







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
解读:
分库:一个电商项目,分为用户库、订单库等等。
分表:一张订单表数据数百万,达到 MySQL 单表瓶颈,分到多个数据库中 的多张表
2.逻辑库
数据库代理中的数据库,它可以包含多个逻辑表
解读:Mycat 里定义的库,在逻辑上存在,物理上在 MySQL 里并不存在。有可能是 多个 MySQL 数据库共同组成一个逻辑库。类似多个小孩叠罗汉穿上外套,扮演一个大 人。
3.逻辑表
数据库代理中的表,它可以映射代理连接的数据库中的表(物理表)
解读:Mycat 里定义的表,在逻辑上存在,可以映射真实的 MySQL 数据库的表。可 以一对一,也可以一对多。
4.物理库
数据库代理连接的数据库中的库,比如mysql上的information_schema
解读:MySQL 真实的数据库
5.物理表
数据库代理连接的数据库中的表,比如mysql上的information_schema.TABLES
解读:MySQL 真实的数据库中的真实数据表。
6.分库分表中间件
实现了分库分表功能的中间件,功能上相当于分库分表型数据库中的计算节点
7.分库分表型数据库
以分库分表技术构建的数据库,在组件上一般有计算节点,存储节点.它的存储节点一般是一个可独立部署的数据库产品,比如mysql
8.拆分键
即分片键,描述拆分逻辑表的数据规则的字段
解读:比如订单表可以按照归属的用户 id 拆分,用户 id 就是
9.分区
一般指数据分区,计算节点上,水平分片表拆分数据的最小区域
10.分区键
当使用等值查询的时候,能直接映射一个分区的拆分键
11.系统表,元数据表
一般指mysql中的information_schema,performance_schema,mysql三个库下的表
12.物理分表
指已经进行数据拆分的,在数据库上面的物理表,是分片表的一个分区
解读:多个物理分表里的数据汇总就是逻辑表的全部数据
13.物理分库
一般指包含多个物理分表的库
解读:参与数据分片的实际数据库
14.单库分表
在同一个数据库下同一个库表拆分成多个物理分表
15.分库
一般指通过多个数据库拆分分片表,每个数据库一个物理分表,物理分库名字相同
解读:分库是个动作,需要多个数据库参与。就像多个数据库是多个盘子,分库就是 把一串数据葡萄,分到各个盘子里,而查询数据时,所有盘子的葡萄又通过 Mycat2 组 成了完整的一串葡萄。
16.分片表,水平分片表
按照一定规则把数据拆分成多个分区的表,在分库分表语境下,它属于逻辑表的一种
17.单表
没有分片,没有数据冗余的表,
解读:没有拆分数据,也没有复制数据到别的库的表。
18.全局表,广播表
每个数据库实例都冗余全量数据的逻辑表.
它通过表数据冗余,使分片表的分区与该表的数据在同一个数据库实例里,达到join运算能够直接在该数据库实例里执行.它的数据一致一般是通过数据库代理分发SQL实现.也有基于集群日志的实现.
解读:例如系统中翻译字段的字典表,每个分片表都需要完整的字典数据翻译字段。
19.集群
多个数据节点组成的逻辑节点.在mycat2里,它是把对多个数据源地址视为一个数据源地址(名称),并提供自动故障恢复,转移,即实现高可用,负载均衡的组件
解读:集群就是高可用、负载均衡的代名词
20.数据源
连接后端数据库的组件,它是数据库代理中连接后端数据库的客户端
解读:Mycat 通过数据源连接 MySQL 数据库
21.schema(库)
在mycat2中配置表逻辑,视图等的配置
22.物理视图
后端数据库中的视图
23.逻辑视图
在mycat2中的逻辑视图是把一个查询语句视为逻辑表的功能
24.前端会话
一般指Mycat服务器中,该会话指向连接mycat的客户端
25.后端会话
一般指Mycat服务器中,该会话指向连接数据库的客户端
26.后端数据库
在数据库代理中,数据库代理连接的数据库
27.透传SQL
在数据库代理中,指从客户端接收的SQL,它不经过改动,在代理中直接发送到后端数据库
28.透传结果集
在数据库代理中,指从后端数据库返回的结果集,不经过改动,转换,写入到前端会话
29.ER表
狭义指父子表中的子表,它的分片键指向父表的分片键,而且两表的分片算法相同
广义指具有相同数据分布的一组表.
