






目录
2. 全连接层(Fully Connected Layer, Dense Layer)
在深度模型中添加卷积层、全连接层等不同类型的层需要根据任务需求、数据特性和模型结构进行合理设计。以下是各层的作用、添加逻辑以及实际应用中的选择策略:
一、核心层类型与作用
1. 卷积层(Convolutional Layer)
作用:
- 局部特征提取:通过滑动窗口捕捉局部空间/时序模式(如图像边缘、纹理)。
- 参数共享:同一卷积核在输入的不同位置复用,减少参数量。
- 平移不变性:对输入中的位置变化具有一定鲁棒性。
典型应用场景:
- 图像处理:2D卷积(
Conv2D)。 - 时序数据:1D卷积(
Conv1D,如音频、文本)。 - 视频/3D数据:3D卷积(
Conv3D)。
关键参数:
kernel_size:卷积核大小(如3×3)。stride:滑动步长(控制输出尺寸)。padding:边界填充(same保持尺寸,valid不填充)。filters:输出通道数(即卷积核数量)。
代码示例(PyTorch) :
import torch.nn as nn
conv = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding="same")2. 全连接层(Fully Connected Layer, Dense Layer)
作用:
- 全局特征整合:将高维特征映射到任务相关空间(如分类得分)。
- 模式匹配:通过权重矩阵学习输入与输出间的复杂关系。
典型应用场景:
- 分类/回归任务的输出层。
- 卷积网络末端的特征展平后处理(如ResNet的
AdaptiveAvgPool + FC)。
关键参数:
in_features:输入维度。out_features:输出维度。bias:是否使用偏置项。
代码示例:
fc = nn.Linear(in_features=1024, out_features=10) # 10分类任务3. 池化层(Pooling Layer)
作用:
- 降维:减少计算量和过拟合(如最大池化保留显著特征)。
- 平移不变性增强:对微小位置变化不敏感。
类型:
- 最大池化(MaxPool) :取窗口内最大值,突出显著特征。
- 平均池化(AvgPool) :取窗口内平均值,平滑特征。
代码示例:
max_pool = nn.MaxPool2d(kernel_size=2, stride=2) # 尺寸减半4. 归一化层(Normalization Layer)
作用:
- 稳定训练:缓解梯度消失/爆炸,加速收敛。
- 减少内部协变量偏移(Internal Covariate Shift)。
常见类型:
- BatchNorm(批归一化) :沿Batch维度归一化,适合小批次数据。
- LayerNorm:沿特征维度归一化,适合RNN/Transformer。
- InstanceNorm:对每个样本单独归一化,适合风格迁移。
代码示例:
bn = nn.BatchNorm2d(num_features=64) # 输入通道数=645. 激活函数(Activation Function)
作用:
- 引入非线性:使模型能够拟合复杂函数。
- 控制输出范围:如Sigmoid将输出压缩到(0,1)。
常见选择:
- ReLU:简单高效,缓解梯度消失(但可能导致神经元死亡)。
- LeakyReLU:解决ReLU的死亡问题(负区间斜率=0.01)。
- GELU:Transformer常用,平滑版的ReLU。
代码示例:
activation = nn.GELU()二、层的添加逻辑与设计原则
1. 卷积网络的典型结构(以图像分类为例)
model = nn.Sequential(
# 阶段1:高频特征提取(边缘/纹理)
nn.Conv2d(3, 64, kernel_size=3, padding="same"),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2), # 降维
