






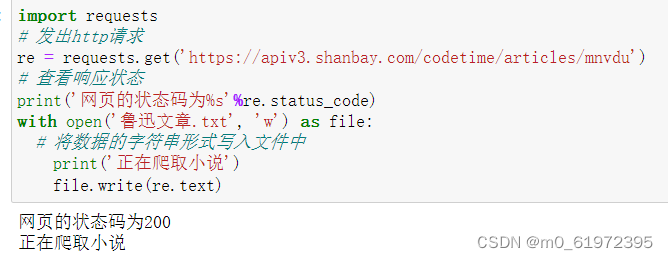
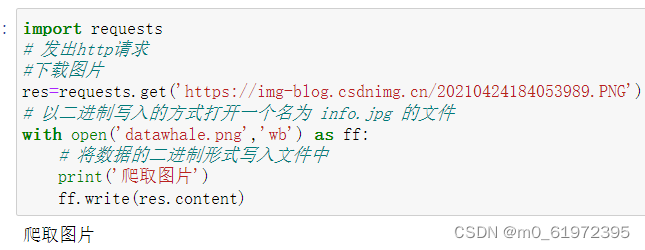
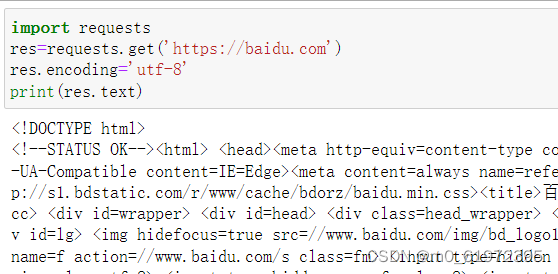
request 对网页Requests进行爬取 可以下载txt文件、下载图片、html解析
- re.status_code 响应的HTTP状态码
- re.text 响应内容的字符串形式 用于文本内容的获取、下载
- rs.content 响应内容的二进制形式 用于图片、视频、音频等内容的获取、下载
- rs.encoding 响应内容的编码 常见的编码方式有 ASCII、GBK、UTF-8 等