解读:关联别的表的子表,例如:订单详情表就是订单表的 ER 表
30.原型库(prototype)
原型库是 Mycat2 后面的数据库,比如 mysql 库
解读:原型库就是存储数据的真实数据库,配置数据源时必须指定原型库
四,MyCat配置文件介绍
1.配置文件
[root@localhost ~]# cd /usr/local/mycat/conf/
[root@localhost conf]# ll
总用量 32
drwxr-xr-x 2 root root 36 6月 28 2021 clusters
drwxr-xr-x 2 root root 41 5月 29 11:01 datasources
-rw-r--r-- 1 root root 3338 3月 5 2021 dbseq.sql
-rw-r--r-- 1 root root 316 11月 2 2021 logback.xml
-rw-r--r-- 1 root root 0 3月 5 2021 mycat.lock
drwxr-xr-x 2 root root 31 6月 28 2021 schemas
drwxr-xr-x 2 root root 6 6月 28 2021 sequences
-rw-r--r-- 1 root root 776 12月 28 2021 server.json
-rw-r--r-- 1 root root 1643 3月 5 2021 simplelogger.properties
drwxr-xr-x 2 root root 233 6月 28 2021 sql
drwxr-xr-x 2 root root 6 6月 28 2021 sqlcaches
-rw-r--r-- 1 root root 49 3月 5 2021 state.json
drwxr-xr-x 2 root root 28 6月 28 2021 users
-rw-r--r-- 1 root root 211 3月 5 2021 version.txt
-rw-r--r-- 1 root root 4165 1月 13 2022 wrapper.conf
clusters:集群
datasources:数据源
server.json:服务配置
user:用户目录
2.用户(user)
配置用户相关信息
1.所在目录
mycat /conf/users
2.命名方式
{用户名}.user.json
3.配置内容
[root@localhost conf]# vi users/root.user.json
{
"dialect":"mysql",
"ip":null,
"password":"123456",
"transactionType":"xa",
"username":"root"
}
#字段含义:
#username:用户名
#password:密码
#isolation:设置初始化的事务隔离级别
#transactionType:事务类型
可选值:
proxy 本地事务,在涉及大于 1 个数据库的事务,commit 阶段失败会导致不一致,但是兼容性最好
xa 事务,需要确认存储节点集群类型是否支持 XA
可以通过语句实现切换
set transaction_policy = 'xa'
set transaction_policy = 'proxy' 可以通过语句查询
SELECT @@transaction_policy
3.数据源(datasource)
配置mycat连接的数据源信息
1.所在目录
mycat /conf/datasources
2.命名方式
{数据源名字}.datasource.json
3.配置内容
[root@localhost conf]# vi datasources/prototypeDs.datasource.json
{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ\_WRITE",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"prototypeDs",
"password":"1234.Com",
"type":"JDBC",
"url":"jdbc:mysql://localhost:3306/mysql?useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8",
"user":"root",
"weight":0
}
字段含义:
dbtype:数据库类型,mysql
name:用户名
password:密码
type:数据源类型,默认JDBC
url:访问数据库地址
idletimeout:空闲连接超时时间
initsqls:初始化sql
initsqlsgetconnection:对于JDBC每次获取连接是否都执行initSqls
instanceType:配置实例只读还是读写 可选值:READ\_WRITE,READ,WRITE
4.集群(cluster)
配置集群信息
1.所在目录
mycat /conf/clusters
2.命名方式
{集群名字}.clusteer.json
3.配置内容
[root@localhost conf]# vi clusters/prototype.cluster.json
{
"clusterType":"MASTER\_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetry":3,
"minSwitchTimeInterval":300,
"slaveThreshold":0
},
"masters":[ #配置多个节点,在主挂的时候会选一个检测存活的数据源作为主节点
"prototypeDs"
],
"maxCon":200,
"name":"prototype",
"readBalanceType":"BALANCE\_ALL",
"switchType":"SWITCH"
}
字段:
clusterType:集群类型
可选值:
single_node:单一节点
master_slave:普通主从
