







对头条文章浏览数据的关联分析
数据链接:
所用到的数据:
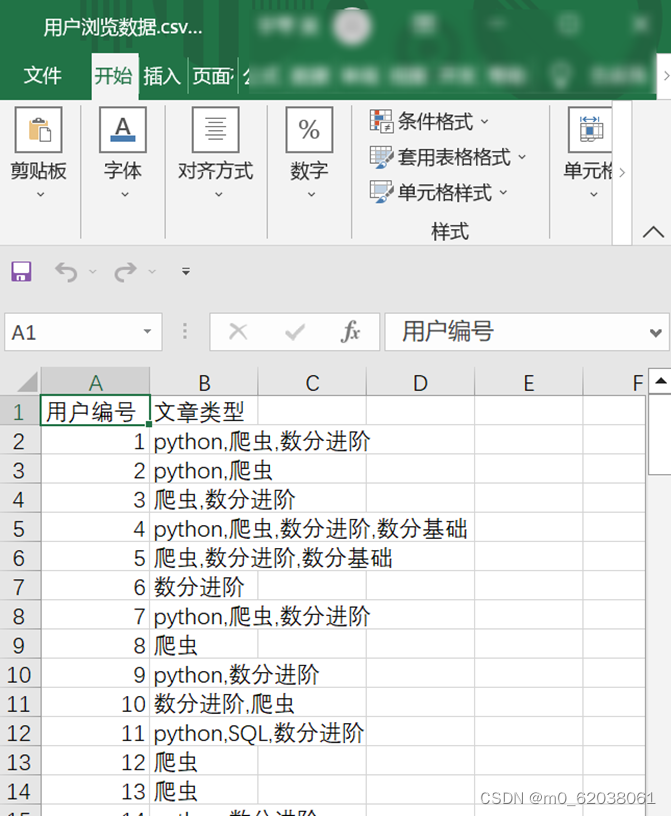
目的:什么类型的文章对什么类型的文章会有促进作用
解题思路:找出强关联规则的项集,观察提升度是否有促进作用
解题步骤:倒着推导一遍为了得到强关联促进关系,我们需要知道提升度,前件,后件,所以需要利用apriori算法,ok
STEP1 观察表结构,转化为双重表结构,方便使用apyori算法
#数据预处理
#双重列表数据结构
articles = []
#step1.将字符串数据转成列表;step2.在列表添加到空列表中
for i in df["文章类型"]:
article = i.split(",")
articles.append(article)
print(articles)
![]()
STEP2 下载apyori模块,使用apyori模块里的apriori()函数产生关联规则
Pip install apyori
#设置强关联规则
from apyori import apriori
#得到强关联规则的关系记录
rules = apriori(articles, min_support= 0.1, min_confidence= 0.6)
STEP3 遍历出规则中的关系记录
for rule in rules:
print(rule)

STEP4 提取支持度,前件,后件,置信度,提升度
for rule in rules:
support = rule.support
for i in rule.ordered_statistics:
head_set = i.items_base
tail_set = i.items_add
confidence = i.confidence
lift = i.lift
print(head_set, tail_set, confidence, lift)

完整代码:
import pandas as pd
df = pd.read_csv(r"C:\用户浏览数据.csv")
#数据预处理
#双重列表数据结构
articles = []
#step1.将字符串数据转成列表;step2.在列表添加到空列表中
for i in df["文章类型"]:
article = i.split(",")
articles.append(article)
#设置强关联规则
from apyori import apriori
#得到强关联规则的关系记录
rules = apriori(articles, min_support= 0.1, min_confidence= 0.6)
#用来存储DataFrame数据
extract_result = []
for rule in rules:
#提取支持度
support = round(rule.support, 3)
#提取前后件,置信度、提升度
for i in rule.ordered_statistics:
#把前件和后件的格式转化为列表
head_set = list(i.items_base)
tail_set = list(i.items_add)
#筛选掉前件为空的数据
if head_set == []:
continue
#将前件和后件拼接为关联字符串
related_category = str(head_set) + "→" +str(tail_set)
#对置信度和提升度四舍五入保留三位小数
confidence = round(i.confidence, 3)
lift = round(i.lift, 3)
extract_result.append([related_category, support, confidence, lift])
rule_data = pd.DataFrame(extract_result, columns= ["关联规则", "支持度", "置信度", "提升度"])
#促进关系
promoted_rules = rule_data[rule_data["提升度"] > 1]
#抑制关系
restricted_rules = rule_data[rule_data["提升度"] < 1]
#绘制簇形柱状图,同时观察支持度和置信度的情况
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = "FangSong"
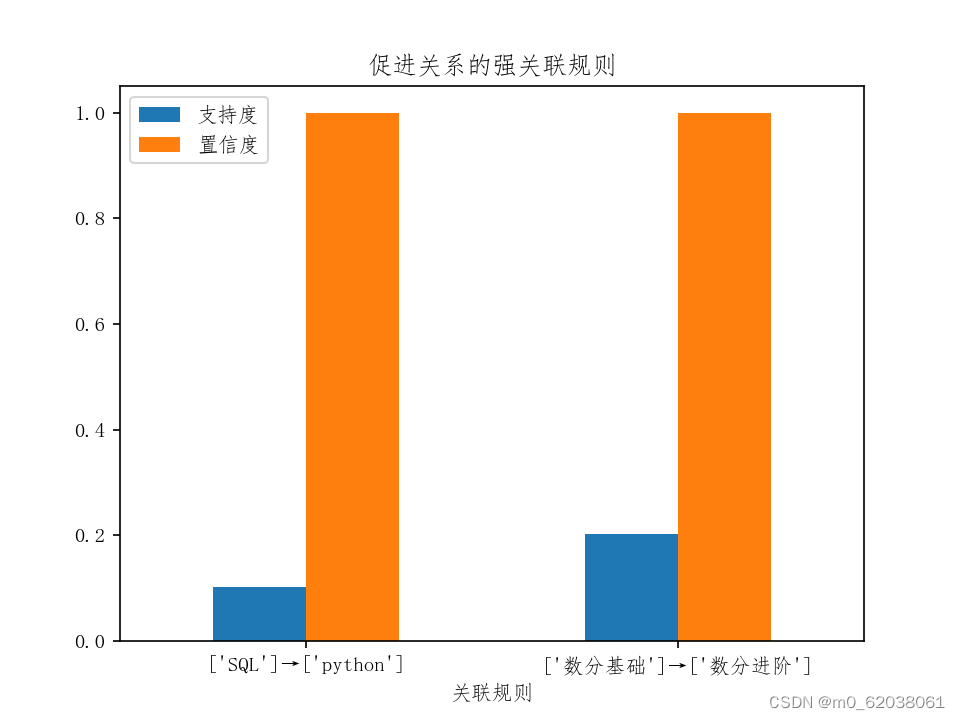
promoted_rules.plot.bar("关联规则", ["支持度", "置信度"], rot = 0)
plt.title("促进关系的强关联规则")
plt.show()
结果展示:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









