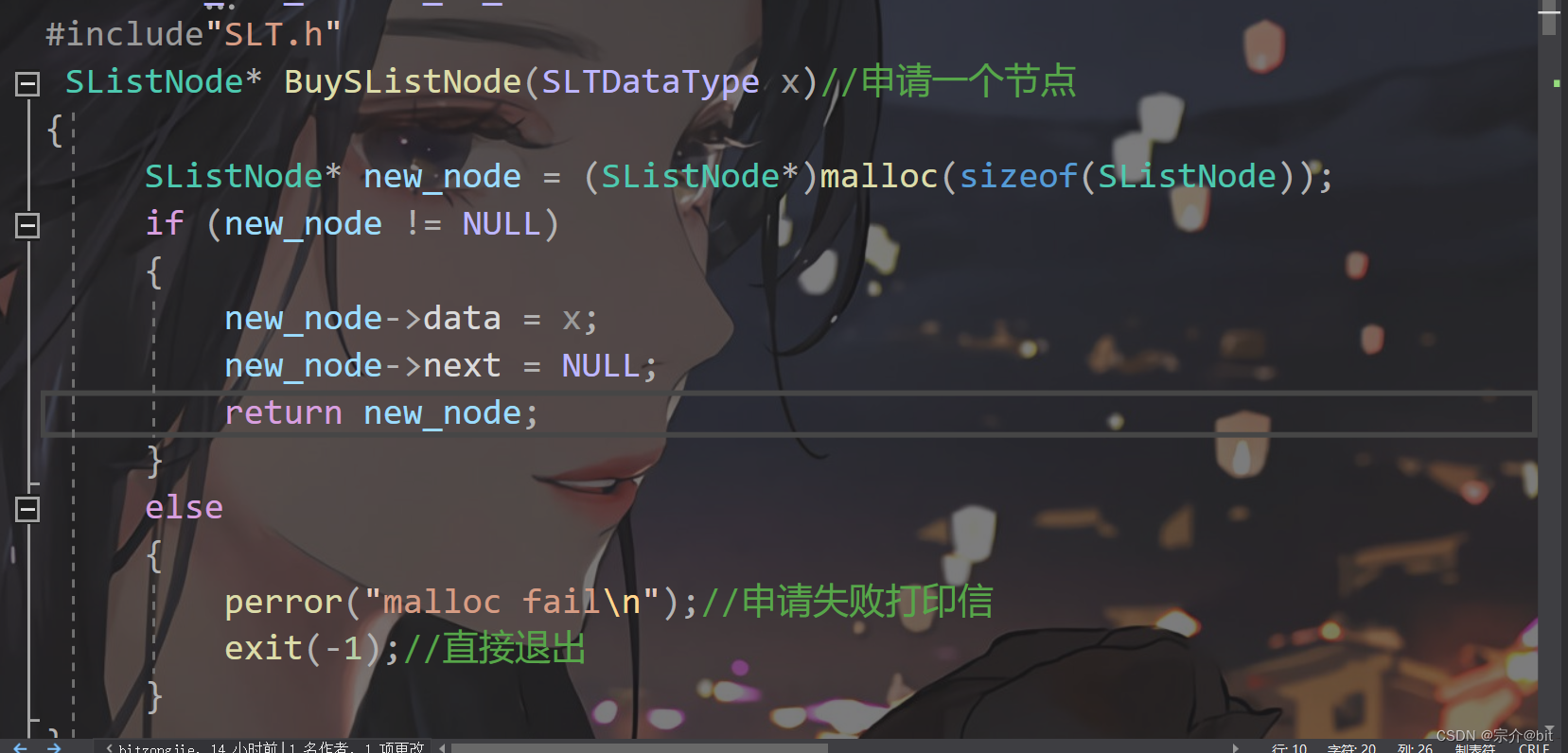
用malloc函数动态申请节点空间,将数据插入节点的数据域中,指针域暂且初始化为空。返回值类型是指针,将新节点的地址返回,后续用相应的变量来接收。
2.链表的相关函数接口的实现
链表相关的函数接口大概有以下几种:
void Print(SListNode* plist);//打印显示
void Create(SListNode** plist,int n);//创建链表
void SListPushBack(SListNode** plist,SLTDataType X);//尾插
void SListPushFront(SListNode** plist, SLTDataType x);//头插
void SListPopBack(SListNode** plist);//尾删
void SListPopFront(SListNode** plist);//头删
void SListDelete(SListNode** plist, SListNode* pos);//指定位置删除
SListNode* SListFind(SListNode* plist, SLTDataType x);//查找
void SListInsertAfter(SListNode* pos, SLTDataType x);//在pos之后插入数据
void SListDestory(SListNode** plist);//销毁链表**
1.链表的创建
首先实现链表的创建
代码示例
void Create(SListNode**plist,int n)//创建初始化
{
SListNode** phead = plist;//链表头节点
SListNode* ptail =NULL;//链表尾节点
for (int i = 0; i < 5; i++)
{
SListNode* new_node = BuySListNode(i + 1);
if (*phead == NULL)
{
ptail = new_node;
*phead = new_node;
//第一个节点 头尾都是自己
}
else
{ ptail->next = new_node;
ptail = new_node;
}
}
return;
}
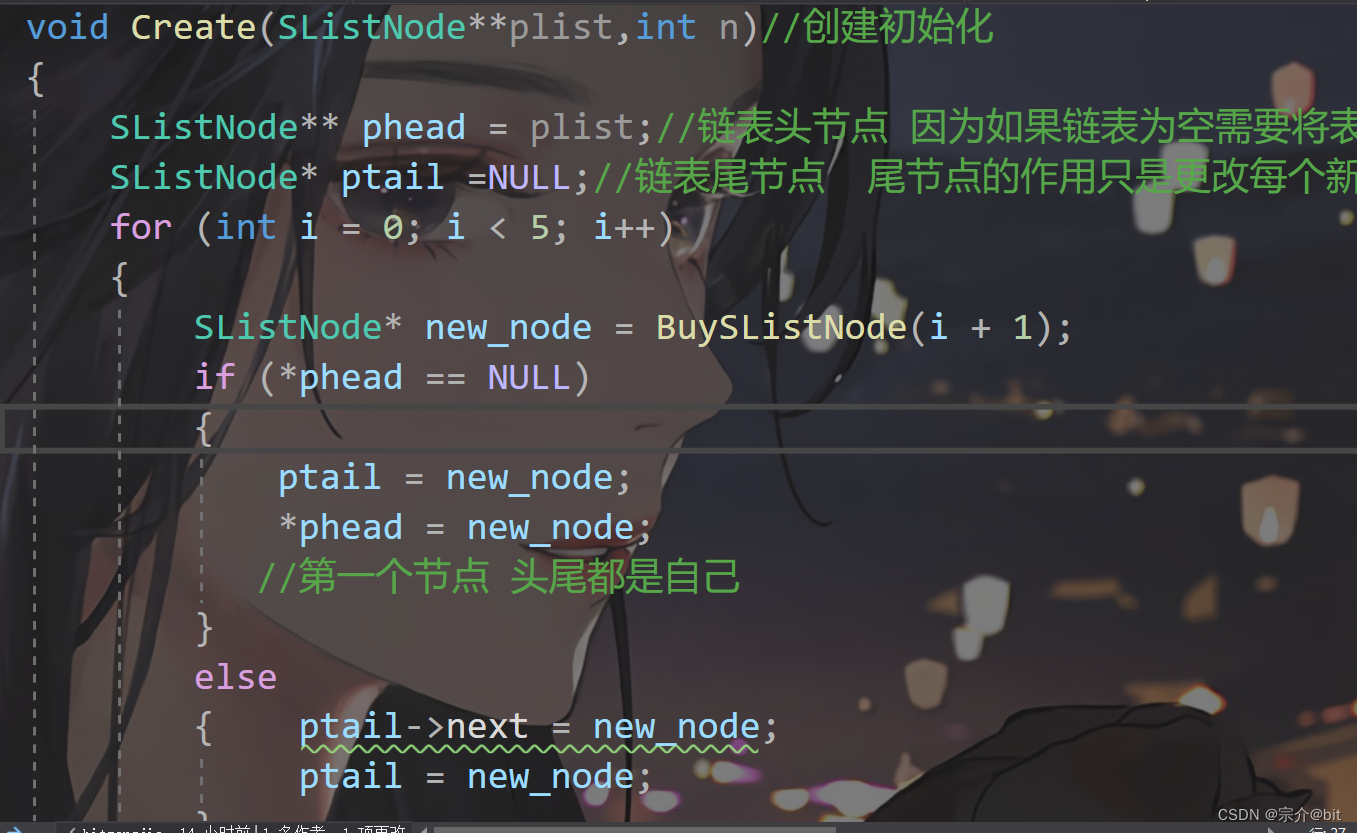
这个链表创建函数就相当于对链表进行了初始化。链表头节点为什么用的是二级指针呢? 因为如果链表为空需要将表头更改 头是一级指针所以这个head要用二级指针 要改什么就是什么访问什么的地址。链表尾节点为什么用的是一级指针呢? 尾节点的作用只是更改每个新节点的next 所以不用二级指针 。只有一个节点时头节点和尾节点都是自己,头节点的地址域指向空,当节点的数量大于1时,头节点的地址域要指向下一个节点的地址,此时ptial尾节点进行更新。此时的尾节点也不再是头节点了,所以增加一个节点ptail更新一次。数据域我采用的是直接赋值的形式初始化,当然也可以用输入数据的方式进行数据域的初始化,不过上述代码也要进行相应的更改。