garela\_cluster:garela cluster /PXC 集群
MHA:MHA集群
MGR:MGR集群
readBalanceType:查询负责均衡策略
可选值:
BALANCE\_ALL(默认值):获取集群中所有数据源
BALANCE\_ALL\_READ:获取集群中允许读的数据源
BALANCE\_READ\_WEITE:获取集群中允许读写的数据源,但允许读的数据源优先
BALANCE——NODE:获取集群中允许写数据源,即主节点中选择
switchType:切换类型
可选值:
NOT\_SWITCH:不进行主从切换
SWITCH:进行主从切换
5.逻辑库表(schema)
配置逻辑库表,实现分库分表
1.所在目录
mycat /conf/shemas
2.命名方式
{库名}.schema.json
3.配置内容
[root@localhost conf]# vi schemas/mysql.schema.json
#库配置
"locality":{
"schemaName":"mysql",
"tableName":"spm\_baseline",
"targetName":"prototype"
}
#schemaName:逻辑库名
#targetName:目的数据源或集群
targetName自动从prototype目标加载test库下的物理表或者视图作为单表,prototype必须是MySQL服务器
#单表配置
{
"schemaName": "mysql-test",
"normalTables": {
"role\_edges": {
"createTableSQL":null,//可选
"locality": {
"schemaName": "mysql",//物理库,可选
"tableName": "role\_edges",//物理表,可选
"targetName": "prototype"//指向集群,或者数据源
}
}
五,搭建读写分离
我们通过mycat和mycat的主从复制配合搭建数据库的读写分离,实现MySQL的高可用性,我们将搭建,一主一从,双主双从两种读写分离模式。
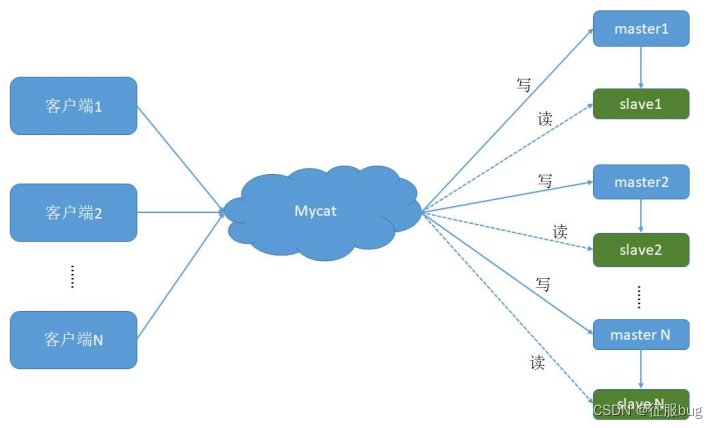
1.搭建一主一从
一个主机用于处理所有写请求,一台从机负责所有读请求
1.搭建MySQL数据库主从复制
1.主MySQL配置
[root@localhost ~]# vi /etc/my.cnf
server-id=1
log-bin=mysql-bin
[root@localhost ~]# systemctl restart mysqld
2.其他配置
#设置不要复制的数据库(可以设置为多个)
binlog-ignore-db=dbname
binlog-ignore-db=information_schema
#设置需要复制的数据库
binlog-do-db=dbname
#设置binlog格式
binlog\_format=statement
2.从MySQL配置
[root@localhost ~]# vi /etc/my.cnf
server-id=2
log-bin=mysql-bin
[root@localhost ~]# systemctl restart mysqld
3.主MySQL添加授权用户和二进制日志信息
mysql> grant replication slave on \*.\* to slave@'%' identified by '1234.Com';
mysql> show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000002 | 438 | | | |
+------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
4.在从机上做主从
mysql> change master to master_host='192.168.2.1',master_user='slave',master_password='1234.Com',master_log_pos=438,master_log_file='mysql-bin.000002';
Query OK, 0 rows affected, 2 warnings (0.00 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
mysql> show slave status\G
Slave_IO_Running: Yes #数据传输
Slave_SQL_Running: Yes #SQL执行
5.测试验证(主MySQL)
mysql> create database mydb1;
Query OK, 1 row affected (0.00 sec)
mysql> use mydb1;
Database changed
mysql> create table mytb1(id int,name varchar(50));
Query OK, 0 rows affected (0.00 sec)
mysql> insert into
-> mytb1 values(1,'zhangsan');
Query OK, 1 row affected (0.03 sec)
mysql> insert into mytb1 values(2,'lisi');
Query OK, 1 row affected (0.00 sec)
mysql> select \* from mytb1;
+------+----------+
| id | name |
+------+----------+
| 1 | zhangsan |
| 2 | lisi |
+------+----------+
2 rows in set (0.00 sec)
2.配置mycat读写分离
1.创建数据源
[root@localhost mycat]# mysql -uroot -p123456 -P8066 -h192.168.2.1
mysql> create database mydb1;