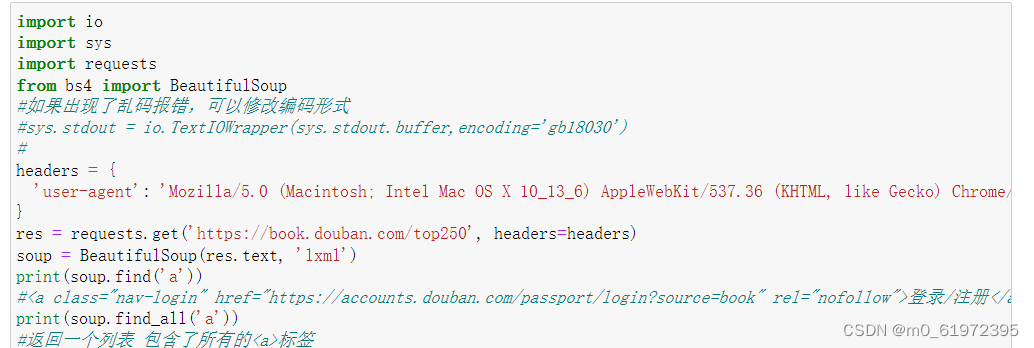
BeautifulSoup可以从HTML或XML文件中提取数据的Python库
find()方法和find_all()方法:
- find() 返回符合条件的首个数据
- find_all() 返回符合条件的所有数据
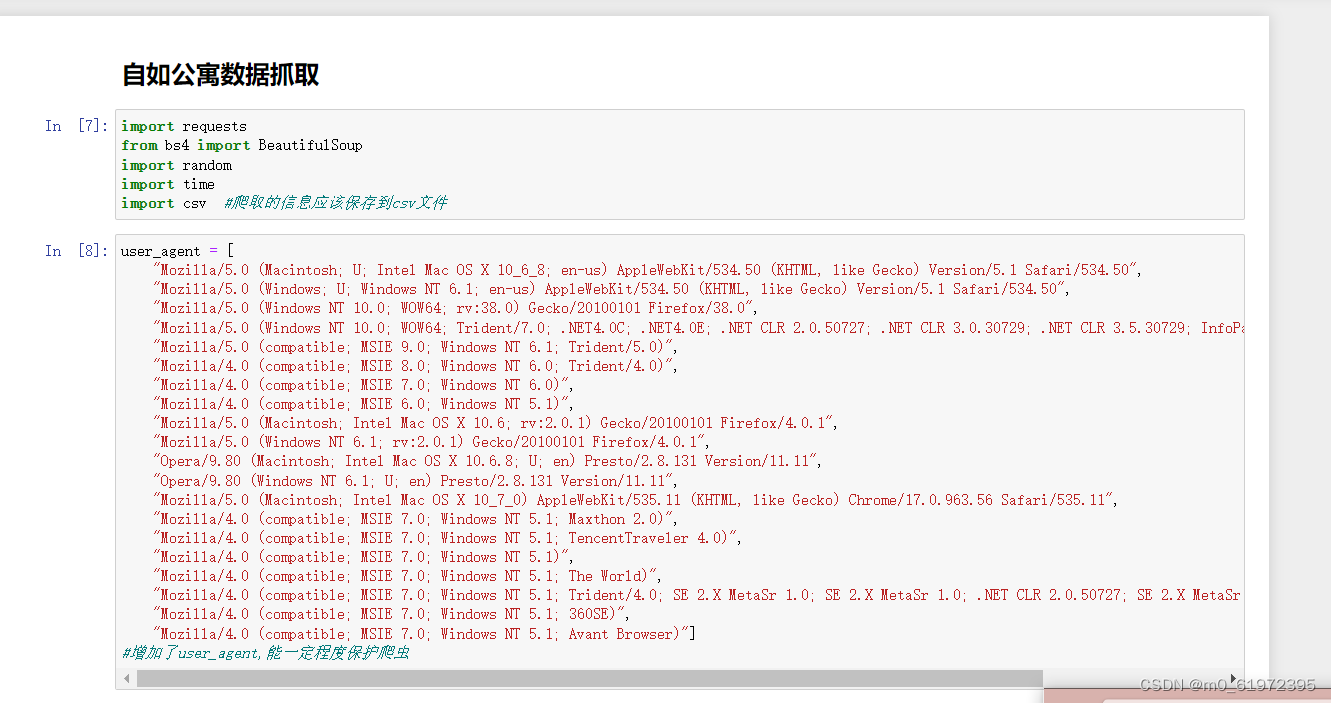
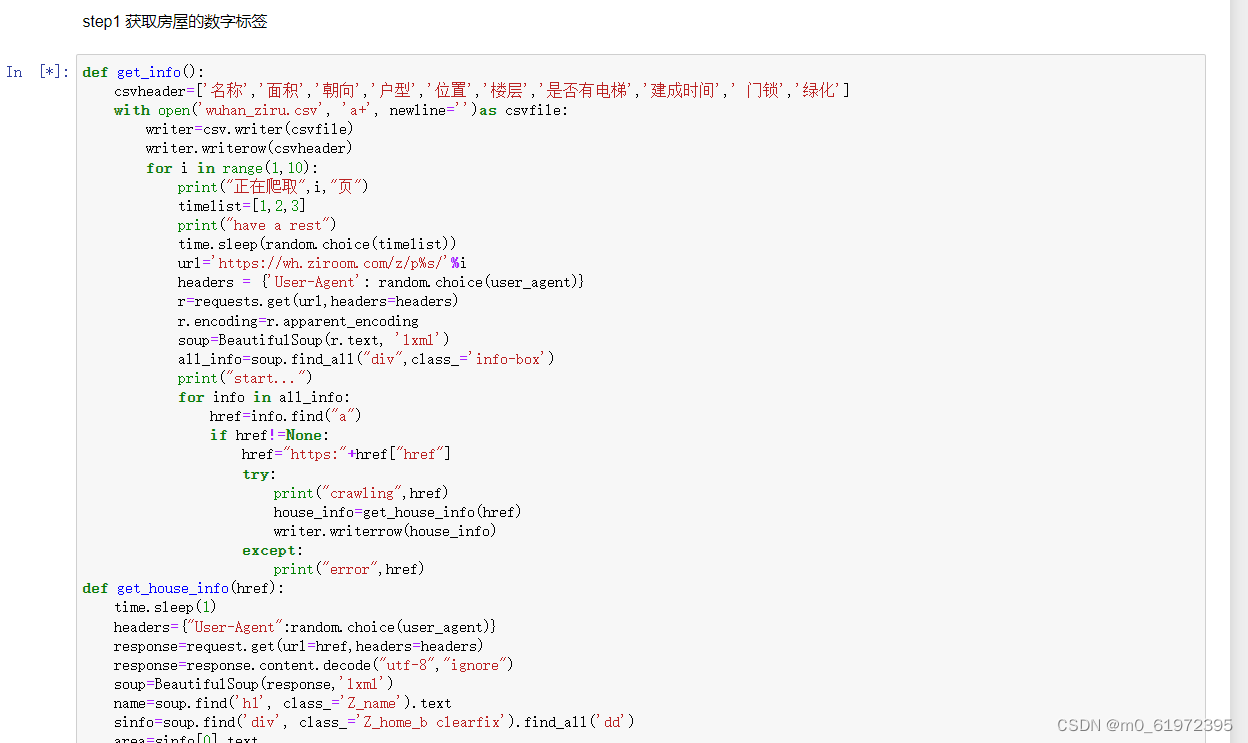
项目练习
















 6900
6900











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