2.数据的插入
链表的数据插入分为3种方式,和顺序表类似分别是尾插头插和指定位置插入。
头插
头插的方式就是在链表头处进行数据插入,此时的链表头需要更新成新的链表头,既然要更改链表头所以采用的传参方式就是二级指针,通过访问链表头的地址来更新表头。
代码示例
void SListPushFront(SListNode** phead, SLTDataType x)//头插
{
SListNode** list_head = phead;//链表头
SListNode* new_node = BuySListNode(x);
if (*list_head == NULL)//空链表处理
{
*list_head = new_node;
return;
}
else
{
new_node->next = *list_head;//新节点的next指向旧的链表头
*list_head = new_node;//旧链表头更新成新的链表头
new_node = NULL;//置空避免成为野指针
return;
}
}
插入数据,肯定是要新增节点,所以就调用了BuySListNode函数。当链表为空时,直接将新节点赋值给list_head即可。如果链表不为空,新节点的next要指向就原来旧的链表头节点,旧的链表头更行成新的链表头。
尾插
尾插的实现,第一步就是找尾,找到原来的尾节点之后将该节点的next指向新节点,这样相当于更新了尾节点。
代码示例
void SListPushBack(SListNode** phead,SLTDataType x)//尾插
{
SListNode* ptail = *phead;//尾节点
SListNode*new_node = BuySListNode(x);//创建一个新的节点
if (ptail == NULL)//链表为空
{
*phead = new_node;
return;
}
while (ptail->next != NULL)//找到尾节点
{
ptail = ptail->next;
}
ptail->next = new_node;
ptail = new_node;//更新新的尾节点
new_node = NULL;//置空避免成为野指针
return;
}
既然是尾插数据为啥参数还是二级指针呢?这是因为当链表是空时,尾插数据就相当于是将空的头节点更新成有数据的头节点。所以传二级指针。当链表为空时,只用更新参数phead即可。ptail是一级指针的原因是,ptail主要是用来更新除了头节点就是尾节点之外的链表尾节点的next的。next是节点的一部分,也就是相当于更改节点,既然改节点,那就用节点指针即可。当链表不为空,就先找到尾节点。尾节点的标志就是该节点的next指向空。将链表原来的尾节点next指向新节点,之后将尾节点更新即可。
指定位置插入