[root@localhost mycat]# vi conf/schemas/mydb1.schema.json
{
"customTables":{},
"globalTables":{},
"normalProcedures":{},
"normalTables":{},
"schemaName":"mydb1",
"targetName": "prototype",
"shardingTables":{},
"views":{}
}
2.登录mycat添加数据源
[root@localhost mycat]# mysql -uroot -p123456 -P8066 -h192.168.2.1
mysql> /\*+ mycat:createDataSource{ "name":"rwSepw","url":"jdbc:mysql://192.168.2.1:3306/mydb1?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true", "user":"root","password":"1234.Com" } \*/;
Query OK, 0 rows affected (0.02 sec)
mysql>
mysql> /\*+ mycat:createDataSource{ "name":"rwSepr","url":"jdbc:mysql://192.168.2.2:3306/mydb1?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true", "user":"root","password":"1234.Com" } \*/;
Query OK, 0 rows affected (0.03 sec)
#查询配置数据源结果
mysql> /\*+ mycat:showDataSources{} \*/\G
3.更新集群信息,添加dr0从节点,实现读写分离
mysql> /\*!mycat:createCluster{"name":"prototype","masters":["rwSepw"],"replicas":["rwSepr"]} \*/;
Query OK, 0 rows affected (0.03 sec)
mysql> /\*+ mycat:showClusters{} \*/; #查看集群配置文件
+-----------+-------------+-------------------+-------------+----------+---------------+-------------------------------------------+-------------------------------------------+-----------+
| NAME | SWITCH_TYPE | MAX_REQUEST_COUNT | TYPE | WRITE_DS | READ_DS | WRITE_L | READ_L | AVAILABLE |
+-----------+-------------+-------------------+-------------+----------+---------------+-------------------------------------------+-------------------------------------------+-----------+
| prototype | SWITCH | 2000 | BALANCE_ALL | rwSepw | rwSepw,rwSepr | io.mycat.plug.loadBalance.BalanceRandom$1 | io.mycat.plug.loadBalance.BalanceRandom$1 | true |
+-----------+-------------+-------------------+-------------+----------+---------------+-------------------------------------------+-------------------------------------------+-----------+
1 row in set (0.01 sec)
ava.lang.RuntimeException: java.lang.IllegalArgumentException: ignored rw
Sepr
修改集群配置文件
[root@localhost mycat]# vi /usr/local/mycat/conf/clusters/prototype.cluster.json
{
"clusterType":"MASTER\_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetryCount":3,
"minSwitchTimeInterval":300,
"showLog":false,
"slaveThreshold":0.0
},
"masters":[
"rwSepw"
],
"replicas":[
"rwSepr"
],
"maxCon":2000,
"name":"prototype",
"readBalanceType":"BALANCE\_ALL",
"switchType":"SWITCH"
}
readBalanceType
查询负载均衡策略
可选值:
BALANCE_ALL(默认值)
获取集群中所有数据源
BALANCE_ALL_READ
获取集群中允许读的数据源
BALANCE_READ_WRITE
获取集群中允许读写的数据源,但允许读的数据源优先
BALANCE_NONE
获取集群中允许写数据源,即主节点中选择
switchType
NOT_SWITCH:不进行主从切换
SWITCH:进行主从切换
4.重启mycat
[root@localhost mycat]# ./bin/mycat restart
Stopping mycat2...