# 阶段2:中级特征(局部形状)
nn.Conv2d(64, 128, kernel_size=3, padding="same"),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
# 阶段3:全局特征整合
nn.AdaptiveAvgPool2d(1), # 全局平均池化
nn.Flatten(),
nn.Linear(128, 10) # 分类头
)设计逻辑:
- 逐步增加通道数(64 → 128):扩大特征表达能力。
- 逐步降低空间尺寸(通过池化或大步长卷积):减少计算量。
- 末端使用全局池化 + FC:避免固定输入尺寸限制。
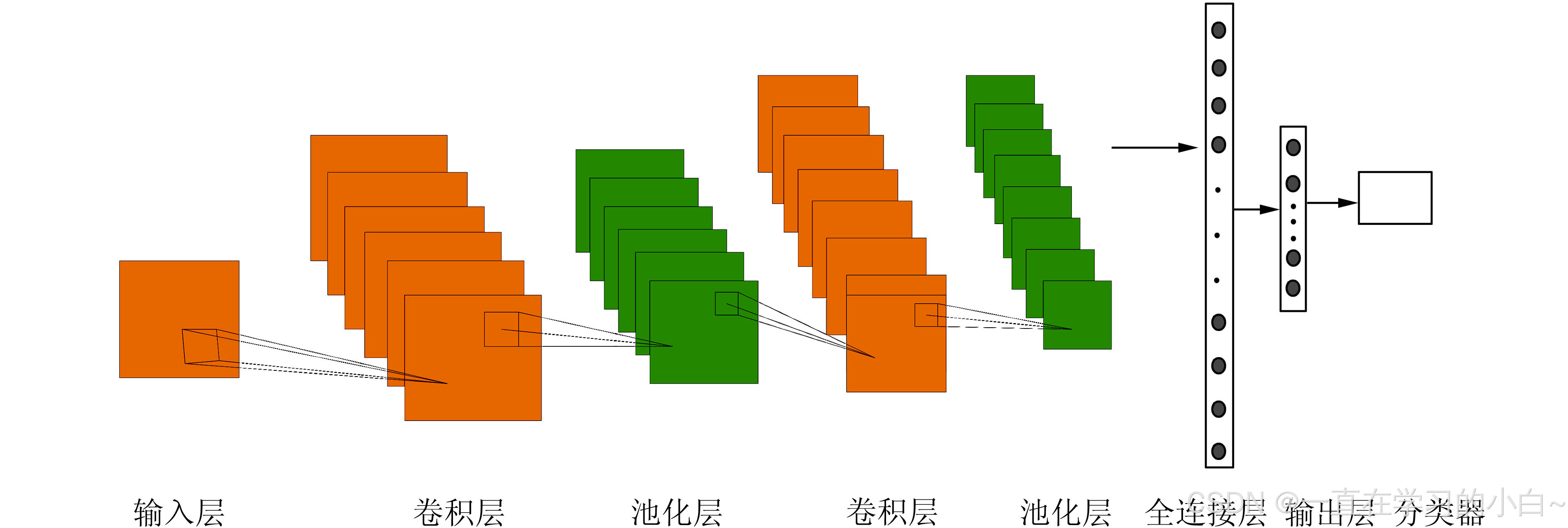
2. 全连接网络的设计陷阱
错误示范:
nn.Sequential(
nn.Linear(1024, 4096), # 参数量爆炸!
nn.Linear(4096, 4096),
nn.Linear(4096, 10)
)问题:
- 参数量过大(1024×4096 + 4096×4096 ≈ 21M参数)。
- 容易过拟合,训练不稳定。
改进方案:
- 添加Dropout层(如
nn.Dropout(0.5))抑制过拟合。 - 使用更小的中间维度(如1024 → 512 → 256 → 10)。
3. 何时添加归一化层?
- 卷积网络:每个卷积层后加
BatchNorm(除非数据量极小)。 - Transformer:
LayerNorm用于残差连接后(如Pre-LN结构)。 - 生成对抗网络(GAN) :
InstanceNorm更适合风格化输出。
4. 特殊层的应用场景
| 层类型 | 典型场景 | 作用 |
|---|---|---|
| Dropout | 全连接层之间 | 防止过拟合 |
| 残差连接 | 深层网络(如ResNet) | 缓解梯度消失 |
| 注意力机制 | Transformer、多模态融合 | 动态聚焦重要区域 |
| 转置卷积 | 生成模型(如GAN) | 上采样生成图像 |
三、实战建议
1. 图像任务(CNN架构)
- 基础结构:
Conv → BN → ReLU → Pooling重复堆叠,末端接全局池化和分类头。 - 进阶技巧:
- 使用深度可分离卷积(
DepthwiseConv)减少参数量。 - 添加注意力模块(如SE Block)增强重要通道。
- 使用深度可分离卷积(
2. 序列任务(RNN/Transformer)
- RNN结构:
Embedding → LSTM/GRU → LayerNorm → FC。 - Transformer结构:
MultiHeadAttention → Add & Norm → FFN → Add & Norm。
3. 多模态融合
- 早期融合:不同模态输入拼接后通过共享网络。
- 晚期融合:各模态单独编码后联合训练(如CLIP的对比学习)。
四、常见问题解答
问题一:卷积层后必须加池化吗?
- 不一定。可用步长=2的卷积替代池化(如ResNet),但池化能增强平移不变性。
问题二:全连接层越多越好吗?
- 不是。FC层参数量大,容易过拟合,通常1-3层足够。
问题三:如何选择激活函数?
- 默认先用ReLU,遇到死亡神经元换LeakyReLU或GELU。
- 输出层根据任务选:分类用Sigmoid/Softmax,回归用线性。
问题四:归一化层放在激活前还是激活后?
- BatchNorm:通常放在卷积后、激活前(
Conv → BN → ReLU)。 - LayerNorm:放在激活后(如Transformer的Pre-LN结构)。
通过合理组合这些层,可以构建高效、稳定的深度模型。实际设计中需通过实验验证不同结构的性能,并参考经典模型(如ResNet、ViT)的最佳实践。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