链表中的指定位置就是相应节点的位置,也就是节点的地址。那么参数就是一级指针。这个指定位置插入是在指定位置之后插入对应的数据。这只是我的设计方式,你也可以在指定位置之前插入,但是如果在指定的位置之前插入,如果这个位置是链表头就要更新链表头,那就会用到二级指针,但是如果是其他位置插入只用一级指针即可。这样的话函数实现就会有些小麻烦。因为我们实现了头插,想要在链表头插入数据时只用调用头插即可。所以我在采用的方式就是在指定位置之后插入数据。
代码实现
void SListInsertAfter(SListNode* pos, SLTDataType x)
//在pos之后插入数据
{
if (pos == NULL)
{
printf("空指针错误\n");
return;
}
else
{
SListNode* new_node = BuySListNode(x);
SListNode* cur = pos->next;
pos->next = new_node;
new_node->next = cur;
return;
}
}
首先当传入空指针后提示报错然后直接返回,当然也可以用assert断言。如果不是空指针,首先将pos位置的节点next保存起来,在将pos位置节点的next指向新节点。新节点的next指向原来pos位置节点的next。这样新节点就将pos处的节点和原来pos处后一个节点连接起来了。
3.数据的删除
链表数据的删除也是分为3种方式,尾删头删和指定位置删除。链表节点的删除用free释放对应的节点空间即可。但是也要考虑其他节点next指向,及时更新相应的其他节点的next,避免造成野指针问题。
头删
头删就是删除头节点,删除之后头节点也要更新。链表就是靠这个头节点来访问链表中的的数据的。
头删代码示例
void SListPopFront(SListNode** plist)//头删
{
SListNode** phead = plist;
if (*phead == NULL)
{
printf("链表为空\n");
return;
}
SListNode* cur = (*phead)->next;//提前保存头后一个节点的地址
free(*phead);
*phead = cur;//更新新头
return;
}
因为链表头需要更新,所以我们采用的是二级指针来当参数。在释放头节点之前,需要先把头节点的next指向的地址先行保存,不然释放之后就找不到了,之后再释放头节点即可。然后将头节点更新成原来链中的第二个节点。还要记得如果传入链表是空,还要进行相应的处理。
尾删
尾删就是找到尾节点进行相应的删除。但是得先要找到尾节点之前的节点,也就是倒数第二个节点。将该节点的next指向空。
代码示例
void SListPopBack(SListNode** plist)//尾删
{ /*传二级指针是因为当只有一个头节点时需要将头节点置为空,
更改头节点需要用到二级指针*/
SListNode* ptail = *plist;//尾节点