Stopped mycat2.
Starting mycat2...
5.验证读写分离
在从MySQL上修改数据
mysql> update mytb1 set name='wangwu' where id=2;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
然后使用mycat登录
查询来查看数据不同
六,双主双从读写分离
一个主机 m1 用于处理所有写请求,它的从机 s1 和另一台主机 m2 还有它的从机 s2 负责所有读请求。当 m1 主机宕机后,m2 主机负责写请求,m1、m2 互为备机。架构图 如下

1.环境
| 角色 | IP地址 |
|---|---|
| master1 | 192.168.2.1 |
| slave1 | 192.168.2.2 |
| master2 | 192.168.2.3 |
| slave2 | 192.168.2.4 |
2.搭建双主双从
1.一主一从
根据上面的读写分离的步骤做两遍
2.双主双从
master1与master2互作主从
1.master1配置
mysql> change master to master_host='192.168.2.3',master_user='slave',master_password='1234.Com',master_log_pos=438,master_log_file='mysql-bin.000001';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
2.master2配置
mysql> change master to master\_host='192.168.2.1',master_user='slave',master_password='1234.Com',master_log_pos=6394,master_log_file='mysql-bin.000001';
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
3.测试
查看是否master1创建库,四台同步
3.实现多种主从
1.双主双从
*m1:主机
*m2:备机,也负责读
*s1,s2:从机
2.添加两个数据源
注意:如果不是从一主一从做的需要添加四个数据源
1.登录mycat操作
为了做好运维面试路上的助攻手,特整理了上百道 【运维技术栈面试题集锦】 ,让你面试不慌心不跳,高薪offer怀里抱!
这次整理的面试题,小到shell、MySQL,大到K8s等云原生技术栈,不仅适合运维新人入行面试需要,还适用于想提升进阶跳槽加薪的运维朋友。

本份面试集锦涵盖了
- 174 道运维工程师面试题
- 128道k8s面试题
- 108道shell脚本面试题
- 200道Linux面试题
- 51道docker面试题
- 35道Jenkis面试题
- 78道MongoDB面试题
- 17道ansible面试题
- 60道dubbo面试题
- 53道kafka面试
- 18道mysql面试题
- 40道nginx面试题
- 77道redis面试题
- 28道zookeeper
总计 1000+ 道面试题, 内容 又全含金量又高
- 174道运维工程师面试题
1、什么是运维?
2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
3、现在给你三百台服务器,你怎么对他们进行管理?
4、简述raid0 raid1raid5二种工作模式的工作原理及特点
5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
7、Tomcat和Resin有什么区别,工作中你怎么选择?
8、什么是中间件?什么是jdk?
9、讲述一下Tomcat8005、8009、8080三个端口的含义?
10、什么叫CDN?
11、什么叫网站灰度发布?
12、简述DNS进行域名解析的过程?
13、RabbitMQ是什么东西?
14、讲一下Keepalived的工作原理?
15、讲述一下LVS三种模式的工作过程?
16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
17、如何重置mysql root密码?
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
a面试**
- 18道mysql面试题
- 40道nginx面试题
- 77道redis面试题
- 28道zookeeper
总计 1000+ 道面试题, 内容 又全含金量又高
- 174道运维工程师面试题
1、什么是运维?
2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
3、现在给你三百台服务器,你怎么对他们进行管理?
4、简述raid0 raid1raid5二种工作模式的工作原理及特点
5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
7、Tomcat和Resin有什么区别,工作中你怎么选择?
8、什么是中间件?什么是jdk?
9、讲述一下Tomcat8005、8009、8080三个端口的含义?
10、什么叫CDN?
11、什么叫网站灰度发布?
12、简述DNS进行域名解析的过程?
13、RabbitMQ是什么东西?
14、讲一下Keepalived的工作原理?
15、讲述一下LVS三种模式的工作过程?
16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
17、如何重置mysql root密码?
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

















 4939
4939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