SListNode* cur = NULL;//记录尾节点的前一个节点
if (ptail == NULL)
{
printf("链表为空\n");
return;
}
else if (ptail->next == NULL)
{
free(ptail);//只有一个节点的时候,头节节点要更新成空
*plist = NULL;
return;
}
else
{
while (ptail->next!=NULL)
{
cur = ptail;
ptail = ptail->next;
}
cur->next = NULL;
free(ptail);
ptail = NULL;
return;
}
}
传二级指针是因为当只有一个头节点时需要将头节点置为空,更改头节点需要用到二级指针。cur是用来记录尾节点前的一个节点,也就是倒数第二个节点。当只有一个节点时,如果没有else if语句的判断,cur会造成空指针解引用,从而引发错误。将cur的next置为空,这意味着倒数第二个节点成了新的尾节点。
指定位置删除
指定位置删除,还是要找指定位置处前一个位置的节点,要将该位置处的节点next更新成删除位置处节点的next。这样才能将链表又重新连接起来。这个指定的位置就是节点所在的空间地址,所以位置用节点一级指针表示。
代码示例
//指定位置删除
void SListDelete(SListNode** plist, SListNode* pos)
{
SListNode* cur = *plist;
if (cur == NULL)
{
printf("链表为空\n");
return;
}
if (cur == pos)
{
cur = cur->next;
free(pos);
*plist = cur;
//如果删除的是链表头释放掉头节点后,要将头节点更新
return;
}
while (cur->next)
{
if (cur->next == pos)
{
cur->next = pos->next;
free(pos);
pos = NULL;
return;
}
else
{
cur = cur->next;
}
}
printf("链表中不存在删除的位置\n");
return;
}
这里传二级的原因是,如果删除的位置是头节点就要更新头节点。接着就遍历链表找这个pos,如果某个节点的next指向pos只用将next指向改为pos的next,然后释放pos即可。当遍历完整个链表,没有找见pos说明链表中不存在删除的位置。对于传入空指针还要进行相应的处理。
4.打印显示节点数据
打印显示就是相当于遍历整个链表节点的数据域。
代码实现
void Print(SListNode* plist)//打印显示
{
if (plist == NULL)
{
printf("链表为空\n");
return;
}
SListNode* cur = plist;
while (cur)
{
printf("%d ", cur->data);
cur = cur->next;
}
printf("\n");
return;
}
因为打印只用遍历即可,所以参数类型就是一级指针。当传入空指针时,直接打印空链表。如果不是空指针,就挨个遍历打印。为啥是while(cur)而不是while(cur->next)呢?因为最后一个节点的数据也要打印,while(cur->next)是用来找尾节点的,打印要将每个数据都打印出来,包括尾节点的数据。while判断是非0为真 ,0为假。空指针在也就相当于0,所以while(cur)和while(cur!=NULL)是一样的。
5.数据查找
数据查找还是遍历链表,我们查找的标准是节点数据域的值是否查找的数值。如果是就返回该节点的地址,如果没找到就返回空指针。
代码示例
SListNode* SListFind(SListNode* plist, SLTDataType x)
{
SListNode* pos = plist;
if (pos == NULL)
{
return NULL ;
}
while (pos)
{
if (pos->data == x)
{
return pos;
}
else
{
pos = pos->next;
}
}
return NULL;
}
当链表是空我们也返回空指针。因为要遍历链表所以要传入链表头节点,函数参数一个就是链表头节点,还有一个参数就是查找的数据。因为所有的节点都要遍历到所以是while(pos)。
6.链表销毁
链表销毁就是从头节点到尾节点挨个用free释放节点。这还是有个遍历的过程。
代码示例
void SListDestory(SListNode** plist)//销毁链表
{
SListNode* cur = *plist;
if (cur == NULL)
{
printf("链表为空\n");
return;
}
else
{
while (cur)
{
SListNode* node = cur->next;
free(cur);
cur = node;
}
}
*plist = NULL;
return;
}
链表销毁了头节点要重新置为空,所以参数用的二级指针。但是销毁链表也就是链表使用完毕的时候,所以头节点就不会在使用了。如果销毁了链表后,头节点没置为空也是可以的,但是为了避免野指针,还是建议在销毁链表的时候将头节点置为空。同时销毁链表是一个必要操作,因为链表的节点空间都是申请的动态内存空间,如果不及时释放就会造成内存泄漏。
3.总结
- 1关于参数是一级指针还是二级指针,要想好改变的是什么?想改什么就传什么的地址。
- 2 链表主要是靠头节点来访问每个节点的数据的,在实现链表相关函数时,可以实现一个调试一个。在确保准确无误后,就接着实现下一个函数。这样便于排查错误。
- 3本文只是简单的介绍了单向循环链表的实现,如有问题欢迎指教!谢谢。















 1806
1806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









